
MindStudio Insight高效锁定Triton算子内存溢出问题
背景:Triton内存管理简介
昇腾硬件内存层次结构
昇腾内存体系采用分层的结构设计,每层都有不同的容量、带宽、访问特性。
以下是昇腾NPU架构版本351x的硬件架构图(https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/900/programug/Ascendcopdevg/atlas_ascendc_10_00065.html)。重点关注全局内存(Global Memory)、L2缓存(L2 Cache)、统一缓冲区(Unified Buffer)、L1缓冲区(L1 Buffer)和寄存器文件(包括SIMT Register File和Vector Register File两个)这些存储单元。
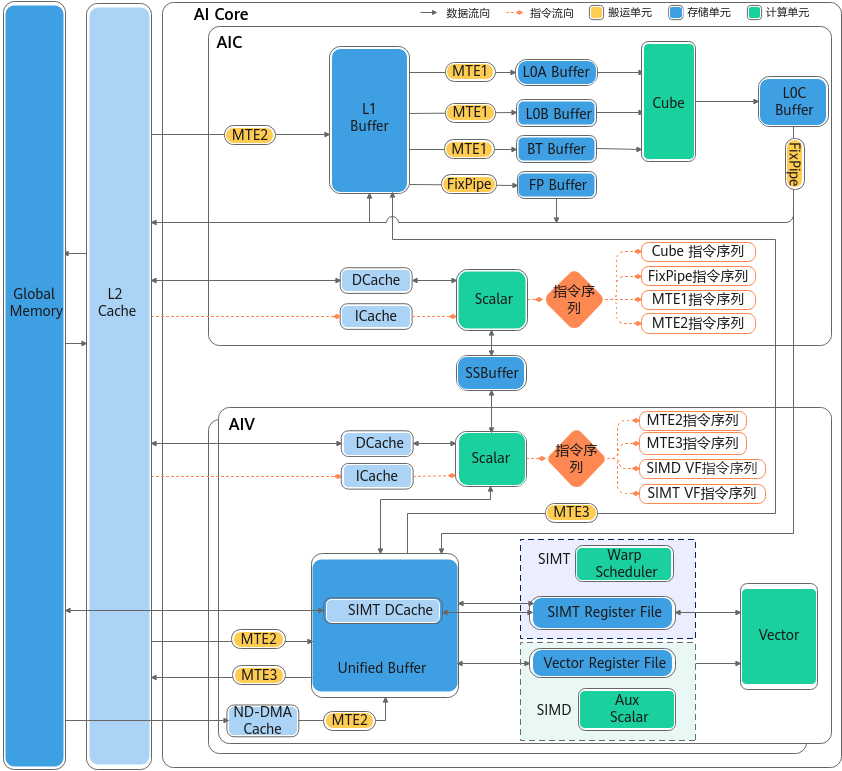
图1 NPU架构版本351x硬件架构图
这些存储单元共同构成了昇腾NPU的内存层次结构,通过不同层级的缓存和数据搬运机制,有效平衡了内存带宽和计算性能。
内存优化的策略
昇腾NPU的统一缓冲区(Unified Buffer, UB)容量有限,为了避免UB Overflow,并最大化访存带宽,必须将庞大的输入张量(Q/K/V)切分为大小合适的Block。
分块策略是解决昇腾硬件片上内存有限性、优化内存访问模式、适配硬件架构差异的必要技术手段,是Triton-Ascend高效实现高性能算子的核心机制。其目标是将数据分解为适合片上的内存大小。在实际开发Triton-Ascend算子的过程中,我们通常会通过设置合适的BLOCK_SIZE来控制一次处理的数据块大小。
Triton算子开发问题:内存UB Overflow
内存优化的核心技术是分块。在现实中通常需要尝试多组分块参数,以得到最佳性能。如果分块过小,芯片性能无法得到充分发挥。如果分配内存过大,由于片上内存是有限的,那么会造成内存溢出,即UB Overflow问题。
其中的一个重要参数就是BLOCK_SIZE。BLOCK_SIZE定义了每个Block处理的元素数量,例如在向量加法算子中,设置BLOCK_SIZE=1024表示每个Block处理1024个元素。
在一般实现中,BLOCK_SIZE对于算子单次处理的数据总量具有决定性作用,且通常单次处理的数据量与算子运行所需的UB大小成正比。
当出现Triton算子内存溢出时,通过日志,我们仅能知道发生了UB overflow,但是具体在何处代码导致的内存异常,有哪些Tensor在使用内存还是一无所知,对于问题定位造成很大的困扰。
因此昇腾MindStudio提供了基于编译器产物的内存使用情况分析工具,通过编译器dump内存打点,结合MindStudio Insight可视化分析,实现UB Overflow的代码级精准定位。
内存溢出案例演示
数据准备与运行
我们使用Triton-Ascend官方仓库中的示例代码05-layer-norm.py(https://gitcode.com/Ascend/triton-ascend/blob/main/third_party/ascend/tutorials/05-layer-norm.py)模拟内存溢出的场景。
原始代码中BLOCK_SIZE会受到MAX_FUSED_SIZE的边界影响(见下方代码),保证不会内存溢出。为了构造内存溢出场景,我们需要更改代码逻辑,使得BLOCK_SIZE可以超过MAX_FUSED_SIZE的边界。(改动如下所示)
# Less than 64KB per feature: enqueue fused kernel- MAX_FUSED_SIZE = 65536 // x.element_size()- BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))+ BLOCK_SIZE = triton.next_power_of_2(N)
我们构造了可稳定复现内存溢出的测试用例:

下面我们用large_N_8192作为例子展示我们Triton算子内存溢出时的定位方法。
环境配置:
NPU: 昇腾910
CANN: 9.5.0
Triton-Ascend: 3.2.1
torch_npu: 2.7.0
torch: 2.7.0
用例large_N_8192参数配置:
在05-layer-norm.py中,修改main的部分
if __name__ == "__main__":_layer_norm(128, 8192, torch.float16)
用例large_N_8192运行:
python 05-layer-norm.py在实际执行中,我们可以看到用例large_N_8192在BLOCK_SIZE >= 16384(预估UB使用256KB)时,执行失败,开始抛出内存溢出的异常。
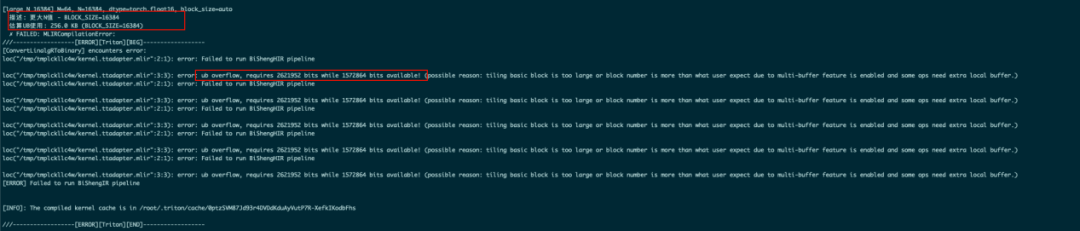
图2 large_N_8192 运行报错信息
下面我们用CANN提供的毕昇编译器(https://www.hiascend.com/cann/bisheng)工具采集Triton算子在编译过程中出现的内存溢出数据。
数据采集
我们取large_N_8192用例第一个出现Overflow的用例作为例子采集数据。
Triton-Ascend算子的编译调用链路如下:
python -> triton-ascend -> npuir -> bishengir-compiler前面我们在执行算子时已经触发了UB Overflow,此时我们找到对应的Triton缓存目录。
// (triton) localhost:triton-ascend/third_party/ascend/tutorials# ls .triton_cache/${lastest_cache}_layer_norm_fwd_fused.ttadapter _layer_norm_fwd_fused.ttir
通过编译执行如下命令,在当前目录下会得到一个memory_info_aiv.json:
bishengir-compiler _layer_norm_fwd_fused.ttadapter --target=Ascend910B --enable-auto-multi-buffer=True --enbale-auto-bind-sub-block-True --enable-hfusion-compile-true --enable-hivm-compile-true --enable-triton-kernel-compile=true --mlir-pirnt-ir-before-all --mlir -print-ir-alter-all --enable-memory-dispaly参数的详细说明可以见命令行帮助信息。
数据展示及分析
在MindStudio Insight软件(https://gitcode.com/Ascend/msinsight)中导入memory_info_aiv.json文件
导入后如下所示:
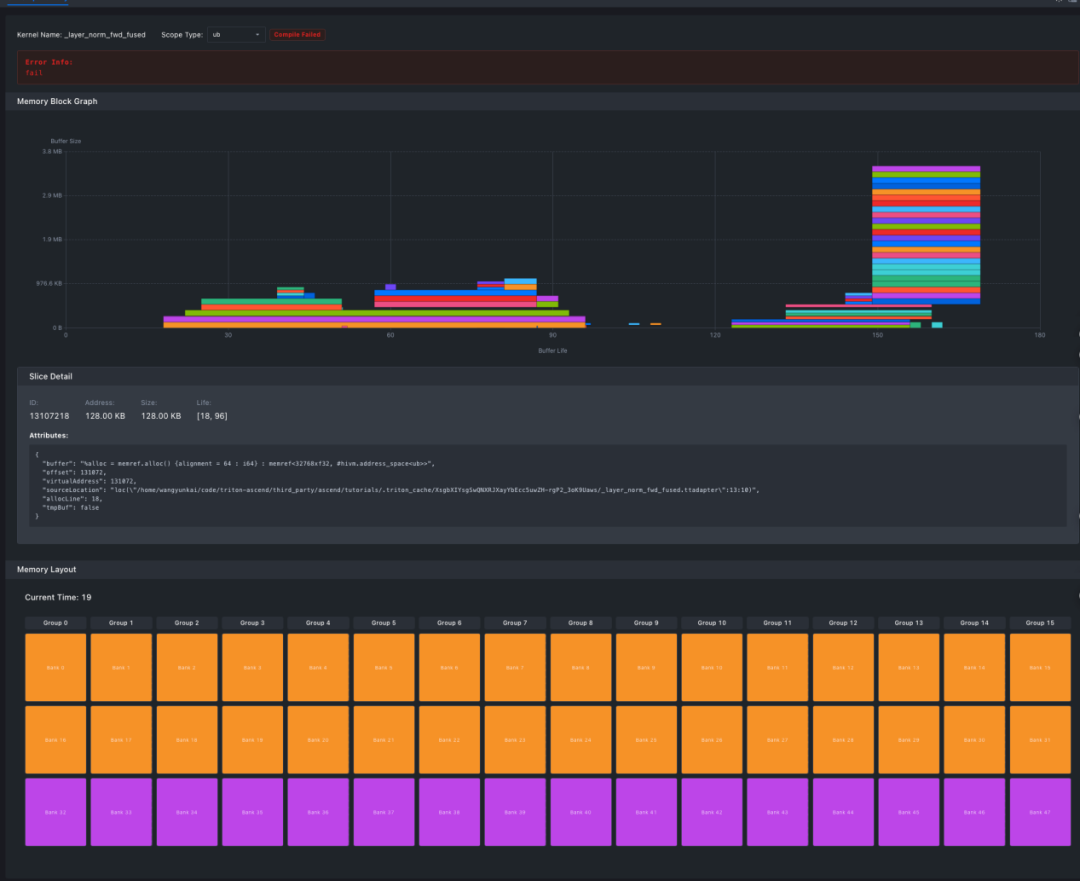
图3 MindStudio Insight 导入 json 文件总览
标题栏
标题栏中包含了算子名称、内存类型、编译状态信息

图4 标题栏显示编译情况和具体报错信息
从这里可以直接看出算子编译存在问题,接下来要具体分析问题原因。
内存块图
该图反映了随时间变化内存的使用情况。横轴是一个虚拟的执行顺序,每个时间单位相当于IR(Intermediate Representation)文件中的一行,竖轴是片上的连续的虚拟内存地址空间。图中每个色块代表一块Tensor内存,它的纵向长度表示占用的内存地址空间大小,它的横向长度表示在IR文件上的生命周期。在这张图上可以反映整体运行过程中保留的连续虚拟内存地址空间的峰值和碎片情况。
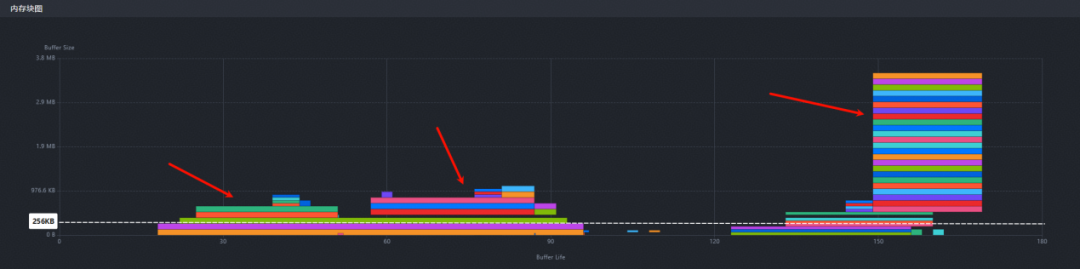
图5 内存块图显示连续虚拟内存地址空间
经过分析。large_N_8192用例的连续虚拟内存地址空间大小中超过256 KB的地方都是存在问题的,其中最后面的地方保留的连续虚拟内存地址空间最大,是导致内存溢出问题最严重的地方。此外,其他超过256 KB的地方也是需要处理,保证总体连续虚拟内存地址空间都不高于256 KB。
内存详情表
在内存块图上点击具体某个内存块时,该图就会展示内存块的详细信息,包括大小、生命周期、申请位置、是否为临时变量。这里我们需要点击超过256 KB的内存块,分析导致内存溢出的具体原因,即这个内存块是在哪一行代码申请的,定位到内存溢出的代码位置。
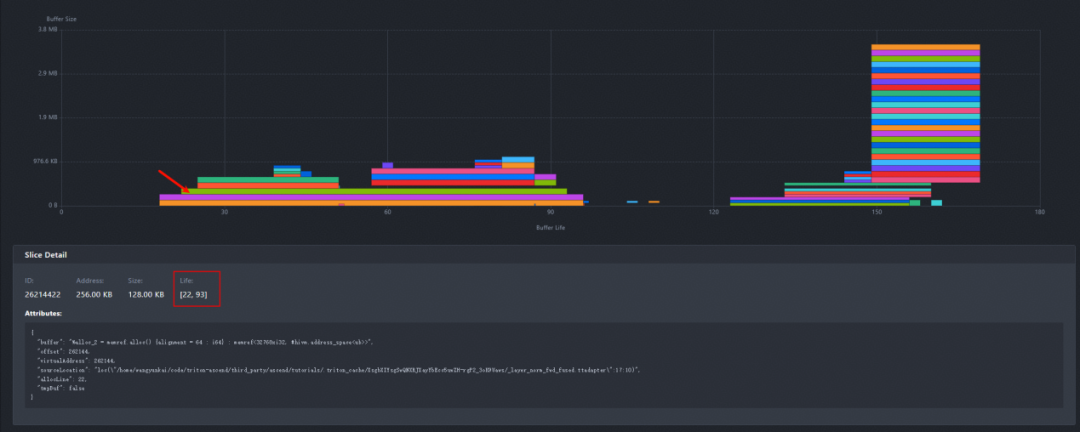
图6 内存详情表展示内存块的详细信息
我们选择第一个超过256 KB的内存块,显示这个内存块的内存详情表。我们重点关注详情表中的Life属性,这个属性显示了内存块是从IR文件的哪一行申请、在哪一行释放的。
这里定位到了IR文件导致内存溢出的代码行,接下来开发者可以从IR文件自行推导到Triton算子的Python文件中导致的内存溢出的代码行。
使用昇腾MindStudio提供的工具链可以很好定位Triton算子内存溢出问题。未来昇腾MindStudio将持续改进,不断优化使用流程,帮助开发者快速定位并解决Triton算子内存溢出问题,提高Triton算子开发效率。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 1
1 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)