
CANN ND格式、NZ(FRACTAL_NZ)格式完整详解
·
CANN ND格式、NZ(FRACTAL_NZ)格式完整详解
二者是昇腾矩阵/GEMM优化最核心的两种张量存储布局,ND是通用标准格式,NZ是Cube硬件专用分形优化格式,专门解决GEMM访存带宽、Cube利用率瓶颈。
一、ND格式(ACL_FORMAT_ND,Normal Dimension)
1. 定义
标准多维行优先连续存储格式,是PyTorch、TensorFlow、CPU通用原生布局,无硬件分块改造,完全贴合逻辑矩阵维度顺序。
- 全称:N-Dimension,任意维度张量都能用ND表示;
- 存储规则:行主序(Row-Major),先存完整一行,再存下一行;多维张量按维度从高到低平铺连续存放。
2. 二维矩阵示例(4×4矩阵)
逻辑矩阵:
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
ND内存一维排布:0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
3. 核心特性
- 通用性极强
加减、激活、归一化、AICPU算子、Host与Device数据互传全部原生支持;NCHW/NHWC本质都是ND的四维特化形式。 - 逻辑直观、无填充
内存地址和矩阵坐标一一对应,无需对齐填充,Host侧读写、调试打印非常方便。 - Cube计算存在额外开销(最大短板)
Cube单元原生只识别16×16硬件块,ND矩阵送入GEMM时,硬件会实时在线转换ND→NZ,消耗HBM带宽、SDMA搬运周期,降低Cube利用率。 - 适用场景
- 模型输入输出、特征图、激活值、向量运算算子;
- 训练场景(权重会反向更新,无法提前预处理转NZ);
- 小规模矩阵、非矩阵乘类算子。
二、NZ格式(FRACTAL_NZ,昇腾分形硬件优化格式)
1. 定义
昇腾达芬奇Cube单元专属优化分块布局,全称Fractal_NZ,专门为FP16/BF16 GEMM矩阵乘设计,把大矩阵拆成硬件天然适配的16×16基础块(FP32为16×8),重排内存顺序消除ND转置开销。
命名拆解:
- Z:块内Z字形(Morton序) 存储元素;
- N:块之间N字形(列主序) 排列分块。
2. 存储两层规则(FP16 16×16基础块)
- 块内(Z序)
单个16×16小块内部元素按Z字交错排列,保证Cube单次取16个数据连续,无Bank冲突; - 块间(N/列主序)
所有16×16小块不按行平铺,而是按列优先依次存放,适配Cube读取K/N维度分片的访存模式。
3. 4×4极简对比ND vs NZ排布
同4×4矩阵,NZ一维内存顺序:0,1,4,5,8,9,12,13,2,3,6,7,10,11,14,15
直观区别:ND一行存完再下一行;NZ先取每两行前两列小块,再存右侧块。
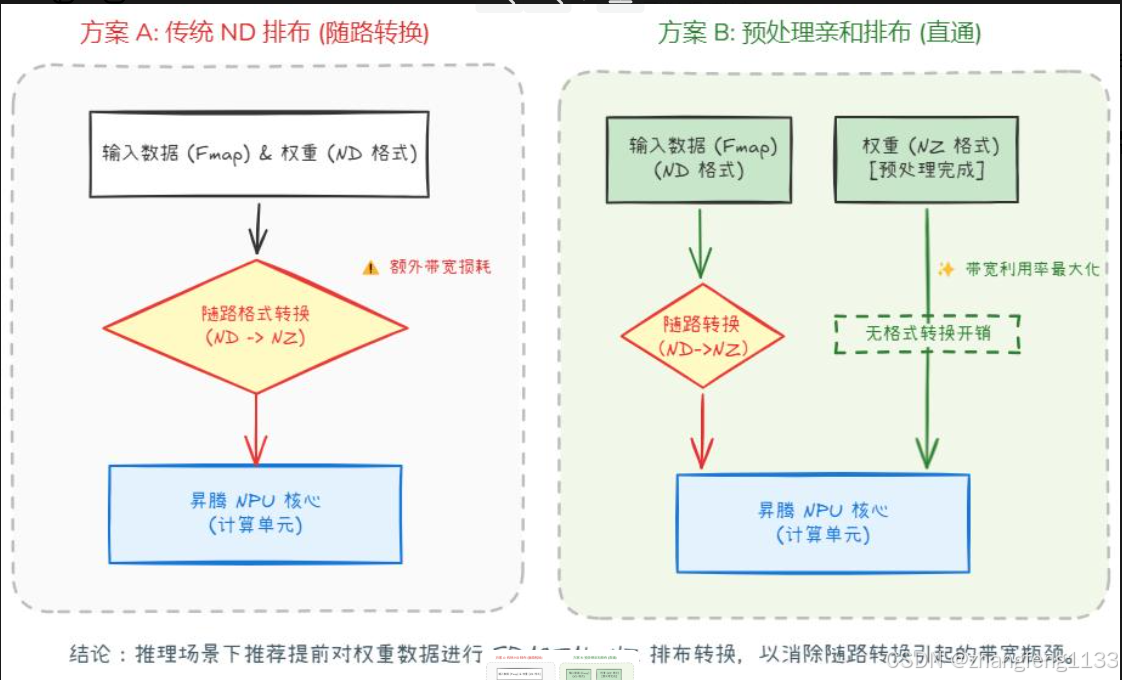
4. 核心优势(GEMM性能关键)
- 消除运行时格式转换开销
推理时权重提前离线转为NZ,GEMM读取时无需ND→NZ实时转置,节省大量Global Memory带宽,msprof可见HBM带宽利用率显著提升。 - 完美匹配Cube 16×16计算粒度
SDMA搬运16×16整块到L0A/L0B时数据完全连续,无碎片化访存,Cube流水线气泡大幅减少,CubeUtilization指标明显上涨。 - Local缓存命中率大幅提升
分块对齐L0缓存容量,减少Global↔Local反复搬运次数,访存瓶颈缓解。
5. 局限性
- 存在填充开销
矩阵M/N/K不能被16整除时,NZ会自动补0对齐16倍数,占用少量额外Global显存; - 仅适合推理静态权重
训练场景权重需要反向梯度更新,频繁NZ↔ND转换会抵消收益,一般训练不启用NZ; - 非矩阵算子不兼容
激活、Add、Norm等向量算子无法直接读取NZ格式张量,必须转回ND使用。
三、ND vs NZ 核心对比表
| 对比维度 | ND 格式(通用标准) | NZ(FRACTAL_NZ) 硬件分形格式 |
|---|---|---|
| 设计目标 | 通用多维张量读写、Host交互 | Cube GEMM矩阵乘极致访存优化 |
| 存储顺序 | 全局行主序,一行完整连续 | 拆16×16基础块;块内Z序、块间N列序 |
| 数据填充 | 无填充,尺寸完全匹配逻辑矩阵 | 尺寸非16倍数需补0对齐 |
| Cube开销 | 运行时自动ND→NZ转换,耗带宽 | 预处理后零实时转换开销 |
| 适用算子 | 全部向量、卷积、AICPU、训练反向 | 仅推理GEMM/全连接静态权重 |
| Host可读性 | 坐标与地址一一对应,调试友好 | 内存重排,无法直接按坐标打印 |
| 内存占用 | 等于逻辑数据量 | 略大(对齐填充) |
四、工程开发使用场景(结合GEMM、Block、Local Memory)
1. 推理优化标准流程(权重走NZ)
- 离线预处理模型权重:ND权重 → 转换FRACTAL_NZ存入Global Memory;
- GEMM读取NZ权重,SDMA直接整块搬运16×16分片至L0B;
- Cube直接执行16×16乘,无格式转置,算力打满;
- 输出C矩阵默认ND格式,供后续激活算子读取。
2. 训练/动态数据流程(全程ND)
- 输入特征、权重均为ND;
- GEMM运行时硬件临时ND转NZ送入L0;
- 计算完成结果转回ND,用于反向梯度更新;
- 无法提前固化NZ,转换开销不可避免。
五、msprof观测区分两种格式瓶颈
- 只用ND权重现象
- HBM带宽利用率低;
- CubeUtilization偏低;
- Timeline出现大量格式转换SDMA任务;
优化:推理开启WeightNZ预转换。
- NZ格式正常现象
- SDMA搬运块尺寸固定16×16倍数,传输连续;
- Cube流水线利用率>80%,访存等待周期少;
- 踩坑点:NZ张量直接送入Add/Relu算子会报错,必须先转ND。
六、补充配套分形格式(拓展)
CANN还有FRACTAL_ZZ、FRACTAL_ZN,均是NZ同系列分形布局:
- ZZ:适合GEMM A矩阵输入;
- ZN:适合GEMM B矩阵;
- NZ:最常用,权重标准优化格式。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)