
Agent记忆系统-分层记忆治理・低时延知识供给:鲲鹏原生Agent记忆底座构建
鲲鹏原生Agent记忆底座以分层记忆治理与低时延知识供给为核心,构建上下文记忆管理框架、向量数据库、鲲鹏亲和加速三层架构。通过分层检索、按需加载、会话压缩归档、上下文缓存及混合介质检索等能力,实现记忆全生命周期管理。实测可降低Token开销50%+,提升任务成功率20%。
特性介绍
记忆系统解决方案以降低Token开销、提升任务成功率为目标,采用上下文/记忆管理框架、向量数据库、鲲鹏亲和加速的三层架构。
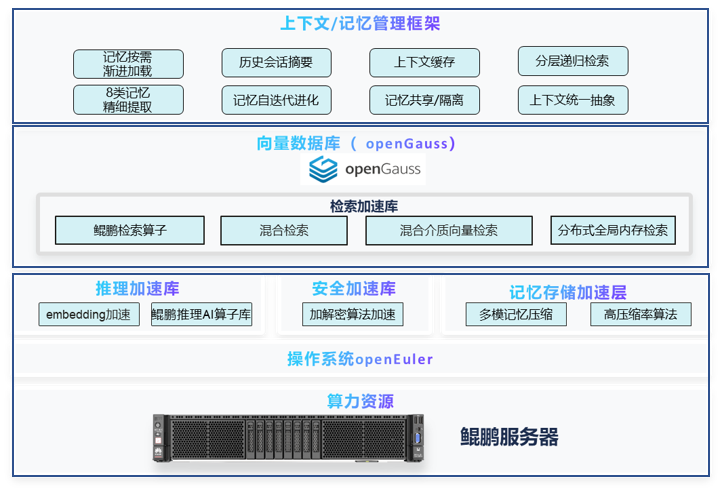
oG-Memory 上下文/记忆管理框架将Agent无状态上下文升级为受管理的系统资源,实现质量、成本与效率的协同优化。传统Agent记忆如同散落的便利贴,各自分立、无法复用;oG-Memory将其升级为系统化企业知识管理系统,支持权限控制、事务管理、版本审计,实现Agent按需获取记忆。
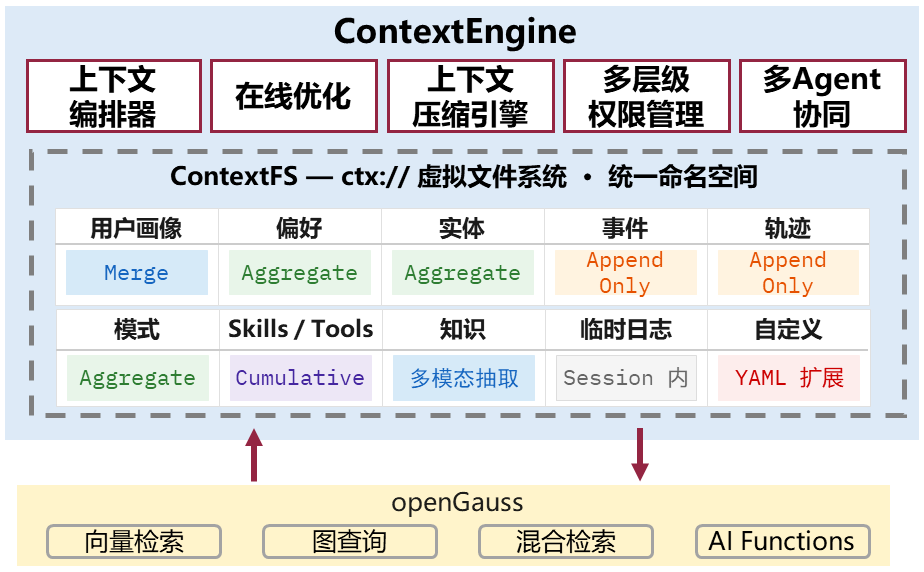
核心能力如下:
- 完整的上下文生命周期管理,实现上下文全流程精细控制,避免记忆越管越乱。
- 基于数据库的虚拟文件系统,统一数据命名空间,实现Agent读取亲和。
- 跨Agent记忆共享,打通上下文传递链路,提高团队效率。
- 基于DB First架构,原生支持向量、文本、图三种检索融合。
openGauss向量数据库,提供向量数据类型的存储、检索,使用熟悉的SQL语法操作向量,简化了用户使用向量数据库的过程。在处理大规模高维向量数据时,能够提供快速、准确的检索结果。适用于智能知识检索、检索增强生成 RAG(Retrieval-Augmented Generation) 、Agent记忆系统等各种复杂应用场景的智能应用。openGauss开源软件包获取链接:
https://opengauss.org/zh/download/?version=lts
鲲鹏加速库,提供基于鲲鹏平台优化的高性能算子加速能力,通过SIMD指令优化、缓存数据编排等充分发挥鲲鹏算力,实现性能倍增。BoostKit文档说明链接:
https://www.hikunpeng.com/document/detail/zh/kunpengboostkit/overview/index.html
优势分析
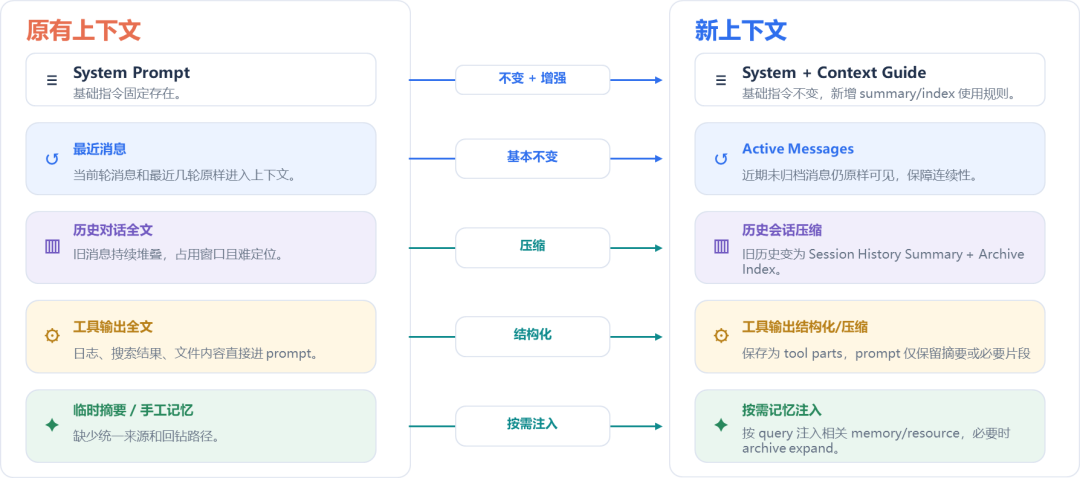
分层检索:参考渐进式披露思想,将记忆分层存储——先粗筛目录摘要,再按类别缩小范围,最终精确返回叶子记忆,确保检索准确性
按需加载:记忆按摘要、概览、全文三级粒度管理,根据问题相关度动态加载——强相关加载全文,弱相关仅加载摘要。保障记忆质量,降低Agent推理复杂度。
会话压缩归档:对历史消息进行摘要压缩,保留近期活跃消息,有效减少长会话冗余,降低Token开销。
上下文缓存:缓存历史工具执行结果,上下文仅保留引用、摘要与必要片段,既保证运行过程的低token开销,又实现必要时工具结果的准确查找。
混合介质检索:通过内存导航图、热点页缓存优化IO访问,实现内存+SSD混合介质检索,降低检索内存开销
全局内存检索:基于UB共享内存实现分布式全局内存索引,解决分片算法计算量超线性增长问题,应对百亿/千亿超大底库挑战。
Embedding模型CPU推理优化:通过矩阵外积实现提升GEMM算子利用率,基于向量化指令、数据切分优化Attention算子,实现Embedding模型鲲鹏CPU高效运行。
结语
鲲鹏记忆系统方案,把短期上下文、长期记忆、外部资源和技能经验统一成可检索、可压缩、可追溯的上下文资源。在长期运行、多轮交互、多工具调用、多会话切换中,让模型拿到“有用、可信、可追溯、不过量”的上下文。 实测证明鲲鹏记忆系统可实现Token开销下降50+%,任务成功率提升20%。
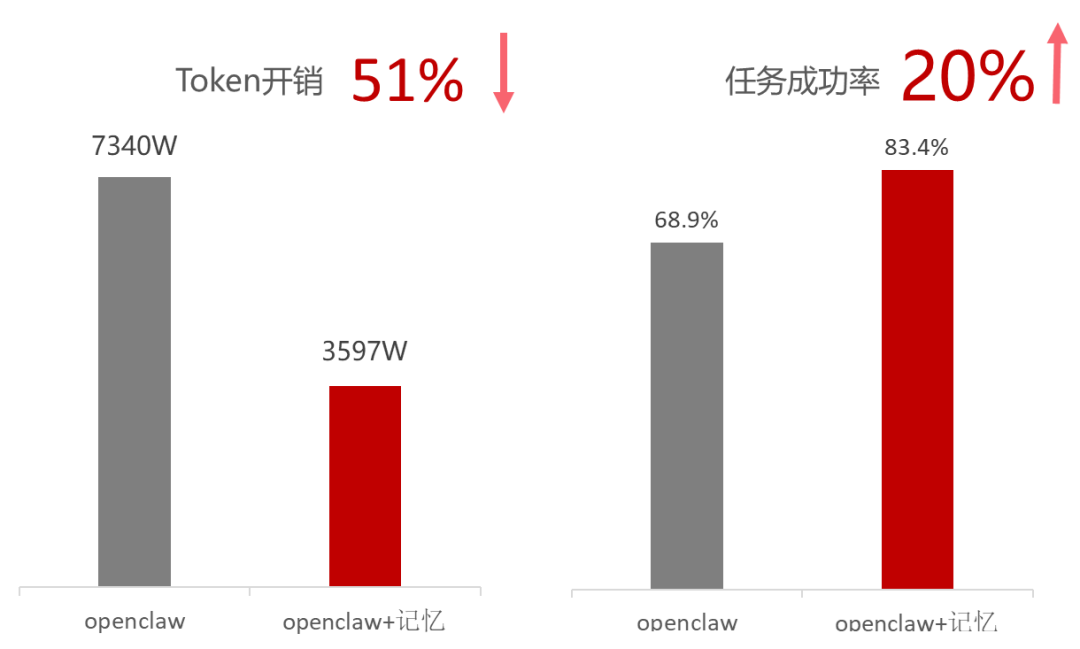
记忆系统端到端效果

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 1
1 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)