
构建CPU+xPU协同推理加速底座
推理场景PD/AF异构分离及调度,异构空闲算力有效填充;计算流、通信流多流并发、轻量级运行时,使能vllm-ascend在昇腾硬件上高效运行;Token级传输及小包聚合,有效提升DSA模型长序列场景吞吐。
特性介绍
长输出、多并发场景,受显存影响出现暂停,CPU侧资源则出现空闲等情况;单算子并发效率不高,图模式padding组图造成资源浪费,灵活性受限;长序列推理需实现解码阶段KV在DDR/片上内存swap,当前以block为粒度放大搬移数据量,恶化PCIe/UB(UnifiedBus)等总线带宽不足问题。
基于鲲鹏+昇腾+openEuler,实现CPU+NPU在算力协同、算子下发效率、灵活性、内存协同多维度优化,有效解决以上问题。
算力协同:通过openEuler社区sysHax特性,根据xPU负载情况,基于vllm PD分离技术深度优化,将部分decode任务卸载到CPU,实现中小模型LLM推理吞吐量提升;基于MoE模型AF分离技术深度优化CPU算力填充部分MoE专家任务,attention计算保留在GPU,实现并发量提升。
轻量运行时:通过openEuler社区轻量级Transformer模型运行时xlite,基于vllm-ascend在GraphWrapper层面及算子层面结合内深度优化,实现多流并发(计算流、通信流),有效避免Python的GC、线程等干扰,灵活调度缓解图算子模式padding 带来的算力浪费,目前支持Qwen系列、Llama系列、DeepSeek-R1、GLM等模型。
内存协同:针对DS/GLM模型DSA技术特点,全量KV保存在DDR,解码过程从DDR 按需搬移KV至片上内存特点,基于vllm /vllm-ascend增强,提供KV Token级搬移(按需搬移)及小包聚合,有效提升解码阶段从DDR搬移至片上内存的效率。
优势分析
面向传统单算子模式,由于Python锁原因,OS底噪干扰问题,造成xPU利用不高,存在典型Host Bound问题;面向图模式,在实例启动时根据BS数量固定组图,难以根据BS动态调整,灵活性不足。
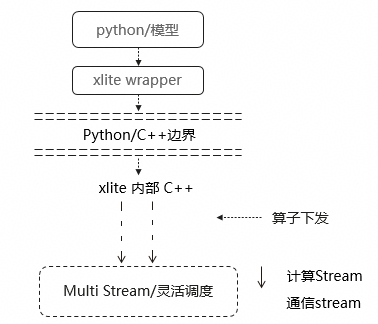
通过轻量级运行时与vllm-ascend 结合,实现多流并发(计算流、通信流)对算子下发时延进行掩盖,资源隔离有效避免Python的GC、线程等干扰,无复杂Host tiling计算,实现算子力度消除Host Bound,灵活调度缓解图算子模式padding 带来的算力浪费。
单机少卡中小模型推理场景,算力填充非实时离线批量推理吞吐提升5~25%+;实时推理场景并发(BS)提升5~10%;卡多多场景,多并发波动场景,吞吐提升10%以上。
结语
鲲鹏+xPU异构算力底座,面向vllm/sglang等推理框架,聚焦PD/AF 异构算力协同,kv swap传输,算子层级调度,有效消除Host Bound,实现推理场景相同硬件规格资源利用率提升。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 1
1 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)