
基于MindIE SD进行vLLM-Omni Wan2.2性能优化实践
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161601003
1. 背景与意义
在全模态模型快速演进的背景下,推理框架不仅需要支持多种模态的统一调度,还需要针对不同硬件架构进行深度优化。面向昇腾 NPU,vLLM-Omni 与 MindIE SD 分别从框架编排和硬件亲和优化两个层面协同加速:前者提供原生全模态推理框架与复杂工作流编排能力,后者提供昇腾亲和的底层算子、算法与并行优化能力,共同提升全模态模型的推理性能。
2025年在12月1日,vLLM社区发布了首个支持原生全模态的推理框架vLLM-Omni。(https://github.com/vllm-project/vllm-omni)vLLM-Omni继承了vLLM 在 AR LLM 阶段的能力,并将文本生成扩展到文本、图像、视频、音频等输入输出混合的全模态和非自回归推理领域,打破vLLM单一模态局限。同时vLLM-Omni支持单请求触发多异构模型组件的复杂工作流编排,例如多模态编码、自回归推理、扩散式多模态生成等场景。
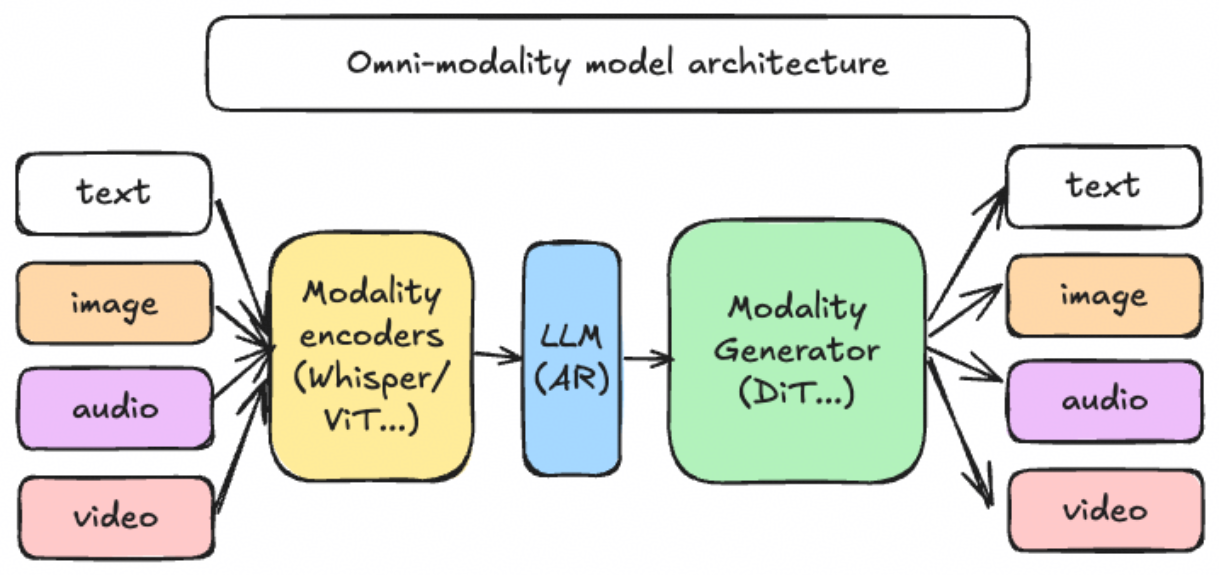
MindIE SD(Mind Inference Engine Stable Diffusion)是MindIE的视图生成推理组件(https://gitcode.com/Ascend/MindIE-SD),专注于提供昇腾亲和的多模态生成关键融合算子、量化/稀疏算法、以存代算、多卡并行等策略,旨在构建昇腾亲和的多模态加速能力,配合业内开源框架(如vLLM-Omni等),实现多模态推理在昇腾上的极致加速。
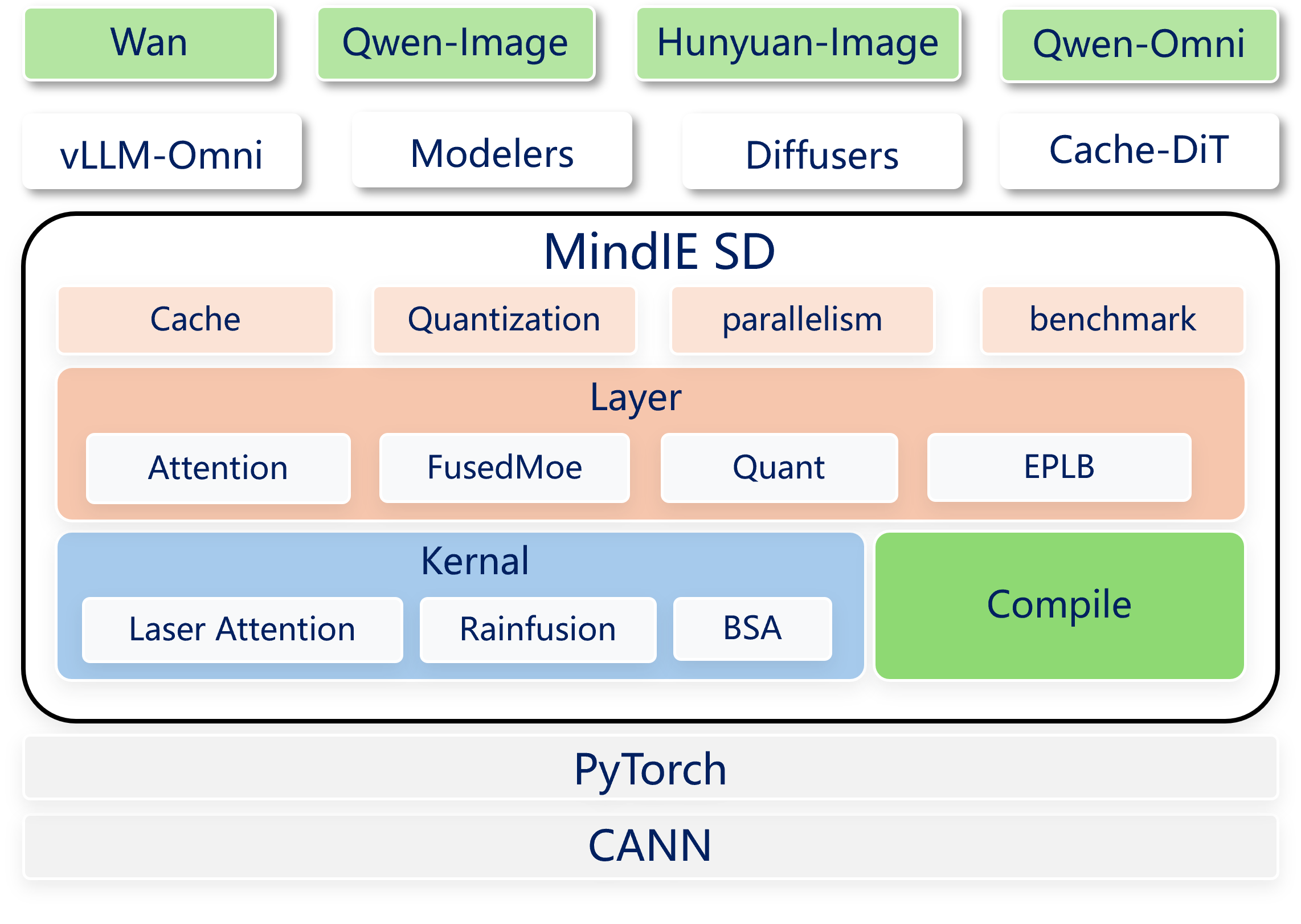
作为加速后端, MindIE SD已完成对vLLM-Omni中主流扩散模型的极致性能优化,如Wan2.2、Qwen-Image等。本文将基于vLLM-Omni Wan2.2介绍MindIE SD的加速能力,使能MindIE SD优化后,端到端推理性能极大提升。
2. 环境版本
基础环境配置
- 硬件平台: G8600(A2-A+X架构,16卡×64GB)
- 操作系统: Ubuntu 22.04
- 驱动版本: 25.2.0
- Python版本: 3.11
软件依赖版本
| 组件 | 版本要求 |
|---|---|
| CANN | 8.5.1 |
| PyTorch | 2.9.0+cpu |
| torch-npu | 2.9.0 |
| vLLM | 0.20.1.empty |
| vLLM-Omni | 0.20.0 |
vLLM-Omni镜像获取:https://quay.io/repository/ascend/vllm-omni?tab=tags
3. 性能优化流程
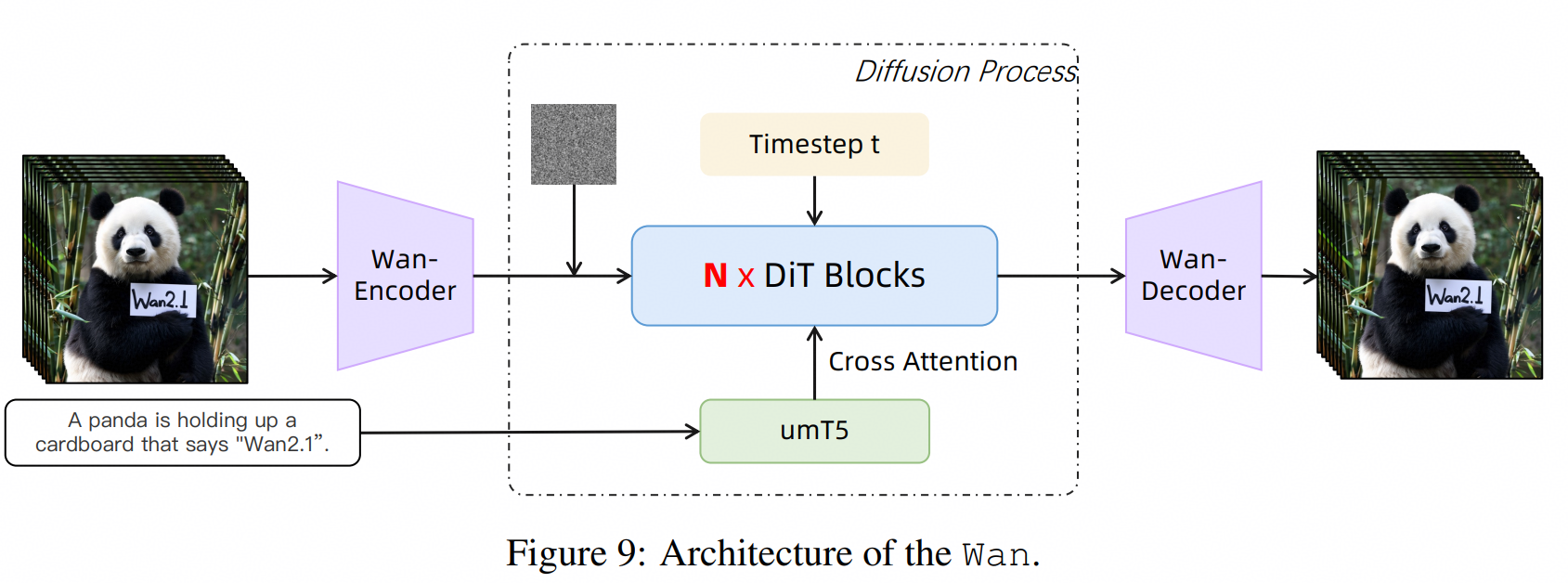
Wan2.2是一个视频生成模型,支持文生视频、图生视频等
1. Wan2.2 结构
Wan2.2首次将混合专家模型(MoE)架构引入视频扩散模型,解决了传统视频生成中 Token 过长导致的计算资源消耗大、推理速度慢的核心痛点。
MoE的本质是将模型拆分为多个专家网络,通常会将传统 Transformer 模型中的前馈网络 (FFN) 层替换为稀疏 MoE 层,并通过门控网络或路由来决定哪些词元(token) 被分发到哪些专家,实现稀疏化计算。
Wan2.2的MoE架构有些许不同,不是 常规 token-level router + top-k expert FFN,而是更粗粒度的 timestep-level / stage-level MoE:整个 denoising 过程被切成两个阶段,前半段用 high-noise expert,侧重于整体布局,后半段用 low-noise expert,细化视频细节。两个专家DiT结构相同,仅权重不同,每个专家模型约有 14B参数,总共 27B参数。两个专家之间的过渡点由timestep决定,并通过boundary_ratio(默认0.875)控制何时切换为low_noise_model。
Wan2.2的MOE结构如下:

Wan2.2的DiT结构如下:
2. 优化点分析
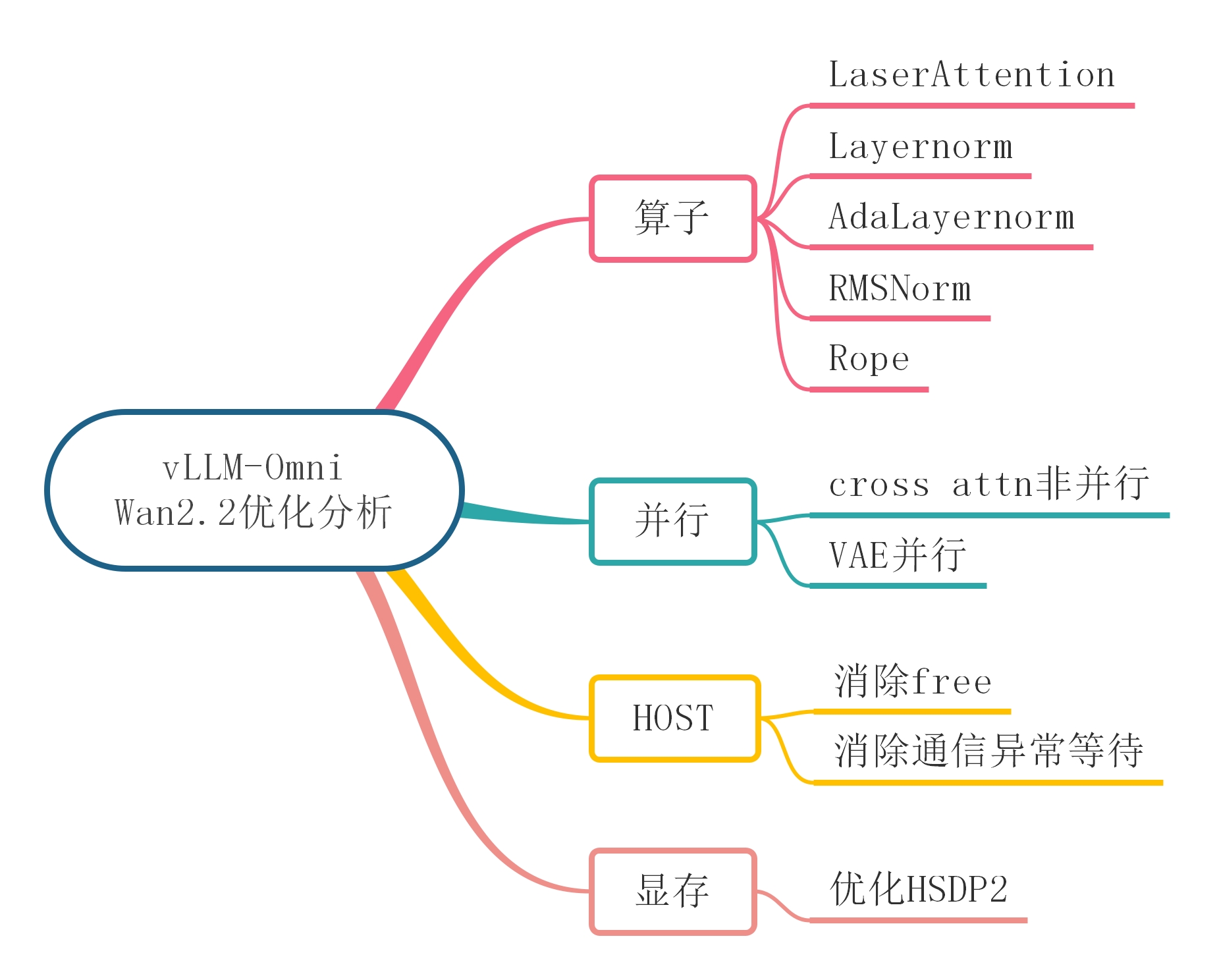
1. 算子优化
1)如优化点分析,vLLM-Omni中Wan2.2的Layernorm、AdaLayernorm、RMSNorm、Rope均为小算子实现,将其替换为MindIE SD中的高性能融合算子。
2)视频生成是典型的长序列场景,Flash Attention算子通常会触发vector bound导致性能较差,MindIE SD提供高性能的Laser Attention算子,通过vector转cube计算等操作,实现Flash Attention单算子极大的性能提升。
2. 并行优化
1)DiT Ulysses SP并行
Ulysses并行的原理是进入DiT时,将hidden states在Token/sequence维度进行切分,计算完成后使用all-gather收集完整的sequence。
非attention部分按照序列并行进行计算,每张卡只计算部分的token;
attention部分通过前后两次all-to-all将序列并行转化成head并行,每张卡只计算部分head的Attention。
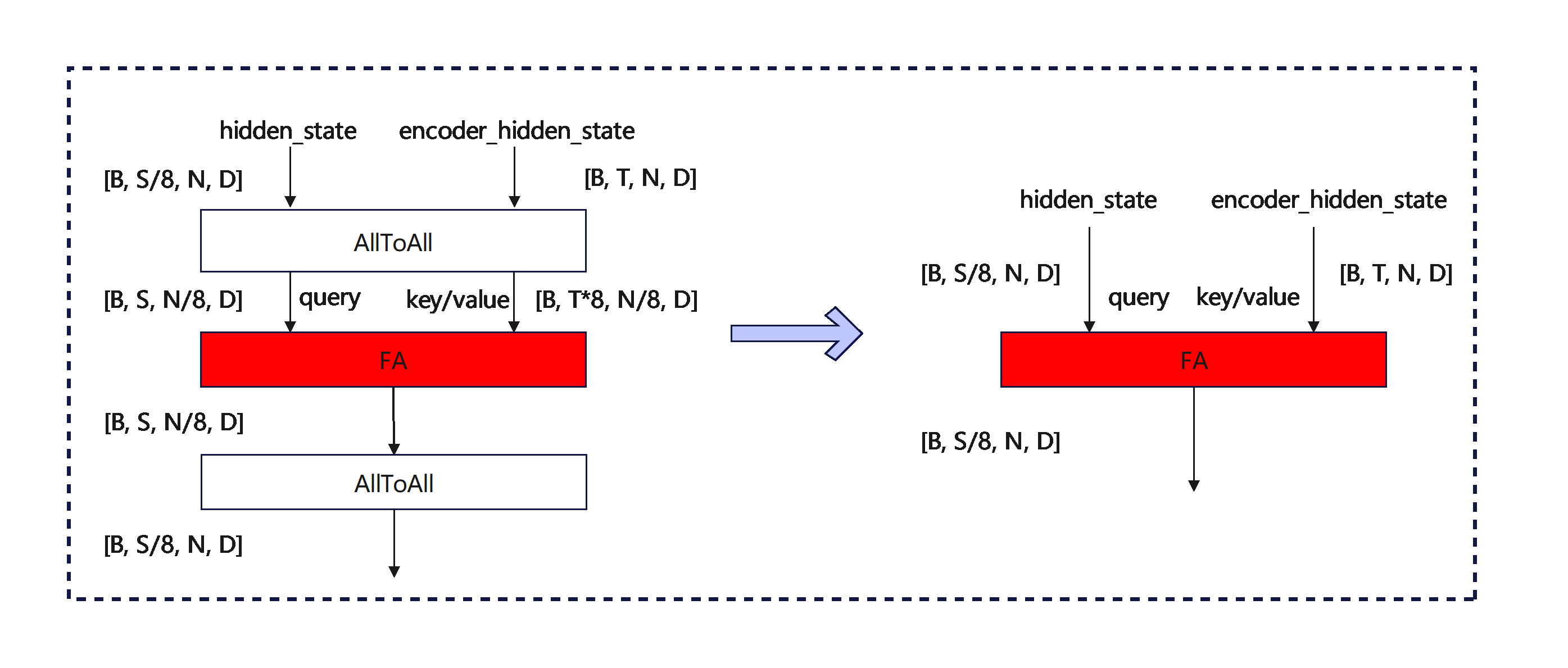
vLLM-Omni中Self-Attention和Cross-Attention均进行了Ulysses并行
但实际上,Cross-Attention无需sp,因为encoder_hidden_state是完整的sequence,并不需要通过all-to-all收集完整的sequence。另一个理由是encoder_hidden_state的seqlen=512很短,all-to-all会带来额外的通信开销,得不偿失。
因此,此处的优化是关闭了Cross-Attention的ulysses sp
2)VAE Patch并行
VAE encode/decode 的并行原理是将大图像或视频 latent 按空间/时间 patch 切成多个块,分发到多张卡并行处理;
为了保持卷积边界等价,每个 tile 会带一圈 overlap,计算完后再裁掉边界并拼回完整结果
VAE的峰值显存通常较大,通过patch并行大大降低峰值显存
3. 显存优化
在说显存优化之前我想先说说
为什么视频生成模型对ulysses并行情有独钟?
视频生成模型的特点:权重不大(10B+)、序列长、激活峰值大
常见的并行手段无非分为三种:切权重(TP)、切激活(Ulysses SP、Ring SP、CP)、切数据(DP、CFGP)
在视频生成模型中通常不选择TP,原因是TP只能用来切分权重,无法缓解长序列和激活大的问题,某些情况下TP切Head后甚至会影响Matmul算子的计算效率。因此通常选择做sequence parallel,如ulysses,直接对序列进行切分。
不切分TP,每张卡加载完整的权重,显存是否够用?
FSDP2原理:
初始化时,对DiT的每个Block权重进行切分。
计算前,对该Block权重前进行all_gather,计算后reduce_scatter
多流异步掩盖:计算block n时预取 block n+1的权重,只要block n的计算耗时>预取权重的all_gather耗时,就可以完全掩盖。
视频生成模型的长序列场景的block计算耗时通常很长
因此Wan2.2中,使用FSDP2+Ulysses SP8的并行方式,兼顾权重和激活的切分。
实际使能FSDP2的过程中遇到一些问题,显存并没有降低,采集显存快照发现显存随着block累积。
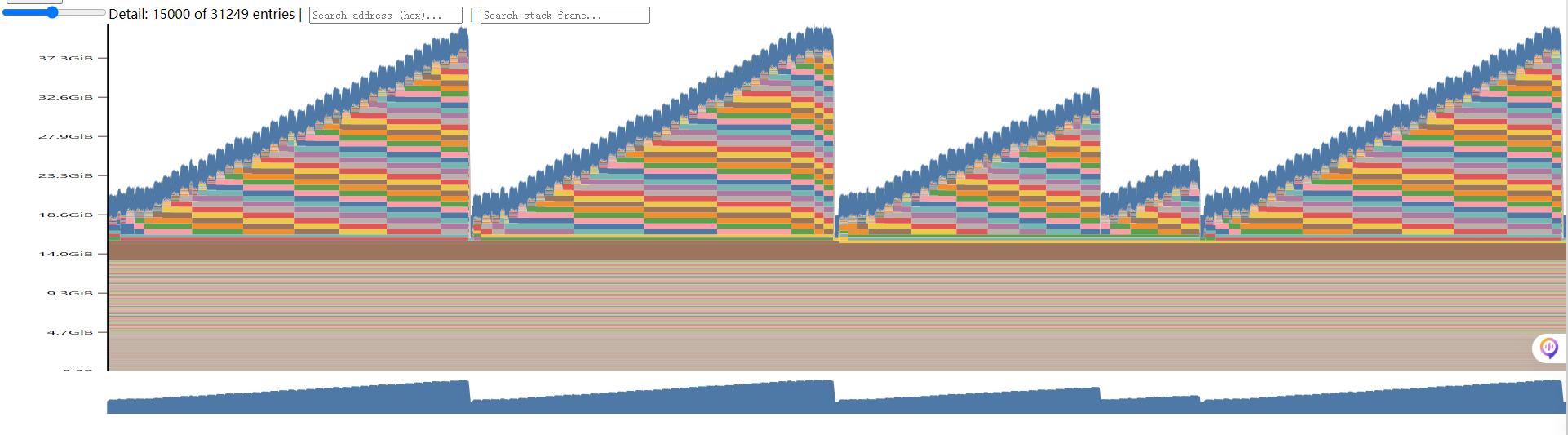
原因:根源在于FSDP2的多流异步机制。每个Block单独起了一个stream来实现异步集合通信,多个流的显存在DiT推理完成后才会释放,导致一个时间步内多个流占用的显存无法复用
解决:NPU上,需开启跨流内存复用的环境变量 export MULTI_STREAM_MEMORY_REUSE=2
4. Host优化
vLLM-Omni中,一个视频生成请求的端到端耗时包含:图片/视频前处理、Pipeline中算子执行耗时、算子下发耗时、后处理、MP4编码。采集L0的profiling,发现整网存在4处free(如下图,从左到右记为free1, …, free4)
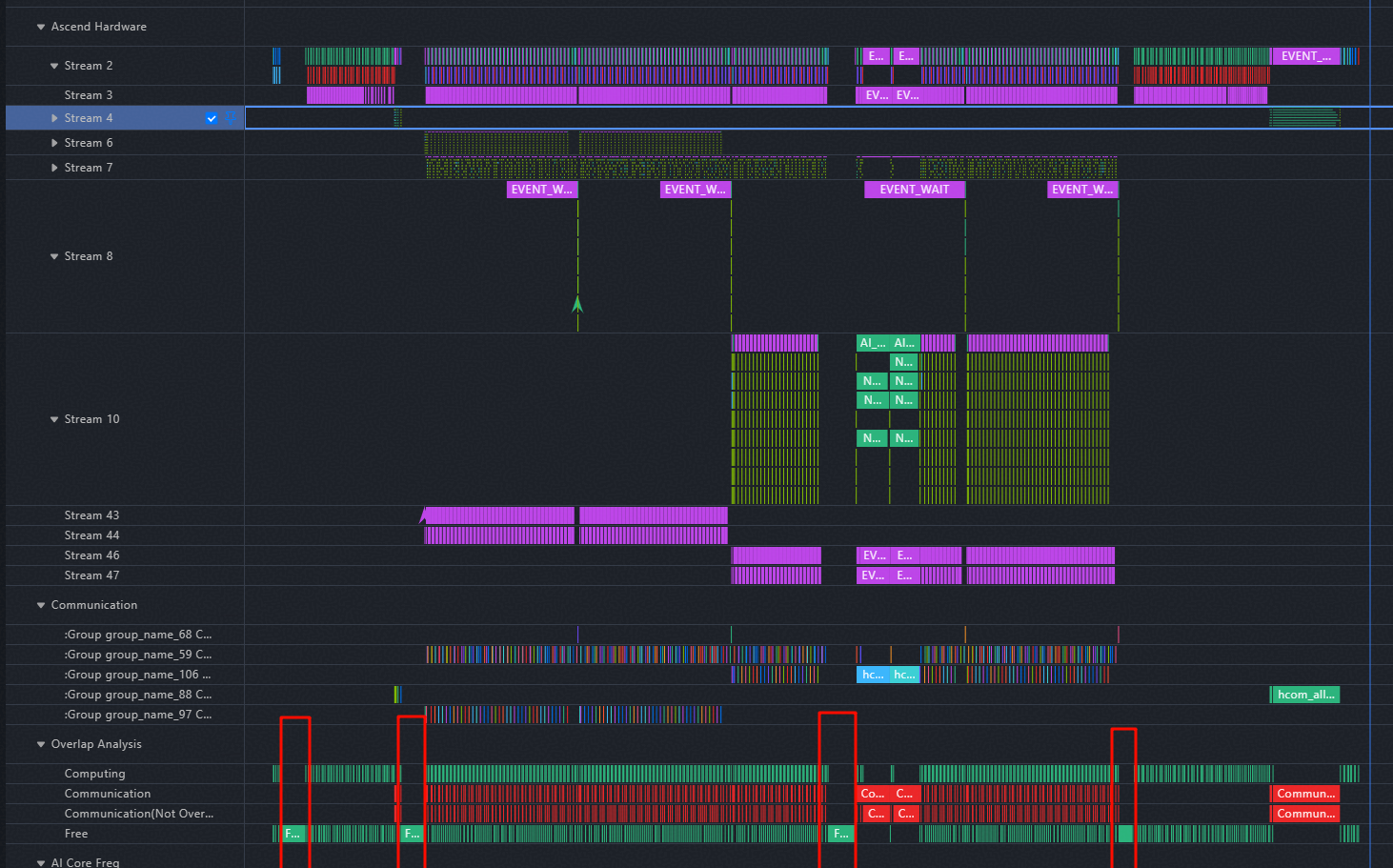
free1: CPU上进行图片预处理,改为在NPU上进行,仍有一段free是img tensor to npu,无法避免。可消除一半。
free2: CPU上生成mask_latent_size,已改为在npu上生成。可完全消除
free3: 由FSDP2导致的显存触顶引入,修复后已消除
free4: 模型代码中,DiT与VAE之间进行的empty cache,为保持兼容性,暂忽略
消除前后对比:

5. 插帧优化
由于attention的计算量与序列长度呈平方增长关系,长时高分辨率视频的生成成本往往非常高。
在vLLm-Omni中,我们引入视频插帧模型 “RIFE”(https://huggingface.co/elfgum/RIFE-4.22.lite),对视频进行后处理插帧,大大减少高帧率视频的生成成本。
4. 性能优化结果
1. 环境准备
vLLM-Omni容器创建
步骤1:在拉起容器镜像前,请先确保昇腾驱动已经正常安装,可使用 npu-smi info命令进行查看
步骤2:使用如下命令拉起 vLLM-Omni 容器镜像:
# Get vLLM-Omni Image from https://quay.io/repository/ascend/vllm-omni?tab=tags
export IMAGE=quay.io/ascend/vllm-omni:v0.20.0
docker run --rm \
--name vllm-omni-npu \
--shm-size=10g \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it $IMAGE bash
MindIE SD安装
# 编译MindIE SD
git clone https://gitcode.com/Ascend/MindIE-SD.git && cd MindIE-SD
pip install build wheel
python -m build --wheel --no-isolation
# 安装MindIE SD
cd dist
pip install mindiesd-*.whl
模型权重下载
https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B-Diffusers
2. 在线推理
执行拉起服务化脚本:
export PYTORCH_NPU_ALLOC_CONF='expandable_segments:True'
export TASK_QUEUE_ENABLE=2
export CPU_AFFINITY_CONF=1
export TOKENIZERS_PARALLELISM=false
export MULTI_STREAM_MEMORY_REUSE=2
export MINDIE_SD_FA_TYPE=ascend_laser_attention
vllm serve /path/to/Wan2.2-I2V-A14B-Diffusers/ \
--omni \
--port 8099 \
--usp 8 \
--use-hsdp \
--vae-patch-parallel-size 8 \
--vae-use-tiling
执行CURL命令:
curl -X POST http://localhost:8099/v1/videos \
-F "prompt='Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside.'" \
-F "input_reference=@/path/to/i2v_input.JPG" \
-F "size=720x1280" \
-F "fps=12" \
-F "num_frames=61" \
-F "guidance_scale=5.0" \
-F "flow_shift=5.0" \
-F "num_inference_steps=40" \
-F "enable_frame_interpolation=true" \
-F "frame_interpolation_exp=1" \
-F "frame_interpolation_scale=1.0" \
-F "seed=42"
5. 总结
本文通过Wan2.2入手,介绍了视频生成模型的结构和常用的优化思路,以及如何将MindIE SD中的加速能力使能到vLLM-Omni框架中。并且基于vLLM-Omni镜像部署Wan2.2的在线服务。
未来,MindIE SD将持续为vLLM-Omni等主流框架贡献昇腾亲和的极致加速能力,也欢迎大家参与MindIE SD社区和vLLM-Omni社区的代码贡献!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)