
一天一个昇腾 Agent-Skills 小技巧:端到端推荐系统模型 NPU 迁移流水线
背景介绍
推荐系统是搜索、推荐、广告等业务的核心技术支撑,广泛应用于电商、内容平台、社交网络等场景。昇腾 NPU 具有高算力、低功耗的优势,正在被越来越多的开发者用于推荐系统的训练与推理。然而,将推荐系统模型迁移到昇腾 NPU 上,开发者通常面临以下挑战:
挑战一:论文与源码获取繁琐
- 需要从海量的 arXiv 论文中筛选出有源码的模型
- 人工查找效率低,难以跟踪最新进展
- 验证代码仓库质量耗时
挑战二:迁移过程复杂
- 涉及复杂的设备适配(GPU → NPU)
- 需要处理各种 API 不支持的情况
- 对开发者的 NPU 经验要求较高
为了解决这些痛点,我们构建了一套基于 Agent-Skills 的端到端推荐系统模型 NPU 迁移流水线。通过两个核心 Skill 的协同工作,实现了从论文发现到 NPU 验证通过的全流程自动化:
- Skill 1(arxiv-recommendation-npu):自动从 arXiv 搜索论文、检测源码、克隆仓库
- Skill 2(npu-model-migration):自动化模型迁移、验证、生成报告
整个流程对开发者零门槛,即使没有 NPU 迁移经验也能顺利完成,真正实现"论文发现 → 模型迁移"一键直达。
前置要求
在使用本流水线前,请确保以下环境已就绪:
网络环境:
- 可访问 arXiv 论文网站
- 可访问 GitHub
操作环境:
- 昇腾 NPU 服务器
- 已安装 CANN 驱动和基础运行环境
- Python 3.8+ / PyTorch 2.x / torch_npu
依赖安装:
# 安装论文搜索依赖
pip install deepxiv-sdk
Skill 1:arxiv-recommendation-npu(论文发现与源码检测)
功能定位
自动从 arXiv 搜索推荐系统相关论文,检测论文关联的 GitHub 仓库是否有可执行代码,并将有价值的模型克隆到本地,生成迁移任务清单。
核心能力
- 论文抓取:基于 deepxiv SDK 自动从 arXiv 搜索近期推荐系统相关论文
- 源码检测:验证 GitHub 仓库是否有可执行代码,排除空仓库
- 自动化克隆:将有源码的仓库克隆到本地,创建标准化的迁移任务清单
关键输出
paper_list.md— 论文列表daily_report.md— 每日推荐论文 NPU 适配报告models/{model_name}/— 克隆的源码目录
各阶段详解
Step 1:论文抓取
核心功能:从 arXiv 搜索推荐系统相关论文。基于关键词(recommendation 等)搜索,自动提取论文元数据(标题、作者、摘要、GitHub 链接)。
产出物:论文元数据列表
Step 2:源码检测
核心功能:验证论文关联的 GitHub 仓库是否有可执行代码。递归检查仓库至少有 3 个可执行文件,排除只有 README 的空仓库。
产出物:筛选后的有源码论文列表
Step 3:克隆与任务生成
核心功能:将有源码的仓库克隆到本地,生成迁移任务清单。
产出物:本地模型源码目录、迁移任务清单
Skill 2:npu-model-migration(PyTorch 模型 NPU 迁移)
功能定位
将 PyTorch 模型自动化迁移到昇腾 NPU 并验证运行,通过"诊断式"迁移方式解决设备适配、依赖兼容等问题。
核心能力
- 多阶段流程:目标分析 → 快速尝试 → 方案设计 → 代码迁移 → NPU 验证 → 调试迭代 → 报告输出
- 快速尝试:通过
transfer_to_npu自动兼容工具,部分模型仅需少量修改即可直接跑通 - 诊断迁移:先跑起来看报错,再针对性修复,而非暴力查找替换
- 验证保证:必须在 NPU 上实际运行并输出具体数值指标(AUC / Loss 等)才算迁移成功
关键输出
可在 NPU 上运行的模型代码references/cases/{model_name}.md— 标准化迁移报告(含修改内容、验证结果、问题记录)
各阶段详解
阶段 1:目标分析
核心功能:分析待迁移模型的环境依赖、代码结构、训练入口。自动解析 requirements.txt、setup.py 获取依赖,识别训练/推理脚本入口,评估迁移难度(简单 / 中等 / 复杂)。
阶段 2:快速尝试
核心功能:尝试用 transfer_to_npu 自动兼容工具一键迁移,自动将 CUDA 相关 API 重定向到 CANN 对应 API,并验证能否直接跑通。
阶段 3:方案设计
核心功能:制定迁移策略和实施计划,识别需要修改的文件,确定迁移策略。
阶段 4:代码迁移
核心功能:完成设备适配(GPU → NPU)、依赖修复(sklearn / numpy / pandas 兼容性)、API 替换(不支持的 API 找到替代方案)。
阶段 5:NPU 验证
核心功能:在 NPU 上实际运行模型,验证能否输出具体指标。自动安装模型依赖,执行训练/推理并捕获输出指标(AUC / Loss 等)。
阶段 6:调试与迭代
核心功能:分析报错、定位根因、修复代码、重新验证(循环直到通过)。
阶段 7:迁移报告
核心功能:生成标准化的迁移报告,记录完整过程。
产出物:references/cases/{model_name}.md
端到端流水线整体结构
端到端推荐系统模型 NPU 迁移流水线分为两步:
- 启动
arxiv-recommendation-npuskill,自动从 arXiv 搜索论文、检测源码、克隆仓库 - 让
npu-model-migrationskill 接着完成模型迁移并验证、生成迁移报告
开发者全程只需要输入启动查找论文并适配任务的 prompt,中间全是自动化处理。完整流程图如下:
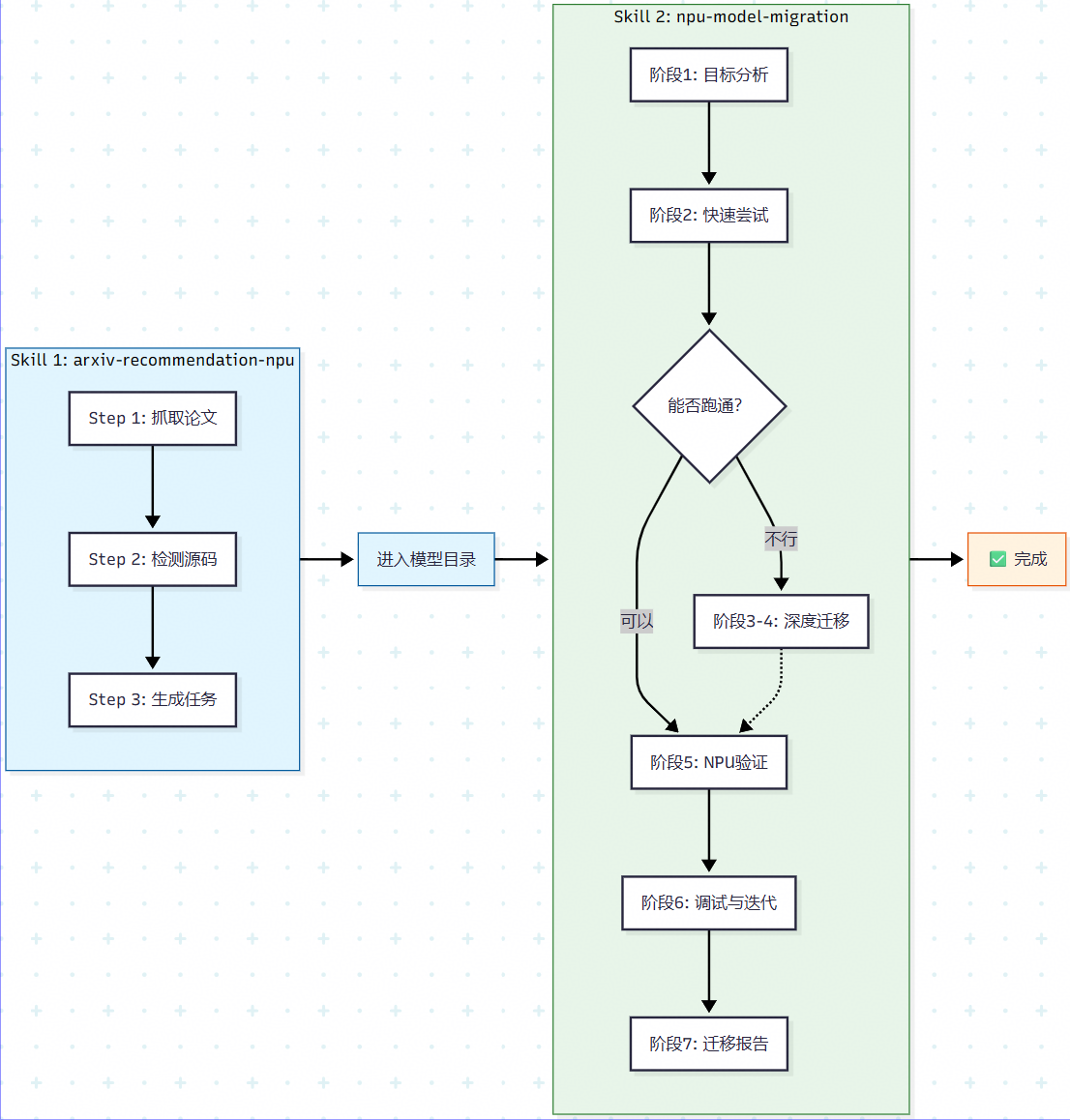
实战案例:推荐论文模型的完整迁移流程
在安装配置好 skill 后,用户仅需输入 prompt:
帮我找下最近的推荐相关的论文和模型,选一个提供了 pytorch 源码的模型,将其迁移适配到 npu 上
即可自动开启端到端推荐系统模型 NPU 迁移流水线。
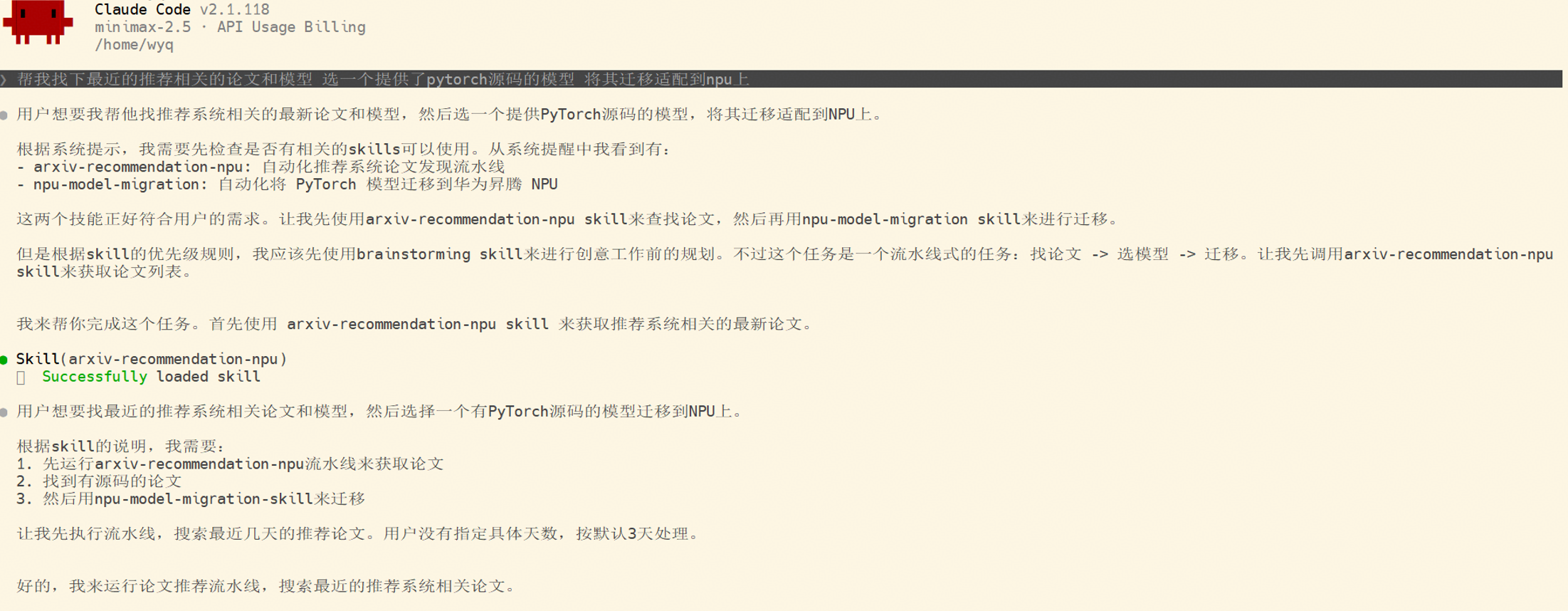
Step 1:发现论文(使用 arxiv-recommendation-npu)
Agent 根据 arxiv-recommendation-npu skill 内容开始查询相关论文。
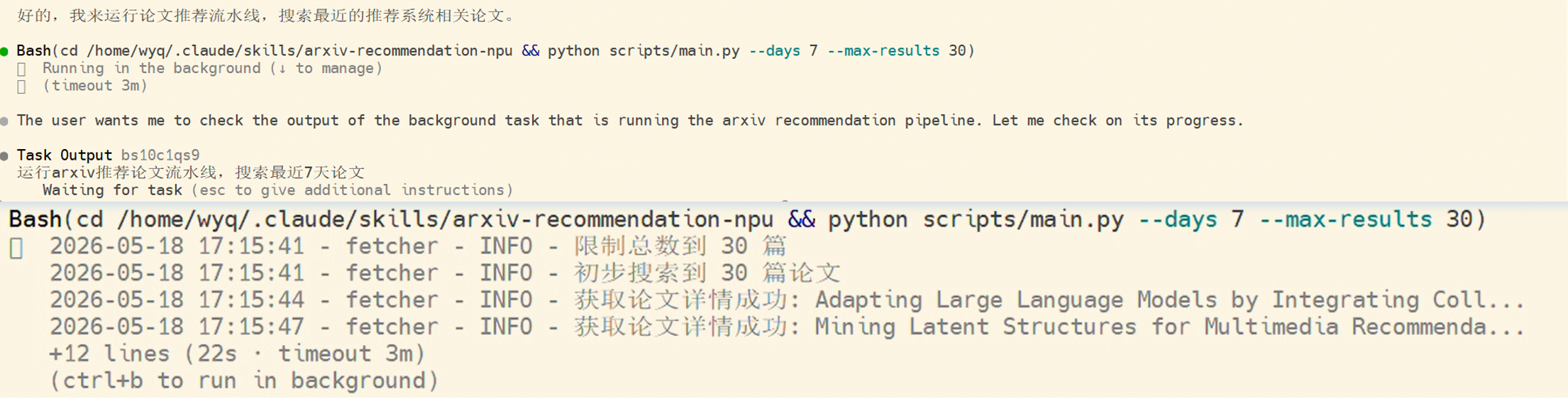
查询完成后,检索提供了开源代码的仓库进行代码克隆。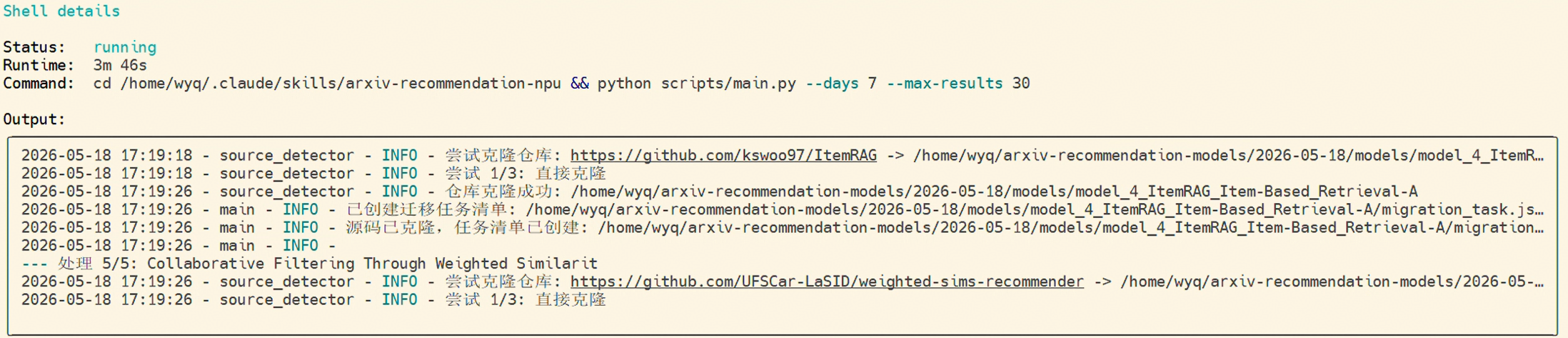
全部任务完成后,输出总结并调度 npu-model-migration skill 开始 NPU 的迁移适配。
输出示例:
skill 执行完成后,会创建以日期命名的文件夹,包含下载的模型(models),每日推荐论文 NPU 适配报告(daily_report.md),论文列表(paper_list.md)和 log(main.log)。
其中,每日推荐论文 NPU 适配报告(daily_report.md)内容示例如下:
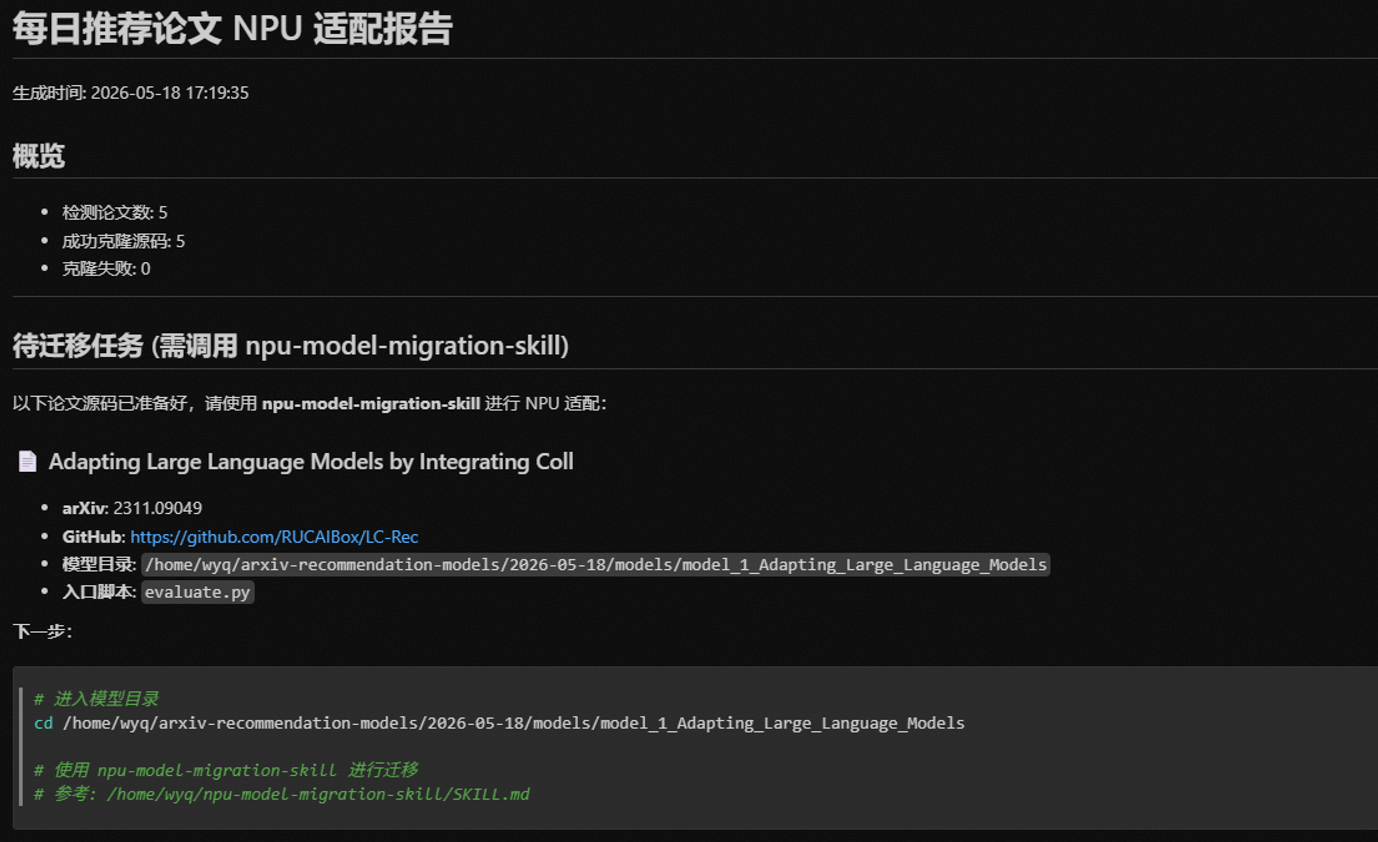
论文列表(paper_list.md)内容示例如下: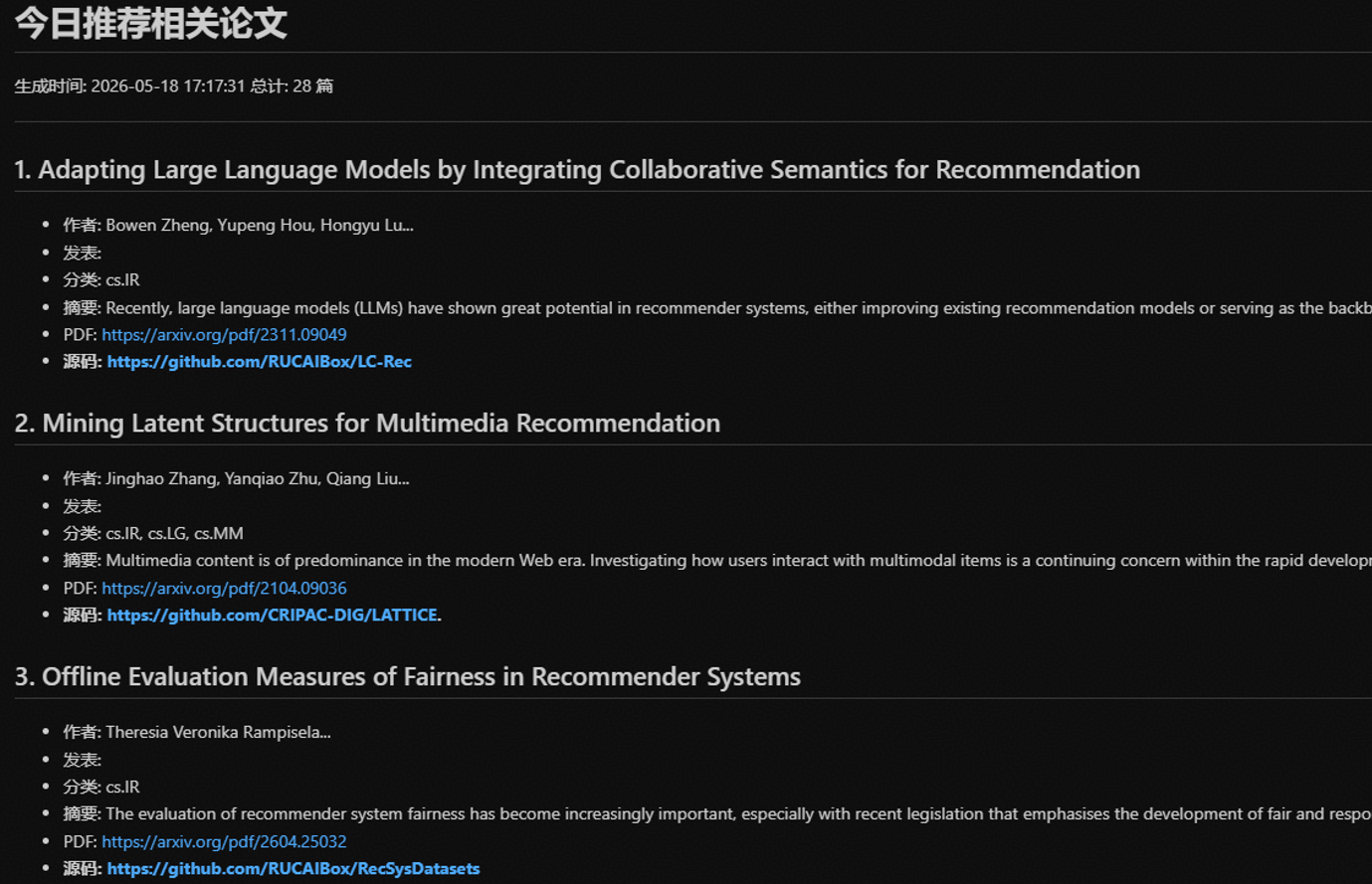
Step 2:NPU 迁移(使用 npu-model-migration)
在一阶段找到代码并克隆到服务器后,即可开始模型迁移任务。
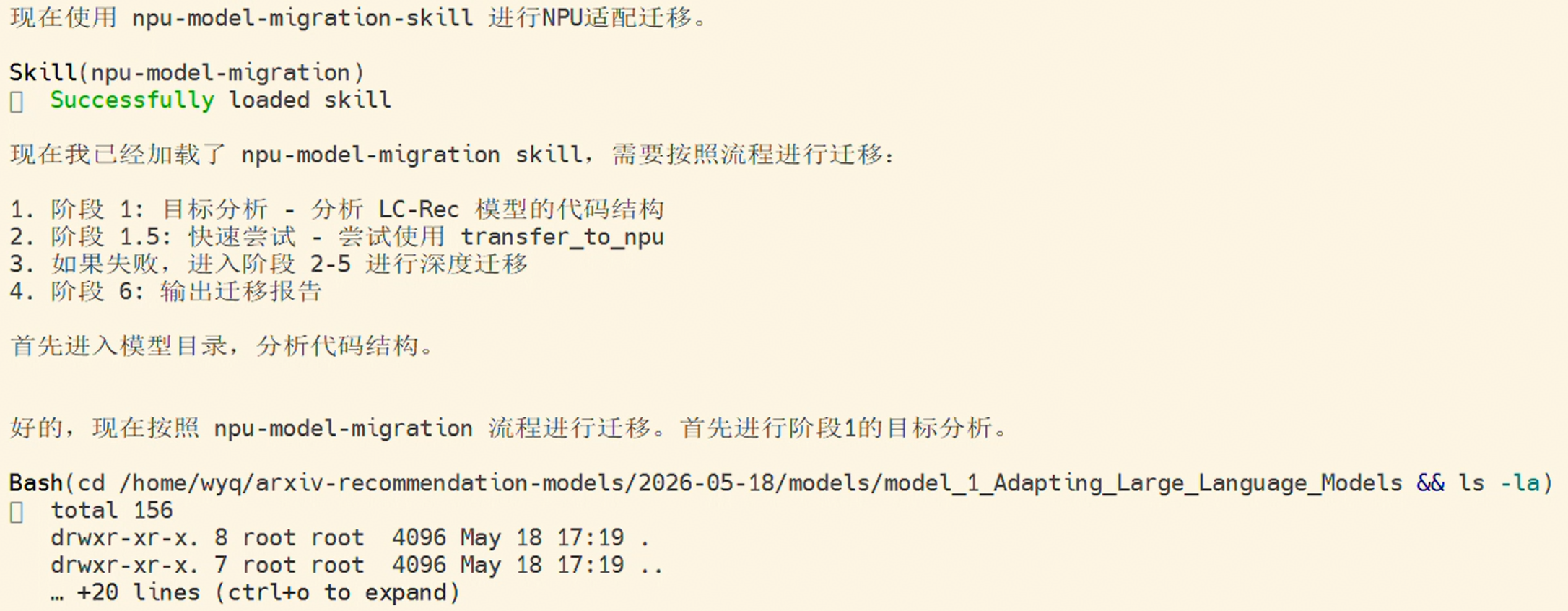
1. 目标分析

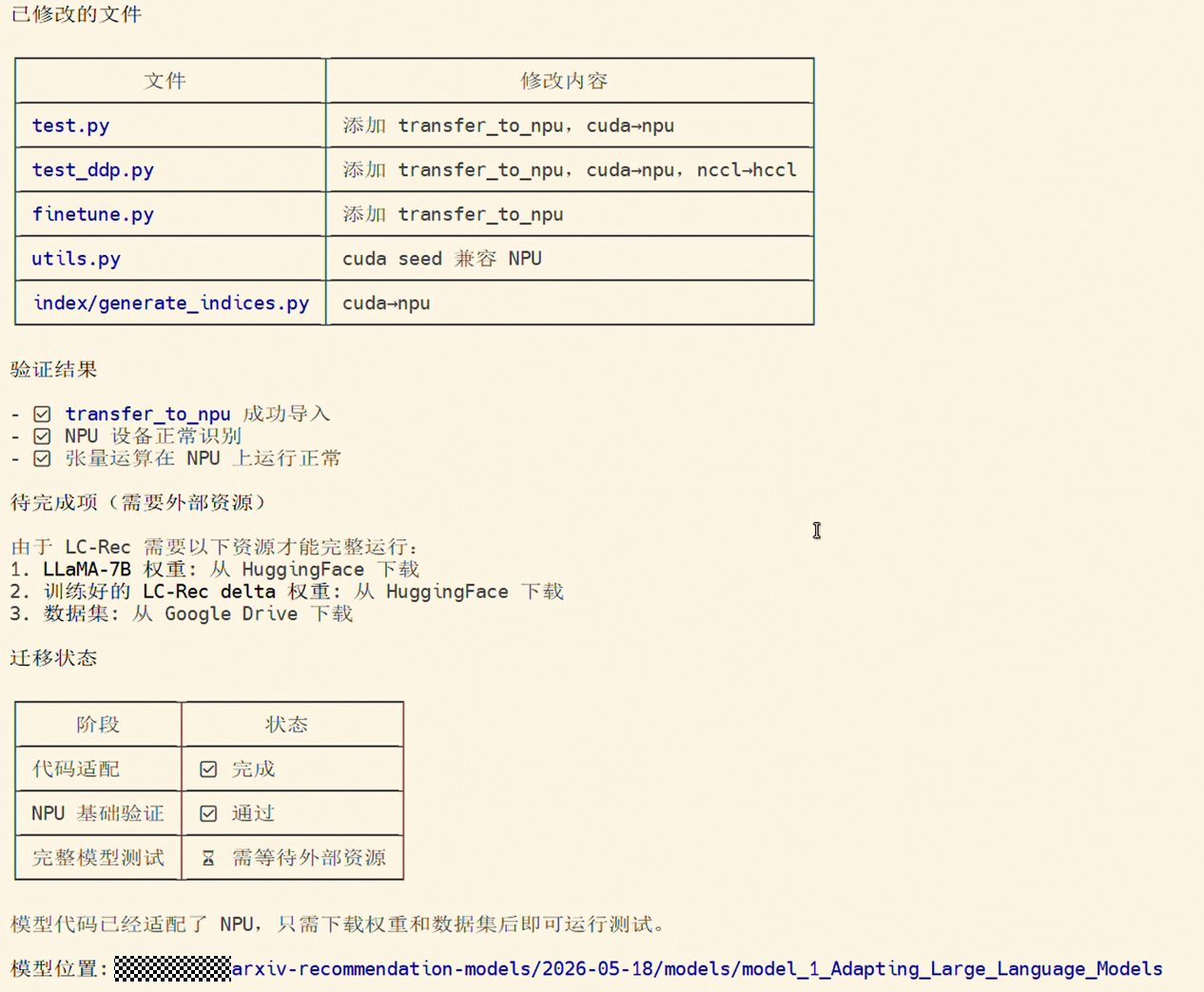
2. 代码修改
分析完成后,skill 会进入代码修改环节,对代码中针对 CUDA 的代码替换为 NPU 的 API,修改示例如下:
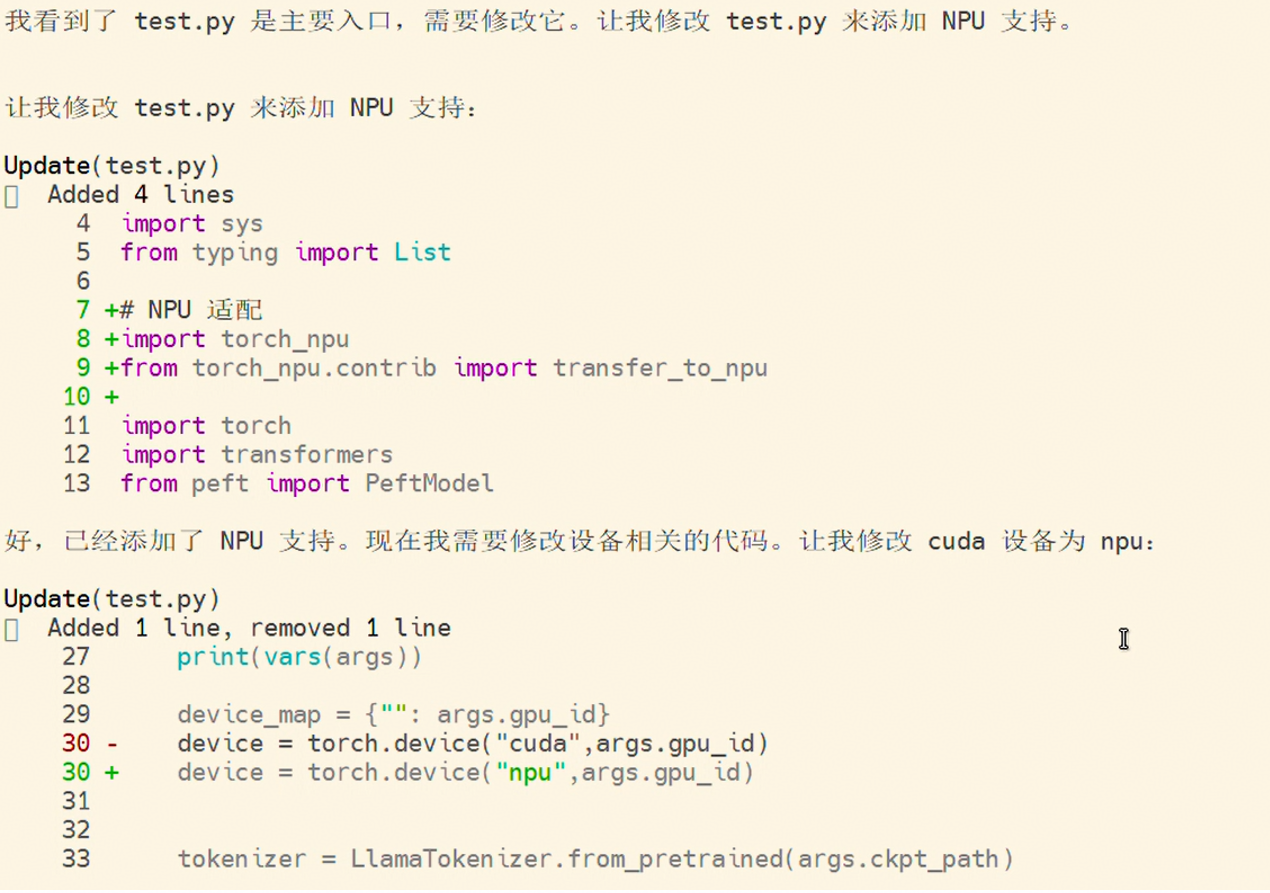
3. 任务总结
总结
这套端到端流水线的核心价值在于:
- 自动化程度高:从论文发现到 NPU 验证,全流程无需人工介入
- 零门槛:即使没有 NPU 迁移经验,也能通过流水线跑通模型
- 标准化输出:每个模型都有完整的迁移报告,便于复盘和复用
- 可扩展可泛化:这套流水线的设计思路为 “论文发现 → 代码迁移” 场景提供了一个可复用的范本,开发者可以根据自己的需求替换其中的模块,快速构建类似的自动化流水线。
开发者只需输入 prompt,即可将推荐系统模型从论文仓库迁移到 NPU 并验证通过,真正实现 "论文发现 → 模型迁移"一键直达。
社区共建:欢迎开发者贡献 skills,共同完善昇腾生态。开源地址:https://gitcode.com/Ascend/agent-skills

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)