
8×910B4-32G NPU服务器 vLLM-Ascend部署Docker安装报告
一、项目概述
一、项目概述
二、硬件环境确认2.1 NPU信息 |
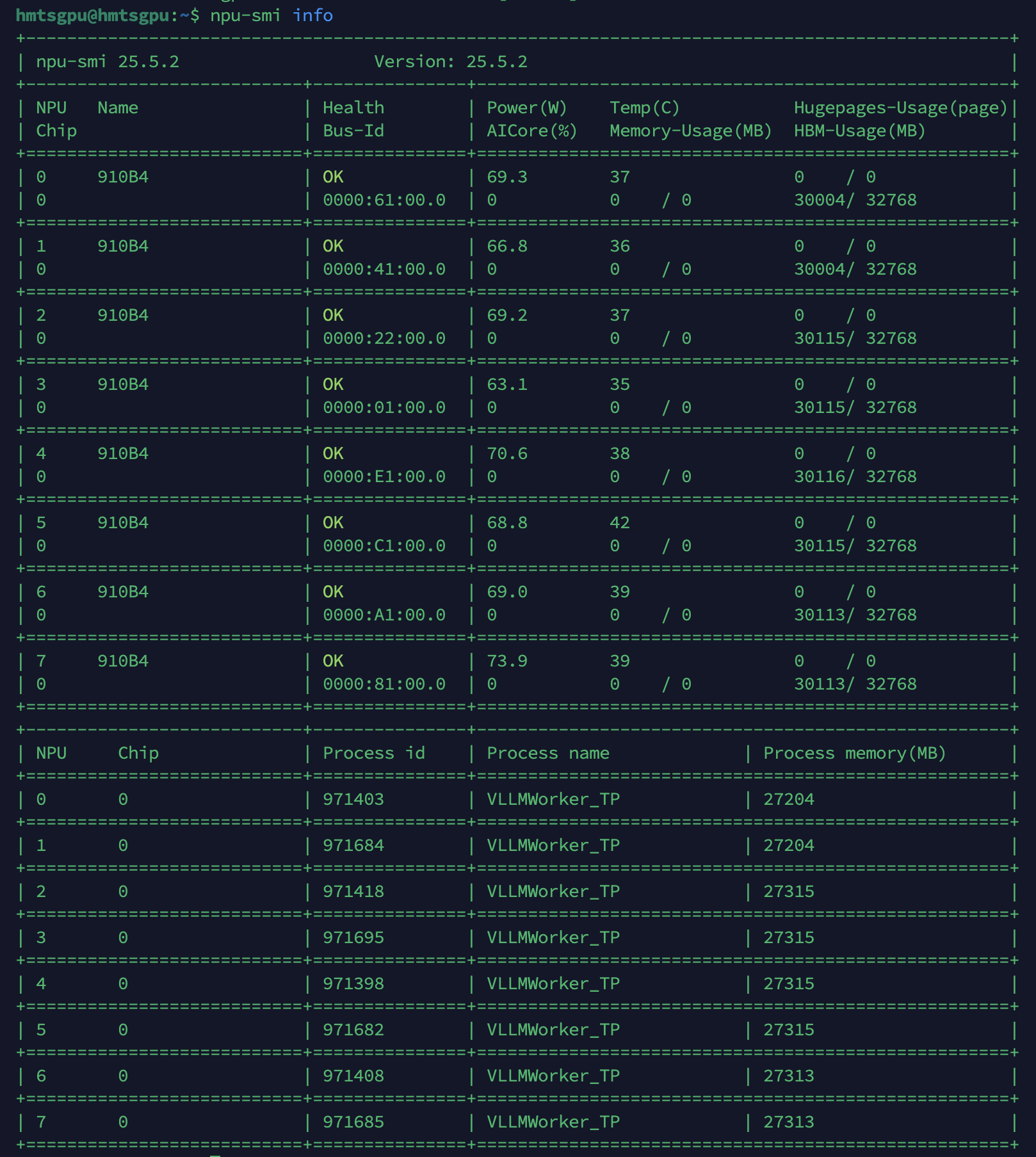

|
NUMA Node |
CPU范围 |
内存 |
分配NPU |
服务 |
|
0 |
0-31, 64-95 |
193GB |
NPU 0-3 |
Service 1 (NPU 0-1), Service 2 (NPU 2-3) |
|
1 |
32-63, 96-127 |
258GB |
NPU 4-7 |
Service 3 (NPU 4-5), Service 4 (NPU 6-7) |
三、Docker安装过程
3.1 安装Docker CE
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
安装结果: Docker version 29.5.3, build d1c06ef
3.2 配置用户权限
sudo usermod -aG docker $USER
newgrp docker
验证: docker run hello-world 成功输出
3.3 配置国内镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json << 'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://hub.rat.dev",
"https://docker.mirrors.ustc.edu.cn",
"https://dockerpull.org",
"https://docker.1panel.dev"
]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
四、vLLM-Ascend Docker镜像
4.1 镜像信息
|
属性 |
值 |
|
镜像源 |
quay.io/ascend/vllm-ascend:v0.18.0 |
|
国内加速 |
m.daocloud.io/quay.io/ascend/vllm-ascend:v0.18.0 |
|
镜像大小 |
~15GB |
|
内置Python |
3.11.14 |
|
vLLM版本 |
0.18.0+empty |
|
包含组件 |
vllm-ascend plugin, CANN驱动, PyTorch-NPU |
4.2 拉取命令
docker pull m.daocloud.io/quay.io/ascend/vllm-ascend:v0.18.0
结果: Status: Image is up to date
4.3 镜像验证
docker images | grep vllm-ascend
# m.daocloud.io/quay.io/ascend/vllm-ascend v0.18.0 ...
五、容器部署方案
5.1 部署架构
采用4容器×2NPU架构,严格按NUMA拓扑隔离:
┌─────────────────────────────────────────────┐
│ 8× 910B4 NPU Server │
├─────────────────────────────────────────────┤
│ NUMA 0 (CPU: 0-31,64-95 | Mem: 193GB) │
│ ├─ Container 1: NPU 0,1 → Port 8000 │
│ └─ Container 2: NPU 2,3 → Port 8001 │
├─────────────────────────────────────────────┤
│ NUMA 1 (CPU: 32-63,96-127 | Mem: 258GB) │
│ ├─ Container 3: NPU 4,5 → Port 8002 │
│ └─ Container 4: NPU 6,7 → Port 8003 │
└─────────────────────────────────────────────┘
5.2 容器创建参数
所有容器共享以下公共配置:
|
参数 |
值 |
说明 |
|
--net=host |
网络模式 |
使用宿主机网络栈 |
|
--shm-size=25g |
共享内存 |
4容器共享100GB物理内存 |
|
--cap-add SYS_NICE |
特权 |
numactl绑定CPU/内存需要 |
|
--device /dev/davinciX |
NPU设备 |
每容器分配2张NPU |
|
--device /dev/davinci_manager |
管理设备 |
NPU管理接口 |
|
--device /dev/devmm_svm |
内存设备 |
设备内存管理 |
|
--device /dev/hisi_hdc |
主机设备 |
主机设备控制器 |
|
-v /usr/local/dcmi |
驱动挂载 |
DCMI接口 |
|
-v /usr/local/Ascend/driver |
驱动挂载 |
CANN驱动库 |
|
-v /data/models |
模型目录 |
宿主机模型挂载 |
5.3 NUMA隔离配置
|
服务 |
容器名 |
cpuset-cpus |
cpuset-mems |
NPU设备 |
numactl绑定 |
|
1 |
s1-npu01 |
0-31,64-95 |
0 |
davinci0,1 |
–cpunodebind=0 –membind=0 |
|
2 |
s2-npu23 |
0-31,64-95 |
0 |
davinci2,3 |
–cpunodebind=0 –membind=0 |
|
3 |
s3-npu45 |
32-63,96-127 |
1 |
davinci4,5 |
–cpunodebind=1 –membind=1 |
|
4 |
s4-npu67 |
32-63,96-127 |
1 |
davinci6,7 |
–cpunodebind=1 –membind=1 |
5.4 容器创建命令示例(Service 1)
docker run -itd --name vllm-ascend-s1-npu01 --net=host --shm-size=25g --cap-add SYS_NICE --cpuset-cpus="0-31,64-95" --cpuset-mems="0" --device /dev/davinci0 --device /dev/davinci1 --device /dev/davinci_manager --device /dev/devmm_svm --device /dev/hisi_hdc -v /usr/local/dcmi:/usr/local/dcmi -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info -v /etc/ascend_install.info:/etc/ascend_install.info -v /data/models:/data/models m.daocloud.io/quay.io/ascend/vllm-ascend:v0.18.0 bash
六、模型部署
6.1 模型信息
|
模型 |
来源 |
大小 |
量化方式 |
验证状态 |
|
Qwen3.5-27B-w8a8-mtp |
Eco-Tech (ModelScope) |
~35GB |
W8A8 (ModelSlim) |
vllm-ascend v0.18.0rc1验证 |
|
Qwen3.6-27B-w8a8 |
Eco-Tech (ModelScope) |
~35GB |
W8A8 (ModelSlim) |
vllm-ascend v0.18.0rc1验证 |
6.2 下载命令
# 在容器内执行
export VLLM_USE_MODELSCOPE=true
pip install modelscope
modelscope download --model Eco-Tech/Qwen3.5-27B-w8a8-mtp --local_dir /data/models/Qwen3.5-27B-w8a8-mtp
modelscope download --model Eco-Tech/Qwen3.6-27B-w8a8 --local_dir /data/models/Qwen3.6-27B-w8a8
6.3 模型文件结构
/data/models/Qwen3.6-27B-w8a8/
├── config.json # 模型配置 (4308 bytes)
├── quant_model_description.json # 量化描述 (124KB)
├── quant_model_weights-00001-of-00009.safetensors # 权重分片1 (4.0GB)
├── quant_model_weights-00002-of-00009.safetensors # 权重分片2 (4.0GB)
├── ... (共9个分片)
├── quant_model_weights.safetensors.index.json # 索引文件
├── tokenizer.json # 分词器
├── tokenizer_config.json # 分词器配置
└── chat_template.jinja # 对话模板
七、vLLM服务启动配置
7.1 启动命令
/usr/bin/numactl --cpunodebind=0 --membind=0 /usr/local/python3.11.14/bin/vllm serve /data/models/Qwen3.6-27B-w8a8 --tensor-parallel-size 2 --port 8000 --host 0.0.0.0 --dtype bfloat16 --max-model-len 262144 --quantization ascend --enforce-eager --gpu-memory-utilization 0.95 --disable-custom-all-reduce --enable-prefix-caching --served-model-name qwen3.6-27b-w8a8 --enable-auto-tool-choice --tool-call-parser qwen3_xml --reasoning-parser qwen3 --api-key sk-qwen-27b-w8a8-2026
7.2 参数说明
|
参数 |
值 |
说明 |
|
--tensor-parallel-size |
2 |
2张NPU张量并行 |
|
--dtype |
bfloat16 |
计算数据类型 |
|
--max-model-len |
262144 |
最大上下文长度 (Qwen3.6) |
|
--quantization |
ascend |
昇腾ModelSlim W8A8量化 |
|
--enforce-eager |
- |
禁用graph编译,确保稳定性 |
|
--gpu-memory-utilization |
0.95 |
GPU内存利用率95% |
|
--disable-custom-all-reduce |
- |
禁用自定义all-reduce |
|
--enable-prefix-caching |
- |
启用前缀缓存加速 |
|
--enable-auto-tool-choice |
- |
自动工具选择 |
|
--tool-call-parser |
qwen3_xml |
Qwen3 XML工具调用格式 |
|
--reasoning-parser |
qwen3 |
Qwen3推理模式解析 |
|
--api-key |
sk-qwen-27b-w8a8-2026 |
API认证密钥 |
八、Nginx负载均衡配置
8.1 安装Nginx
sudo apt update
sudo apt install -y nginx
8.2 配置文件
upstream vllm_backend {
server 10.255.254.65:8000;
server 10.255.254.65:8001;
server 10.255.254.65:8002;
server 10.255.254.65:8003;
keepalive 64;
}
server {
listen 2199;
client_max_body_size 0;
client_body_timeout 3600s;
client_header_timeout 3600s;
location /v1/ {
proxy_pass http://vllm_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_connect_timeout 30s;
proxy_send_timeout 3600s;
proxy_read_timeout 3600s;
proxy_buffering off;
chunked_transfer_encoding on;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
8.3 超时配置汇总
|
超时类型 |
值 |
说明 |
|
client_body_timeout |
3600s |
读取客户端请求体 |
|
client_header_timeout |
3600s |
读取客户端请求头 |
|
proxy_connect_timeout |
30s |
连接后端超时 |
|
proxy_send_timeout |
3600s |
向后端发送数据 |
|
proxy_read_timeout |
3600s |
等待后端响应 |
九、systemd服务化
9.1 服务文件
[Unit]
Description=vLLM Ascend Service 1 (NPU 0-1, NUMA 0, Port 8000)
After=docker.service network.target
Requires=docker.service
[Service]
Type=simple
Restart=always
RestartSec=10
User=root
ExecStart=/usr/local/bin/vllm-ascend-s1-start.sh
ExecStop=/usr/bin/docker stop -t 30 vllm-ascend-s1-npu01
ExecStopPost=/usr/bin/docker rm -f vllm-ascend-s1-npu01
[Install]
WantedBy=multi-user.target
9.2 启动脚本功能
- 容器创建:如容器不存在,自动创建并配置NUMA隔离
- 容器启动:如容器未运行,自动启动
- vLLM启动:如vllm serve未运行,自动在容器内启动
- 进程监控:while true循环,每10秒检测,崩溃自动重启
- 清理停止:ExecStop时停止并删除容器
9.3 服务管理命令
# 查看状态
systemctl status vllm-ascend-s1
# 查看日志
journalctl -u vllm-ascend-s1 -f
# 重启服务
systemctl restart vllm-ascend-s1
# 开机自启
systemctl enable vllm-ascend-s1
十、问题与解决方案
10.1 问题1:模型输出全感叹号
现象: curl 返回 "content":"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
根因: 1. config.json 被手动篡改(架构从 Qwen3_5ForConditionalGeneration 改为 Qwen3ForCausalLM) 2. safetensors 权重文件缺失 weight_scale 和 weight_offset 量化参数
解决: 重新下载官方验证模型 Eco-Tech/Qwen3.6-27B-w8a8
10.2 问题2:numactl权限不足
现象: set_mempolicy: Operation not permitted
解决: 创建容器时添加 --cap-add SYS_NICE
10.3 问题3:Nginx重复upstream
现象: duplicate upstream "vllm_backend"
解决: 清理 /etc/nginx/conf.d/ 和 /etc/nginx/sites-enabled/ 中重复定义,合并为单一配置文件
10.4 问题4:脚本语法错误
现象: --api-key: command not found
根因: sed 插入 --api-key 时使用了 \n 字面量,导致shell解析错误
解决: 重新生成完整脚本,确保 --api-key 在同一行或用正确续行符
十一、验证结果
11.1 服务状态
|
服务 |
容器 |
状态 |
PID |
端口 |
NPU |
NUMA |
|
vllm-ascend-s1 |
s1-npu01 |
active |
86 |
8000 |
0,1 |
0 |
|
vllm-ascend-s2 |
s2-npu23 |
active |
86 |
8001 |
2,3 |
0 |
|
vllm-ascend-s3 |
s3-npu45 |
active |
86 |
8002 |
4,5 |
1 |
|
vllm-ascend-s4 |
s4-npu67 |
active |
86 |
8003 |
6,7 |
1 |
11.2 API测试
|
测试项 |
请求 |
预期 |
结果 |
|
无Key访问 |
无Authorization |
401 |
✅ 401 Unauthorized |
|
错误Key |
Bearer wrong-key |
401 |
✅ 401 Unauthorized |
|
正确Key |
Bearer sk-qwen-27b-w8a8-2026 |
200 |
✅ 200 OK |
|
流式输出 |
stream: true |
SSE |
✅ data: {…} + [DONE] |
|
模型列表 |
GET /v1/models |
qwen3.6-27b-w8a8 |
✅ 返回正确 |
11.3 推理验证
curl http://10.255.254.65:2199/v1/chat/completions -H "Authorization: Bearer sk-qwen-27b-w8a8-2026" -d '{"model":"qwen3.6-27b-w8a8","messages":[{"role":"user","content":"What is the capital of France?"}],"max_tokens":50}'
# 输出: thinking process + "Expected answer: Paris"
十二、文件清单
|
文件路径 |
说明 |
|
/usr/local/bin/vllm-ascend-s1-start.sh |
Service 1启动脚本 |
|
/usr/local/bin/vllm-ascend-s2-start.sh |
Service 2启动脚本 |
|
/usr/local/bin/vllm-ascend-s3-start.sh |
Service 3启动脚本 |
|
/usr/local/bin/vllm-ascend-s4-start.sh |
Service 4启动脚本 |
|
/etc/systemd/system/vllm-ascend-s1.service |
Service 1 systemd配置 |
|
/etc/systemd/system/vllm-ascend-s2.service |
Service 2 systemd配置 |
|
/etc/systemd/system/vllm-ascend-s3.service |
Service 3 systemd配置 |
|
/etc/systemd/system/vllm-ascend-s4.service |
Service 4 systemd配置 |
|
/etc/nginx/sites-available/vllm |
Nginx负载均衡配置 |
|
/data/models/Qwen3.6-27B-w8a8/ |
Qwen3.6模型文件 |
|
/data/models/Qwen3.5-27B-w8a8-mtp/ |
Qwen3.5模型文件 |
十三、后续维护
13.1 日常检查
# NPU状态
npu-smi info
# 容器状态
docker ps | grep vllm-ascend
# 服务状态
systemctl status vllm-ascend-s1 s2 s3 s4
# Nginx状态
sudo systemctl status nginx
13.2 日志查看
# vLLM日志
journalctl -u vllm-ascend-s1 -f
# Nginx访问日志
sudo tail -f /var/log/nginx/access.log
# Nginx错误日志
sudo tail -f /var/log/nginx/error.log
13.3 重启操作
# 重启单个服务
systemctl restart vllm-ascend-s1
# 重启所有服务
systemctl restart vllm-ascend-s1 vllm-ascend-s2 vllm-ascend-s3 vllm-ascend-s4
# 重载Nginx
sudo nginx -s reload
报告生成时间: 2026-06-12 报告版本: v1.0 服务器: 8×910B4-32G (10.255.254.65)

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)