
基于昇腾RecSDK:多级缓存突破TB级Embedding训练
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
摘要
昇腾RecSDK通过多级缓存架构,有效缓解TB级稀疏Embedding对显存的高占用问题。基于A2芯片架构,采用HBM与DDR分层存储:HBM仅保留训练所需的“热数据”,全量Embedding持久化存储于DDR,实现高效资源利用。该方案无需依赖NPU侧全栈下沉或专用KV存储算子,即可支持TB级大规模稀疏模型训练,为资源受限场景下的可扩展演进提供稳定工程支撑。
背景概述
当前头部推荐系统面临万亿级稀疏特征带来的算力与存储压力,传统GPU方案依赖HBM全量承载Embedding,但实际计算中仅约1%特征活跃,导致HBM资源99%闲置。主流方案虽在算子与分布式训练上优化,仍难突破HBM容量瓶颈与调度效率问题。因此,实现稀疏表的高效分层管理、低时延动态调度与NPU协同,成为推动推荐系统向高算力密度、低功耗、可扩展演进的关键。
系统架构与核心组件设计
面对 TB 级 Embedding 表的训练难题,昇腾 RecSDK提供了独具特色的多级缓存架构设计。其核心理念是“冷热数据分层”——将高频访问的“热点”特征驻留在高速的 NPU 显存(HBM)中,而将海量全量参数存放在大容量的主机内存(DDR)里。该架构支持动态扩容能力,能根据训练过程中的实际特征规模自动弹性扩展存储空间,无需在初始化时死板预估。
为了实现该功能,昇腾RecSDK设计了以下几个模块
- EmbCacheManager核心管控
- Swapmanager高效换入换出集合的计算引擎
- FeatureFilter准入淘汰机制
- PipeLine流水线
EmbCacheManager:中央控制组件
传统torchrec框架在做embedding表管理时,都是将所有的表数据放在HBM上,而如果要实现多级缓存,需要将可动态扩容的数据放在DDR,HBM上只放热点数据,因此必然需要一个核心管控组件,负责调动所有资源以及DDR与HBM之间的数据互联。
为此我们设计了一个EmbCacheManager调度器,它是整个多级缓存架构的中央控制组件,负责统一管理多张 Embedding 表的缓存策略、特征过滤、数据换入换出(Swap)及持久化存储。在架构设计上,它聚合了三大核心功能模块:
- SwapManager 负责具体的缓存数据迁移调度
- EmbTable 提供 Embedding 表的底层存储管理与访问接口
- FeatureFilter 则实现对输入特征的准入筛选与预处理。
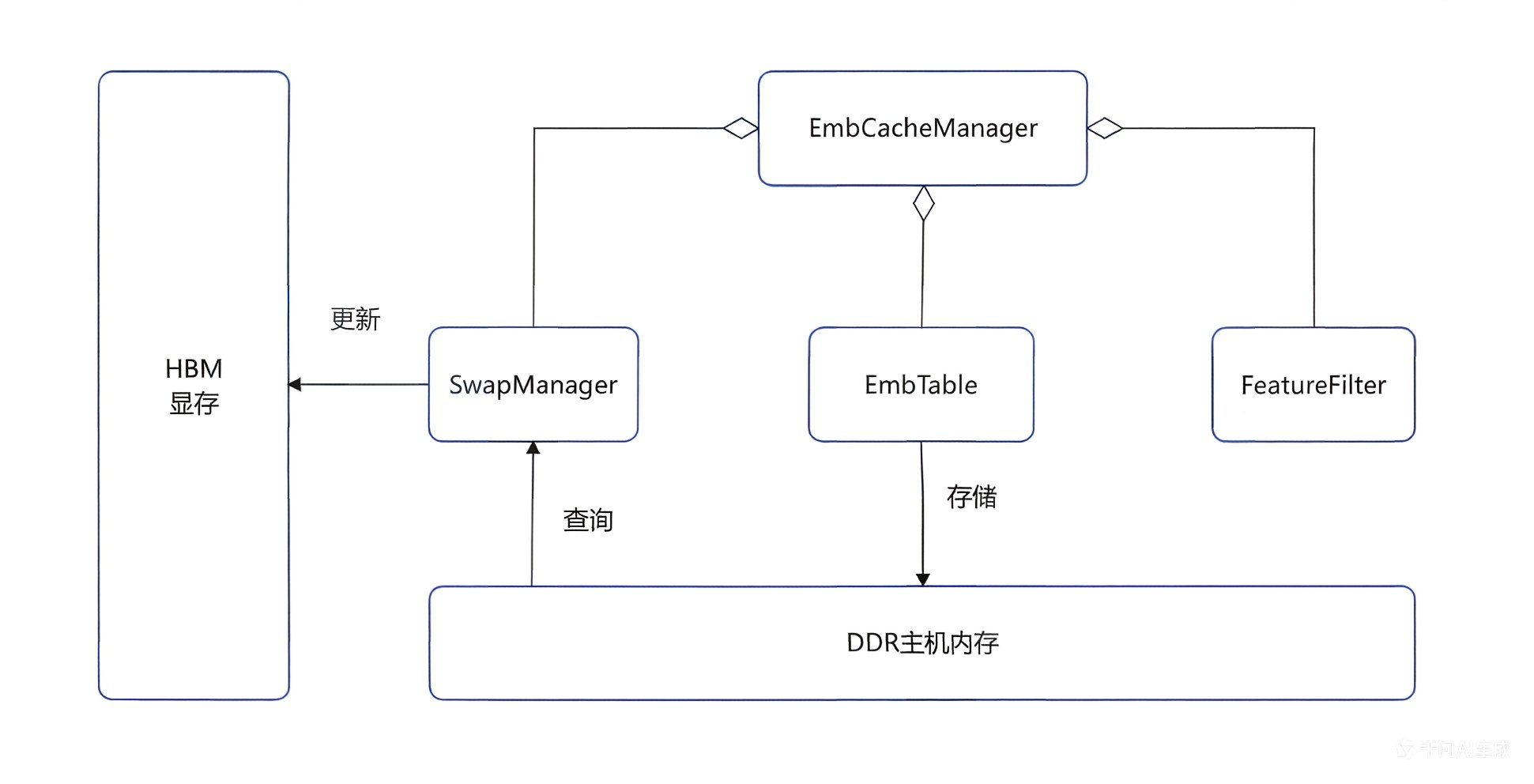
图1:EmbCacheManager组件架构图
EmbCacheManager通过维护全局内存映射,实时追踪Embedding特征在DDR与HBM中的位置。新Batch输入时,异步线程池并行计算需换入的热点Key与换出的冷数据,生成含偏移与地址的调度指令,实现数据调度与NPU计算解耦。同时,在HBM中为多表规划连续存储空间,预计算每表起始偏移,支持上层算子统一接口高效跨表提取,简化地址映射,为流水线并行提供基础。
SwapManager:高效计算引擎
在动态的训练环境中,HBM显存作为高速缓存,其空间始终有限。因此,如何智能地决定哪些数据应该被加载进来(换入),哪些数据应该被替换出去(换出),就成了保障训练效率的关键。SwapManager正是负责这一核心决策的“智能调度器”。
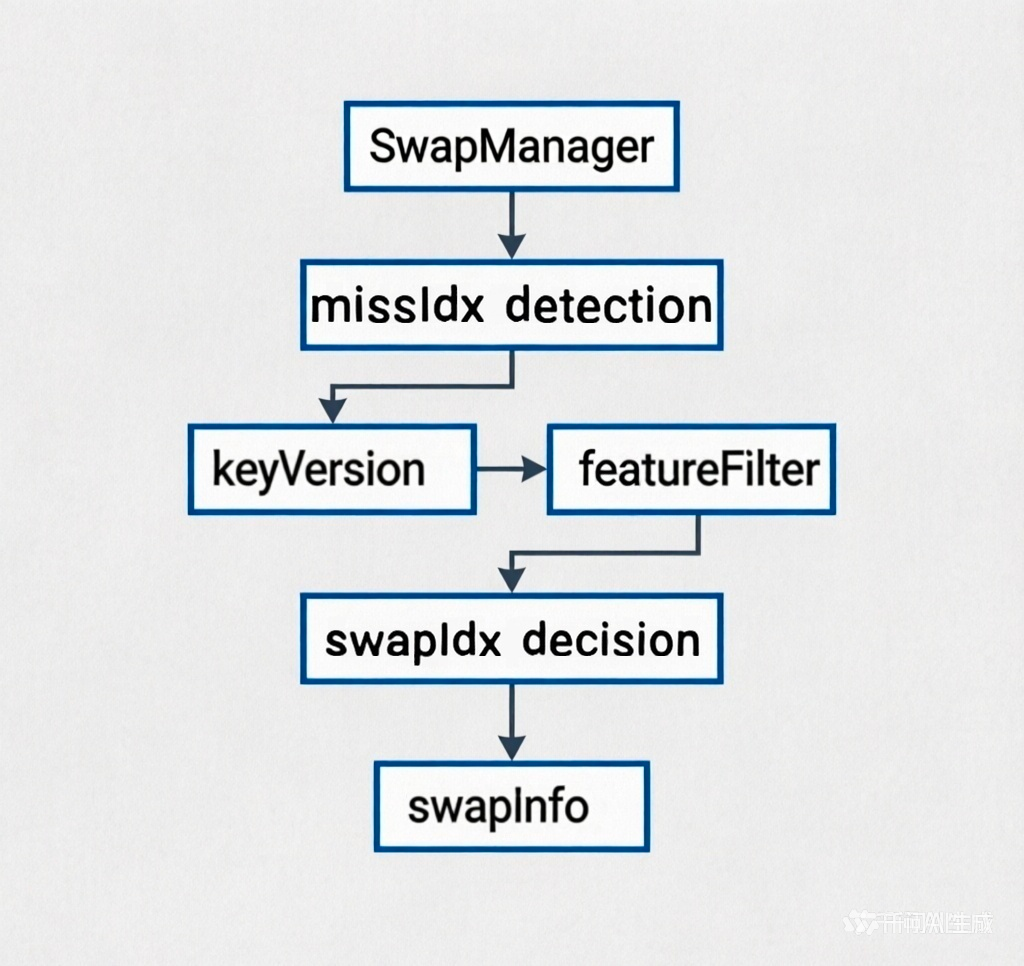
图2:SwapManager流程图
SwapManager的调度逻辑遵循一个清晰的三步走框架,确保数据流动的高效与精准:
并行missidx检测:在每个训练步骤(Step)开始时,SwapManager首先利用多线程并行技术分析当前Batch所需的特征键(Keys)。通过与HBM缓存的当前状态进行比对,它能精确识别出哪些是刚应届毕业准备进入社会毒打的新key,即需要从DDR主存中换入的数据;哪些是已经毕业2年半的社畜,即当前已不再活跃,可以被考虑换出的数据。
swapIdx决策:系统引入KerVersion机制结合FeatureFilter准入淘汰策略进行决策。系统会为每个数据记录其“活跃度”,从而确保当前及上一轮正在被计算的关键数据不会被错误换出,同时优先淘汰那些长时间未被访问的“冷数据”,确保了宝贵的HBM空间始终服务于最活跃的训练数据。
swapinfo生成:在完成需求分析和策略决策后,SwapManager会生成一份精确的“调度清单”(SwapInfo)。这份清单明确指出了本轮需要执行的所有换入和换出操作,包括具体的键(Key)及其在HBM中的目标位置(Offset)。这份清单随后会被交付给底层的执行模块,驱动数据在DDR与HBM之间高效流转。
FeatureFilter:高效特征预筛选器
面对海量的特征表,如何将“热点数据”常驻于HBM上,即保证当用户请求推荐内容时,系统能直接从缓存中直接获取相关数据,是减少延迟和计算开销的关键核心。
因此我们设计了FeatureFilter准入淘汰功能,来确保缓存中的内容是最有价值和最相关的,以此来加速冷启动过程。
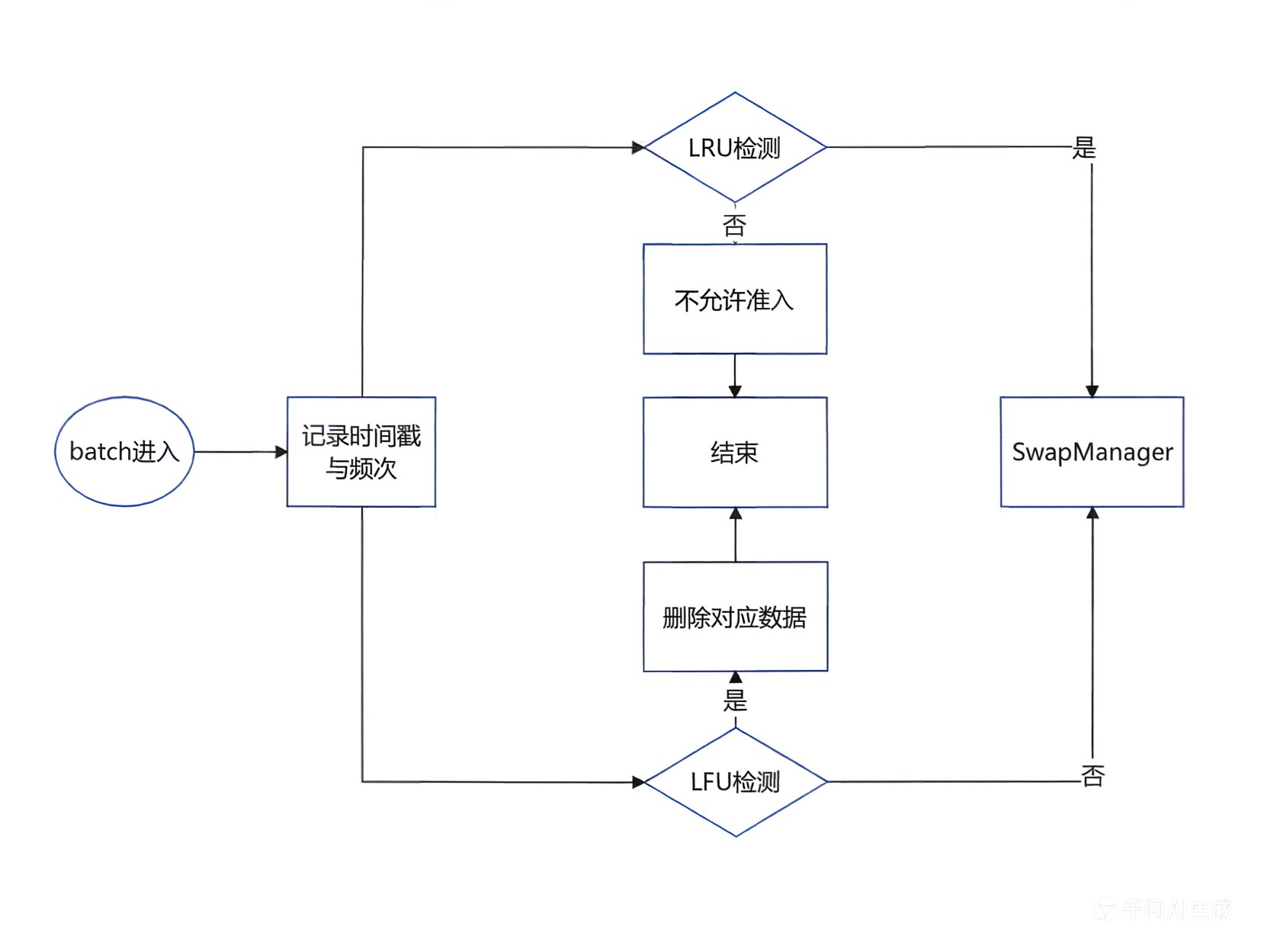
图3:准入淘汰流程图
该组件主要用于控制特征的准入和淘汰策略,通过设置准入阈值和淘汰阈值来优化EmbeddingCache的使用效率。其中包含两个核心组件:特征过滤器和特征淘汰记录,它们协同工作以实现特征的准入控制和淘汰机制。主要包含以下三个步骤:
数据记录:每当batch进来时,统计特征访问次数,获取时间戳并记录
特征准入:在启动准入时,基于LFU算法以及统计频次计算是否可以参与后续计算
特征淘汰:在启动淘汰时,基于LRU算法以及记录的历史时间戳判断是否需要淘汰该数据
Pipeline:高效流水并行框架
在大规模稀疏训练场景下,频繁的 Embedding 查表、DDR 到 HBM 的数据换入换出以及跨卡特征通信会带来巨大的 IO 开销。如果采用传统的串行执行模式,NPU 强大的算力将大量耗费在等待数据搬运的空转上。
因此,为最大化掩盖数据搬运与通信和计算开销,系统构建了深度的流水线并行机制。该机制将数据处理、特征通信、缓存调度与模型计算等异构任务进行精细化拆解,并重组为多级并行的执行流。
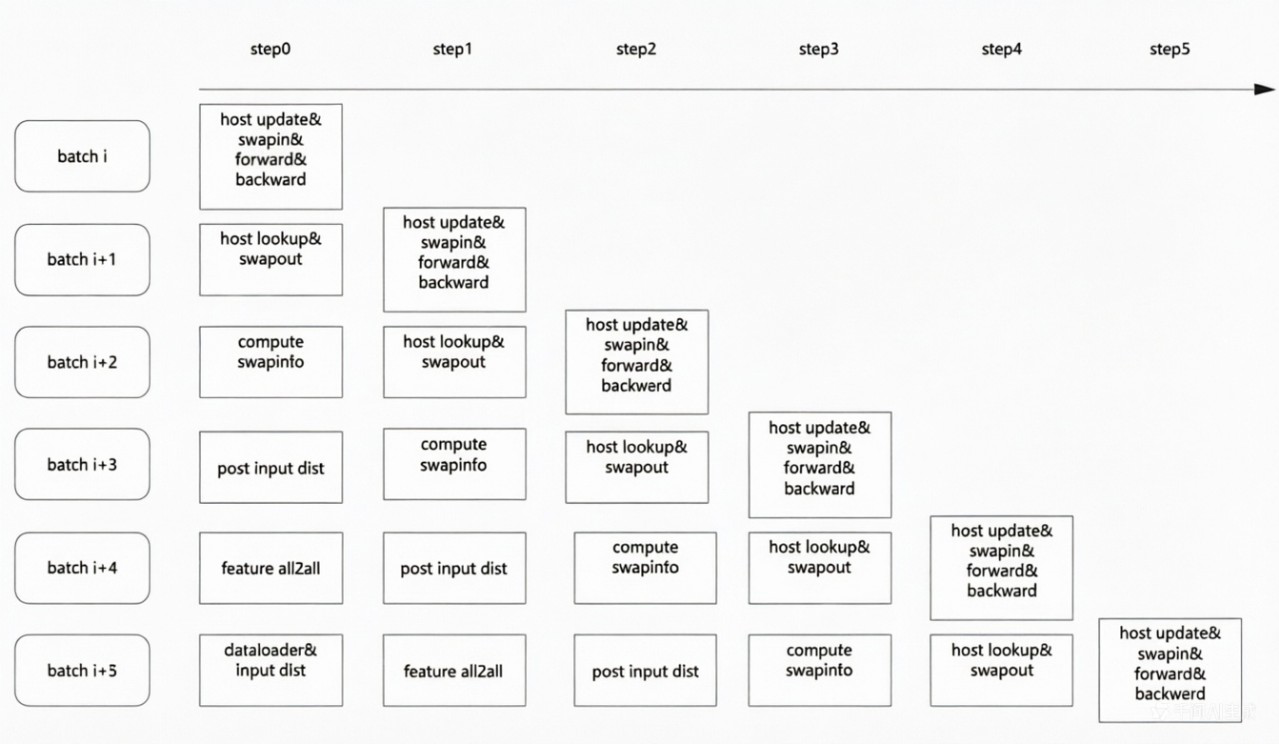
图4:细粒度六级流水调度示例图
在我们的设计中,训练步骤被划分6个步骤:
1.数据加载与 CPU 预处理:从数据源读取 Batch 数据,完成特征编码与格式转换。
- All2All 通信:在多卡间完成特征分发与聚合。
- CPU 计算预处理:特征后处理。
4.计算换入换出:调用 SwapManager,计算换入换出信息。
- Host查表与换出:根据换入换出信息,执行DDR查表并执行换出。
- NPU计算执行:将最终数据送入 NPU 执行 Embedding Lookup 与模型前反向计算。
使用指南
torchrec_embcache安装指南
使用案例
基于ebc的使用案例
RecSDK/training/torch_rec_v1-代码预览-RecSDK:基于昇腾平台的搜索推荐广告框架项目 - AtomGit | GitCode
基于dlrm模型多级缓存适配与用例执行
基于gr模型的多级缓存适配与用例执行
总结
昇腾RecSDK通过 EmbCacheManager 的全局智控、EmbTable 的极速存储、SwapManager 的精准调度以及 FeatureFilter 的智能筛选,系统成功将有限的 NPU 显存转化为无限弹性的计算空间。配合深度流水线并行技术,实现了数据搬运与模型计算的极致重叠。这不仅让 TB 级 Embedding 表在有限硬件资源上的高效训练成为可能,更为推荐系统与大规模稀疏模型的迭代升级提供了坚实的底层支撑。
参考资料
RecSDK多级缓存源码地址:
https://gitcode.com/Ascend/RecSDK/tree/develop/training/torch_rec_v1/torchrec_embcache

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)