
写计算通信融合算子太痛苦?试试这个C++模板库—CATCCOS
背景介绍
在大模型参数量指数级增长的今天,分布式执行成为主流。算子开发的核心挑战已从单卡优化转向:如何让计算与通信协同优化。
传统融合算子开发面临三大痛点:
- 复杂的流水线编排
- 依赖硬件拓扑
- 代码不可维护
CATCCOS应运而生,借鉴CATLASS的设计理念,通过C++模板元编程将计算通信流水逻辑抽象化、解耦化,让开发者像搭积木一样灵活组合功能模块,构建高性能融合算子。
CATLASS:
https://gitcode.com/cann/catlass
CATCCOS框架介绍
使用CATCCOS开发算子更像是“搭积木”——将“做什么(计算/通信逻辑)”与“怎么做(流水线调度)”分离,通过静态多态在编译期完成抽象展开,不引入运行时开销。
清晰的五层抽象
CATCCOS设计了五层抽象模型(图1):
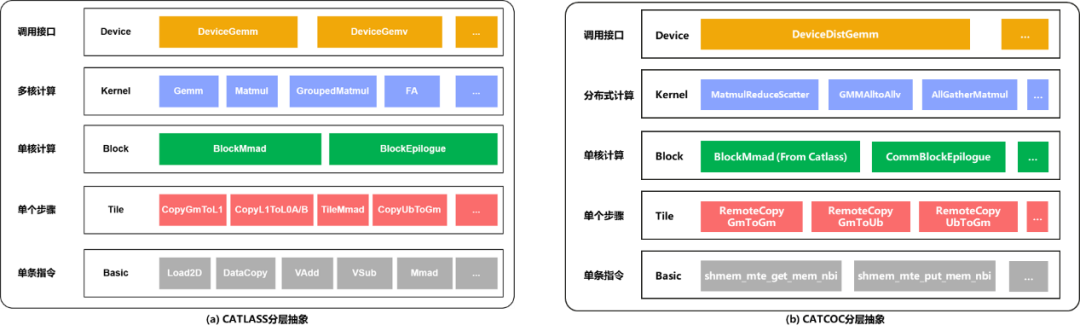
图 1:分层抽象
这五层架构将融合逻辑拆解为可独立管理的模块:Device Layer(设备层)、Kernel Layer(内核层)、Block Layer(块级层)、Tile Layer(切片层)、Basic Layer(架构层)。五层架构中,Kernel层解决流水线编排痛点,Block层解决逻辑解耦痛点,Tile层解决跨代兼容痛点。
融合算子的执行机制
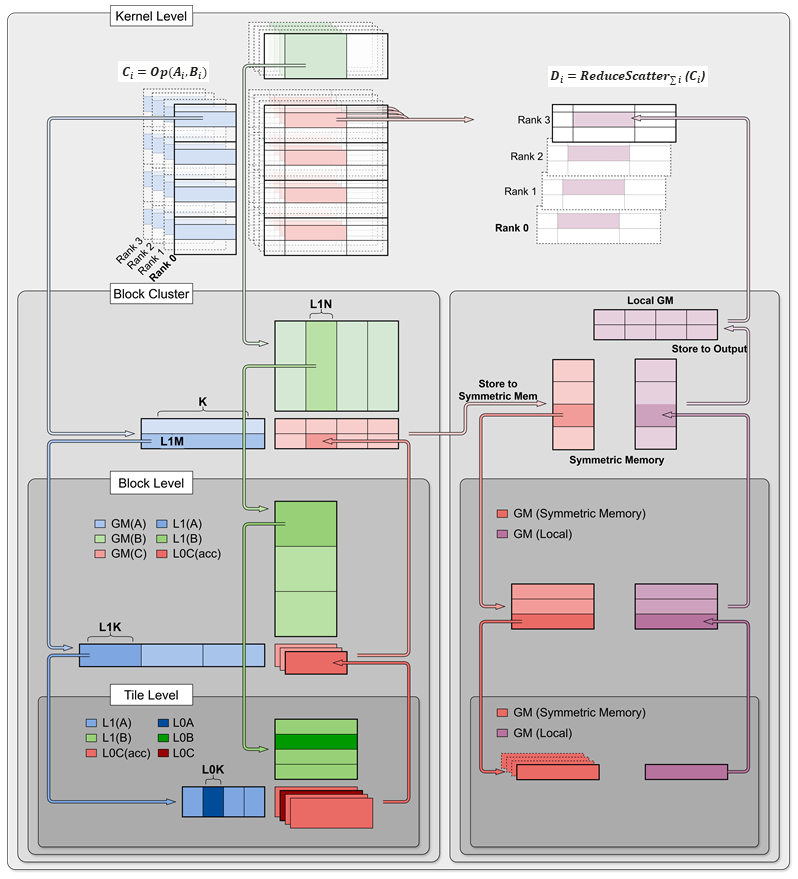
图 2:CATCCOS执行流程
以Matmul融合ReduceScatter算子为例,Kernel层到Tile层自顶向下实现多层任务切分:
宏观流水:基于Block Cluster的乒乓调度
宏观流水:计算将部分和存入对称内存,进行PingPong调度——一个Block Cluster完成计算即触发通信,下一个Cluster并行启动(图3)。

图3:CATCCOS流水机制
微观分工:基于Block的并行执行
微观分工:Cluster内Cube Cores负责矩阵乘法(复用CATLASS模板),Vector Cores负责数据搬运与归约/量化。
吞吐最大化:解耦的Tiling策略
Tiling解耦:计算侧自由优化Block/Tile Shape追求吞吐,通信侧独立选择最优传输粒度,互不干扰。
双层调度架构:Swizzle引擎与Remapper机制
融合算子面临核心调度冲突:计算追求“局部性”(非线性Swizzling提高Cache命中),通信追求“连续性”(线性内存开启DMA Burst)。
调度冲突分析
CATCCOS引入双层调度机制(图4):Swizzle层规划执行顺序,Remapper层负责数据布局重映射。
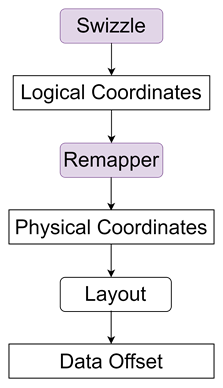
图4:CATCCOS双层调度机制示意图
Swizzle:硬件感知的执行序重排
计算阶段采用非线性Swizzle提升数据局部性,通信阶段切换为线性Swizzle确保连续传输。
Paired Remappers:计算与通信之间的地址映射转换
Paired Remappers解决计算与通信数据遍历顺序不一致的问题:
Remapper I(计算→通信):将分形布局的小矩阵块重排为连续数据块写入对称内存,消除传输前重排开销(图5)。
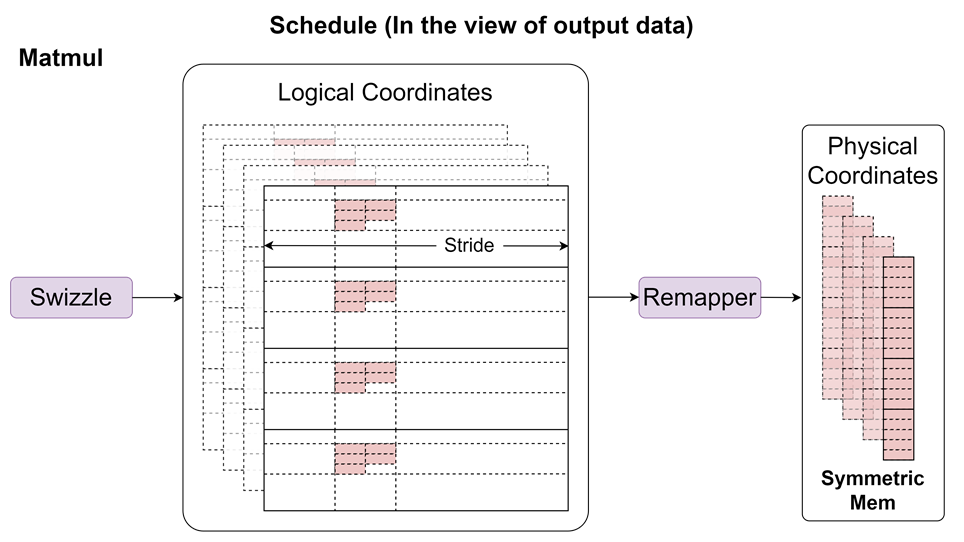
图5:计算阶段调度示意图
Remapper II(通信→输出):从线性排布反向映射回标准张量布局,使融合算子对外表现为即插即用的黑盒(图6)。
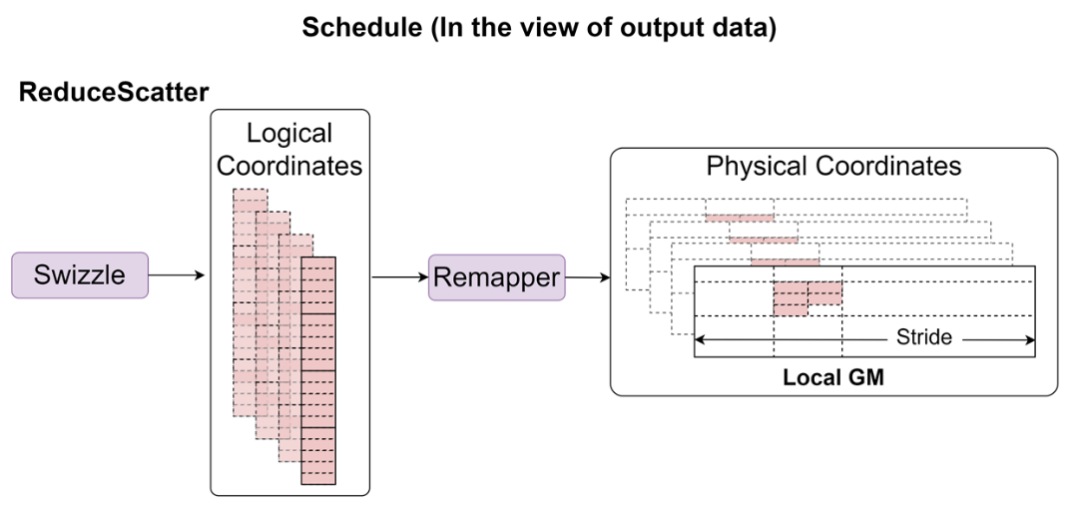
图6:通信阶段调度示意图
价值:通过抽象解耦降低复杂度
传统开发需手动编写地址跳转与索引计算,导致:
开发复杂度高
代码污染
CATCCOS通过双层调度解决——调度优化独立、地址计算透明化、计算逻辑纯粹化,将开发范式从“侵入式硬编码”转向“模块化架构”。
实战演示
以AllToAllV-GroupedMatmul算子为例,展示CATCCOS如何通过模板配置实例化分布式算子。代码仓examples目录提供了MoE融合、TP融合及混合精度版本等多个案例。
模块化算子构建
开发者只需选择合适的“积木块”填入模板参数:
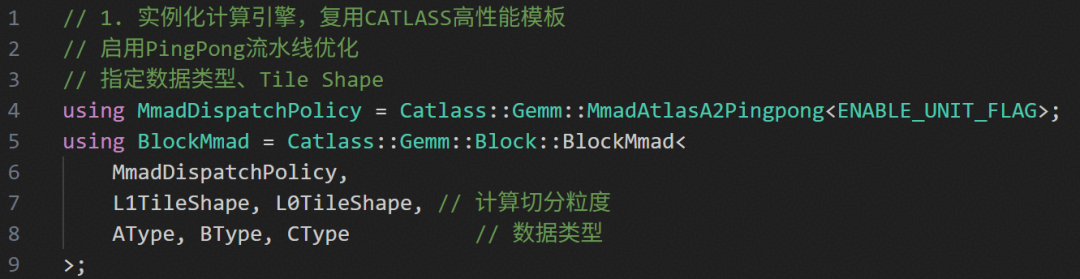
第一步:选择计算引擎BlockMmad,复用CATLASS组件,指定Pingpong策略。
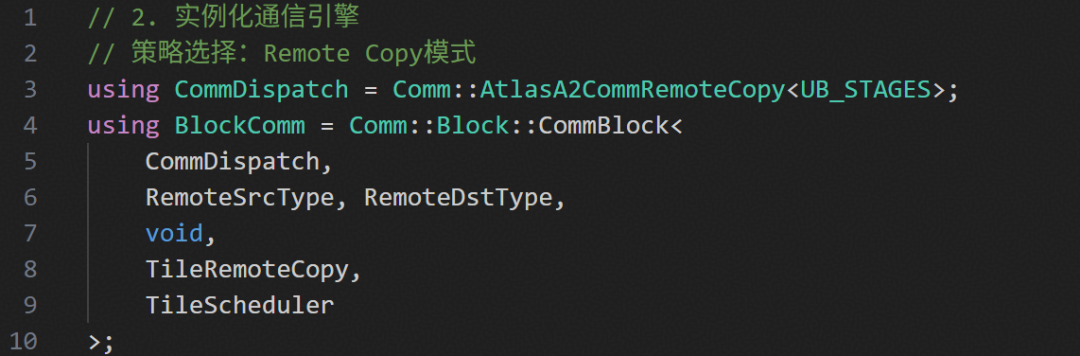
第二步:选择“通信引擎”(BlockAllToAllV) 针对MoE场景的变长通信需求,实例化了CommBlock。通过AtlasA2CommRemoteCopy策略调用DMA引擎处理远程内存拷贝。
第三步:通过MoeConstraints注入业务约束,调度器实现特化remappers。

第四步:将所有模块填入核心模板,生成Device Kernel。

解耦带来可组合性——如需将AllToAllv改为AllGather,只需替换Scheduler即可。
核心引擎实现
Kernel层通过C++模板特化实现计算与通信协同,Remapper抽象统一逻辑访存视图:
计算侧
计算侧只需关注逻辑矩阵计算,Remapper承担坐标映射,屏蔽物理分布。
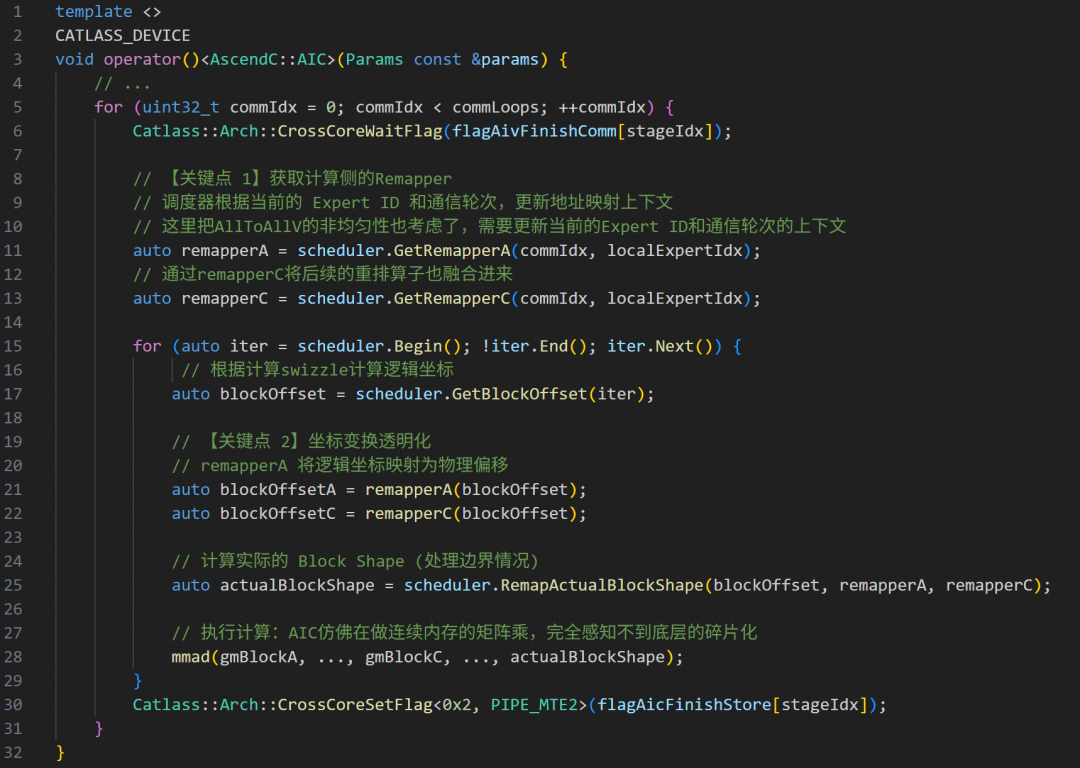
通信侧
通信侧利用Remapper确定数据源地址,屏蔽MoE场景下Expert数据分布逻辑。
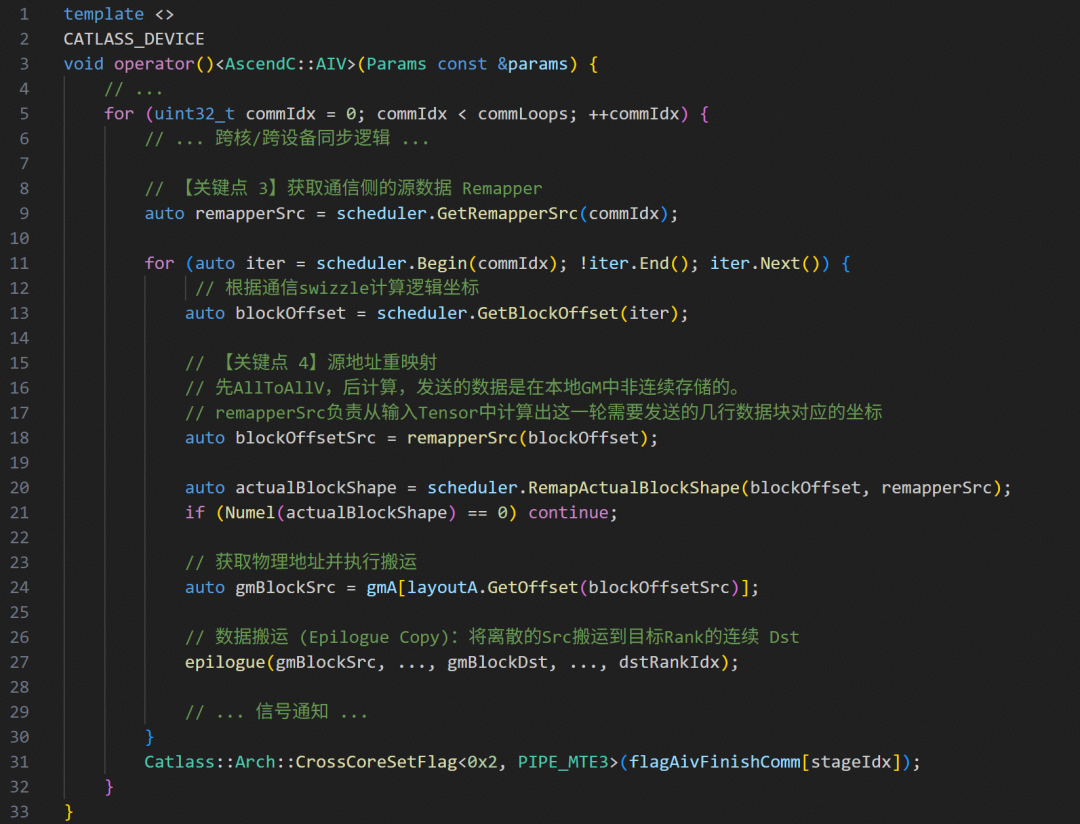
Remapper实现了复杂度的隔离:AIC侧remapperA让计算逻辑保持纯粹,AIV侧remapperSrc高效处理变长非连续数据块。
性能实测
标准算子:从通用优化到场景特化
对于标准融合算子(GEMM+ReduceScatter、AllGather+GEMM),CATCCOS优于标杆实现(图7、表1)。
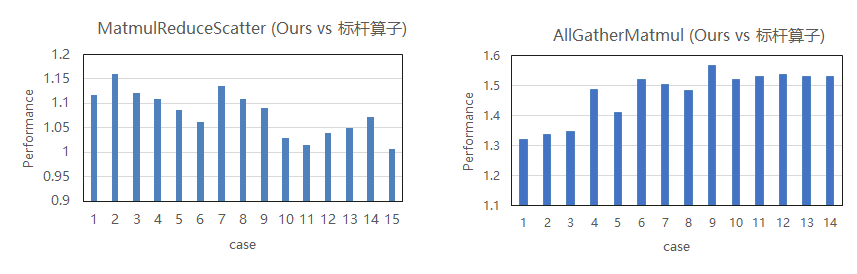
图7 标准算子性能收益
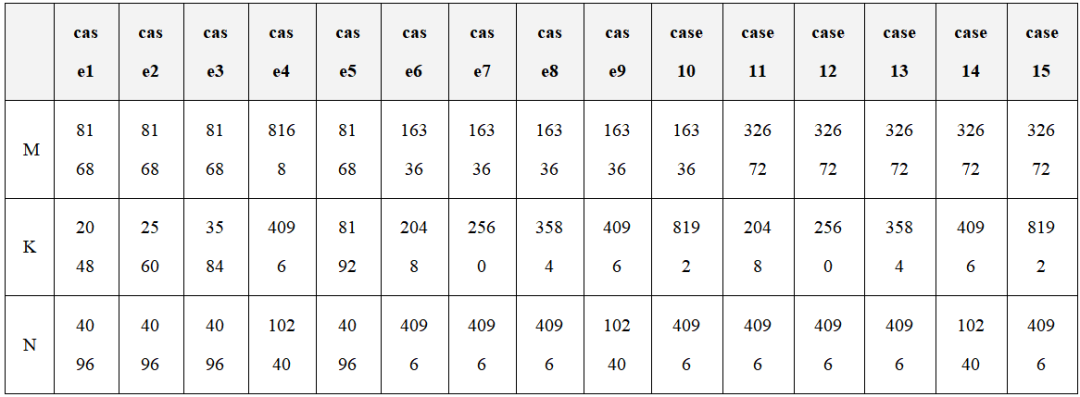
表1 部分典型Shape
性能优势源于策略的定制调整——计算、通信、调度模板解耦后可针对特定场景灵活微调。
复杂场景:研发效率与性能的平衡
模块化配置大幅缩短研发周期。传统开发AllToAllv+GroupedMatmul耗时数月,CATCCOS可快速迭代。
多数场景掩盖率50%~80%(表2)。特定配置下甚至超过100%,源于内核启动开销与访存开销的消除。
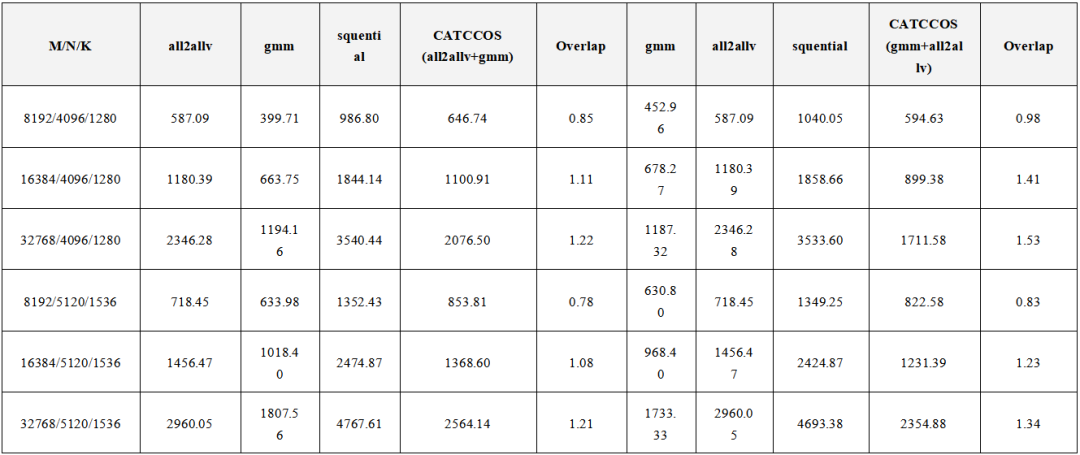
表2 CATCCOS融合算子与非融合Baseline相比
深度优化:掩盖率超过100%
在特定配置下,CATCCOS甚至表现出了掩盖率超过100%的优化效果(即融合算子执行时间小于理论计算或通信的最长单项耗时)。
总结与展望
CATCCOS为高性能分布式算子开发提供了系统性解决方案,其核心范式转变:
从“过程式”到“声明式”:模板抽象屏蔽底层,开发者声明“做什么”,框架处理“怎么做”。
从“强耦合”到“逻辑正交”:Remapper与独立Swizzle实现计算通信逻辑正交、执行协同。
沉淀专家经验:优化专家专注核心组件,上层开发者复用预优化模板快速构建。
未来将扩展TLA(复杂数据排布的通用抽象,简化Tile地址计算)和EVG(Point-wise操作与通信快速融合,演进为“矩阵乘+后处理+通信”的融合引擎)两大特性。
欢迎大家来开源社区体验!
CATCCOS:
https://gitcode.com/cann/catccos

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 9
9 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)