
基于Triton的GDN算子昇腾训练优化实践
线性注意力是大模型训练处理长文本的核心技术,相比传统注意力计算效率大幅提升,却存在算子开发难、硬件适配成本高的痛点。昇腾团队依托开源Triton DSL打造线性注意力GDN算子,结合昇腾硬件特点做多维度优化,破解算子适配难题,在实现天级算子适配的同时性能倍级跃升。
技术背景和挑战
当前主流高性能大语言模型的超长文本建模能力,核心得益于线性注意力机制,Qwen3-Next、Qwen3.5等业界主流模型均已大规模应用该方案。凭借长序列场景下远超标准注意力的计算效率,线性注意力已成为下一代注意力机制的核心发展方向。
线性注意力与传统Softmax标准注意力的计算范式存在本质差异:传统注意力通过Q、K点积生成注意力分数矩阵,经Softmax归一化保留所有Token关联关系,时空复杂度均为序列长度平方级;线性注意力舍弃Softmax归一化,通过核函数映射Q、K并调整矩阵乘法顺序,将平方复杂度优化为线性复杂度,大幅提升长序列计算速度。该特殊计算范式为高性能GDN算子开发带来极大工程挑战:定制开发周期长、实现方案高度依赖底层硬件特性,适配成本高昂,严重制约了线性注意力机制的迭代优化与深度研究落地。
GDN序列结构及Triton编程介绍
Gated DeltaNet(GDN)是线性注意力+门控机制+动态差异计算(Delta规则)的高效序列结构,用来替代Transformer的自注意力,由原来的O(L2)复杂度优化到到O (L)复杂度,还能超长上下文、速度快、效果强。
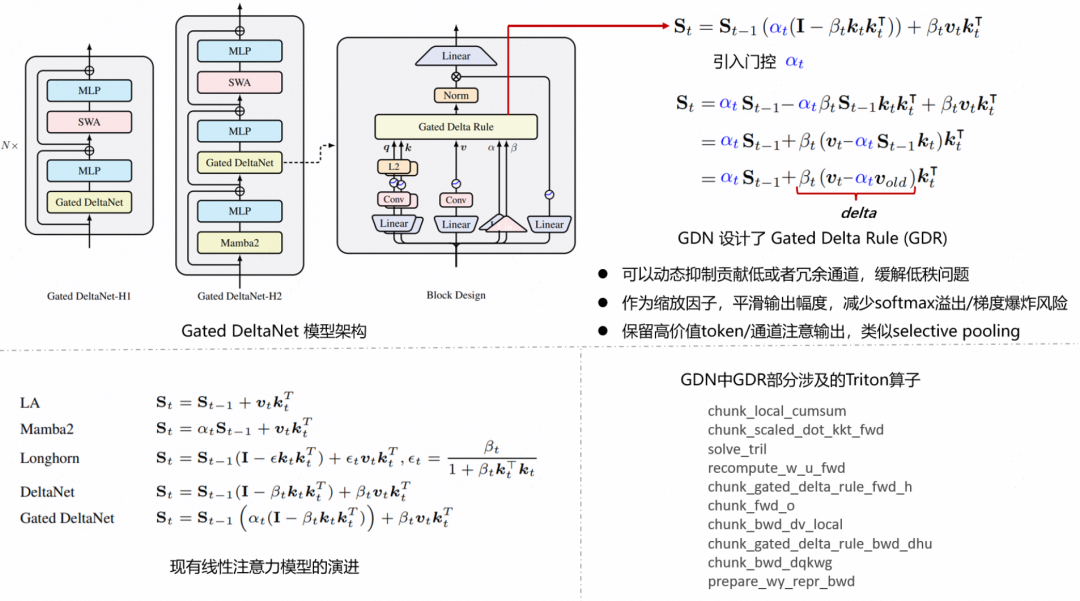
Gated DeltaNet是“有状态的线性递归层”,它只在每层/每头维护一个固定长度的状态矩阵,随着新的token递推更新,不需要把所有过去的K、V存起来。因此,GDN可以采用chunkwise并行算子提升训练与推理速度。FlashLinearAttention(FLA)基于PyTorch和Triton,提供了前沿的线性注意力结构,本文将基于FLA中的GDN算子,针对昇腾NPU(昇腾A2/A3系列产品)的架构特点,对GDN的Triton算子进行深度计算优化。
Triton是一套面向深度学习与高性能计算(HPC)的开源领域专用语言(DSL)及其配套编译器系统,它兼顾高效开发与极致硬件性能,能够在保证开发便捷性的前提下,跑出逼近硬件理论上限的运算速度。与传统的底层编程模型不同,Triton将开发者关注点从线程级调度提升至“分块”(Tile/Block)粒度,用户只需描述如何对张量进行分块以及在分块上执行的计算逻辑,而内存分配、数据搬运、计算调度、流水并行等底层优化则由编译器在编译时自动完成。
基于GDN快速上手Triton优化的昇腾实践
为了解决上述技术挑战,我们基于编程简洁、易用性强的开源Triton DSL开展算子开发,有效降低线性注意力GDN算子的开发与迭代门槛。同时结合昇腾硬件特性完成多项深度适配与性能优化,包括负载均衡的任务分核计算优化、昇腾亲和Tiling分块优化、离散数据合并访存加速、昇腾专属计算流优化。提升开源Triton的昇腾适配效率,算子适配从平均7天降低到平均4小时,同时算子运行性能提升2倍+。
基于负载均衡的任务分核计算优化
目前开源Triton大多基于SIMT(单指令多线程)架构开发,该架构十分适配高并行度计算任务,执行层面还支持多维任务调度,运行时往往会生成规模较大的Grid;反观昇腾前代NPU,其计算架构设计思路与之存在差异,更适合并行任务数量少、单任务处理大数据量的业务场景。基于两种硬件架构的特性差异,在对开源Triton算子做性能优化时,可以优先调整算子的绑核逻辑,以此降低并行任务的数量。
grid = [x, y, z] ——> grid = [24] / grid = [48]
优化前:
def chunk_fwd_kernel_o(...):
i_v, i_t, i_bh = tl.program_id(0), tl.program_id(1), tl.program_id(2)
i_b, i_h = i_bh // H, i_bh % H
…
for i_v in range(tl.cdiv(V, BV)):
…
…
def chunk_fwd_o(..):
…
def grid(meta): return (triton.cdiv(V, meta['BV']), NT, B * H)
# kernel 调用
chunk_fwd_kernel_o[grid](...)
…
Return o优化后:
def chunk_fwd_kernel_o(…):
...
for i_v in range(tl.cdiv(V, BV)):
for i_b in range(B):
...
core_id = tl.program_id(0)
# 根据core_id计算当前轮次的i_t的范围(start_it,end_it)
for i_h in range(0, H):
...
for i_t in range(start_it,end_it):
...
def chunk_fwd_o(..):
…
CV_kernel_num=24
# kernel 调用
chunk_fwd_kernel_o[CV_kernel_num](...)
…
Return o上述优化针对gird数进行调整,将其减小为设备的实际物理核数,并将原多线程的流程替换到单算子内部进行循环计算处理。该优化策略可以有效地解决开源triton算子迁移NPU存在grid溢出无法跑通的问题。在昇腾最新950代际架构上已支持了SIMT架构,可以更加平滑地兼容开源triton算子的开箱运行,不需要再进行相关的调整修改。
昇腾亲和的Tiling优化
在GDN的算子中,存在大量分块大小为64的cv融合算子,在NPU上,可以通过将Tiling增大(即增大分块大小),充分利用UB的容量,亲和昇腾硬件特点,将BV分块的维度从64增大到128,可以显著的提升大部分的算子性能。
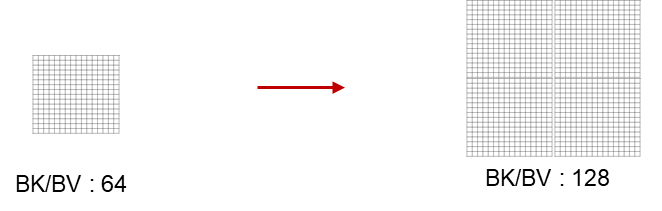
如图所示,将一次处理64*64的数据变成一次处理128*128的数据,在NPU上可获得更好的性能收益。
优化前:
def prepare_wy_repr_bwd_kernel(...):
...
for i_v in range(tl.cdiv(V, BV)):
...
for i_k in range(tl.cdiv(K, BK)):
...
...
def prepare_wy_repr_bwd(...):
...
CONST_TILING = 64 if check_shared_mem() else 32
BK = min(max(triton.next_power_of_2(K), 16), CONST_TILING)
BV = min(max(triton.next_power_of_2(V), 16), CONST_TILING)
# kernel 调用
prepare_wy_repr_bwd_kernel [grid](...)
...
return dk, dv, dbeta, dg优化后:
def prepare_wy_repr_bwd_kernel(...):
...
for i_v in range(tl.cdiv(V, BV)):
...
for i_k in range(tl.cdiv(K, BK)):
...
...
def prepare_wy_repr_bwd(...):
...
BK = 128
BV = 128
# kernel 调用
prepare_wy_repr_bwd_kernel [grid](...)
...
return dk, dv, dbeta, dg上述的代码直接将针对K/V分块的BK/BV值进行增大,在保证不会ub溢出的情况下,该分块大小的增加可以显著提升triton算子在NPU上的性能。
离散数据合并访存加速
在GDN算子中,典型计算是基于序列T维度分块进行迭代计算隐藏层状态。由于输入的q、k、v的layout为(B,T,H,D),当沿T维度按BT分块读取BT*BD数据时,步长为H*D,读写操作会跨越高维H维,导致离散访存问题。在NPU上,若循环处理的数据访存连续,可有效提高Cache命中率,从而提升计算效率。为此,我们将q、k、v在GM端的layout从(B, T, H, D)转置为(B, H, T, D),有效减少离散访存带来的性能损失。此外,对于涉及g和beta的算子,同样可以通过将其layout从(B, T, H)转置为(B, H, T)来减少离散访存。
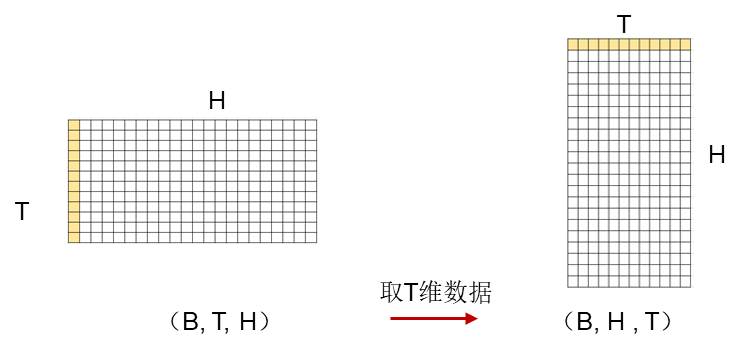
如上图所示,数据存储是横向逐行存储数据,原数据布局为(B,T,H),当前需要访问同H维下的所有T维元素,此时每读取一个元素都需要跨越H长度才能读取到下一个元素。针对该场景,我们将数据进行转置为(B,H,T)的存储布局,此时读取每个相邻数据元素都只需跨越长度1即可,能够有效地提升读取性能。
优化前:
def chunk_fwd_kernel_o(…):
...
g += bos * H + i_h
p_g = tl.make_block_ptr(g, (T,), (H,), (i_t * BT,), (BT,), (0,))
...
def chunk_fwd_o(...):
...
# kernel 调用
chunk_fwd_kernel_o[grid](...)
...
return o优化后:
def chunk_fwd_kernel_o(...):
...
p_g = tl.make_block_ptr(g + bos * H + i_h * T_max, (T,), (1,), (i_t * BT,), (BT,), (0,))
...
def chunk_fwd_o(...) :
...
g = g.transpose(1, 2).contiguous()
# kernel 调用
chunk_fwd_kernel_o[grid](...)
...
return o上述代码通过调整变量g的内存分布,从而将原来的离散访存修改为连续访问,实现读取性能的提升。
昇腾亲和的计算流优化
在使用Triton编写高性能内核时,对全局内存的读写操作通常需要配合mask来避免越界访问,这类mask一般通过tl.arange生成的索引张量(在昇腾A2/A3系列产品上默认为int64类型)与边界条件进行比较运算得到。然而,昇腾A2/A3系列产品的vector单元不支持int64类型数据的比较操作,导致这些操作被迫退化为标量计算,降低执行效率。为规避这一性能瓶颈,可在不损失数值精度的前提下,将用于生成mask的int64索引显式转换为Fp32类型后再进行比较。针对部分算子若分析模型输入前的数据已确保满足一定要求后,可将对应的mask校验删除,提高性能。
优化前:
b_A = desc.load([i_t * 64, offset]).to(tl.float32)
b_A = -tl.where(m_A, b_A, 0)优化后:
b_A = -desc.load([i_t * 64, offset]).to(tl.float32)在保证外部数据满足相关要求的情况下,可以针对专门模型场景进行优化,删除部分约束边界限制,减少相关判断耗时。
关于GDN的Triton优化代码,详细参考仓库链接:
https://gitcode.com/Ascend/MindSpeed-Ops/tree/master/mindspeed_ops/arch32/triton/gdn
结语
当前triton算子已成为大部分模型架构主流选择,大部分开源triton算子都可通过上述介绍的triton优化策略实现快速迁移NPU使用,在手动修改迁移triton算子的同时,我们也有专门的Skill仓可进行部分triton算子的自动迁移优化。
欢迎开发者体验、贡献与共建!
昇腾亲和的训练业务自定义算子实现开源代码仓MindSpeed-OPS:https://gitcode.com/Ascend/MindSpeed-Ops
Trion算子自动迁移优化的Skills开源代码仓:
https://gitcode.com/Ascend/agent-skills/tree/master/community/Op/simple-vector-triton-gpu-to-npu
昇腾开源微信小助手:
ascendosc

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 1
1 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)