
鲲鹏赋能算力卡集群组网,打造MOE大模型高效推理
鲲鹏基于灵衢互联打造多机超节点,实现800GB/s全网状互联,无需专用交换设备。支持2-8节点灵活组网,最多挂载64张计算卡,PCIe与UB协同满足张量并行与专家并行的带宽时延要求。CPU内存统一编址可容纳大容量KV Cache,降低Engram内存,实现轻量化、高性价比的千亿MoE集群推理。
特性介绍
千亿或万亿参数的MoE模型通常难以适配单机8卡部署,需通过多机组网方式来满足MoE的模型权重和KV Cache对片上内存容量的需求,并且现有集群组网须依赖专用卡间互联专有网络或多网卡搭建RDMA网络,这些方案都需额外增加互联设备,机柜复杂度高,如何实现轻量化MoE大模型推理亟待突破。
鲲鹏依托灵衢互联打造多机互联的超节点,可实现整机双向800GB/s聚合带宽,如下图所示,每个节点的CPU服务器可与其他节点进行全网状互联,为每个节点提供均衡互联高带宽,CPU节点数可从2到8任意组合,满足不同计算卡数、不同模型的组网诉求。
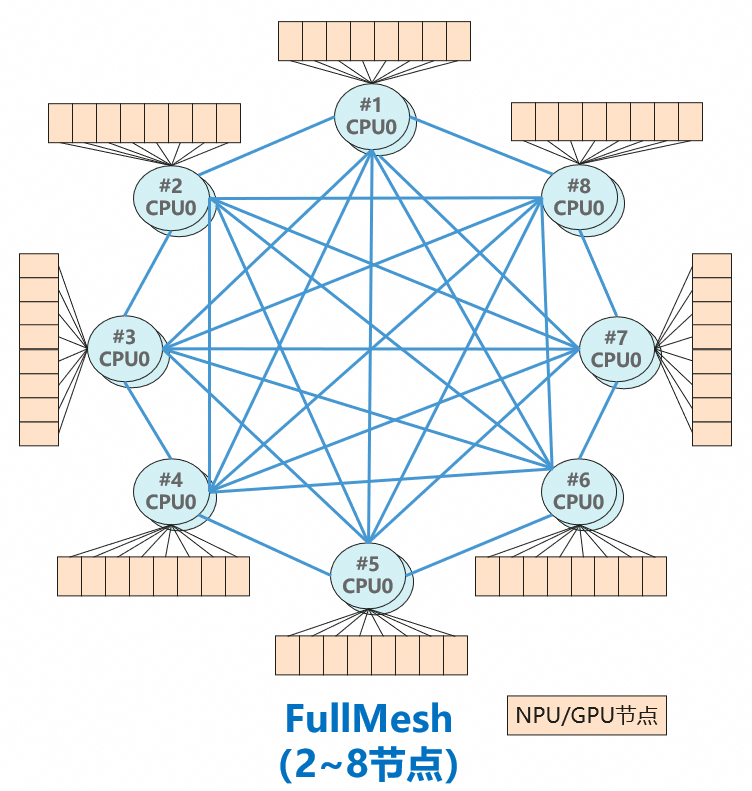
图1:基于灵衢互联的8节点FullMesh组网
优势分析
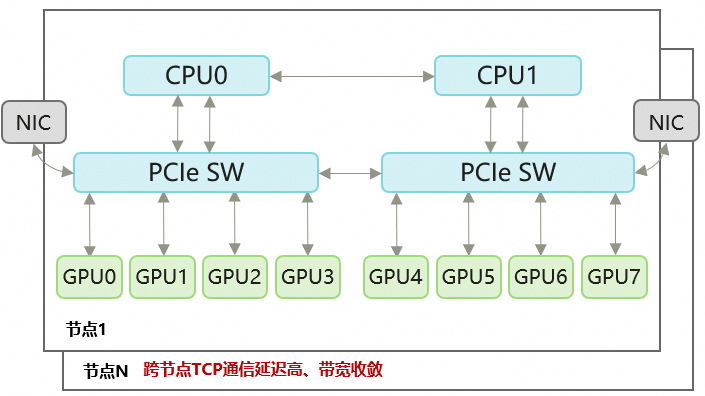
图2:基于PCIe Switch和NIC的典型组网方案
目前,大部分算力卡的互联方案依赖PCIe Switch和NIC,跨节点通信存在以下问题:
时延高:跨节点RDMA通信带宽利用率低、时延高。在EP并行、大规模稀疏数据访问(如搜推广的embedding table稀疏访问)等场景下时延问题尤为突出。
带宽收敛:跨节点PCIe Switch直连方案会出现带宽汇聚与争用,导致单卡可用带宽下降。
成本高:跨节点通信依赖额外的PCIe lanes和NIC设备,带来更高成本。
基于灵衢互联的集群组网可以打破这些限制,实现:
跨节点带宽零收敛:节点间大带宽低延迟通信,无带宽收敛
统一编址:基于灵衢互联,并结合openEuler的GMEM成熟生态,可以实现超节点内GPU、CPU、内存的统一编址
硬件成本优化:无需额外互联设备,即可实现多节点高性能通信
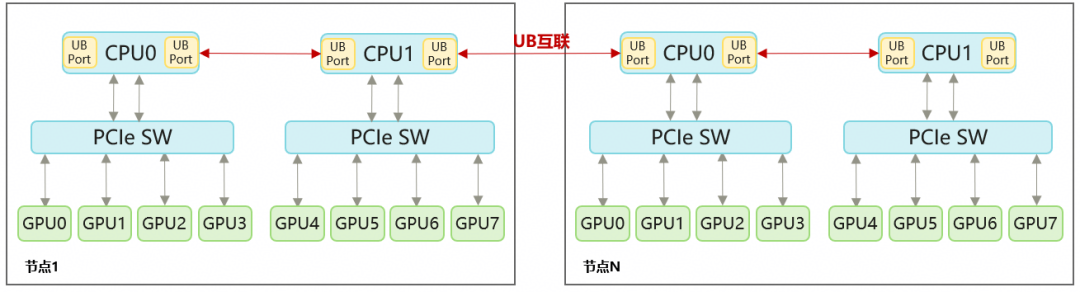
图3:基于灵衢互联的多节点集群组网方案
鲲鹏CPU服务器原生同时提供PCIe接口与UB接口,叠加灵衢能力,实现:
支持本地CPU-GPU与GPU-GPU通信
支持多节点算力卡灵衢互联,形成高带宽低延迟的小型多机推理集群
最大可挂载64张计算卡,满足:
-
单机算力卡间的TP并行带宽与时延需求
-
多机间的EP并行与稀疏数据访问带宽与时延需求
-
KV Cache数据传输的分时复用带宽需求
-
未来异构计算(如 Engram)带来的带宽与时延需求
整个集群无需额外互联设备,实现了轻量化、易部署、高性价比的推理方案。
同时,鲲鹏多机推理集群结合CPU节点间统一内存编址优势,可以为KV Cache提供跨节点大容量DDR存储,并有效减少每个节点上Engram的重复内存开销,从而进一步提升资源利用率与系统吞吐。
基于鲲鹏处理器和灵衢互联的大带宽、低时延以及内存语义通信,我们构建对等计算架构,减少数据交换,打造高性能计算网络,助力算力卡集群组网,在MoE大模型轻量推理场景下实现有效算力提升。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 2
2 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)