
数据库字符集比较性能新突破:鲲鹏ARM SIMD加速引擎,让排序与哈希效率倍增!
一条看似普通的ORDER BY name查询,在数据量翻倍后,响应时间常常不止翻两倍——三倍、五倍的退化在线上系统中并不罕见。LIKE 'abc%'这样的前缀匹配,放在百万行级别的大表上,耗时动辄以秒计。GROUP BY分组查询随着数据增长,性能曲线不断下滑。
查索引、看执行计划、调缓冲池、甚至升级硬件规格,折腾一圈下来,瓶口依然卡在同一个地方。原因出在一个几乎被所有人忽略的角落——字符集比较。
MySQL/Percona在排序、分组、去重、索引比较乃至表连接等操作中,底层都在密集地执行字符集处理。这些处理涉及多字节解码、大小写归一化、排序权重映射、逐权重比较等一系列流程。表里只有几千行数据时几乎感知不到,可一旦规模到了几百万、上亿行,这部分开销就成了实实在在的CPU瓶颈——它不直接出现在EXPLAIN输出里,却真实地拖慢着每一条SQL的响应时间。
鲲鹏BoostKit正式推出字符集处理SIMD优化方案,针对MySQL/Percona字符集比较热点路径进行深度加速,排序、分组、哈希操作效率获得成倍提升。
字符集比较:一笔被忽略的“CPU账单”
先理清一个基本问题:数据库比较两个字符串,究竟在比什么?
以最常用的utf8mb4_general_ci排序规则为例。当数据库需要判断“abc”和“ABC”是否等价、或者确定两者的先后顺序时,内部走的是这样一套流程:
将每个字符从多字节编码解码为宽字符
根据排序规则进行大小写归一化
查排序权重表,获取每个字符的排序权重
从左到右逐权重比较
utf8mb4编码下,单个字符可能占1到4个字节,每个字符都要完整走完上述流程。
但这里存在一个巨大的优化空间:对ASCII字符(英文字母、数字、常见标点),上述步骤绝大多数是多余的。ASCII字符在utf8mb4中仅占1个字节,解码基本不花力气;大小写之间只差一个比特位(0x20),完全不需要查表。然而数据库的字符集处理逻辑并不会区分“简单字符“和“复杂字符“——它按统一流程,一个字符一个字符地处理到底。
在实际业务中,用户名、邮箱、订单号、商品编码、手机号——这些字段的内容绝大多数是ASCII数据。传统实现对所有字符一视同仁的做法,等于在大量的“轻量级”字符上执行了“重量级”的处理流程,白白消耗了大量CPU周期。这种冗余处理,是数据库排序和比较场景中一块隐蔽但可观的性能短板。
鲲鹏ARM SIMD:用向量化替代逐字循环
解决这个问题的钥匙,藏在鲲鹏处理器的硬件能力中。
鲲鹏处理器基于ARM架构,原生支持两套SIMD指令集——NEON(ARM高级SIMD扩展)和SVE(可伸缩向量扩展)。它们的核心思路很直接:一条指令,同时操作多份数据。
传统逐字符处理就好比一条单车道,一次只放行一辆车。SIMD则相当于把这条路扩成了多车道高速——同样的时间窗口里,通行的数据量翻了十几倍。
NEON:固定128位宽,单次处理16个字节,一条指令即可完成16个字符的判定或运算。
SVE(鲲鹏差异化优势):支持256位宽(2×256bit)。相比市面上仅提供128位SVE的ARM处理器,鲲鹏单次能处理32个字节,吞吐直接翻倍。SVE的向量宽度在运行时动态可探测,一套通用代码即可自动适配不同宽度的硬件——“可伸缩”的含义正在于此。
以处理32个ASCII字符为例,下图直观展示传统逐字符处理与SIMD批量处理的吞吐差距:传统标量需要32次循环迭代,NEON仅需2次,SVE一次搞定。
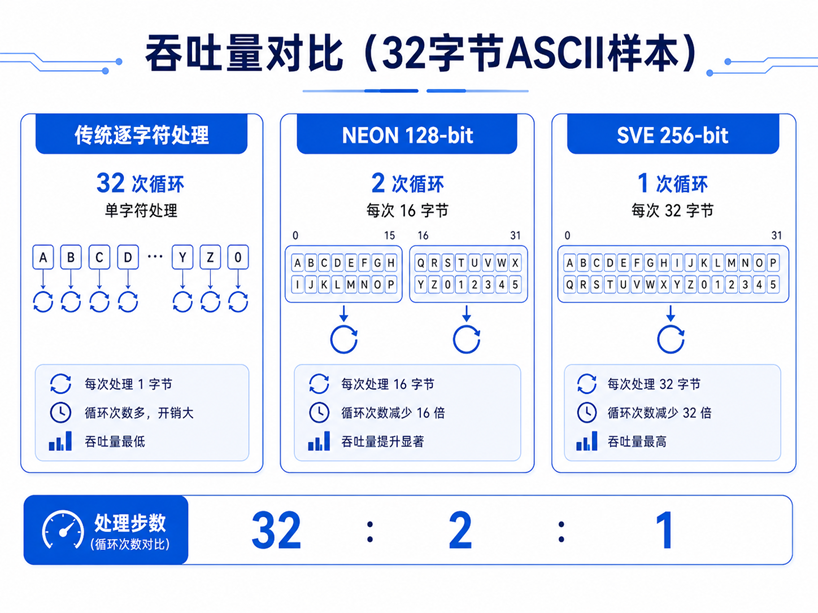
原本需要循环16次甚至32次的字符操作,现在被压缩为一条指令。当这个16倍、32倍的加速作用于数百万行数据的排序、分组和哈希运算时,累积收益相当可观。
ARM SIMD加速在MySQL框架中的位置
ARM SIMD优化并非局限于某一个模块,而是覆盖了从SQL执行到存储引擎的多个关键路径。下图以四层子图全景呈现六个核心加速热点函数的位置,箭头标注了数据在各层之间的流转关系:
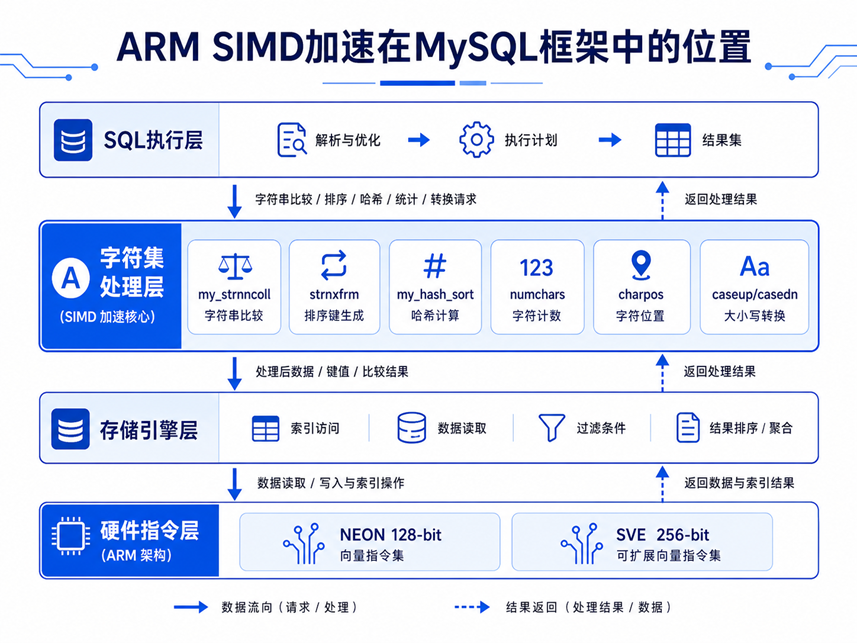
从图中可以清晰看到:
加速点集中于MySQL Server层的字符集处理模块,横跨SQL执行与存储引擎之间的所有字符串操作路径
my_strnncoll(字符串比较)是排序、分组、连接操作最终调用的底层函数,也是加速收益最大的单一热点
strnxfrm(排序键生成)是ORDER BY的核心依赖,批量展开ASCII字符权重直接决定排序吞吐
my_hash_sort(哈希计算)在MEMORY引擎和哈希分区场景中是关键路径,批量哈希更新大幅降低函数调用频率
SVE 256位宽的物理寄存器在鲲鹏处理器上可直接利用,无需修改上层调用逻辑
三大优化策略,贯穿字符处理全链路
鲲鹏BoostKit字符集SIMD优化覆盖了MySQL/Percona中多个核心热点路径,涉及字符串比较、排序键生成、哈希计算、字符计数、大小写转换、通配匹配等高频操作。整体思路可以归纳为以下三条主线:
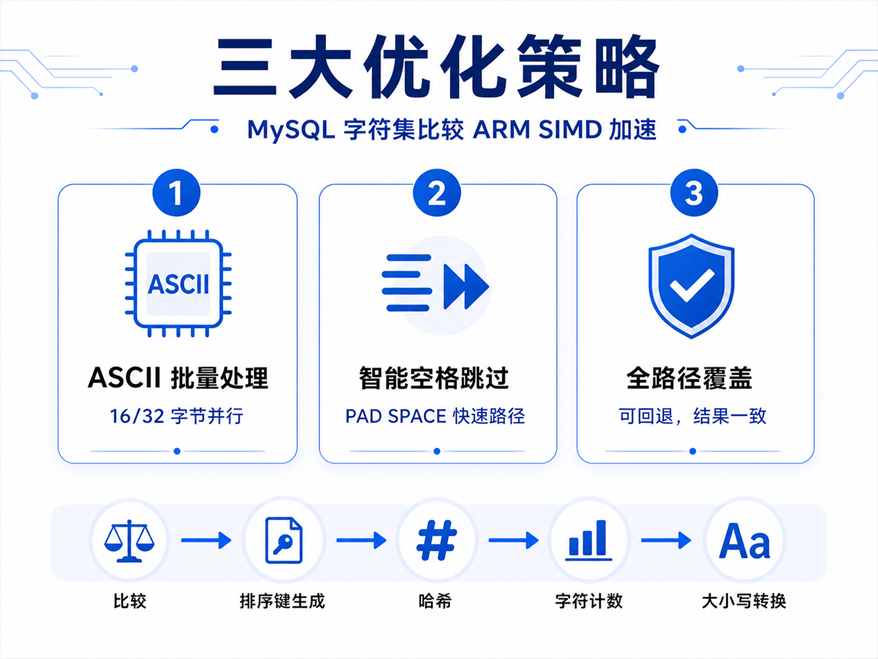
策略一:ASCII批量处理——16/32字节一步完成
这是整套优化的基石。传统实现遵循“逐字符解码→逐字符查表→逐字符映射→逐字符比较”的循环模式,每个字符独立走完一个完整周期。
鲲鹏BoostKit的改造思路是:在比较路径上,当数据以ASCII为主时,一次性加载一个向量块(NEON 16字节或SVE 32字节),在这个块内批量完成ASCII判定、大小写归一化、权重映射和比较/哈希更新。
以哈希计算为例:在MEMORY引擎和哈希分区场景中,数据库需要对字符串计算排序哈希值。传统方式逐字符读取、逐个累加哈希状态,16个字符就要调用16次哈希更新函数。SIMD版本将这16个ASCII字符的权重一次性映射并累积到哈希状态中,调用频次降为原来的1/16。排序键生成同理——ORDER BY依赖的strnxfrm将ASCII字符批量展开为排序权重写入缓冲区,循环迭代次数大幅缩减。
策略二:智能空格跳过——PAD SPACE比较的路径优化
utf8_general_ci、utf8_unicode_ci等排序规则遵循PAD SPACE语义,即字符串尾部的空格不参与比较。传统实现在比较主循环中遇到空格时,需要逐个字节地检查后续是否也全是空格——一个字节一个字节地挪,在最坏情况下开销很大。
鲲鹏BoostKit引入了双指针同步跳过机制:当左右字符串的当前位置同时为空格时,加载16字节向量一次性检测是否为全空格块,直接跳过整段连续空格。在字符串包含大量对齐空格的业务场景中,这一优化效果尤为明显。
策略三:全路径覆盖与代码收敛——不给优化留盲区
除上述两大核心加速点外,鲲鹏BoostKit还对以下路径进行了系统性的SIMD改造:
InnoDB行格式写入中的尾部空格裁剪:将两处手写裁剪循环统一为复用skip_trailing_space(),裁剪逻辑同步享受SIMD加速
字符数统计与位置定位(numchars / charpos):ASCII前缀按向量宽度批量推进
合法UTF8前缀长度检查(well_formed_len):ASCII段批量通过,跳过逐字节校验
UCA排序规则路径:utf8_unicode_ci、utf8mb4_unicode_ci和utf8mb4_0900_ai_ci的可打印ASCII前缀加速
大小写转换:caseup / casedn路径的ASCII段批量归一化
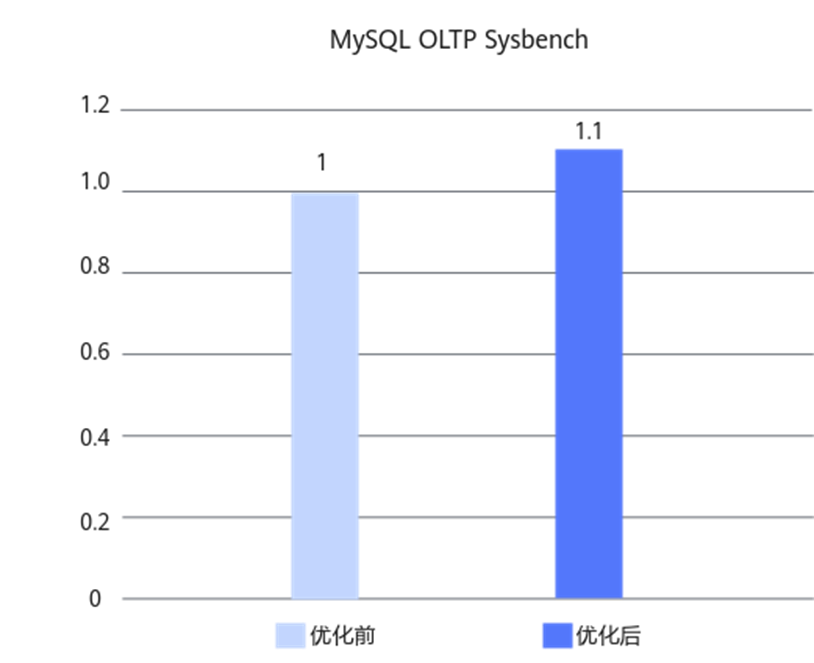
实测数据:在鲲鹏920服务器8C16G容器规格的Percona-Server 5.7.44-53环境中,记录匹配优化、字符集处理SIMD优化和非对齐内存访问优化三个特性叠加后,Sysbench只读场景性能提升约10%。
安全回退机制:能加速则加速,不能则原路
一个很自然的疑问:如果数据中混入了中文、日文、emoji,或者使用了自定义排序规则,这套SIMD加速会不会产生错误的比较结果?
答案是:不会。
下图展示SIMD快路径的完整决策流程——四级准入检查全部通过才进入批量处理,任一环节不满足即回退:
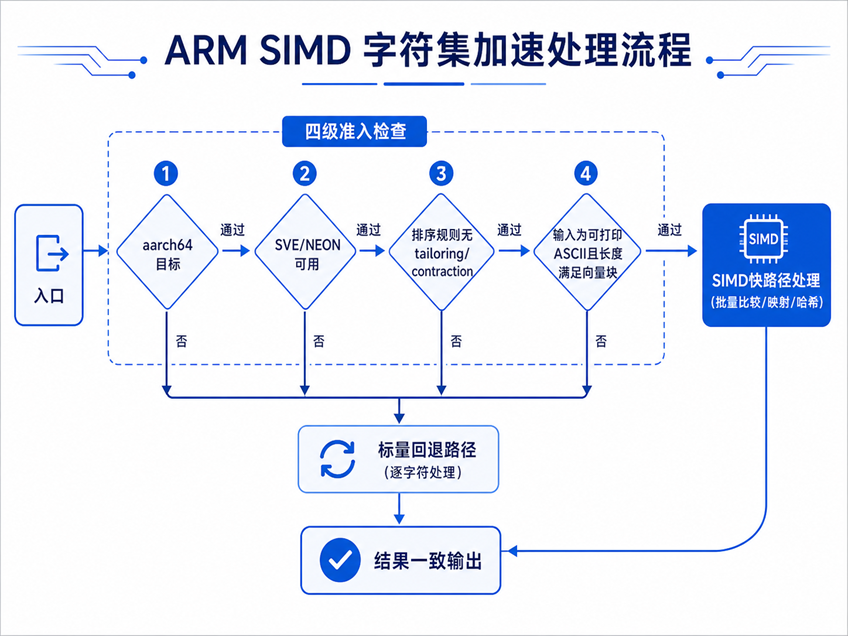
鲲鹏优化方案在每条快路径的入口都设置了多层守卫检查:
编译目标非aarch64 → 不走快路径
运行时无SVE硬件支持 → 自动回退到NEON或标量路径
排序规则存在tailoring定制或contraction收缩字符(如匈牙利语的cs、ch)→ 全量走原始逻辑
输入中出现非ASCII或不可打印字符 → 立即退出快路径
尾段不足一个向量宽度 → 不做部分写,回退到逐字节处理
无论数据多复杂、排序规则多特殊,优化前后的比较结果、排序顺序、哈希值完全一致。SIMD只在“能加速的地方”出力,在“不能加速的位置”安静退让。对上层SQL和业务逻辑来说,这一切完全透明——不需要改一行应用代码,不需要调整任何SQL写法。
哪些业务场景最能受益
ARM SIMD优化在ASCII数据占比高的场景中收益最集中。以下几类业务尤其值得关注:
电商搜索与推荐
商品名称、品牌名、SKU编码的主体是ASCII字符。在商品池千万级的电商平台中,ORDER BY排序和LIKE前缀匹配是每秒都在跑的高频操作。SIMD批处理将字符串比较吞吐提升数倍,用户搜索响应更流畅,推荐排序更新更快。在大促峰值期间,这种加速能为系统挤出宝贵的CPU余量来应对流量洪峰。
金融交易系统
交易流水号、用户ID、机构代码等字段以ASCII为主。交易监控、风控规则匹配、历史对账中密集的GROUP BY和哈希分区操作,受益于批量哈希计算与排序键生成的加速,CPU占用明显下降,系统吞吐提升。在毫秒级响应的风控场景中,每一次排序和比较的加速都直接关系到规则的实时命中率。
用户中心与身份管理
用户名、邮箱、手机号是典型的ASCII字符串。登录校验、权限匹配、批量导入去重等场景频繁涉及字符串等值比较和排序。SIMD快路径让MEMORY引擎的哈希查找和B+树索引的比较效率显著提升。对拥有数亿注册用户的大型平台而言,每次登录验证节省的微秒级时间,放大到日均数十亿次调用上就是一笔可观的算力节约。
CRM与客户数据平台
客户姓名(拼音/英文)、联系人信息、地址编码等大量使用ASCII。客户分群、标签匹配、排序展示等操作在千万级客户数据上运行,SIMD加速让数据处理响应时间更短,业务决策周期进一步缩短。
安装与启用
ARM SIMD加速方案已作为鲲鹏BoostKit使能套件的一部分正式发布。以下是资源获取与安装指引。

表1 硬件要求
|
项目 |
名称 |
版本 |
获取地址 |
|
操作系统 |
openEuler 22.03 LTS SP4 |
openEuler 22.03 LTS SP4 for ARM |
https://repo.openeuler.org/openEuler-22.03-LTS-SP4/ISO/aarch64/openEuler-22.03-LTS-SP4-everything-aarch64-dvd.iso |
|
操作系统 |
openEuler 24.03 LTS SP3 |
openEuler 24.03 LTS SP3 for ARM |
https://repo.openeuler.org/openEuler-24.03-LTS-SP3/ISO/aarch64/openEuler-24.03-LTS-SP3-everything-aarch64-dvd.iso |
|
MySQL |
percona-server-8.0.43-34 |
8.0.43-34 |
https://github.com/percona/percona-server/archive/refs/tags/Percona-Server-8.0.43-34.tar.gz |
|
boost |
boost_1_77_0 |
- |
http://downloads.sourceforge.net/project/boost/boost/1.77.0/boost_1_77_0.tar.gz |
|
MySQL |
percona-server-5.7.44-53 |
5.7.44-53 |
https://github.com/percona/percona-server/archive/refs/tags/Percona-Server-5.7.44-53.tar.gz |
|
boost |
boost_1_59_0 |
- |
http://downloads.sourceforge.net/project/boost/boost/1.59.0/boost_1_59_0.tar.gz |
|
补丁文件 |
0001-refactor-character-set-handling-for-aarch64-architec.patch |
8.0.43-34 |
https://gitcode.com/boostkit/mysql/blob/MySQL-Percona-Server-8.0.43-34/boostdb-patches/0001-refactor-character-set-handling-for-aarch64-architec.patch |
|
补丁文件 |
0001-refactor-character-set-handling-for-aarch64-architec.patch |
5.7.44-53 |
https://gitcode.com/boostkit/mysql/blob/MySQL-Percona-Server-5.7.44-53/boostdb-patches/0001-refactor-character-set-handling-for-aarch64-architec.patch |
表2 操作系统和软件要求
安装步骤
将MySQL字符集优化特性Patch包合入MySQL源码并完成编译安装后即可使用。以Percona-Server 8.0.43-34为例:
-
获取并解压MySQL源码,进入源码目录。MySQL源码获取路径请参见表2操作系统和软件要求。
tar -xzvf Percona-Server-8.0.43-34.tar.gzcd percona-server-8.0.43-34
-
获取MySQL字符集优化特性Patch包并存放至服务器本地路径(例如 /home),patch获取路径请参见表2操作系统和软件要求。
-
合入Patch包。
dos2unix /home/0001-refactor-character-set-handling-for-aarch64-architec.patchgit apply --check -p1 </home/0001-refactor-character-set-handling-for-aarch64-architec.patchgit apply --whitespace=nowarn -p1 </home/0001-refactor-character-set-handling-for-aarch64-architec.patch
回显中无报错信息即表示Patch已成功应用。
-
编译安装MySQL。请参见《Percona移植指南》。
-
在MySQL配置文件 /etc/my.cnf中增加字符序配置。
打开配置文件:
vi /etc/my.cnf按i进入编辑模式。
字符集为utf8时,在[mysqld]下增加以下配置:
character_set_server = utf8collation_server = utf8_general_ci
字符集为utf8mb4时,在[mysqld]下增加以下配置:
character_set_server = utf8mb4collation_server = utf8mb4_general_ci
-
按Esc退出编辑模式,输入 :wq!保存并退出。
-
启动数据库。操作请参见《MySQL移植指南》的运行MySQL章节。
-
以数据库sbtest中的表sbtest1为例,查询数据库和表的字符集、字符序配置:
showcreate database sbtest;SHOW VARIABLES LIKE'collation_database';showcreatetable sbtest1;showfull columns from sbtest1;showtable status from sbtest like'sbtest%';
说明:进入客户端的操作请参见《MySQL移植指南》的运行MySQL章节。
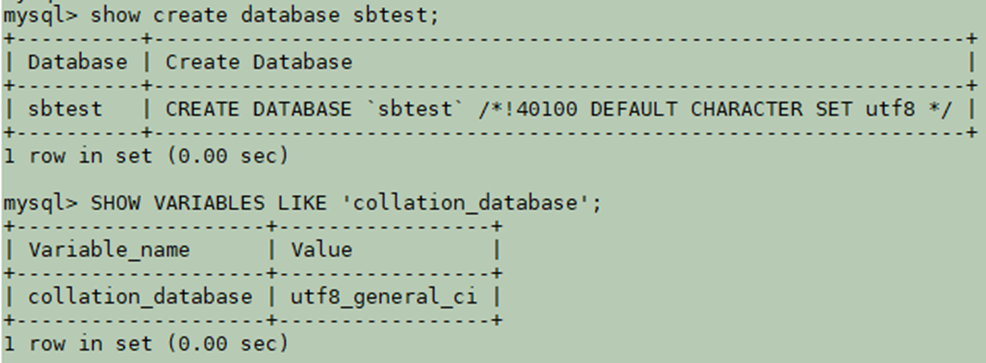
图1 查询数据库字符集、字符序
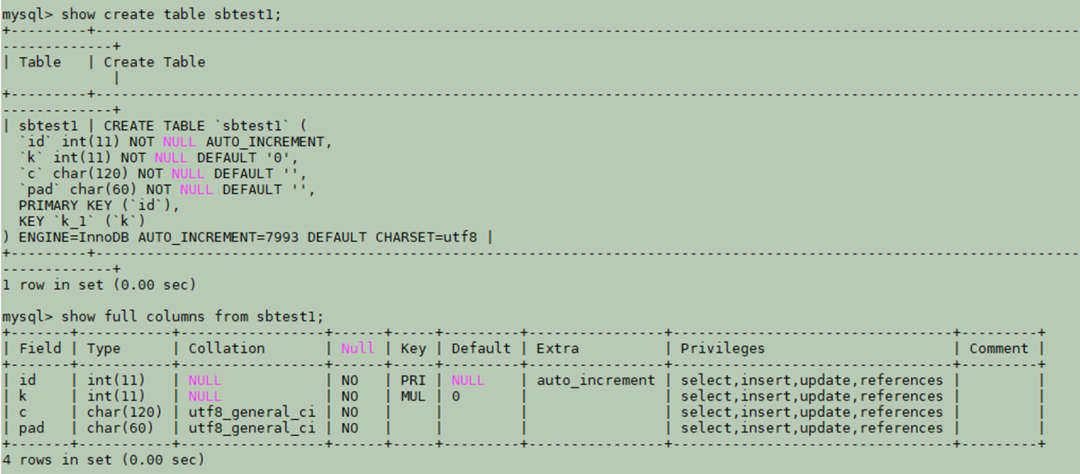
图2 查询表的字符集、字符序

图3 获取数据库的表信息,collation列即为字符序
合入补丁、重新编译后,无需修改任何应用代码,SQL查询自动享受SIMD加速。更多详细指导,请参见鲲鹏BoostKit字符集处理 SIMD优化特性指南。
字符集比较——数据库中最不起眼却又无处不在的基础操作。鲲鹏ARM SIMD加速方案,用向量化批处理替代逐字符循环,充分释放每一条SQL背后的CPU算力。合入补丁,重新编译,即刻享受加速红利。
你的业务在数据库排序和字符比较上遇到过性能瓶颈吗?欢迎在评论区聊聊你的经验和见解。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 0
0 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)