
基于MindCluster的昇腾集群秒级故障检测机制
摘要:昇腾实战派介绍了MindCluster针对昇腾设备集群的故障检测机制,可秒级完成NPU芯片、服务器硬件及参数面网络的故障检测与隔离。关键能力包括:1)通过Ascend Device Plugin组件实时上报NPU芯片故障;2)利用NodeD和Kubelet检测服务器硬件与共享存储故障;3)快速识别ROCE网络和灵衢总线设备故障。部署时需根据设备类型选择适配的YAML配置文件,并支持自定义启动
作者:昇腾实战派
1. 技术特性与价值
随着大模型预训练技术的发展,模型参数量以及数据量极速膨胀,因此在训练模型时将使用千卡甚至万卡规模的设备进行训练。与通用计算不同,AI分布式训练涉及到更多数量的硬件器件,同时其中任何一个器件的失效都有可能导致训练的中断。每次训练中断时故障器件的排除成为了运维人员在AI计算的首要难题,快速且精准地找到故障设备能够降低大量的训练成本。MindCluster针对昇腾设备集群提供了一套故障检测机制,能够秒级完成昇腾相关设备的故障检测与隔离,用户可以根据MindCluster上报的集群设备故障信息,排除集群中出现异常的设备。
2. 关键能力
2.1 NPU芯片故障检测
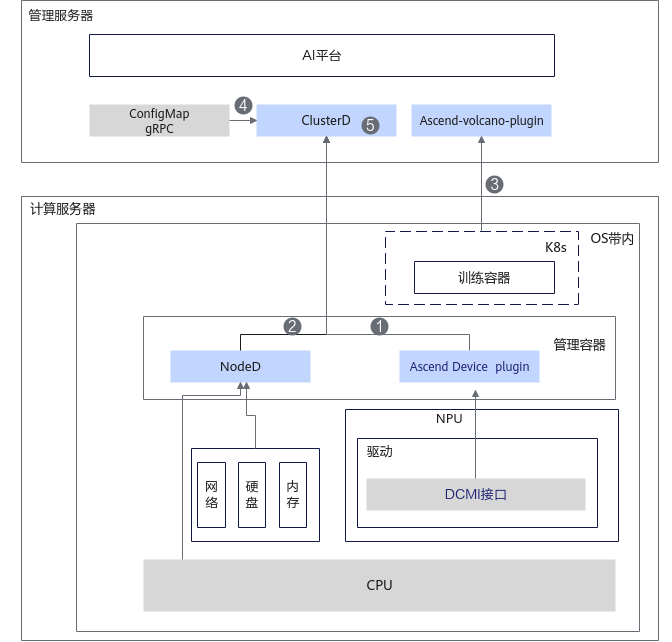
芯片故障指的是NPU出现的基础软件类故障和芯片硬件类故障。MindCluster在集群的NPU节点部署Ascend Device Plugin组件,Ascend Device Plugin组件除了提供基础的设备发现和挂载功能外,还负责NPU相关故障的检测。
NPU内部具有故障检测机制,NPU故障后将故障事件通知到Ascend Device Plugin,Ascend Device Plugin对故障信息进行处理后对外上报该故障信息,这一过程将在1秒内完成。对外上报故障信息的接口当前主要以K8S的Configmap承载,将刷新故障信息到Configmap中,用户可以在深度学习平台的管理面或者业务容器挂载获取该节点的NPU故障信息。
2.2 服务器故障检测
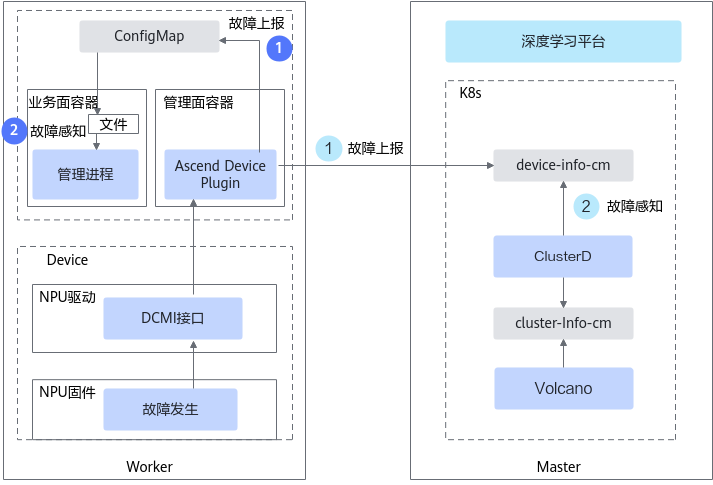
服务器故障指的是NPU所在AI服务器上除了NPU外的其他软硬件的故障信息。MindCluster在集群的NPU节点部署NodeD组件,NodeD组件提供服务器相关软硬件的故障检测,此外,MindCluster还复用了kubelet的节点健康检测能力,会基于NodeD和Kubelet获取服务器故障信息。
- 服务器心跳状态
Kubelet将定期与Api-Server发送心跳,当Api-Server发现某个节点的心跳丢失后,将把该节点的状态置为Not Ready,MindCluster将节点Not Ready的服务器检测为服务器不可用。 - 服务器硬件故障
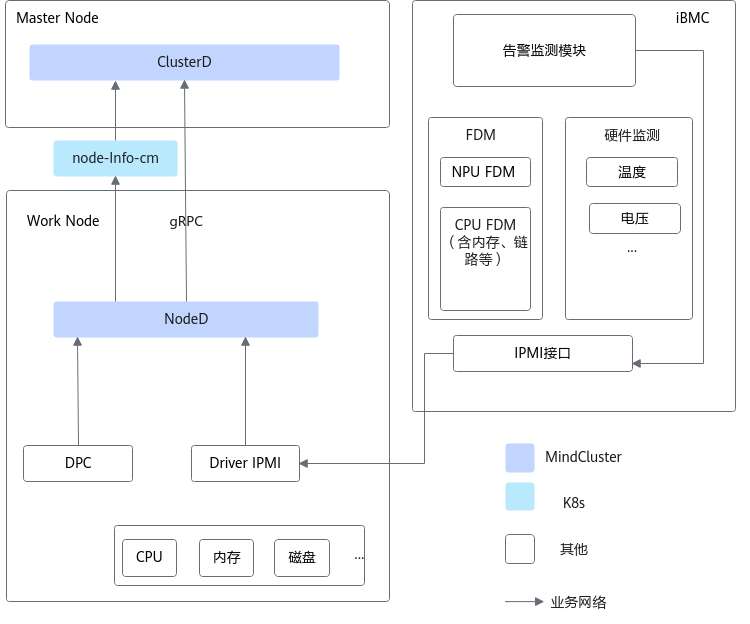
针对服务器硬件故障,NodeD通过IPMI驱动向iBMC发送故障查询请求,iBMC将当前硬件告警信息响应给NodeD。NodeD收集硬件告警信息后,将节点硬件状态对外上报信息。 - 服务器DPC共享存储故障
针对共享存储服务DPC,NodeD将基于DPC服务的过程记录信息检测DPC存储服务的故障,检测故障后将该信息对外上报。
2.3 参数面网络检测
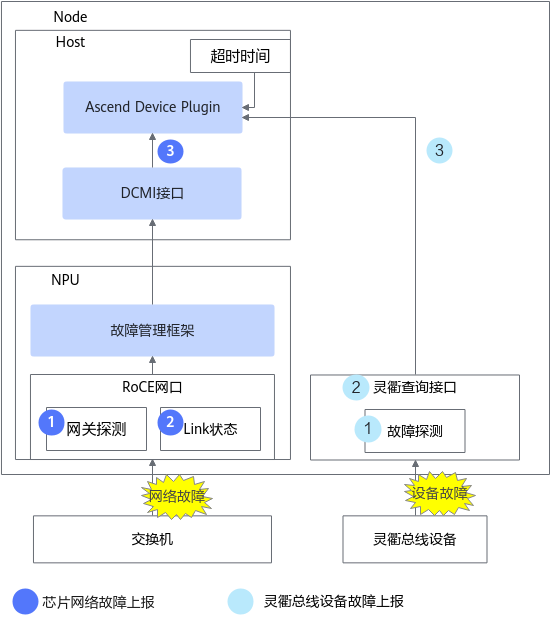
NPU的参数面网络故障包括ROCE网络相关故障和灵衢总线设备故障。参数面网络出现故障时,通常将导致训练任务中断或者训练任务性能劣化。
- ROCE网络故障,在昇腾A2和A3设备上,ROCE网口是NPU上直出,因此NPU具有其直出的ROCE网络的故障检测机制,ROCE故障后将故障事件通知到Ascend Device Plugin。
- 灵衢总线设备故障,灵衢总线设备当前仅在昇腾A3设备上使用,灵衢总线设备驱动将检测对应的灵衢总线设备的故障信息,灵衢网络故障后将故障事件通知到Ascend Device Plugin。
Ascend Device Plugin对故障信息进行处理后对外上报该故障信息,这一过程将在1秒内完成。对外上报故障信息的接口当前主要以K8S的Configmap承载,将刷新故障信息到Configmap中,用户可以在深度学习平台的管理面或者业务容器挂载获取该节点的NPU故障信息。Ascend Device Plugin对故障信息进行处理后对外上报该故障信息
3. 快速部署
3.1 安装Ascend Device Plugin组件
操作步骤
-
以root用户登录各计算节点,并执行以下命令查看镜像和版本号是否正确。
docker images | grep k8sdeviceplugin回显示例如下:
ascend-k8sdeviceplugin v7.1.RC1 29eec79eb693 About an hour ago 105MB -
将Ascend Device Plugin软件包解压目录下的YAML文件,拷贝到K8s管理节点上任意目录。请注意此处需使用适配具体处理器型号的YAML文件,并且为了避免自动识别Ascend Docker Runtime功能出现异常,请勿修改YAML文件中DaemonSet.metadata.name字段,详见下表。
表2 Ascend Device Plugin的YAML文件列表展开| YAML文件列表 | 说明 |
| ---------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------- |
| device-plugin-310-v*{version}.yaml | 推理服务器(插Atlas 300I 推理卡)上不使用Volcano的配置文件。 |
| device-plugin-310-volcano-v{version}.yaml | 推理服务器(插Atlas 300I 推理卡)上使用Volcano的配置文件。 |
| device-plugin-310P-1usoc-v{version}.yaml | Atlas 200I SoC A1 核心板上不使用Volcano的配置文件。 |
| device-plugin-310P-1usoc-volcano-v{version}.yaml | Atlas 200I SoC A1 核心板上使用Volcano的配置文件。 |
| device-plugin-310P-v{version}.yaml | Atlas 推理系列产品上不使用Volcano的配置文件。 |
| device-plugin-310P-volcano-v{version}.yaml | Atlas 推理系列产品上使用Volcano的配置文件。 |
| device-plugin-910-v{version}.yaml | Atlas 训练系列产品、Atlas A2 训练系列产品、Atlas A3 训练系列产品或Atlas 800I A2 推理服务器、A200I A2 Box 异构组件上不使用Volcano的配置文件。 |
| device-plugin-volcano-v{version}*.yaml | Atlas 训练系列产品、Atlas A2 训练系列产品、Atlas A3 训练系列产品或Atlas 800I A2 推理服务器、A200I A2 Box 异构组件上使用Volcano的配置文件。 | -
如不修改组件启动参数,可跳过本步骤。否则,根据实际情况修改Ascend Device Plugin的启动参数。启动参数请参见表3,可执行**./device-plugin** -h查看参数说明。
- 在Atlas 200I SoC A1 核心板节点上,修改启动脚本“run_for_310P_1usoc.sh”中Ascend Device Plugin的启动参数。修改完后需在所有Atlas 200I SoC A1 核心板节点上重新制作镜像,或者将本节点镜像重新制作后分发到其余所有Atlas 200I SoC A1 核心板节点。说明如果不使用Volcano作为调度器,在启动Ascend Device Plugin的时候,需要修改“run_for_310P_1usoc.sh”中Ascend Device Plugin的启动参数,将“-volcanoType”参数设置为false。
- 其他类型节点,修改对应启动YAML文件中Ascend Device Plugin的启动参数。
-
根据需要使用的故障处理模式,修改Ascend Device Plugin组件的启动YAML。
containers: - image: ascend-k8sdeviceplugin:v7.1.RC1 name: device-plugin-01 resources: requests: memory: 500Mi cpu: 500m limits: memory: 500Mi cpu: 500m command: [ "/bin/bash", "-c", "--"] args: [ "device-plugin -useAscendDocker=true -volcanoType=true # 重调度场景下必须使用Volcano -autoStowing=true # 是否开启自动纳管开关,默认为true;设置为false代表关闭自动纳管,当芯片健康状态由unhealthy变为healthy后,不会自动加入到可调度资源池中;关闭自动纳管,当芯片参数面网络故障恢复后,不会自动加入到可调度资源池中。该特性仅适用于Atlas 训练系列产品 -listWatchPeriod=5 # 设置健康状态检查周期,范围[3,1800],单位为秒 -logFile=/var/log/mindx-dl/devicePlugin/devicePlugin.log -logLevel=0" ] securityContext: privileged: true readOnlyRootFilesystem: true -
在K8s管理节点上各YAML对应路径下执行以下命令,启动Ascend Device Plugin。
- K8s集群中存在使用Atlas 训练系列产品、Atlas A2 训练系列产品、Atlas A3 训练系列产品或Atlas 800I A2 推理服务器、A200I A2 Box 异构组件的节点(配合Volcano使用,支持虚拟化实例,YAML默认开启静态虚拟化)。
kubectl apply -f device-plugin-volcano-v{version}.yaml - K8s集群中存在使用Atlas 训练系列产品、Atlas A2 训练系列产品、Atlas A3 训练系列产品或Atlas 800I A2 推理服务器、A200I A2 Box 异构组件的节点(Ascend Device Plugin独立工作,不配合Volcano使用)。
kubectl apply -f device-plugin-910-v{version}.yaml - K8s集群中存在使用推理服务器(插Atlas 300I 推理卡)的节点(使用Volcano调度器)。
kubectl apply -f device-plugin-310-volcano-v{version}.yaml - K8s集群中存在使用推理服务器(插Atlas 300I 推理卡)的节点(Ascend Device Plugin独立工作,不使用Volcano调度器)。
kubectl apply -f device-plugin-310-v{version}.yaml - K8s集群中存在使用Atlas 推理系列产品的节点(使用Volcano调度器,支持虚拟化实例,YAML默认开启静态虚拟化)。
kubectl apply -f device-plugin-310P-volcano-v{version}.yaml - K8s集群中存在使用Atlas 推理系列产品的节点(Ascend Device Plugin独立工作,不使用Volcano调度器)。
kubectl apply -f device-plugin-310P-v{version}.yaml - K8s集群中存在使用Atlas 200I SoC A1 核心板的节点(使用Volcano调度器)。
kubectl apply -f device-plugin-310P-1usoc-volcano-v{version}.yaml - K8s集群中存在使用Atlas 200I SoC A1 核心板的节点(Ascend Device Plugin独立工作,不使用Volcano调度器)。
kubectl apply -f device-plugin-310P-1usoc-v{version}.yaml
说明如果K8s集群使用了多种类型的昇腾AI处理器,请分别执行对应命令。
启动示例如下:serviceaccount/ascend-device-plugin-sa created clusterrole.rbac.authorization.K8s.io/pods-node-ascend-device-plugin-role created clusterrolebinding.rbac.authorization.K8s.io/pods-node-ascend-device-plugin-rolebinding created daemonset.apps/ascend-device-plugin-daemonset created - K8s集群中存在使用Atlas 训练系列产品、Atlas A2 训练系列产品、Atlas A3 训练系列产品或Atlas 800I A2 推理服务器、A200I A2 Box 异构组件的节点(配合Volcano使用,支持虚拟化实例,YAML默认开启静态虚拟化)。
-
在任意节点执行以下命令,查看组件是否启动成功。
kubectl get pod -n kube-system回显示例如下,出现Running表示组件启动成功。
NAME READY STATUS RESTARTS AGE ... ascend-device-plugin-daemonset-d5ctz 1/1 Running 0 11s ...
3.2 安装NodeD
操作步骤
-
以root用户登录各计算节点,并执行以下命令查看镜像和版本号是否正确。
docker images | grep noded回显示例如下:
noded v7.1.RC1 ef801847acd2 29 minutes ago 133MB -
将NodeD软件包解压目录下的YAML文件,拷贝到K8s管理节点上任意目录。
-
如不修改组件启动参数,可跳过本步骤。否则,请根据实际情况修改YAML文件中NodeD的启动参数。启动参数请参见表1,可执行**./noded-h**查看参数说明。
-
在管理节点的YAML所在路径,执行以下命令,启动NodeD。
-
不使用dpc故障检测功能,请执行以下命令。
kubectl apply -f noded-v{version}.yaml -
如果环境已部署Scale-Out Storage DPC 24.2.0及以上版本,并且使用dpc故障检测功能,则执行以下命令,启动NodeD。
kubectl apply -f noded-dpc-v{version}.yaml启动示例如下:
serviceaccount/noded created clusterrole.rbac.authorization.k8s.io/pods-noded-role created clusterrolebinding.rbac.authorization.k8s.io/pods-noded-rolebinding created daemonset.apps/noded created
-
-
执行以下命令,查看组件是否启动成功。
kubectl get pod -n mindx-dl回显示例如下,出现Running表示组件启动成功。
NAME READY STATUS RESTARTS AGE ... noded-fd6t8 1/1 Running 0 74s ...
4. 集成接口
4.1 ascend-device-plugin相关接口
接口形式:k8s configmap
具体故障信息可参考ascend-device-plugin芯片资源信息上报接口
4.2 noded相关接口
接口形式:k8s configmap
具体故障信息可参考noded服务器资源信息上报接口

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)