
昇腾NPU适配Ola-Omni全模态大模型实战
本文基于昇腾CANN生态,成功实现了全模态语言模型Ola-Omni在昇腾NPU上的端到端训练适配。通过环境搭建、代码适配和三阶段微调训练的全流程实践,验证了该模型在国产算力平台上的可行性。关键成果包括:完成环境配置与依赖处理,实现自动迁移和性能优化,三阶段微调训练loss稳定下降。该实践为全模态大模型在昇腾平台的部署提供了可复用方案,展现了国产AI生态在多模态领域的应用潜力。
作者:昇腾实战派
一、背景概述
Ola是一款全模态语言模型,与专用模型相比,它在图像、视频和音频理解方面均取得了极具竞争力的性能。Ola 支持包括文本、图像、视频和音频在内的全模态输入,能够同时处理这些输入,并在理解所有这些模态的任务中都表现出色。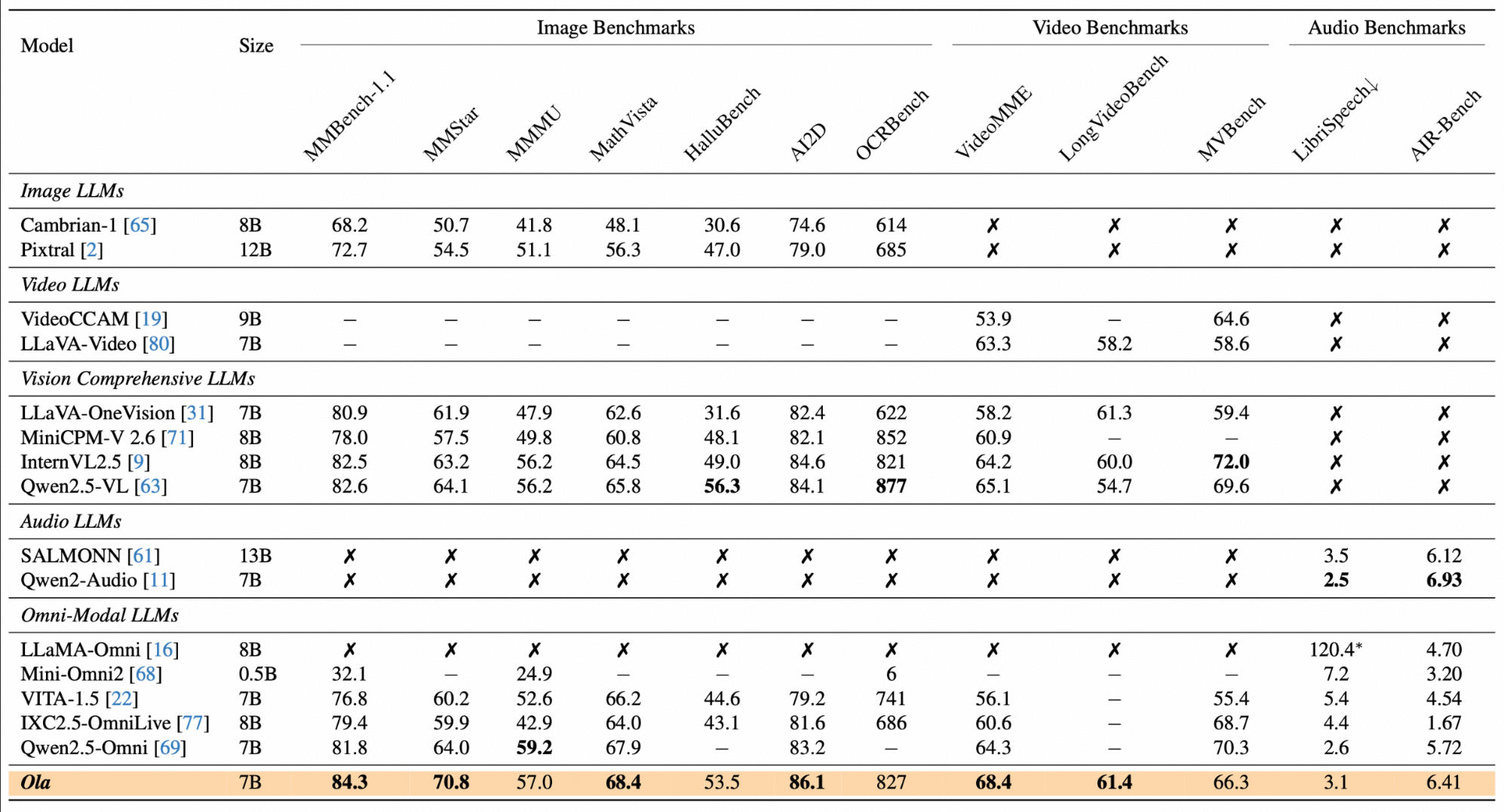
本文基于最新版 Ola-Omni框架,结合昇腾CANN生态,完整复现了从环境构建、代码适配到三阶段微调训练的全流程实践,验证了在昇腾NPU上运行全模态大模型的可行性与高效性。
✅ 核心成果:成功实现Ola模型在昇腾NPU上的端到端训练,微调三个stage跑通,Loss稳定下降,模型收敛良好,为全模态大模型在国产算力平台上的部署铺平道路。
二、适配方案
1.环境搭建
机器型号:Atlas 800T A3 训练服务器
CANN:8.5.0
HDK:25.5.1
pytorch:2.8.0
首先需要安装cann(安装指导)。其他可先按照原本环境搭建方式进行部署环境,遇到版本冲突时可灵活调整
(1)克隆仓库
git clone https://github.com/Ola-Omni/Ola
cd Ola
(2)安装所需软件包
conda create -n ola python=3.10 -y
conda activate ola
pip install --upgrade pip
pip install -e .
(3)安装用于训练案例的附加软件包
pip install -e ".[train]"
在此过程中会发现找不到omegaconf的指定版本2.0.6,可灵活升级为2.3.0版本即可。
删除bitsandbytes0.46.1,因BF16无需量化,与BF16训练中冲突直接移除
torch版本要求2.1.2,由于torch_npu需要和torch版本配套,没有2.1.2的配套版本,torch可直接升级版本2.8.0,下载配套的torch_npu即可
针对有些模块,可进行编译安装,如decord,若预编译包不兼容 NPU 架构,需手动编译源码:
步骤 1:克隆指定版本源码
git clone --branch v0.6.0 https://github.com/dmlc/decord.git
cd decord
# 初始化子模块(关键:解决源码依赖缺失)
git submodule update --init --recursive
步骤 2:安装编译依赖(NPU 环境需提前装系统依赖)
# 适用于 CentOS/RHEL
yum install -y gcc gcc-c++ cmake ffmpeg-devel
# 适用于 Ubuntu/Debian
apt-get install -y gcc g++ cmake libavcodec-dev libavformat-dev libavutil-dev libswscale-dev
步骤 3:编译并安装 decord
mkdir build && cd build
# 针对 NPU 架构(如昇腾 ARM64)指定编译参数,默认参数适配多数场景
cmake -DCMAKE_INSTALL_PREFIX=/usr/local -DUSE_CUDA=OFF .. # NPU 环境关闭 CUDA
make -j$(nproc)
make install
# 安装 Python 绑定
cd ../python
pip install -e . -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
针对环境问题,按照提示的缺失依赖进行安装
2.适配替换
(1)在最外层的训练脚本中加入自动迁移,如在train.py中加入自动迁移,直接导入
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
(2)关闭TF32精度类型参数
(3)针对flash_attn_func、flash_attn_varlen_func按照指导替换。
在模型初始化时将attn_implementation改为"sdpa",sdpa已适配NPU,直接调用即可调用到FA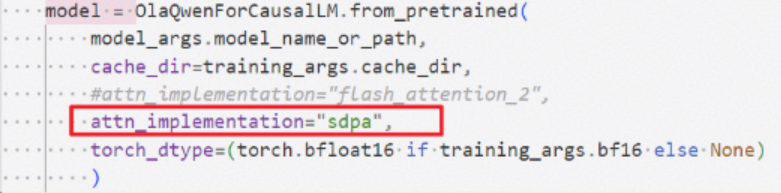
(4)部分计算在性能影响不大的情况下,可移至cpu进行计算后再转至npu,如下:
适配主要方式就是加载自动迁移后,运行模型去跟踪问题进行处理。
3.进行微调训练
将数据集处理目标结构后即可进行微调训练,经过验证,3个stage都可正常训练,loss呈下降趋势,适配成功
三、总结
本实践的核心价值
| 项目 | 实现成果 |
|---|---|
| ✅ 全模态支持 | 文本、图像、视频、音频输入统一处理 |
| ✅ 三阶段微调成功 | Loss稳定下降,训练可闭环 |
| ✅ 可复用性强 | 适用于其他多模态模型在昇腾平台的迁移 |
欢迎广大开发者加入昇腾社区,共同探索全模态AI在国产化AI生态中的无限可能!
📎 附:参考链接

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)