
稀疏矩阵向量乘法(SpMV)AscendC算子的设计与实现
作者:昇腾实战派
一、背景
在NPU上实现csr格式的稀疏矩阵向量乘法(Sparse Matrix-Vector Multiplication,SpMV)是许多高性能计算和机器学习应用中的常见需求。然而,当前CANN框架中尚未提供该算子的实现。本文将详细介绍SpMV算法的原理、算子的设计方案以及开发过程中遇到的性能和精度问题。
二、SpMV介绍
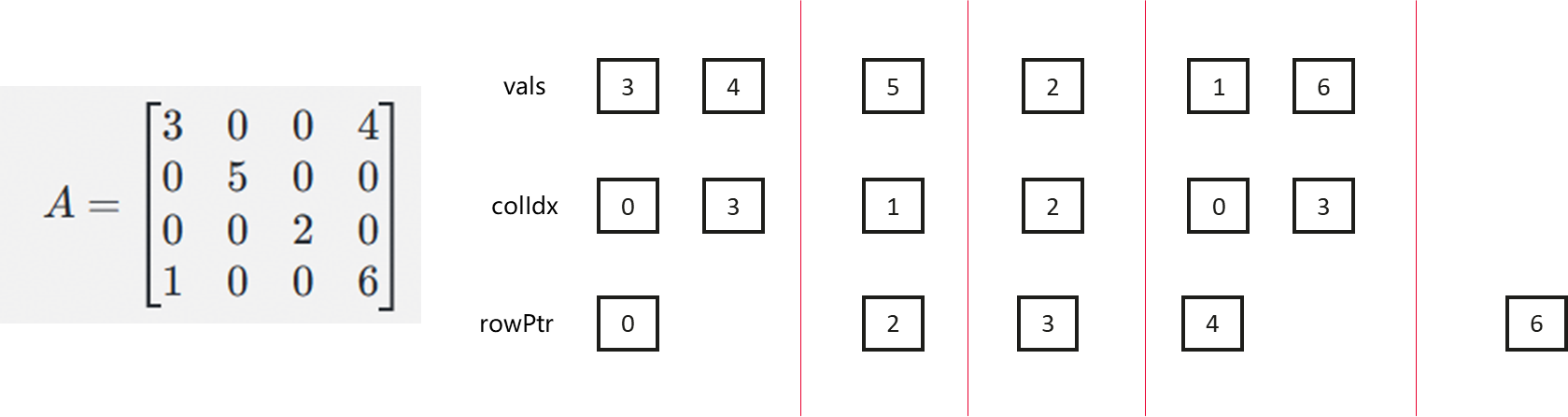
当矩阵中存在大量0时,存储整个矩阵会耗费大量空间。因此,可以使用一些稀疏矩阵的表示方法来表示稀疏矩阵。在本案例中,我们使用csr格式来表示稀疏矩阵。csr格式包含三个关键变量:vals、colIdx和rowPtr。其中,vals表示矩阵中所有的非0值,colIdx表示vals中每一个元素在矩阵中的列标,rowPtr表示矩阵中每一行的第一个非零元素在vals中的位置,rowPtr的最后一个元素为矩阵非0值的数量。
如下图所示,vals=[3, 4, 5, 2, 1, 6],colIdx=[0, 3, 1, 2, 0, 3],rowPtr=[0, 2, 3, 4, 6]。
本案例中的算子需要实现csr格式的稀疏矩阵与向量乘法。用C++形式的代码可以表示如下:
std::vector<float> spmv_cpu(const std::vector<uint32_t>& row_ptr,
const std::vector<uint32_t>& col_ind,
const std::vector<float>& values,
const std::vector<float>& x) {
uint32_t M = row_ptr.size() - 1; // 行数
std::vector<float> y(M);
for (uint32_t i = 0; i < M; ++i) {
float sum = 0.0f;
for (uint32_t j = row_ptr[i]; j < row_ptr[i + 1]; ++j) {
sum += values[j] * x[col_ind[j]];
}
y[i] = sum;
}
return y;
}
三、方案与实现
3.1 Tiling
在Host侧,SpmvTilingData结构体中包含以下关键信息,用于指导Kernel侧的执行:
-
totalRowsNum: 矩阵总行数。 -
totalColsNum: 矩阵总列数。
// spmv/op_kernel/spmv_tiling_data.h
struct SpmvTilingData {
uint32_t totalRowsNum; // 输入稀疏矩阵的总行数
uint32_t totalColsNum; // 输入稀疏矩阵的总列数
};
// spmv/op_host/spmv_tiling.cpp
totalRowsNum = inputShapeRowPtr.GetShapeSize() - 1;
totalColsNum = inputShapeX.GetShapeSize();
核数确定:运算时使用的核数为硬件最大物理核数与矩阵行数的较小值。
// spmv/op_host/spmv_tiling.cpp int64_t usedCoreNum = totalRowsNum < coreNum ? totalRowsNum : coreNum; context->SetBlockDim(usedCoreNum);
tiling key规划:按输入数据类型(dtype)映射到schMode,支持float(ELEMENTWISE_TPL_SCH_MODE_0)和int32(ELEMENTWISE_TPL_SCH_MODE_1),用于区分kernel分支。
// spmv/op_host/spmv_tiling.cpp
if (dataType == ge::DT_FLOAT) {
tilingKey = GET_TPL_TILING_KEY(ELEMENTWISE_TPL_SCH_MODE_0);
context->SetTilingKey(tilingKey);
} else if (dataType == ge::DT_INT32) {
tilingKey = GET_TPL_TILING_KEY(ELEMENTWISE_TPL_SCH_MODE_1);
context->SetTilingKey(tilingKey);
} else {
OP_LOGE(context, "get dtype error");
return ge::GRAPH_FAILED;
}
return ge::GRAPH_SUCCESS;
3.2 Init
分核策略
-
行间并行:将矩阵的总行数
totalRowsNum按核数(GetBlockNum())进行均分。 -
负载均衡处理:对于不能整除的部分,将多余的行依次分配给前面的核。每个核处理的行范围由
startRow和endRow确定,保证了核间负载的基本均衡。
// spmv/op_kernel/spmv.h
this->totalRowsNum = tilingData->totalRowsNum;
this->totalColsNum = tilingData->totalColsNum;
uint32_t tempRowNum = totalRowsNum % AscendC::GetBlockNum(); // 均分之后剩下的行数
if (AscendC::GetBlockIdx() < tempRowNum) { // 计算每个核分到多少行,整除后剩下的行分给前面的核
this->blockRowNum = this->totalRowsNum / AscendC::GetBlockNum() + 1;
this->startRow = this->blockRowNum * AscendC::GetBlockIdx();
} else {
this->blockRowNum = this->totalRowsNum / AscendC::GetBlockNum();
this->startRow = this->blockRowNum * AscendC::GetBlockIdx() + tempRowNum;
}
this->endRow = this->startRow + this->blockRowNum;
单核内切分
-
基于行的流水线:在单核内部,以行为单位进行流水线处理。对于每一行,执行
CopyIn->Compute->CopyOut的流水线操作。在真实场景中,稀疏矩阵一行的有效元素数量并不大(通常不会超过10000),因此一次操作一整行,不在行内进一步切分。
// spmv/op_kernel/spmv.h
__aicore__ inline void Spmv<T>::Process() {
for (int32_t m = 0; m < this->blockRowNum; m++) {
CopyIn(m);
Compute(m);
CopyOut(m);
}
}
-
动态缓冲区大小:每个核的缓冲区大小(
tileLength)被设置为该核处理的所有行中,非零元个数的最大值max(row_nnz)。这是为了在UB中预留足够的空间,以容纳行内最大规模的稀疏计算。
// spmv/op_kernel/spmv.h
this->tileLength = 0;
for (int i = this->startRow; i < this->endRow; i++) {
uint32_t rowLength =
reinterpret_cast<__gm__ uint32_t*>(rowPtr)[i + 1] - reinterpret_cast<__gm__ uint32_t*>(rowPtr)[i];
this->tileLength = rowLength < this->tileLength ? this->tileLength : rowLength;
}
全局内存(GM)Tensor映射
-
rowPtrGm: 映射到当前核需要访问的rowPtr片段,长度为blockRowNum + 1。 -
colIdxGm和valsGm: 分别映射到当前核需要处理的colIdx和vals片段,长度为blockLength。 -
xGm: 映射到整个向量x(共享数据,不做切分)。 -
yGm: 映射到当前核需要计算的输出y片段,长度为blockRowNum。
// spmv/op_kernel/spmv.h rowPtrGm.SetGlobalBuffer((__gm__ uint32_t*)rowPtr + this->startRow, this->blockRowNum + 1); // 直接从ub访问 colIdxGm.SetGlobalBuffer((__gm__ uint32_t*)colIdx + startValIdx, this->blockLength); valsGm.SetGlobalBuffer((__gm__ T*)vals + startValIdx, this->blockLength); xGm.SetGlobalBuffer((__gm__ T*)x, this->totalColsNum); // x不切分,直接从ub访问 yGm.SetGlobalBuffer((__gm__ T*)y + this->startRow, this->blockRowNum);
队列与缓冲区初始化(TPipe)
-
输入队列:
inQueueColIdx和inQueueVals(TPosition::VECIN),用于存放从GM搬入的当前行非零元列索引和值。缓冲区大小均为tileLength * sizeof(element)。 -
计算队列:
-
workQueueX(TPosition::VECCALC):存放从GM中x向量收集来的当前行相关元素,大小tileLength * sizeof(T)。 -
workQueueReduce和floatQueueReduce(TPosition::VECCALC):用于ReduceSum和类型转换的中间缓冲区,大小tileLength * sizeof(float)。
-
-
输出队列:
outQueueY(TPosition::VECOUT),用于存放当前行的计算结果。缓冲区大小固定为sizeof(T)(一行一个结果)。
// spmv/op_kernel/spmv.h pipe.InitBuffer(inQueueColIdx, BUFFER_NUM, this->tileLength * sizeof(uint32_t)); pipe.InitBuffer(inQueueVals, BUFFER_NUM, this->tileLength * sizeof(T)); pipe.InitBuffer(workQueueX, BUFFER_NUM, this->tileLength * sizeof(T)); // 管理localX,不是gmx pipe.InitBuffer(workQueueReduce, BUFFER_NUM, this->tileLength * sizeof(float)); // ReduceSum接口用到 pipe.InitBuffer(floatQueueReduce, BUFFER_NUM, this->tileLength * sizeof(float)); pipe.InitBuffer(outQueueY, BUFFER_NUM, sizeof(T));
3.3 CopyIn & CopyOut
CopyIn
为当前行分配colIdxLocal和valsLocal缓冲区。使用DataCopyPad接口,将当前行的列索引和值从colIdxGm和valsGm复制到对应的本地缓冲区中,然后将其入队到inQueueColIdx和inQueueVals。
// spmv/op_kernel/spmv.h
AscendC::LocalTensor<uint32_t> colIdxLocal = inQueueColIdx.AllocTensor<uint32_t>();
AscendC::LocalTensor<T> valsLocal = inQueueVals.AllocTensor<T>();
uint32_t copyLengthColIdx = this->tileLength * sizeof(uint32_t);
uint32_t copyLengthVals = this->tileLength * sizeof(T);
AscendC::DataCopyExtParams copyParamsColIdx{1, copyLengthColIdx, 0, 0, 0};
AscendC::DataCopyExtParams copyParamsVals{1, copyLengthVals, 0, 0, 0};
AscendC::DataCopyPadExtParams<uint32_t> padParamsColIdx{false, 0, 0, 0};
AscendC::DataCopyPadExtParams<T> padParamsVals{false, 0, 0, 0};
AscendC::DataCopyPad(colIdxLocal, colIdxGm[(rowPtrGm(currentRow) - rowPtrGm(0))], copyParamsColIdx, padParamsColIdx);
AscendC::DataCopyPad(valsLocal, valsGm[(rowPtrGm(currentRow) - rowPtrGm(0))], copyParamsVals, padParamsVals);
inQueueColIdx.EnQue(colIdxLocal);
inQueueVals.EnQue(valsLocal);
CopyOut
从outQueueY中出队计算结果yLocal,使用DataCopyPad将其写回到yGm的对应位置,最后释放缓冲区。
// spmv/op_kernel/spmv.h
AscendC::LocalTensor<T> yLocal = outQueueY.DeQue<T>();
AscendC::DataCopyExtParams copyParams{1, sizeof(T), 0, 0, 0};
AscendC::DataCopyPad(yGm[currentRow], yLocal, copyParams);
outQueueY.FreeTensor(yLocal);
3.4 Compute
核心逻辑是实现 $y[i] = \sum_{j=rowPtr[i]}^{rowPtr[i+1]-1} vals[j] * x[colIdx[j]]$。
-
数据准备:从输入队列
inQueueColIdx和inQueueVals中取出当前行的列索引colIdxLocal和值valsLocal。从workQueueX分配本地TensorxLocal。
// spmv/op_kernel/spmv.h pipe.InitBuffer(inQueueColIdx, BUFFER_NUM, this->tileLength * sizeof(uint32_t)); pipe.InitBuffer(inQueueVals, BUFFER_NUM, this->tileLength * sizeof(T)); pipe.InitBuffer(workQueueX, BUFFER_NUM, this->tileLength * sizeof(T)); // 管理localX,不是gmx pipe.InitBuffer(workQueueReduce, BUFFER_NUM, this->tileLength * sizeof(float)); // ReduceSum接口用到 pipe.InitBuffer(floatQueueReduce, BUFFER_NUM, this->tileLength * sizeof(float)); pipe.InitBuffer(outQueueY, BUFFER_NUM, sizeof(T));
-
Gather操作(关键步骤):由于
x向量是随机访问的,代码使用了一个for循环,根据colIdxLocal中的索引,从全局内存xGm中逐个读取x元素,并存入xLocal。 -
向量乘加:
Mul(xLocal, xLocal, valsLocal, validNum): 对xLocal和valsLocal执行逐元素乘法,结果存回xLocal。 -
归约(Reduce):
-
float类型:直接调用ReduceSum<float>对xLocal进行求和,结果存入yLocal。 -
其他类型(如
int32):-
先通过
Cast将xLocal从源类型转换为float存入floatTmpBuffer。 -
对
floatTmpBuffer调用ReduceSum,结果存回floatTmpBuffer。 -
最后将
floatTmpBuffer的结果通过Cast转回源类型,存入yLocal。
-
// spmv/op_kernel/spmv.h
// 将需要计算的值从xgm中取出,存入localtensorX, xLocal(i) = xGm(colIdxLocal(i))
const __gm__ T* xGmPhyAddr = xGm.GetPhyAddr(); // 提升scalar操作的效率
__ubuf__ T* xLocalUb = (__ubuf__ T*)xLocal.GetPhyAddr();
__ubuf__ uint32_t* colIdxLocalUb = (__ubuf__ uint32_t*)colIdxLocal.GetPhyAddr();
int32_t eventIDMTE2ToS = static_cast<int32_t>(GetTPipePtr()->FetchEventID(AscendC::HardEvent::MTE2_S));
AscendC::SetFlag<AscendC::HardEvent::MTE2_S>(eventIDMTE2ToS);
AscendC::WaitFlag<AscendC::HardEvent::MTE2_S>(eventIDMTE2ToS);
int validNum = rowPtrGm(currentRow + 1) - rowPtrGm(currentRow);
if (validNum > 0) {
for (int i = 0; i < validNum; i++) {
int xi = colIdxLocalUb[i];
T x_value = xGmPhyAddr[xi];
xLocalUb[i] = x_value;
}
int32_t eventIDSToV = static_cast<int32_t>(GetTPipePtr()->FetchEventID(AscendC::HardEvent::S_V));
AscendC::SetFlag<AscendC::HardEvent::S_V>(eventIDSToV);
AscendC::WaitFlag<AscendC::HardEvent::S_V>(eventIDSToV);
AscendC::Mul(xLocal, xLocal, valsLocal, validNum);
AscendC::PipeBarrier<PIPE_V>();
if constexpr (std::is_same_v<T, float>) {
AscendC::ReduceSum<float>(yLocal, xLocal, sharedTmpBuffer, validNum);
} else {
AscendC::Cast<float, T>(floatTmpBuffer, xLocal, AscendC::RoundMode::CAST_ROUND, this->tileLength);
AscendC::PipeBarrier<PIPE_V>();
AscendC::ReduceSum(floatTmpBuffer, floatTmpBuffer, sharedTmpBuffer, validNum); // 规约 需要CHECK用得对不对
AscendC::PipeBarrier<PIPE_V>();
AscendC::Cast<T, float>(yLocal, floatTmpBuffer, AscendC::RoundMode::CAST_ROUND, this->tileLength);
AscendC::PipeBarrier<PIPE_V>();
}
} else {
yLocal.SetValue(0, static_cast<T>(0));
}
-
结果写出:将计算好的
yLocal放入输出队列outQueueY。 -
资源释放:释放所有已使用的本地Tensor。
// spmv/op_kernel/spmv.h outQueueY.EnQue<T>(yLocal); inQueueColIdx.FreeTensor(colIdxLocal); inQueueVals.FreeTensor(valsLocal); workQueueX.FreeTensor(xLocal); workQueueReduce.FreeTensor(sharedTmpBuffer); floatQueueReduce.FreeTensor(floatTmpBuffer);
四、问题记录
本案例算子开发流程为先以简易工程算子直调的方式开发了demo,然后迁移到标准工程中。这一章记录过程中遇到的问题。
4.1 简易工程Kernel开发
-
数据拷贝未对齐:在开发过程中数据的拷贝起初使用
AscendC::DataCopy()接口,但该接口存在限制拷贝数据必须32Byte对齐,而Spmv中每一行的有效数据是不固定的,因此拷贝数据量难以保证对齐。后改用AscendC::DataCopyPad()代替。 -
同步导致的精度问题:如第四章所述,算子性能瓶颈在于scalar,因此改写了从GM读取数据的方式,但这样写需要额外的手动同步,如果不添加同步精度验证无法通过。
-
从GM读取数据方法错误:在
Init中需要直接从GM中读取rowPtr以计算startValIdx和endValIdx,这个步骤在SetGlobalBuffer之前,而GM_ADDR的类型是,因此需要reinterpret_cast<__gm__ uint32_t*>(rowPtr)强转后读取,否则读取出来的数据错误导致精度问题。
4.2 标准工程迁移
-
算子定义:在标准工程中编写算子定义时,编译时没有编译进kernel中。只编译了host代码,但依然生成了自定义算子算子安装包,最后执行测试的时候报错,提示芯片不支持,检查算子定义后确认注册了芯片。
排查后发现编译没有生成
binary_info_config.json,仔细回看编译日志发现存在error。在
spmv_def.cpp中添加如下代码后重新编译解决。OpAICoreConfig aicoreConfig; aicoreConfig.DynamicCompileStaticFlag(true) .DynamicFormatFlag(false) .DynamicRankSupportFlag(true) .DynamicShapeSupportFlag(true) .NeedCheckSupportFlag(false) .PrecisionReduceFlag(true); -
约束与限制:完成算子开发测试时发现当稀疏矩阵每一行的非零数据数量巨大时运行不通过。排查之后根本原因在于当前方案对每一行的所有非零元素一次性分配UB(UnifiedBuffer)内存,当
tileLength过大时,可能会导致总UB用量超出AICore容量限制,后续方案可以进一步优化改进。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)