
性能跃升1.6-2.0倍!昇腾已上线VeRL Fully Async特性
目前大模型的千亿级参数、超长文本需求已经成为强化学习训练的效率、稳定性与扩展性的核心瓶颈,VeRL传统共卡同步训练模式逐渐难以满足这些需求带来的性能要求和高昂的训练成本,原因主要在于共卡模式中Rollout样本生成与策略梯度更新串行同步执行,所有环节需要等待Batch内最长尾序列生成完成,才能统一更新权重,超长样本会阻塞整轮训练,导致大部分算力陷入空闲等待,导致算力利用率低下,也同时限制了算力的横
强化学习(RL)已成为大模型从“能用”到“好用”的核心引擎,是激活模型深度思考、实现个性化匹配与价值对齐的关键路径。然而,通常的同步训练模式却深陷“长尾延迟陷阱”——生成阶段的极端耗时会导致训练流程频繁阻塞,硬件资源长期处于闲置状态,不仅拉低训练吞吐量,更推高了算力成本,成为制约大模型RL训练规模化落地的主要瓶颈。
VeRL作为强化学习大模型领域的主流开源框架,已全面覆盖PPO、GRPO、DAPO等核心算法,其Fully Async(全异步)特性,依托训推解耦的理念,具备突破同步训练模式性能限制的潜力。为让这一特性真正作用于自主创新算力生态、释放最大效能,昇腾以工程落地为导向,主动联动VeRL社区完成深度重构与合入,实现昇腾对Fully Async特性的支持。
经实测验证,VeRL+昇腾应用Fully Async特性在主流大模型RL训练场景下可实现1.6-2.0倍的性能跃升,同时显著提升资源利用率。切实为开发者提供更高效的强化学习训练方案,欢迎广大开发者体验使用。
技术挑战
目前大模型的千亿级参数、超长文本需求已经成为强化学习训练的效率、稳定性与扩展性的核心瓶颈,VeRL传统共卡同步训练模式逐渐难以满足这些需求带来的性能要求和高昂的训练成本,原因主要在于共卡模式中Rollout样本生成与策略梯度更新串行同步执行,所有环节需要等待Batch内最长尾序列生成完成,才能统一更新权重,超长样本会阻塞整轮训练,导致大部分算力陷入空闲等待,导致算力利用率低下,也同时限制了算力的横向扩展(scaling)能力。
技术原理:NPU平台1.6-2.0倍提升,提升多场景RL训练效率
Fully Async全异步架构实现了训练与推理任务的完全解耦——Rollouter作为数据生产者逐样本生成训练数据并写入消息队列MessageQueue,Trainer作为消费者同步调用算力进行模型训练。通过分离式训练方式,无需等待推理任务完成即可启动训练流程,最大化利用硬件资源,规避了传统共卡同步中的算力空闲问题。
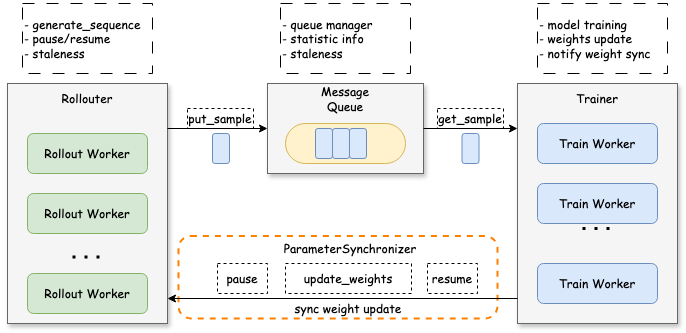
图1 Fully Async架构示意图
Fully Async针对不通场景需求所设计的on policy pipeline、stream off policy pipeline、async stream pipeline with stale samples、async stream pipeline with partial Rollout四种模式。通过调整staleness让开发者可以更细粒度地控制off policy的比例,开启partial Rollout则进一步填充训练流水线中的bubble,大幅降低Rollouter和Trainer的空闲率。
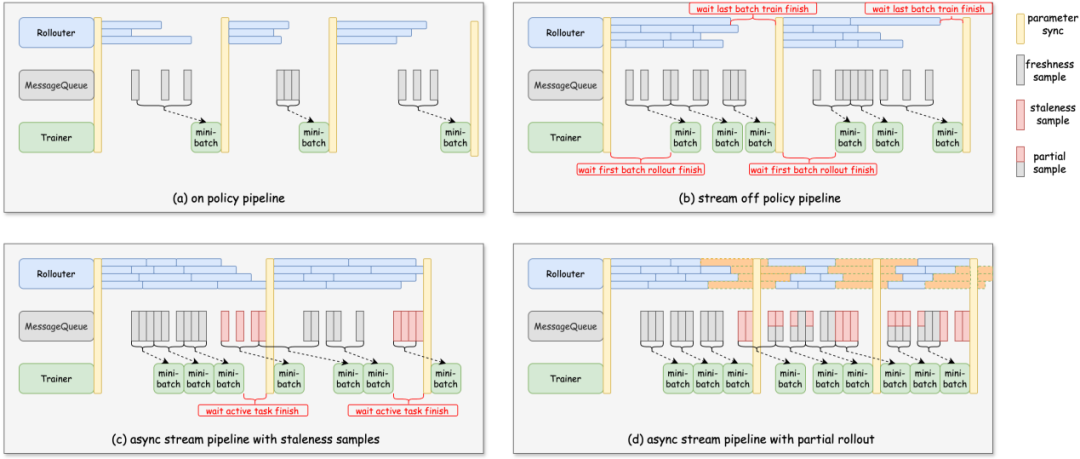
图2 Fully Async 4种模式
为了在昇腾上实现Fully Async特性,昇腾与VeRL社区展开深度技术合作,主要进行了以下工作:
CheckpointEngine重构
昇腾完成了对共卡方案参数同步CheckpointEngine的HCCL(NPU集合通信库)的支持,但现有的Fully Async架构通过ParameterSynchronizer进行参数同步,因此在昇腾上无法运行,同时这部分内容也造成了与主线参数同步方案的冗余。所以我们将参数同步部分进行了重构,将CheckpointEngine接入到FullyAsync和One-Step-Off中取代ParameterSynchronizer,使分离异步方案满足原生支持NCCL、HCCL等多类checkpoint engine后端;另外我们还对FSDP、Megatron后端同时做了支持,开发者使用昇腾的异卡方案时可以自由选择不同的训练后端。
Engine Worker重构
由于VeRL社区的高活跃度,Fully Async方案架构已部分落后于主线代码,不利于后续跟随主线的代码演进。因此昇腾也与社区联创对Worker部分的代码进行了重构,将原本根据不同训练后端单独实现的Worker替换为主线的Engine worker方案,消除了大量冗余代码同时令后续Fully Async的维护和开发变得更容易。
Validation资源调度优化
我们还发现Fully Async在做Validation时只能调用Rollouter的计算资源,导致了Validation过程的效率低下,我们也对此进行了优化:一方面通过统一调度训推资源,提高Validation过程资源利用率,另一方面进行Validation的长尾掩盖,使得Validation长尾的时间可以用于下一个step的train和Rollout。
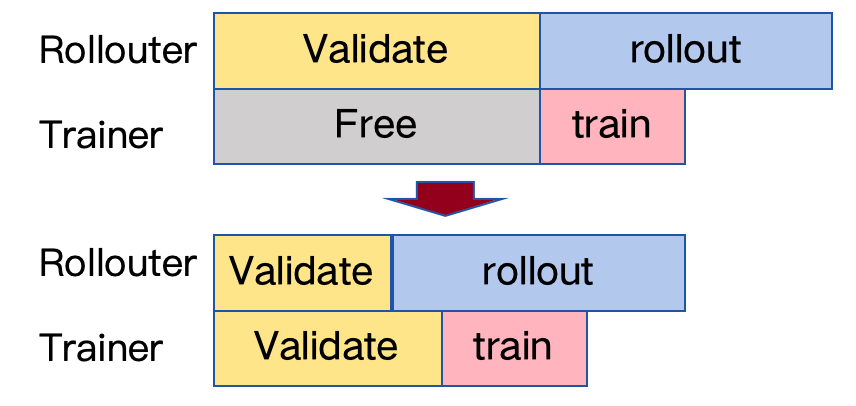
图3 Validation资源调度优化
目前,上述功能均已合入VeRL开源仓库,此次合作通过针对性的代码重构与功能开发,不仅完成了 Fully Async特性对昇腾的完整支持,更实现了框架架构的模块化重构升级,构建起基于昇腾的异步训练支撑体系,满足开发者的训练需求。
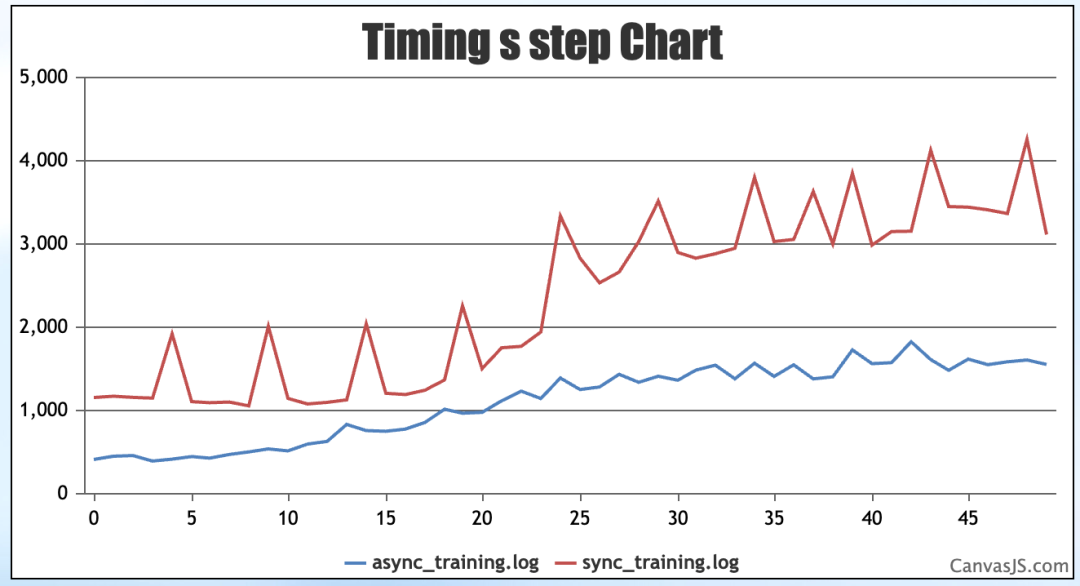
在长序列处理、大模型RL后训练等典型场景下,Fully Async方案性能提升尤为显著,在Qwen3-30B-A3B输入2k推理20k长序列场景下,相比共卡性能提升接近2.0倍,有效缩短模型训练周期,降低异构计算场景下的研发成本。
使用指导:无缝衔接开发流程
经过昇腾与VeRL社区的多轮功能测试与性能验证,VeRL的Fully Async特性在昇腾上已完全可用,已同步至VeRL main分支和v0.7.1分支,全面支持FSDP、Megatron等主流训练框架和昇腾NPU硬件。开发者仅需在配置文件中设置async_training相关参数,即可开启全异步训练模式:
准备环境
昇腾在社区提供了版本配套的每日构建镜像,可以参考Ascend QuickStart:
https://github.com/VeRL-project/VeRL/blob/main/docs/ascend_tutorial/quick_start/ascend_quick_start.rst
启动ray服务
Head节点执行ray启动命令
ray start --head
worker节点执行
ray start --address=xxx.xxx.xxx.xxx
配置Fully Async启动脚本,以Qwen3-0.6B为例
#!/usr/bin/env bashset -xeuo pipefailproject_name='DAPO-FullAsync-Qwen3-0.6B-NPU'exp_name='fully_async'# RayRAY_ADDRESS=http://127.0.0.1:8265WORKING_DIR=${WORKING_DIR:-"${PWD}"}RUNTIME_ENV=${RUNTIME_ENV:-"${WORKING_DIR}/verl/trainer/runtime_env.yaml"}MODEL_PATH="<YOUR_MODEL_PATH>"CKPTS_DIR=./TRAIN_FILE="<YOUR_TRAIN_FILE>"TEST_FILE="<YOUR_TEST_FILE>"rollout_mode="async"rollout_name="vllm"if [ "$rollout_mode" = "async" ]; thenexport VLLM_USE_V1=1return_raw_chat="True"fi# Algorithm parametersadv_estimator=grpouse_kl_in_reward=Falsekl_coef=0.0use_kl_loss=Falsekl_loss_coef=0.0clip_ratio_low=0.2clip_ratio_high=0.28# Response length parametersmax_prompt_length=$((1024 * 2))max_response_length=$((1024 * 20))enable_overlong_buffer=Falseoverlong_buffer_len=$((1024 * 4))overlong_penalty_factor=1.0# Training parametersloss_agg_mode="token-mean"# Algorithmtemperature=1.0top_p=1.0top_k=-1val_top_p=0.7n_gpus_rollout=4n_gpus_training=4n_nodes_rollout=1n_nodes_train=1train_prompt_bsz=0gen_prompt_bsz=1n_resp_per_prompt=4train_prompt_mini_bsz=32total_rollout_steps=$(((512*100)))test_freq=25staleness_threshold=0.1trigger_parameter_sync_step=1partial_rollout=Trueenforce_eager=Falsenccl_timeout=7200sp_size=2use_dynamic_bsz=Trueactor_ppo_max_token_len=$(((max_prompt_length + max_response_length) / 2))infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) / 2))ref_offload=Trueactor_offload=Falsegen_tp=1fsdp_size=$((n_gpus_training * n_nodes_train))ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \--working-dir "${WORKING_DIR}" \--address "${RAY_ADDRESS}" \-- python3 -m verl.experimental.fully_async_policy.fully_async_main \--config-path=config \--config-name='fully_async_ppo_trainer.yaml' \data.train_files="${TRAIN_FILE}" \data.val_files="${TEST_FILE}" \data.prompt_key=prompt \data.truncation='left' \data.max_prompt_length=${max_prompt_length} \data.max_response_length=${max_response_length} \data.train_batch_size=${train_prompt_bsz} \data.gen_batch_size=${gen_prompt_bsz} \data.return_raw_chat=${return_raw_chat} \actor_rollout_ref.rollout.n=${n_resp_per_prompt} \actor_rollout_ref.rollout.free_cache_engine=True \algorithm.adv_estimator=${adv_estimator} \algorithm.use_kl_in_reward=${use_kl_in_reward} \algorithm.kl_ctrl.kl_coef=${kl_coef} \actor_rollout_ref.actor.strategy=fsdp2 \actor_rollout_ref.actor.fsdp_config.strategy=fsdp2 \actor_rollout_ref.actor.fsdp_config.ulysses_sequence_parallel_size=${sp_size} \actor_rollout_ref.actor.fsdp_config.use_torch_compile=False \critic.strategy=fsdp2 \actor_rollout_ref.rollout.calculate_log_probs=True \actor_rollout_ref.nccl_timeout=${nccl_timeout} \actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \actor_rollout_ref.actor.clip_ratio_c=10.0 \actor_rollout_ref.model.use_remove_padding=True \actor_rollout_ref.hybrid_engine=False \+actor_rollout_ref.model.override_config.max_position_embeddings=32768 \actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \actor_rollout_ref.model.path="${MODEL_PATH}" \actor_rollout_ref.actor.optim.lr=1e-6 \actor_rollout_ref.actor.optim.lr_warmup_steps=10 \actor_rollout_ref.actor.optim.weight_decay=0.1 \actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz} \actor_rollout_ref.actor.fsdp_config.param_offload=${actor_offload} \actor_rollout_ref.actor.fsdp_config.optimizer_offload=${actor_offload} \actor_rollout_ref.actor.entropy_coeff=0 \actor_rollout_ref.actor.grad_clip=1.0 \actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \actor_rollout_ref.rollout.gpu_memory_utilization=0.80 \actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \actor_rollout_ref.rollout.enable_chunked_prefill=True \actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \actor_rollout_ref.rollout.enforce_eager=${enforce_eager} \actor_rollout_ref.rollout.temperature=${temperature} \actor_rollout_ref.rollout.top_p=${top_p} \actor_rollout_ref.rollout.top_k=${top_k} \actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \actor_rollout_ref.rollout.val_kwargs.do_sample=True \actor_rollout_ref.rollout.val_kwargs.n=1 \actor_rollout_ref.ref.fsdp_config.param_offload=${ref_offload} \actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \actor_rollout_ref.actor.fsdp_config.fsdp_size=${fsdp_size} \actor_rollout_ref.rollout.name=${rollout_name} \actor_rollout_ref.rollout.mode=${rollout_mode} \reward_model.reward_manager=dapo \trainer.use_legacy_worker_impl=disable \+reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \+reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \+reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \+reward_model.reward_kwargs.overlong_buffer_cfg.log=False \+reward_model.reward_kwargs.max_resp_len=${max_response_length} \trainer.logger=['console'] \trainer.project_name="${project_name}" \trainer.experiment_name="${exp_name}" \trainer.val_before_train=False \trainer.test_freq="${test_freq}" \trainer.save_freq=-1 \trainer.default_local_dir="${CKPTS_DIR}" \trainer.resume_mode=auto \trainer.nnodes="${n_nodes_train}" \trainer.n_gpus_per_node="${n_gpus_training}" \rollout.nnodes="${n_nodes_rollout}" \rollout.n_gpus_per_node="${n_gpus_rollout}" \rollout.total_rollout_steps="${total_rollout_steps}" \rollout.test_freq=${test_freq} \rollout.total_epochs=10 \async_training.staleness_threshold="${staleness_threshold}" \async_training.trigger_parameter_sync_step="${trigger_parameter_sync_step}" \async_training.partial_rollout="${partial_rollout}" \trainer.device=npu
运行效果
技术展望
开源生态的核心价值在于通过技术协同实现能力共建,此次昇腾与VeRL社区联合完成Fully Async特性的联创重构,是框架生态与硬件算力深度融合的实践,既拓展了VeRL框架的适用场景,也充分发挥了昇腾产品在RL训练场景的算力优势。
未来,昇腾将持续与VeRL社区深化合作,围绕Fully Async特性的性能迭代、多算法应用支撑等方向持续优化,同时推进支持更多RL核心特性,完善“框架+硬件”协同优化体系,为开发者提供更高效、更稳定的强化学习开发工具,助力大模型RL技术的工程化落地。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 7
7 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)