
算力利用率超90%:昇腾NPU算力切分技术深度解析
作者:华为昇腾技术专家 樊利、季鲁月、鄢明
一、 算力迷局:AI 时代的“贫血式浪费”
在 AI 浪潮奔涌的当下,算力已超越单纯的硬件指标,成为企业数字化竞速的核心引擎。从千亿参数的大语言模型训练,到万级并发的生产环境推理应用,算力供给的质量与效率直接决定了企业业务迭代的边界。
然而,一个尴尬的悖论正困扰着无数开发者与决策者:宏观上的“一卡难求”与微观上的“用之即废”并存。
在宏观层面,算力紧缺已成为行业常态。由于供应链波动及市场需求激增,企业为了确保大模型能够按时落地,往往不惜重金求卡,甚至面临长达数月的交付周期。但在微观机房内,由于传统调度机制颗粒度过粗,大量算力在处理轻量化任务时,如同“用重型卡车运送一杯咖啡”,导致高达 60%—70% 的算力在机房里默默“沉睡”。这种“贫血式浪费”不仅造成了巨额的财务损失,更阻碍了 AI 技术的普惠与创新。昇腾NPU算力切分技术的出现,正是为了终结算力荒废而生。
二、 核心痛点深挖:为什么昂贵的资源会“沉睡”?
要破解算力困局,必须正视当前企业在算力调度与利用中面临的三大核心痛点。这些挑战如果得不到解决,单纯增加硬件投入只会陷入“边际效应递减”的泥潭。
1. 资源错配导致的“财务陷阱”
目前的算力市场呈现出一种奇特的供需错位。在 RAG(检索增强生成)、Embedding 或轻量化小模型的推理任务中,实际消耗的算力与显存往往仅占整张物理卡的 5%–15%。然而,受限于传统的硬件隔离架构,即便任务再小,也必须“独占整卡”。 这种“强行霸位”的代价是沉重的。对于企业而言,这演变成了一个扎心的财务陷阱:算力投入产出比持续走低。在缺乏有效切分手段的情况下,买卡越多,闲置的算力就越多,成本浪费随规模呈指数级增长。
2. 颗粒度过粗:僵化的“一刀切”分配机制
现有的资源分配机制在面对高并发、低负载的现代推理业务时,显得过于“笨重”。
- 分配模式僵化: 传统的调度机制通常以“整卡”或“半卡”为最小单位,缺乏精细化管理的手段。
- 供需深度错配: 这种僵化导致了双输的局面。一方面是“小任务排长队”,大量时延敏感的小型推理请求因为拿不到整卡资源而在队列中苦苦等待;另一方面是“大任务缺资源”,算力被无数个低负载任务零散占用,真正需要高性能计算的大型任务反而面临“无卡可用”的窘境。
3. 业务灵活性与扩展性的丧失
当算力被固定在物理硬件的边界内时,业务的弹性就无从谈起。企业迫切需要一种能够打破物理边界、实现微秒级响应与动态配比的方案,来终结这种昂贵的资源荒废,让算力从“刚性资产”变为“柔性资源”。
三、 昇腾破局一:NPU软切分的“精算”思维
面对“算力荒”与“资源废”并存的僵局,昇腾NPU软切分技术通过时分复用技术,彻底打破了物理卡的隔离藩篱,让多容器共享整卡成为现实。这不仅是一次技术突破,更是一套为企业量身定制的“算力精算方案”。
1. 突破边界:从“整卡独占”到“像素级共享”
昇腾NPU软切分技术通过底层的虚拟化引擎,将刚性的硬件资源转化为随需流动的“数字活水”:
- 精细到极致的算力粒度: 告别粗放的分配方式,用户可以像拆解乐高积木一样使用算力。其最小支持 1% 的算力粒度,能够精准匹配轻量级长尾业务。
- 显存的精准切分: 显存实现了 MB(兆字节)级的划分。这意味着企业可以根据不同模型(如文本处理、图像预处理)的实际显存占用进行按需分配,彻底杜绝了“为了几百兆显存而霸占整张卡”的浪费现象。
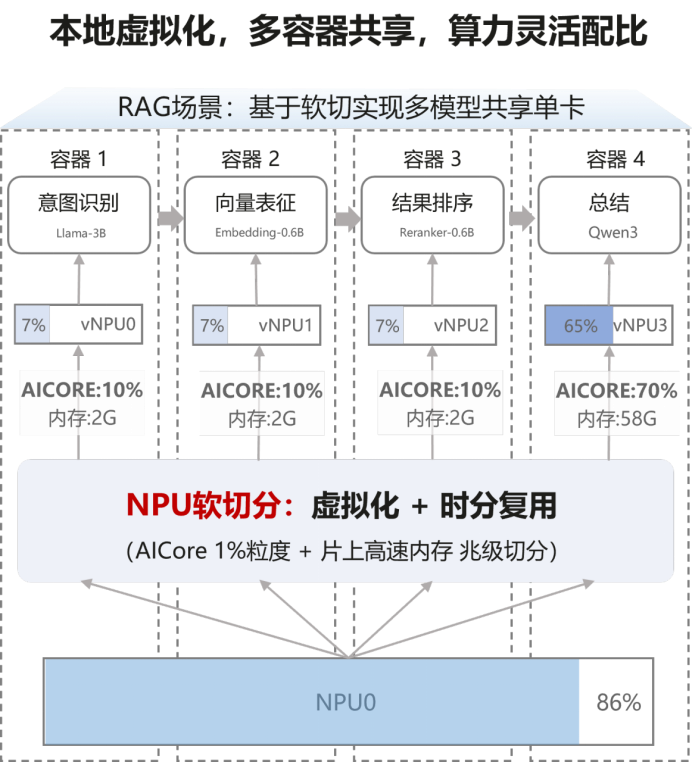
2. 三大调度模式:动态平衡“稳”与“快”
为了满足不同生产环境下的优先级需求,软切分技术提供了三种核心调度模式,确保在任何复杂场景下都能游刃有余:
- 严格模式(Fixed-shared): 为核心业务划定“专属红线”。在这种模式下,系统会为特定任务预留固定比例的资源且不可被抢占。这为金融交易、实时质检等时延敏感型任务提供了绝对的 QoS(服务质量)保障。

- 弹性模式(Elastic): 赋予业务“伸缩自如”的生命力。在系统空闲时,业务可自动获取更多算力以缩短处理时间;而在系统高峰期,则能灵活收缩回保底水平,实现全局资源的最优配比。

- 争抢模式(Best-effort): 专为高并发、非即时任务设计。它能“见缝插针”地利用系统剩余的每一分资源,不放过任何一秒的算力空窗期,将单卡的容器密度和吞吐量推向极限。

四、 昇腾破局二: NPU硬切分,单卡多实例,资源强隔离
在 AI 推理小模型场景中,业务常面临 “大卡跑小模型、算力闲置浪费”“多模型混部互相抢占、稳定性差”“多租户部署隔离成本高”三大痛点。昇腾NPU算力硬切分技术(硬件级虚拟化),为 Atlas 800I A2、Atlas 800I A3 提供精准算力划分、强隔离运行能力,单卡可虚拟化为 2/4/8 个独立vNPU 实例,让每一分算力都高效可用。
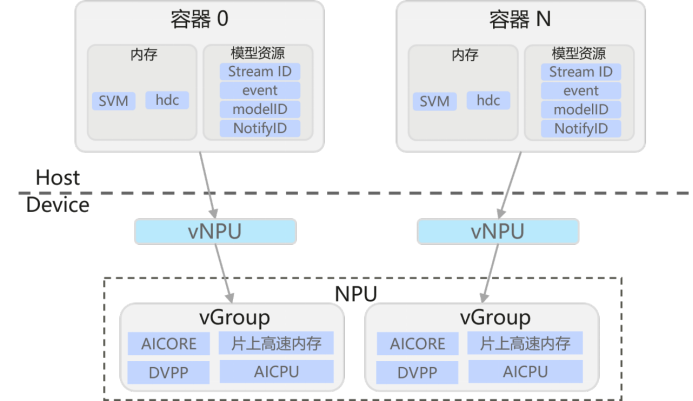
- 关键技术:硬件级硬切分,隔离与性能兼备
昇腾NPU硬件资源主要包括AICore(用于AI模型的计算)、AICPU、内存等,昇腾算力硬切分功能主要原理是将上述硬件资源根据用户指定的资源需求划分出vNPU,每个vNPU对应若干AICore、AICPU、内存资源。从底层杜绝资源抢占与数据干扰。
- 硬件强隔离,性能无损:非软件模拟,物理层隔离,vNPU间无调度争抢、无内存抢占,性能接近物理卡原生体验,无额外虚拟化开销。
- 固定粒度,灵活适配:支持多种切分粒度,粒度精准匹配不同模型算力需求。
- 资源独享,安全可靠:每个vNPU用于独立显存、AICore、AICPU资源,多租户部署数据隔离,隔离和安全性好。
如下图,整体方案,按照切分模板对NPU进行切分,将固定比例的AICore,片上内存和AICPU资源分配给vNPU,挂接到容器中使用。
五、 价值重塑:释放每一分算力的极致价值
昇腾NPU软切分方案带来的改变是颠覆性的。它不仅重新定义了算力的分配方式,更通过“精算”思维,助推企业在AI赛道上实现投入产出比的跨越式跃升。
- 利用率直冲巅峰: 通过软切分的精准调控,原本仅有 30% 左右的 NPU平均利用率,能够被瞬间激活,直接提升至90%以上。这意味着在硬件投入不变的前提下,企业的AI承载能力实现了近三倍的跨越。
- 降低创新门槛与TCO: 昂贵的算力不再是不可分割的“重资产”。通过精细化运营,企业可以用同样的资金尝试更多的 AI 业务场景,大幅降低了实验性业务的启动成本。
- 破解负向规模效应: 软切分终结了“买卡越多、浪费越多”的恶性循环。随着业务规模扩大,企业能够通过精细的资源调度实现线性的效能增长。
昇腾NPU硬切分技术,以硬件级隔离为核心,重新定义算力分配逻辑,打破资源浪费困局,为企业AI部署提供安全、高效、稳定的算力支撑,实现从 “可用”到 “好用”的跨越。
- 硬件级隔离,安全可控:依托硬件层面的资源划分,实现计算、显存资源独立隔离,数据与性能安全有保障,解决了多场景下的资源冲突问题,满足金融、政务等合规要求。
- 性能无损复用,效能拉满:硬切分无需额外软件适配,保留物理卡原生性能,单卡可拆分多实例独立运行,既避免算力浪费,又能确保业务稳定运行,实现算力利用与业务需求的精准匹配。
六、实操部署一:软切分
vCANN-RT(virtual CANN Runtime)是ubs-virt-enpu提供NPU算力软切分的方案。本方案需要依赖Linux系统Preload Hook的能力,通过预加载软切分动态库,拦截部分runtime API的调用,根据算力和显存资源配额信息,进行算力控制或显存控制。
1、主机侧环境配置
1.1 主机侧通过npu-smi工具开启容器共享模式。若配合MindCluster使用,要求整节点开启容器共享模式。
# 设置容器共享模式
npu-smi set -t device-share -i ${id} -c ${chip_id} -d ${value}
# 查询设备容器共享模式
npu-smi info -t device-share -i ${id}
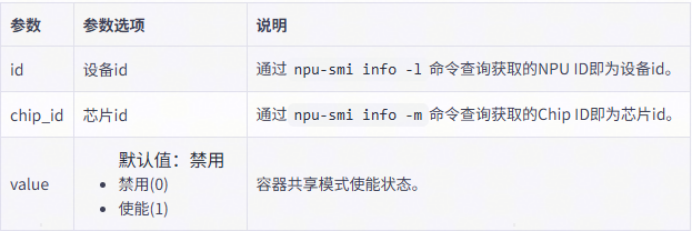
示例: 开启设备0所有芯片的容器共享模式,查询设备0容器共享模式。
npu-smi set -t device-share -i 0 -d 1
npu-smi info -t device-share -i 0

2、源码获取
在编译vCANN-RT源码前,用户需要先设置CANN的环境变量。
可以使用如下方式获取vCANN-RT源码。
git clone <ubs-virt-enpu-vcann-rt-url>
源码获取:
vCANN-RT源码的主要目录结构如下所示:
├── scripts // 存放项目中编译构建使用的脚本文件
├── src // 存放项目的功能实现源码,仅该目录参与构建出包
└── test // 存放项目的ut用例
3、编译
1、在编译vCANN-RT源码前,用户需要先设置CANN的环境变量。
2、vCANN-RT在代码仓中提供了统一的编译构建脚本(即make_build.sh文件),可以直接执行该脚本文件进行编译构建。
- bash make_build.sh 8.5.0
- 编译完成之后,会在build目录下面产生相应的编译产物(如果当前编译环境安装的cann版本不是8.5.0,则不需要增加编译参数)。
4、部署
用户可以选择将软切分动态库libvruntime.so和检测工具enpu-monitor分别拷贝到/opt/enpu/vcann-rt/lib和/opt/enpu/vcann-rt/tools目录。(如果选择不拷贝,则需要在后面的流程中修改相应的路径。)
- 启动服务:docker方式部署(不依赖kubernetes组件)
当不依赖k8s组件使用vCANN-RT时,需要用户在启动容器时自行挂载软切分相关动态库、文件和设备。例如软件分动态库、配置文件、共享内存设备和物理NPU设备。具体步骤如下:
5.1 创建vNPU配置文件和共享内存设备。
针对每个容器,需要在主机侧创建一个配置文件,并映射到容器的npu_info.config文件中(由于不同容器的配置内容不同,需要确保每个容器的配置文件在主机侧独立存储并明确区分,比如通过文件名或者路径区分)。配置文件的格式和字段示例如下:
physical-npu-id=0
virtual-npu-id=0
aicore-quota=20
memory-quota=1024
shm-id=xxx
scheduling-policy=2
此外,需要设置配置文件具有合适的权限,建议为644。
5.2 预加载配置文件
在主机侧创建预加载动态库文件ld.so.preload, 文件内容为libvruntime.so的路径,例如:/opt/enpu/vcann-rt/lib/libvruntime.so。
不建议将ld.so.preload文件放置在主机的/etc目录,否则将在主机侧预加载软切分动态库,可能影响主机侧业务。
5.3 启动业务容器
用户在启动容器时,需要将软切分相关动态库、文件和设备挂载到容器,容器启动命令可参考(假如使用第0张NPU卡):
docker run -it --name=container_name \ --device=/dev/davinci0:/dev/davinci0 \ --device=/dev/davinci_manager \ --device=/dev/hisi_hdc:/dev/hisi_hdc \ -v /usr/local/sbin:/usr/local/sbin \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /dev/shm:/dev/shm \ -v /opt/enpu/vcann-rt/lib/libvruntime.so:/opt/enpu/vcann-rt/lib/libvruntime.so \ -v /opt/enpu/vcann-rt/tools/enpu-monitor:/opt/enpu/vcann-rt/tools/enpu-monitor \ -v /xxx/npu_info.config:/etc/enpu/vcann-rt/npu_info.config \ -v /xxx/ld.so.preload:/etc/ld.so.preload \ image_name /bin/bash
5.4 启动业务,使用vCANN-RT服务
推理任务启动时,会自动拉起vCANN-RT服务进行算力控制和显存控制,软切分服务启动成功之后会设置一个进程级环境变量ENPU_ENABLE=True。如果日志回显内容为"Successfully to initialize all module.", 则表示vCANN-RT服务启动成功。
在容器内可通过监测工具查询vNPU资源配额和内存使用情况等信息。
/opt/enpu/vcann-rt/tools/enpu-monitor
七、实操部署二、硬切分
1、案例说明
以金融智能化助手一体机这一典型场景为例,通过采用虚拟化硬切分方案,可在单台Atlas 800I A2上部署多个不同模型,从而满足该一体机各类功能应用的模型需求。例如通过单卡1切2实现两个vNPU,用其中一个vNPU部署PP-OCRv5。
2、部署
2.1 执行命令 npu-smi info 查询空闲NPU卡(如下图所示0号卡(id=0,chip_id=0)上无任何进程),可进行切分。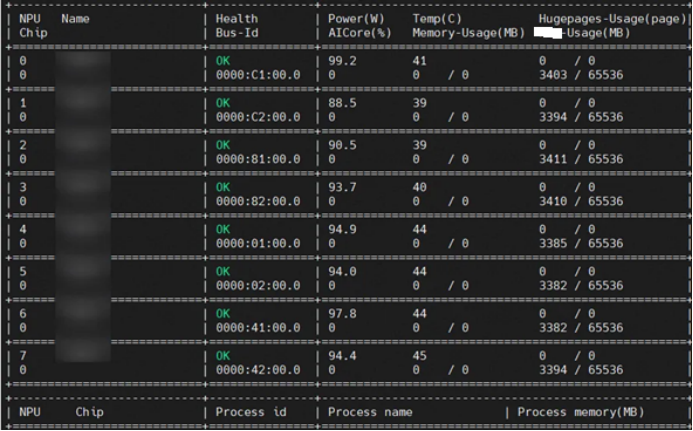
2.2 执行命令 npu-smi info -t info-vnpu -i id -c chip_id 查询该NPU上是否有vNPU,若已存在vNPU,可参照本节步骤2.10的操作按需决定是否删除。
2.3 执行命令 npu-smi info -t template-info 查询当前机型支持的切分模版。
2.4 根据模型占用显存大小来选择合适的切分模板vnpu_config。例如:本实践中使用的PP-OCRv5模型,最大模型占用显存为23GB。使用切分模板vir10_3c_32g可以分配到32G显存,选择切分模板vir10_3c_32g进行1切2。
2.5. 执行命令 npu-smi set -t create-vnpu -i id -c chip_id -f vnpu_config 进行切分。
2.6. 执行命令 npu-smi info -t info-vnpu -i id -c chip_id 查询该vNPU的信息,获取vNPU_id。
2.7. 参考附录中【命令参考-使用vNPU】节内容,提供两种vNPU挂载方式:
a) 原生Docker使用vNPU:
docker run -it -d --net=host --shm-size=1g \
--name <container-name> \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/vdavinci212:/dev/davinci212 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /home:/home \
<image_name> bash
b) Ascend Docker Runtime使用vNPU:
一些容器,例如本方案中的paddle-npu容器必须使用Ascend docker-runtime来挂载vNPU。否则会出现设备无法初始化等问题导致容器内找不到vNPU。需要通过Ascend Docker Runtime容器组件,将vNPU挂载到容器。Ascend docker-runtime组件安装参考链接:Ascend Docker Runtime安装。
Ascend Docker Runtime组件提供有两种挂载方式:
docker run -it -d --net=host \
--shm-size=128g \
--name <container-name> \
-e ASCEND_VISIBLE_DEVICES=100 \
-e ASCEND_RUNTIME_OPTIONS=VIRTUAL \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home:/work \
-w=/work \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/device/paddle-npu:cann800-ubuntu20-npu-$(chip_type)-base-$(uname -m)-gcc84 bash
说明:
ASCEND_VISIBLE_DEVICES:切分得到的vNPU_id。
docker run -it -d --net=host \
--shm-size=128g \
--name <container-name> \
-e ASCEND_VISIBLE_DEVICES=7 \
-e ASCEND_VNPU_SPECS=vir10_3c_32g \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home:/work \
-w=/work \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/device/paddle-npu:cann800-ubuntu20-npu-$(chip_type)-base-$(uname -m)-gcc84 bash
说明:
ASCEND_VISIBLE_DEVICES:切分用到的物理卡卡号。
ASCEND_VNPU_SPECS:切分模板名称。
第一种方式需要我们提前创建好vNPU,在docker run命令中绑定容器。
第二种方式不需要提前创建vNPU,在保证该物理卡上的资源满足切分后,在docker run命令中完成vNPU切分并绑定容器。
8. 进入上一步创建的docker容器中,执行命令 npu-smi info 查询vNPU信息,若成功回显类似带有 “vir10_3c_32g ”字样的虚拟卡名称,说明vNPU成功挂载到容器中,后续使用方式跟使用普通NPU一样。
9. 各模型服务化启动方式不再一一列举,可参考1.3节中表1的各官方教程。
10. 确认该vNPU不再使用后,执行命令 npu-smi set -t destroy-vnpu -i id -c chip_id -v vnpu_id 销毁指定的vNPU,避免影响其他人使用。
本部署步骤适用于所有支持的昇腾推理硬件,切分后的各模型性能可以达到实际使用场景下的性能要求。
八、总结
总结而言,昇腾NPU算力切分技术,真正实现了让每一块芯片都火力全开,最终帮助企业在AI竞赛中用同样的投入跑出数倍的业务增长。
在算力成为一种核心竞争力的今天,昇腾算力软切分这种对每一分资源的极致压榨,正是帮主企业提高核心竞争力的最大助力,具有非常重大的意义。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 11
11 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)