
银河麒麟v10 Server 本地部署大模型RAG服务 #4
本文介绍了在银河麒麟v10 Server上部署本地大模型RAG服务的实践。系统采用鲲鹏920 CPU和Atlas 300I推理卡,运行Kylin Linux系统,部署了BGE-M3模型实现多语言语义检索,通过Docker容器化部署Ollama和Docling服务。重点解决了离线环境下文档解析和知识库构建问题:使用BGE-M3进行语义嵌入,支持跨语言检索;通过Docling将PDF等非结构化文档转换
银河麒麟v10 Server 本地部署大模型RAG服务 #4
文章目录
模型算是配好了,但是光有个模型还是太拉了,配置点外围应用试试看
一、进度介绍
硬件总览
| 组件 | 详细信息 |
|---|---|
| CPU | 2 × 华为鲲鹏 920 (Kunpeng 920 5220) |
| 内存 | 总容量:256 GiB |
| 系统盘 | 致态 Ti600 4TB NVMe SSD |
| 数据盘 | 东芝 3.6T SATA HDD |
| 处理加速器 | 2 × Atlas 300I Duo 推理卡 |
软件总览
| 项目 | 详细信息 |
|---|---|
| 操作系统 | Kylin Linux Advanced Server V10 (Halberd) ID: kylin,VERSION_ID: V10 |
| 内核版本 | 4.19.90-89.11.v2401.ky10.aarch64 |
| 架构支持 | aarch64 (ARM 64-bit) |
| Python版本 | 3.7.9 |
| Docker版本 | 29.3.0 |
| NPU驱动版本 | 25.5.0 |
| MindIE版本 | 2.3.0 |
| OpenWebUI版本 | 0.8.10 |
| 已验证部署模型 | DeepSeek-R1-Distill-Qwen-32B,Qwen2.5-VL-3B-Instruct,Qwen2.5-VL-32B-Instruct,Qwen3-VL-2B-Instruct |
二、目标效果
基本要求:
-
离线部署:所有服务(推理、嵌入、解析)均部署在服务器本地,不依赖外部网络
-
文档解析:支持 PDF、Word、PPT 等复杂格式的解析,不丢失表格与阅读顺序
-
语义检索:不仅是关键词匹配,更要理解长文本和多语言语境
当前系统已完成大模型推理层的搭建,但是在使用上存在一些问题:首先,因为离线部署,模型无法引用最新领域资料;其次,无法处理长文本,用户每次提问都需手动粘贴全文;再者,在面对非结构化输入时(如办公文档),模型缺乏阅读解析能力。
针对上述问题,本阶段计划在已部署大语言模型的基础上,实现本地化 RAG(Retrieval-Augmented Generation,检索增强生成),将非结构化文档转化为可供语义检索的向量索引,并引入文档解析工具,将异构格式文件转化为结构化 Markdown,使得后续分段与嵌入有统一格式输入。
三、BGE-M3做知识库嵌入
嵌入是RAG的核心,核心的技术难点是将语义相近的内容映射到相近的向量中,比如说 “美国海军近况” 和 “美新财年舰艇规划” 在字面上差距很大,但是在语义上需要接近,不能只对关键词进行匹配,而是要理解实际内容。同时,还要考虑到知识库里可能存在多个语种的资料,需要在单语言语境下交叉检索到多个语言的内容。
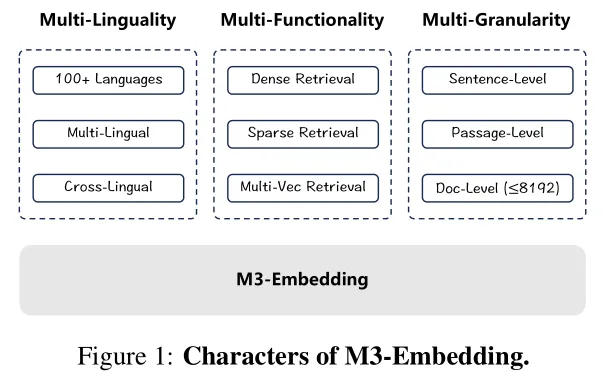
BGE-M3 的命名即体现了其三大核心特性——多语言(Multi-Lingual)、多功能(Multi-Functionality)、多粒度(Multi-Granularity),恰好覆盖我们从跨语种检索到术语精准匹配的全部需求。
1.服务部署
对对于国产化 ARM64 服务器而言,麒麟系统不属于主流 Linux 发行版,社区软件适配往往存在滞后。为兼容多种服务并隔离运行环境,Docker 是最优解 (发明docker的人真是个天才)
而对于这种通用的小模型,用ollama容器是最省心的选择,不用考虑docker容器版本,也不需要考虑容器内软件兼容性
# 创建docker目录
mkdir -p /data/ollama
# 启动 Ollama 容器(默认端口11434)
docker run -d \
--name ollama \
-v /data/ollama:/root/.ollama \
-p 11434:11434 \
--restart unless-stopped \
ollama/ollama:latest
# 拉取 BGE-M3 模型
docker exec -it ollama ollama pull bge-m3
2.服务测试
验证 Embedding 接口是否正常
[@localhost ]# root ➜ ~ $ curl http://localhost:11434/api/embed -d '{
> "model": "bge-m3",
> "input": ["银河麒麟高级服务器操作系统"]
> }'
{"model":"bge-m3","embeddings":[[-0.019254837,-0.010413596,-0.057714093,-0.0071352543,-0.01943673,-0.03746254,0.044497292,-0.009654001,-0.02931048,-0.0142898,0.042900898,0.018841904,-0.0062140035,0.0019933956,0.013516876,-0.04324301,0.0063461736,0.014754978,0.0012913349,0.00799676,-0.0033453149,-0.03963021,0.0043639615,0.037673734,-0.033706915,-0.018178457,-0.017625388,...,0.041324142]],"total_duration":21333946768,"load_duration":2417682565,"prompt_eval_count":11}
运行顺利
3.运行效果
将容器接入OpenWebUI,测试一下效果

调一下检索参数,亲测这里的增强混合搜索文本打开后,多语种混合检索能力会有所提升

首先创建一个笔记,内容如下

然后在对话中引用笔记内容,并提问笔记内容
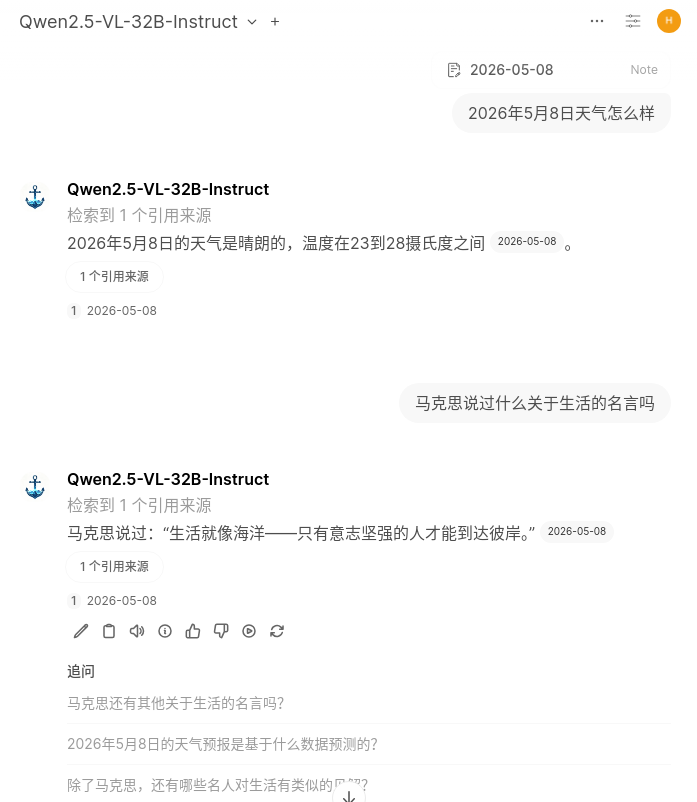
效果还是很不错的
四、docling做文档分析
BGE-M3模型的嵌入能力已经足以满足构建知识库的需求,现在的问题是,如何快速构建一个内容丰富的知识库
知识库建设面临的现实是:大量存量资料以 PDF、DOCX、PPT 等非结构化格式存在,必须转换为统一的结构化文本才能进行向量嵌入,核心要求是转换过程不丢失表格、标题、阅读顺序等关键信息——这正是 Docling 的强项
1.部署步骤
平衡部署难度和实际表现,我选择了使用docker容器部署Docling服务
# 创建Docling目录
mkdir -p /data/docling
# 启动 Docling 服务容器(默认5001端口,开启OCR)
docker run -d \
--name docling-serve \
-p 5001:5001 \
-e DOCLING_SERVE_ENABLE_UI=true \
-e DOCLING_OCR_ENABLED=true \
-e DOCLING_SERVE_ENABLE_REMOTE_SERVICES=true \
-e DOCLING_SERVE_MAX_SYNC_WAIT=600 \
-e DOCLING_SERVE_ENG_LOC_NUM_WORKERS=2 \
-e OMP_NUM_THREADS=4 \
-e MKL_NUM_THREADS=4 \
-e UVICORN_WORKERS=1 \
--restart unless-stopped \
quay.io/docling-project/docling-serve:latest
2.服务测试
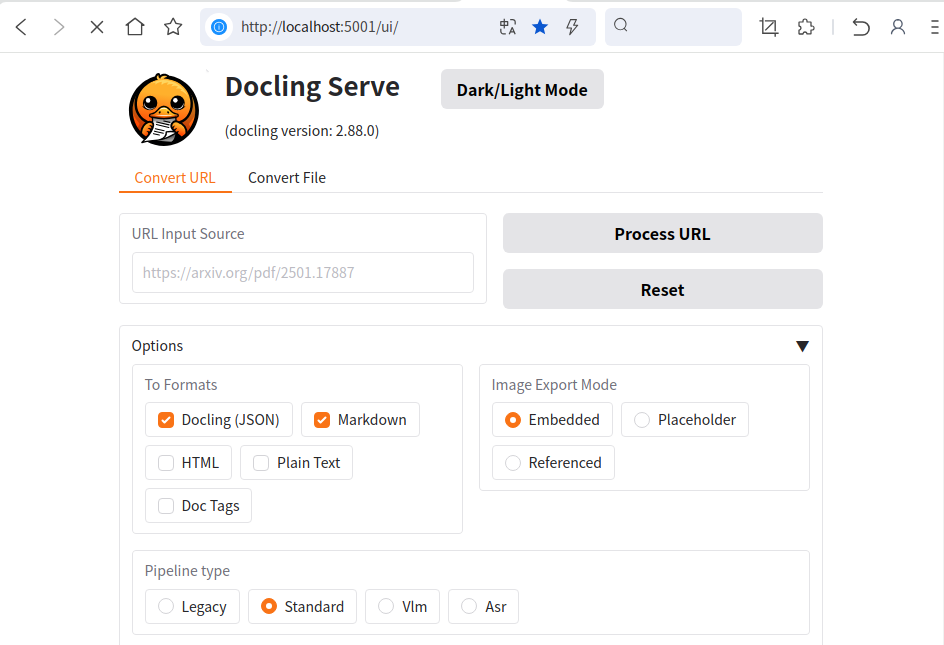
在5001端口可以看到Docling的服务页面
将docling服务接入OpenWebUI
3.运行效果
这里导入了一个带表格的pdf,看看表格的转换效果
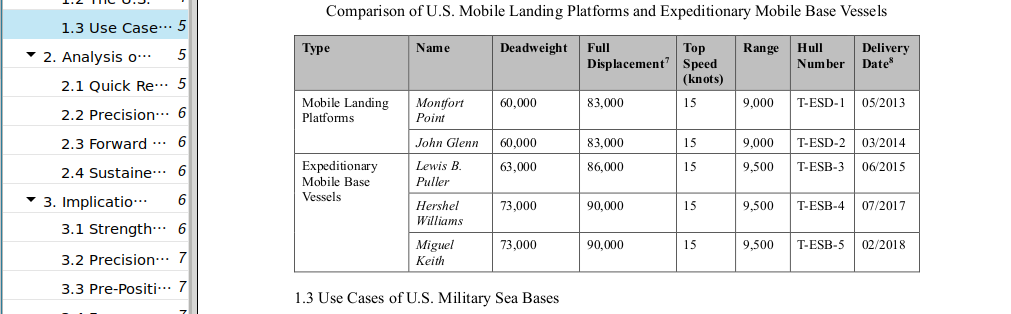
对于合并单元格的复杂表格,Docling 准确理解了单元格合并关系,以 Markdown 表格格式完整保留了原始信息
同时,表格下方的次级标题也被正确识别并以 Markdown 标题语法标注,排版还原度很高
五、总结
最后看看效果,在引用知识库之前

引用知识库之后

至此,我们在离线大模型推理能力之上,补齐了文档解析与语义检索两大环节,使私域知识库问答从"能对话"进化为"能引用、可追溯",显著提升了离线模型的实际可用性
接下来就是模型调优和稳定性增强,顺便开发一些好用的小函数,下面的工作才是最具挑战性的部分,书到用时方恨少,越是学习越是觉得自己什么都不会啊

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)