
昇腾MindStudio支持DeepSeek-V4模型W8A8量化
4月24日,DeepSeek-V4发布,模型支持百万字超长上下文,在 Agent 智能交互、通用世界知识与逻辑推理能力方面,综合性能位居国内及开源领域前列。昇腾MindStudio 模型量化工具支持模型W8A8量化,适配昇腾A2、A3及950全系列产品,实现模型轻量化部署,进一步提升推理性能。
4月24日,DeepSeek-V4发布,模型支持百万字超长上下文,在 Agent 智能交互、通用世界知识与逻辑推理能力方面,综合性能位居国内及开源领域前列。昇腾MindStudio 模型量化工具支持模型W8A8量化,适配昇腾A2、A3及950全系列产品,实现模型轻量化部署,进一步提升推理性能。
高易用性:降低学习成本,提升用户体验
MindStudio模型量化工具msModelSlim聚焦用户体验优化,通过全流程极简设计大幅降低使用门槛,核心特性包括:
- 一键量化:用户仅需通过命令行指定模型路径、结果保存路径及配置文件等必要参数,即可快速端到端量化,无需编写复杂量化脚本,提升操作效率。
- 配置驱动:采用声明式YAML配置协议,可清晰直观地描述量化方案;支持从最佳实践库快速匹配已验证的配置,同时兼容用户自定义配置,兼顾灵活性与便捷性。
- 模型接入简化:引入模型适配机制,结构相似的模型可直接复用适配器;新模型接入时,仅需按标准流程实现必要接口方法,大幅降低适配的学习和开发成本。
- 功能丰富:除基础量化功能外,还内置量化敏感层分析、自动调优等高级功能,可满足不同场景下的量化需求,助力用户优化量化方案。
可扩展性:自由定制,适配多元场景
msModelSlim架构面向结构复杂的大模型量化场景,原生支持更细粒度控制以适应不同软硬件场景下差异化的量化需求:
- 低硬件约束:支持layer_wise逐层量化模式,将大模型量化过程拆解为逐层递进的处理流程,大幅降低显存与内存占用压力,单卡64G显存即可完成DeepSeek-V4-Flash等千亿模型的量化任务,突破硬件资源限制。
- 弱软件依赖:摆脱对特定版本CANN的依赖,有效提升架构的兼容性与可移植性,适配更多软硬件环境,降低部署门槛。
- 精细化量化策略:支持针对不同模型结构匹配针对性量化算法,实现量化策略的精细化配置,兼顾量化效率与模型精度。
msModelSlim 为新模型接入设计了清晰的四步流程,按流程推进即可高效完成接入。

DeepSeek-V4模型与DeepSeek-V3.2结构相似,但在其基础上发展出两大创新结构:mHC和Engram。
结合现有的量化算子支持,我们采取如下的量化方案:
(1)线性层wq_a,wkv,indexer.wq_b,wq_b,w1,w2,w3采用W8A8动态量化
(2)Indexer结构采用类attention动态量化
为了控制精度损失,量化结构需应用离群值抑制算法。在DeepSeek系列模型量化历史经验中,业界QuaRot的旋转抑制叠加华为自研的Flex Smooth Quant算法普遍具有较好的精度控制效果,无需插入在线算子,不会影响推理性能。
msModelSlim通过声明式的量化配置驱动,将自然语言的量化方案组织成结构化的量化配置即可驱动msModelSlim完成量化。由于推理引擎组图在Indexer结构上统一采用attention动态量化算子,量化权重无需包含attention量化信息,量化配置只需要描述线性层量化方案。

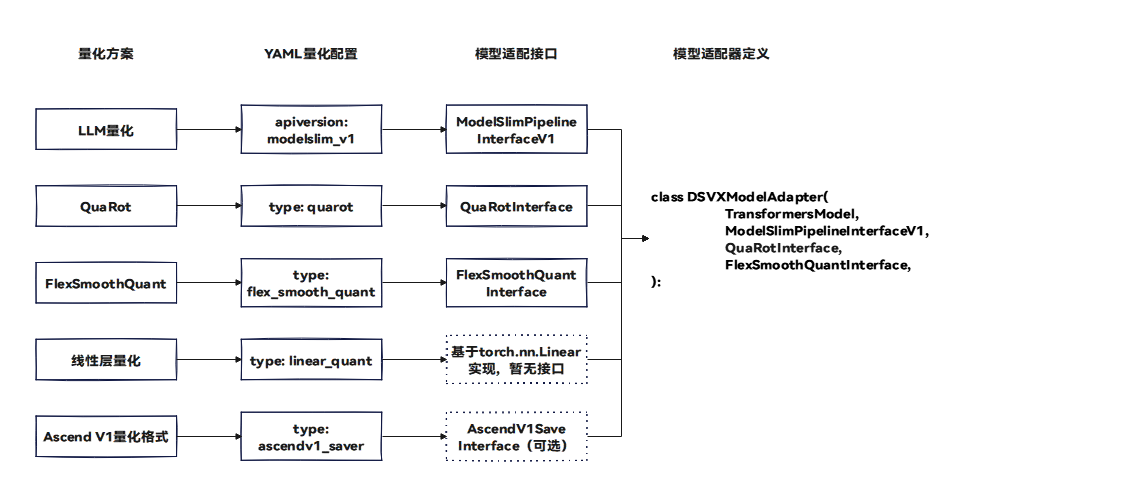
配置与接口映射关系图
量化配置YAML直接指明了量化使用的算法组件,部分组件需要获取模型结构信息辅助处理,这就要求专用的模型适配器,实现组件提出的模型适配接口,以指明模型的结构信息:
- LLM量化:量化配置YAML中的api-version: modelslim_v1,对应模型适配器接口ModelSlimPipelineInterfaceV1;
- QuaRot算法:量化配置YAML中的type: quarot,对应接口QuaRotInterface(描述如何融合Norm层并旋转权重);
- Flex Smooth Quant算法:量化配置YAML中的type: flex_smooth_quant,对应接口FlexSmoothQuantInterface(描述如何融合Norm层或Linear层);
- 线性层量化:量化配置YAML中的type: linear_quant,基于torch.nn.Linear,组件无需额外模型信息,暂无接口;
- Ascend V1量化格式:量化配置YAML中的type: ascendv1_saver,组件基于torch.nn.Linear实现,无需额外模型信息,暂无接口;
- 建议继承TransformersModel(工具基类,提供transformers库的通用方法,如配置加载等,简化实现)。
- 综上,DeepSeek-V4模型适配器只需继承TransformersModel、ModelSlimPipelineInterfaceV1、QuaRotInterface、FlexSmoothQuantInterface并实现对应的方法,即可满足量化执行要求。
明确所需接口后,填充接口方法,完成适配器开发与注册。
在msmodelslim/msmodelslim/model目录下新增deepseek_v4文件夹,目录结构如下:
|
msmodelslim/ ├── model.py ├── mtp_quant_module.py ├── convert_fp8_to_bf16.py |
DeepSeek-V4基本可复制DeepSeek-V3.2模型适配器的handle_dataset、init_model、enable_kv_cache、generate_model_visit和generate_model_visit方法,仅需注意前向末尾输出logits前存在额外的mHC结构处理,以及MTP层实现上的差异,和浮点模型前向实现保持一致即可。
旋转和离群值抑制图示
图示为完整的DeepSeek-V4模型的离群值抑制方案,只需要将上述图像分解转化为结构化信息填入对应算法的模型适配代码块并作为接口方法的输出即可完成离群值抑制适配。特别的是,需要将mHC结构的权重右旋,使得mHC的加权系数计算与浮点保持一致,则旋转可穿透mHC结构,不会对后续旋转方案产生影响。
1、修改配置文件:编辑msmodelslim/config/config.ini,修改[ModelAdapter]和[ModelAdapterEntryPoints]两组配置,添加DeepSeek-V4-Flash模型适配器,详细配置如下:
[ModelAdapter]
# DeepSeek-V4-Flash 对应 HuggingFace官方模型名,后续用于命令行参数
deepseek_v4 = DeepSeek-V4-Flash
[ModelAdapterEntryPoints]
# 路径对应模型适配器类实现路径
deepseek_v4 = msmodelslim.model.deepseek_v4.model_adapter:DeepSeekV4ModelAdapter
2、注册插件:重新安装msModelSlim即可,自动将模型适配器插件注册到pip路径
4. 第四步:执行一键量化
量化配置和模型适配都已准备就绪,接下来通过一键量化命令触发量化。
一键量化命令:
|
bash |
替换路径后,执行上述命令即可开始量化。
msModelSlim 通过高度可扩展的架构设计和用户友好的操作流程,该架构有效降低了模型量化技术门槛,让更多开发者和企业能够轻松实现大模型的高效部署。
无论是学术研究还是工业应用,msModelSlim 都将成为AI模型优化部署的得力助手。现在就开始体验,让您的大模型在昇腾AI基础软硬件平台上发挥更大价值!
msModelSlim代码仓:https://gitcode.com/Ascend/msmodelslim
DeepSeek-V4-Flash W8A8量化权重获取:https://modelers.cn/models/Eco-Tech/DeepSeek-V4-Flash-w8a8-mtp

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)