
体系结构论文(104):AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing
本文提出AscendKernelGen框架,研究如何利用大语言模型自动生成NPU内核代码,并确保生成代码可编译、功能正确且性能优化。针对通用LLM在硬件专用代码生成上的不足,作者构建了包含文档推理、代码推理的Ascend-CoT数据集,开发了KernelGen-LM模型,并设计了NPUKernelBench评测体系。实验表明,经过领域自适应训练的模型在中等复杂度任务上表现优异(Level2执行率6
AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units 【华为26年paper】
这篇文章在讲什么
这篇文章研究的是:能不能让大语言模型替人写 NPU 内核代码,而且写出来的不只是“像代码”,而是真的能编译、能跑对、最好还能跑得快。
这里的 NPU 不是我们平时写 Python、C++ 那种通用编程环境,而是华为 Ascend 这类 AI 加速器对应的底层编程体系。作者关注的语言是 AscendC。这个领域的特点是:
1. 不是“会写程序”就能写好。
2. 你必须同时理解硬件、内存层次、并行执行方式、同步机制、tiling(分块)、数据布局等很多底层约束。
3. 代码是否正确,不只是看语法,还要看是否满足硬件接口约束、数值是否正确、运行是否高效。所以这篇文章不是普通的“代码生成论文”,而是在讨论一个更难的问题:LLM 能否掌握硬件相关的专门知识,并把这些知识转化成真正可执行的低层 kernel。
作者的核心判断很明确:
1. 通用 LLM 在这种任务上几乎不行。
2. 问题不只是 prompt 不够好,而是数据、推理模式、训练方式、评测方式都不对。
3. 想把这件事做起来,必须把“数据集 + 专项训练 + 硬件级评测”一起做。
1. 什么叫 kernel
在 AI 加速器里,kernel 可以理解成“一个非常底层、非常专用的计算小程序”。比如矩阵乘、归一化、激活函数、TopK、Attention 的某个子步骤,都可能由一个或多个 kernel 完成。
上层框架里你可能只写一行:
y = layer_norm(x)
但在底层,真正把这个计算搬到 NPU 上执行的,往往就是一段专门写出来的 kernel。
2. 为什么 kernel 难写
因为你不是只写“算什么”,你还得写“怎么在这块硬件上高效地算”。例如:
1. 数据先放在哪里,放到全局内存还是片上缓存?
2. 一次处理多少元素,怎么分块?
3. 什么时候搬数据,什么时候算?
4. 数据搬运和计算能不能并行重叠?
5. 多个执行单元之间要不要同步?
6. 输入尺寸不是整齐对齐时,边界怎么处理?
这些问题如果处理不好,会出现三类后果:
1. 编译不过。
2. 编译能过,但结果算错。
3. 结果对了,但性能很差,甚至比手写基线慢。
3. AscendC 和 CUDA / Triton 有什么不同
如果你熟悉 GPU 方向,可以把 AscendC 理解成一种强硬件约束、强接口约束的低层 DSL。但它和 CUDA/Triton 又不完全一样:
1. 生态更封闭。
2. 开源训练数据更少。
3. API 语义更专门。
4. 很多正确写法依赖厂商文档、工程模板和经验积累。
这意味着:通用代码模型虽然见过大量 Python、C++、Java,但并没有真正学到 AscendC 这种窄而深的知识体系。
4. 为什么“能编译”不等于“能用”
这是硬件代码生成里最容易被忽略的一点。
普通代码生成 benchmark 往往只关心功能测试是否通过,但 kernel 任务至少要看三层:
1. Compilation:能不能过编译。
2. Correctness:输出数值对不对。
3. Performance:性能是否达到合理水平。
比如一个模型可能会生成一个“语法看起来挺像”的 kernel,但:
1. 调了一个并不存在的 API。
2. 参数顺序错了。
3. tile 大小算错了。
4. host 侧算出来的 tiling 参数和 device 侧实际读取的逻辑不一致。
5. 边界 mask 少写了一个条件,结果只有部分输入会算错。
所以这类任务比 HumanEval 那种“写个函数通过单元测试”难得多。
一、INTRO
1. 为什么这个问题重要
开头先从大背景切入:
- AI 和深度学习发展很快
- 为了追求更高计算效率,domain-specific accelerators 越来越重要
- 其中 NPU 已经成为现代 AI 基础设施里的关键硬件
- 但 NPU 真正能不能发挥性能,不只取决于硬件本身,还取决于底层 compute kernel 的质量
这里作者想建立的逻辑是:
NPU 很重要 → kernel 很关键 → kernel 开发问题值得单独研究。
kernel quality 是释放 NPU 能力的前提。
2. 传统 kernel 开发为什么难
因为它通常依赖厂商专用的硬件编程方式,文中把这类东西称为 vendor-specific DSLs, such as AscendC。而开发者必须掌握很多很底层的知识,例如:
- 分层内存管理(global memory / on-chip memory)
- 数据 tiling
- 异步流水线编程
- 向量单元和矩阵单元的显式利用
作者这里要突出两个结论:
- 学习门槛很高
- 人工开发代价很大,而且容易出错
所以 Intro 的第二步是在说:
这个任务难,不是因为代码长,而是因为它要求程序员理解硬件执行机制。
3. 引出 LLM,但立刻指出通用 LLM 不行
然后文章顺势过渡到 LLM:
- 现在大模型在通用代码生成上很强
- 所以自然会想到:能不能让 LLM 自动生成 NPU kernel?
但作者没有直接唱好,而是马上泼冷水:
不行,至少通用 LLM 直接上基本不行。
原因有两点:
3.1 领域知识本质不同
作者认为,NPU 这种硬件特定代码所需知识,和普通编程知识不一样,涉及:
- 严格 API 约束
- 架构相关语义
- 性能敏感优化模式
这说明作者对问题的判断不是“模型不够大”,而是:训练分布不对,任务本质也不一样。
3.2 高质量训练数据稀缺
通用代码很多,但高质量 NPU kernel 数据很少。
所以通用 LLM 没法自然学到这一类知识。
4. 用实验事实证明“通用模型不行”
为了避免只是口头判断,作者在 Intro 里给了一个前测结果:
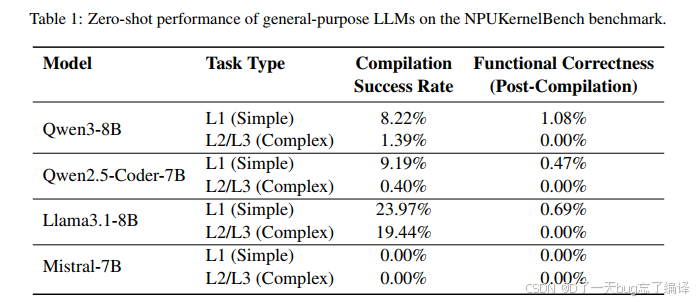
这里要特别注意“Compilation Success”和“Functional Correctness”是分开的。比如 Llama3.1-8B 在复杂任务上的编译成功率居然还有 19.44%,但功能正确率是 0。这说明:
1. 模型可以凑出某种“形式上像代码”的东西。
2. 但它并没有真正理解 kernel 的执行语义。
很多人会以为“能编译就已经八九不离十了”。但在底层硬件代码里,能编译只是第一道门槛。
- 通用模型在 zero-shot 生成 AscendC kernel 时表现极差
- 常见问题包括:
- 幻觉不存在的 API,比如
AscendC::Softmax - 严重误用硬件接口
- 编译失败率很高
- 幻觉不存在的 API,比如
- 对复杂的 L2/L3 kernel,执行成功率几乎掉到 0%
作者想借这个结果说明:现有通用代码大模型,不能直接迁移到复杂 NPU kernel 生成。
也就是说,这篇文章的研究动机不是“让效果更好一点”,而是:先把这个任务从几乎不可用,推到可用。
5.提出作者自己的核心判断
在证明通用模型不行之后,作者就给出自己的诊断:
要想让 LLM 能做 NPU kernel generation,需要两个关键条件:
5.1 模型必须学会硬件专用编程范式
也就是要理解:
- 硬件架构特性
- API 约束
- kernel 的推理方式
5.2 必须有专业可靠的评测框架
不能只测“像不像代码”,而要测:
- compilation
- functional correctness
- performance
作者认为问题不是单点模型问题,而是两个层面的问题:
- 训练问题:模型没学到这个领域知识
- 评测问题:没有足够严谨的 benchmark 去判断生成结果到底行不行
6. 正式抛出本文方案
于是作者提出 AscendKernelGen,并把自己的贡献概括成三部分:
6.1 Ascend-CoT
一个面向低层 NPU kernel 编程的数据集,强调:
- pipeline construction
- synchronization logic
- arithmetic reasoning patterns
这意味着作者不是只收集代码,而是收集推理过程。
6.2 KernelGen-LM
在强基座模型上做领域自适应后训练,专门提升低层 NPU kernel 生成能力。
6.3 NPUKernelBench
一个评测框架,从三个维度评估生成 kernel:
- 编译是否成功
- 功能是否正确
- 性能怎么样
所以 Intro 最后的落点不是“我们设计了一个新模型”,而是:
我们搭了一个从数据、训练到评测的完整研究框架。
二、挑战
这一节是整篇论文里我认为最应该认真读的理论部分之一。作者没有陷入“Ascend 某个指令长什么样”的细节泥潭,而是先抽象出 NPU kernel 编程的结构本质。
作者把低层 NPU kernel 概括成一种“静态结构化程序”,它同时规定了:
1. 全局数据怎么分块。
2. 异步流水各阶段怎么排。
3. 同步关系怎么建立。
4. 在多个处理单元上如何复制执行模板。
例如,你不只是写一行加法,而是在安排:
1. 第一步从全局内存把数据搬到片上。
2. 第二步让计算单元处理当前 tile。
3. 第三步把结果写回。
4. 与此同时下一块数据可能已经在预取。
5. 中间还要靠同步原语保证“先搬完再计算”“先算完再写回”。
作者在这一节总结了四个关键难点,我认为非常准确:
1. 长距离语义依赖。
例如 block index、tiling factor、边界大小等参数,可能在 host 侧算出来,在 kernel 多个位置使用。模型必须跨多段代码保持语义一致。
2. 显式同步推理。
同步原语不是“写了就安全”,而是必须成对、按时序、按依赖关系出现。少一个会数据冒险,多一个会卡死,顺序错了也会错。
3. 边界敏感的算术推理。
输入尺寸往往不是块大小的整数倍,所以需要处理尾块。一个 `<` 写成 `<=`,或者 mask 少一位,结果就会错。
4. 布局感知推理。
某个阶段为了适配硬件单元,数据物理布局可能和逻辑张量布局不同。代码必须知道“现在这个数据长得像什么”和“它语义上代表什么”。
这一节的价值在于:作者把问题从“模型没见过 AscendC”提升到了“这种程序天然需要跨区域、多约束、时序化推理”。这使得后面的数据设计和训练设计有了逻辑基础。
二、文章总体思路
作者提出了一个完整框架 AscendKernelGen。它不是单点方法,而是三部分联动:
1. Ascend-CoT:面向 AscendC 内核生成的领域推理数据集。
2. KernelGen-LM:在通用模型基础上做领域后训练得到的专门模型。
3. NPUKernelBench:真正落到硬件上的评测基准,检查编译、正确性和性能。
这三者的关系可以借助文中的 Figure 1 来理解。
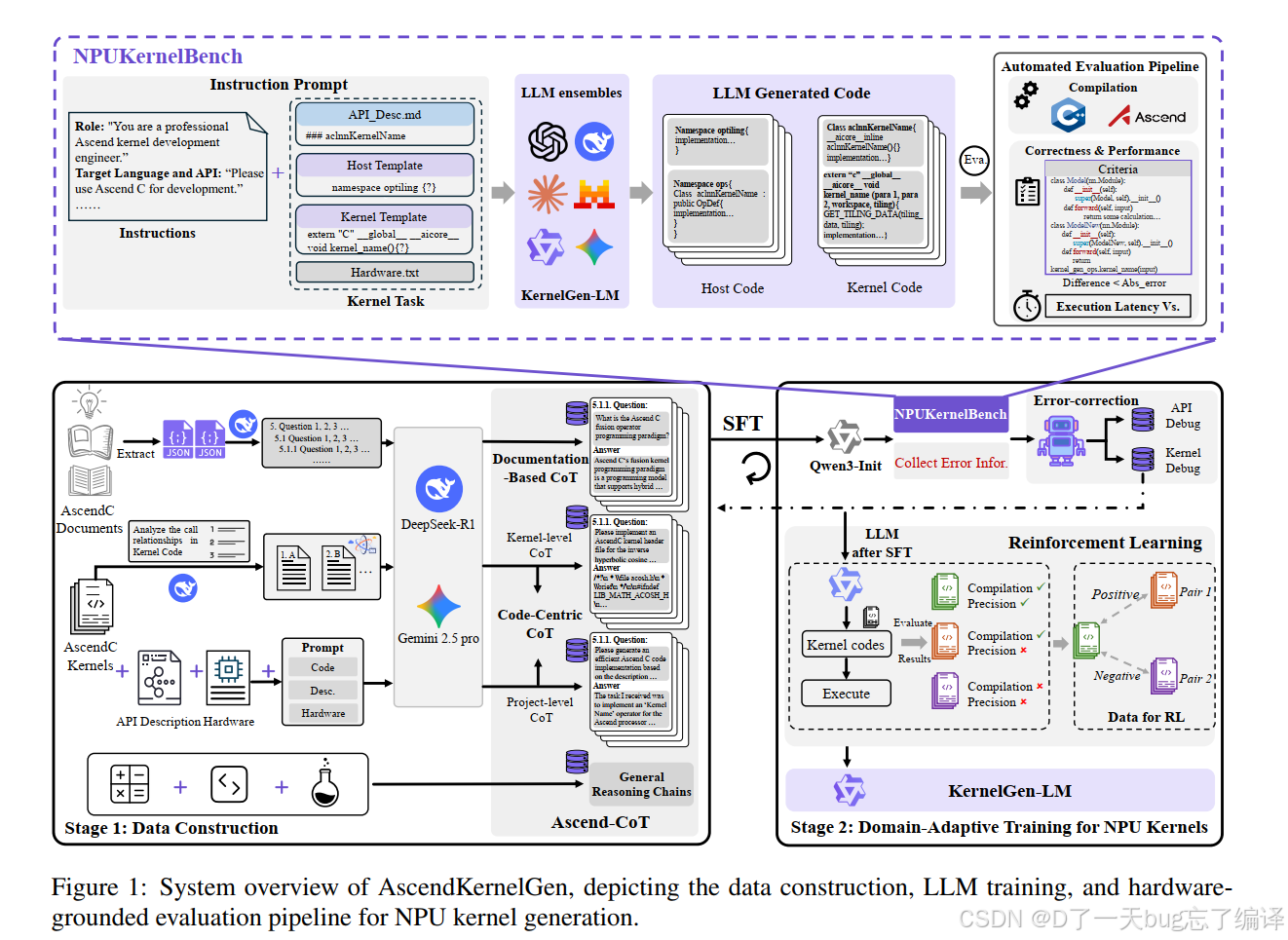
Figure 1 不是简单流程图,而是在说明作者的总体研究立场:他们不把“生成代码”看成一个孤立的文本任务,而是看成一个闭环系统。
这个闭环包括:
1. 从文档、代码、工程项目中构造训练数据。
2. 用这些数据对模型做 SFT 和 RL。
3. 让模型生成 host 代码和 kernel 代码。
4. 把生成结果送进真实的编译与执行流水线。
5. 再把错误信息和执行反馈反哺回训练。
这张图真正要表达的重点是:作者不是只想证明“模型能输出看起来像 AscendC 的文本”,而是想让模型在“生成 - 编译 - 执行 - 修正”的工业闭环里逐步变强。
这也是这篇工作相对扎实的地方。
在系统概览中,作者把 AscendKernelGen 分成两大部分:
1. 生成侧:Ascend-CoT + KernelGen-LM。
2. 评测侧:NPUKernelBench。
如果只看文字,这很像标准套路;但结合 Figure 1 来读,就会发现作者在强调三个层面的“闭环”:
1. 知识闭环:文档知识、代码知识、项目知识都被转成监督信号。
2. 训练闭环:SFT 先教会基本结构,RL 再根据执行反馈做细化。
3. 评测闭环:从编译到正确性到性能层层筛。
也就是说,Figure 1 其实是在反对一种常见的偷懒做法:只做 prompt engineering,然后用少数 case 展示几个成功样例。作者想证明的是,这种任务必须在系统工程意义上搭完整。
这里可以给一个很通俗的类比:
如果把通用代码生成看成“让模型写作文”,那这篇文章处理的是“让模型按工艺标准绘制并验证一张可投产的工程图纸”。后者不能只看语言流畅度,必须有生产线验证。
数据构建
这篇论文的一个重要贡献不是“想了个更巧的 prompt”,而是认真构建了领域推理数据。作者把数据分成三类,这个拆法是有逻辑的。
Documentation-Based CoT:把文档变成“会推理的知识”
第一类数据来自官方文档,包括:
1. Operator Development Guide。
2. API Reference。
3. Best Practices。
很多人做领域适配时会简单把文档喂给模型继续预训练,但作者这里没有停在“灌知识”层面,而是把文档转成 question-answer 加 reasoning trace 的形式。这个设计很关键,因为它不是让模型机械记忆 API,而是让模型学习:
1. 某个 API 什么时候该用。
2. 参数约束是什么。
3. 典型错误长什么样。
4. 为什么某种写法会违反硬件/接口约束。
换句话说,作者不是只想让模型“背 API 手册”,而是想让模型像工程师一样解释 API 使用逻辑。
这类数据的作用主要是解决两个问题:
1. 降低 hallucination。
2. 把“接口合法性”显式注入模型。
不过也要客观看,它的上限是有限的。因为文档能覆盖规则,但不一定能覆盖复杂工程中的隐式配合关系。
Code-Centric CoT
第二类数据来自真实 AscendC operator 实现。作者把这类数据又分成两种:
1. 能独立编译的单体 kernel 文件,做 kernel-level CoT。
2. 复杂工程项目,拆成 host-kernel 对,做 project-level CoT。
这里的 project-level CoT 非常关键。因为很多真正复杂的问题并不在 kernel 单体内部,而在 host 和 device 的协同。
举个例子:
1. host 侧根据输入形状算出 tiling 参数。
2. 这些参数通过结构体传给 kernel。
3. kernel 侧再依据这些参数安排内存与计算。
如果 host 侧算的块大小、循环次数、边界条件和 kernel 侧消费这些参数的方式不一致,代码可能编译通过,但运行就错。
所以作者不是简单用“代码 - 注释”配对,而是试图让模型学到跨 host/device 边界的因果关系。这一点比很多只做 kernel 片段学习的工作更像工业真实场景。
这部分还有一个比较扎实的点:作者说只保留通过自动验证的 CoT 样本。也就是说,他们知道 reasoning 数据很容易“写得头头是道但其实不对”,所以增加了一层过滤。
当然,局限也存在:论文并没有完全展开说明这些 CoT 的生成质量到底如何、人工校验比例有多少、是否存在模型自举生成 reasoning 再训练自己的风险。如果这些推理链主要由别的 LLM 生成,那么它的可靠性仍然值得继续追问。
General CoT:防止模型过窄
第三类数据是一般推理数据,比如数学、代码推理、科学问答等。作者的理由是:如果全用窄领域数据训练,模型可能会失去一般问题求解能力。
这个思路是合理的,因为 kernel 生成不是纯背模板,它依然需要一般性的逻辑推理、算术推理和多步规划能力。
训练设计
这一节讲训练流程:先 SFT,再 RL。思路本身并不新,但作者做得比较扎实的地方在于,他们没有把 SFT 理解成“拿正确答案直接训”,而是引入了 error-derived supervision。
Error-Derived Supervision
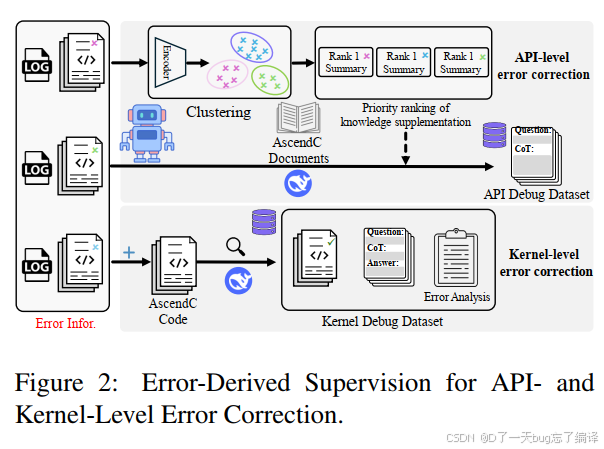
Figure 2 讲的是作者如何把错误转化成训练信号。它不是简单说“收集错误样本”,而是分成两层:
1. API-level error correction。
2. Kernel-level numerical inconsistency correction。
这两个层次分别对应两类很常见、但性质不同的问题。
第一类是 API 级错误。比如:
1. 参数顺序错。
2. 参数类型不匹配。
3. 调用了不存在的重载。
4. 某个接口少了必要参数。

作者在 Algorithm 1 里给出了流程:从 build log 里抽错,把相关代码片段和 API 文档拼起来,再让模型分析根因、给出修正实现。这个思路是对的,因为编译错误日志本身就是一种“强监督信号”,它明确告诉你哪里违反了接口约束。
第二类是 kernel 级数值错误。也就是代码能编译,但结果不对。这个比 API 错误难,因为它往往意味着:
1. memory staging 有问题;
2. 累加顺序不对;
3. host-kernel 的 tiling 语义不一致;
4. 某个边界条件没处理好。
作者在 Algorithm 2 里做的事是:找出这类“能编译但验错”的样本,再配对 ground-truth kernel,用重构式 CoT 让模型重新分析错误并生成正确实现。

这套做法的意义在于:它把“失败样本”从噪声变成了高价值教材。
普通 SFT 像是在给学生看标准答案;
而 error-derived SFT 像是在把错题本系统化整理出来,再教学生为什么错、应该怎么改。
这通常比只看标准答案更有针对性。
当然,这里也有一个值得警惕的点:作者把 GT kernel 当作监督目标,这会明显提升“向已有实现靠拢”的能力,但也可能让模型更擅长模仿已有写法,而不是探索真正新的优化结构。所以它提升的是“可靠复现与修正”能力,不一定直接等价于“原创优化”能力。
Reinforcement Learning
在 RL 部分,作者采用 DPO 风格的偏好优化。这里最重要的是正负样本怎么构造:
1. 编译通过且精度通过的,作为正样本。
2. 编译通过但精度失败的,作为负样本。
这比拿“编译失败样本”做负例更有信息量,因为:
1. 编译失败说明模型连门槛都没过;
2. 编译通过但精度失败,说明它已经走到了更接近可用实现的位置;
3. 此时正负样本之间的差别,往往更接近真正关键的执行语义差别。
不过这部分也有一条明显短板:当前 RL 的优化目标主要还是围绕正确性,性能只是在最终评测里看,并没有形成一个强的性能导向奖励。作者自己在结论里也承认,未来要进一步引入 performance-aware reward。
这其实意味着:现阶段的 RL 更像“让模型少犯执行级错误”,而不是“系统性学会性能最优”。
NPUKernelBench
如果没有一个像样的 benchmark,这篇文章很容易退化成“作者自己说自己模型写得不错”。NPUKernelBench 的作用,就是尽量把这个问题制度化。
Benchmark Overview
作者强调 benchmark 是 end-to-end 的:给定任务、生成代码、编译、执行、验证正确性、测性能,全流程自动化。
这点很重要,因为很多代码生成 benchmark 到了硬件方向就偷懒,只做静态检查或者少量运行样例。这里作者明确把真实硬件执行纳入评测闭环,这让结果更可信。
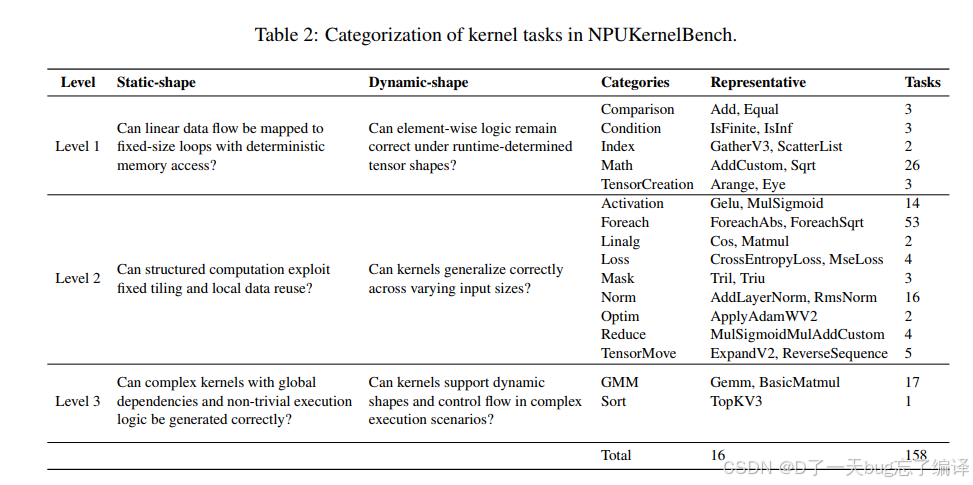
Table 2 把 158 个 kernel 按 Level 1、2、3 分级,还进一步区分 static-shape 和 dynamic-shape。
这个设计很有必要,因为如果把所有任务混在一起,平均分会掩盖问题。
1. Level 1 是简单元素级或算术操作,例如 Add、Sqrt。
2. Level 2 是常见神经网络算子,如激活、norm、mask、reduce 等。
3. Level 3 则是 Gemm、TopK、attention 相关这类具有全局依赖或复杂控制流的任务。
这个分层背后的逻辑很清楚:
1. Level 1 更像“会不会写基本模板”。
2. Level 2 开始考察局部数据复用、结构化计算和标准优化套路。
3. Level 3 才真正逼近复杂工业 kernel 的推理深度。
从后面结果看,这个分层是有效的,因为模型在 Level 1、2、3 上的表现差异非常明显。
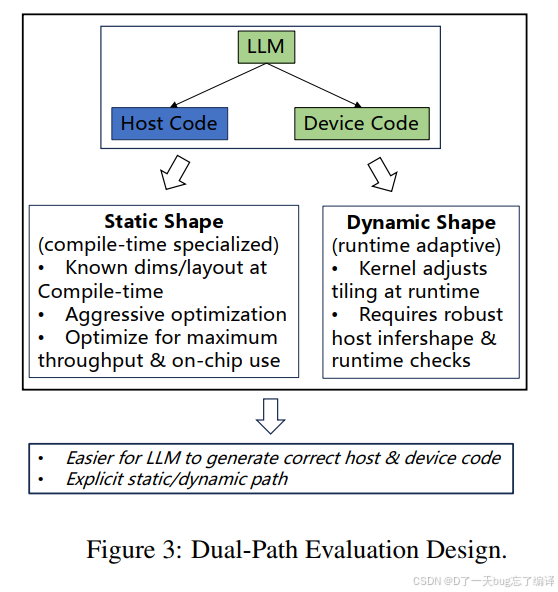
Figure 3 的双路径设计是这篇 benchmark 的一个亮点。
作者区分了:
1. Device-Only Path:只让模型生成 kernel,host 端由固定驱动提供。
2. Host+Device Path:让模型同时生成 host 和 kernel。
这背后的现实考虑是:
1. 有些任务主要难在 kernel 本体;
2. 有些任务真正难在 host 和 device 的协同,比如动态 shape、tiling 计算、shape inference。
如果不区分这两种情况,就会把“kernel 逻辑错误”和“host 侧 orchestration 错误”混在一起,最后很难分析模型到底卡在哪。
Figure 3 其实是在告诉你:作者不把 kernel 生成看成一个单文件补全问题,而是把它看成系统代码生成问题。这一点和工业需求是吻合的。

Table 3 列出了通用 prompt 指令,比如:
1. 角色设定是专业 Ascend kernel 工程师。
2. 必须使用 Ascend C。
3. 输出格式上 host 与 kernel 分离。
4. 注意数据类型、shape、layout。
这张表的价值不在“prompt 写得多漂亮”,而在“作者试图规范输入接口”,减少因为 prompt 随意性导致的评测波动。
不过这里要保持客观:这类 role prompt 和格式约束确实能帮助编译率,但它们更多是“把模型约束在轨道上”,不等于模型真的学会了深层推理。所以它是必要工程措施,不是根本创新。

Table 4 给了编译日志示例,Table 5 给了评分准则。它们说明作者对评测链条做了拆解:
1. 先看能否编译。
2. 再看数值精度是否过线。
3. 再看性能相对基线的速度提升。
这里尤其值得注意的是精度检查并不是一句“输出相同”这么简单,而是带绝对误差和相对误差阈值的。对浮点 kernel 来说,这比简单的 exact match 更合理。
三、实验
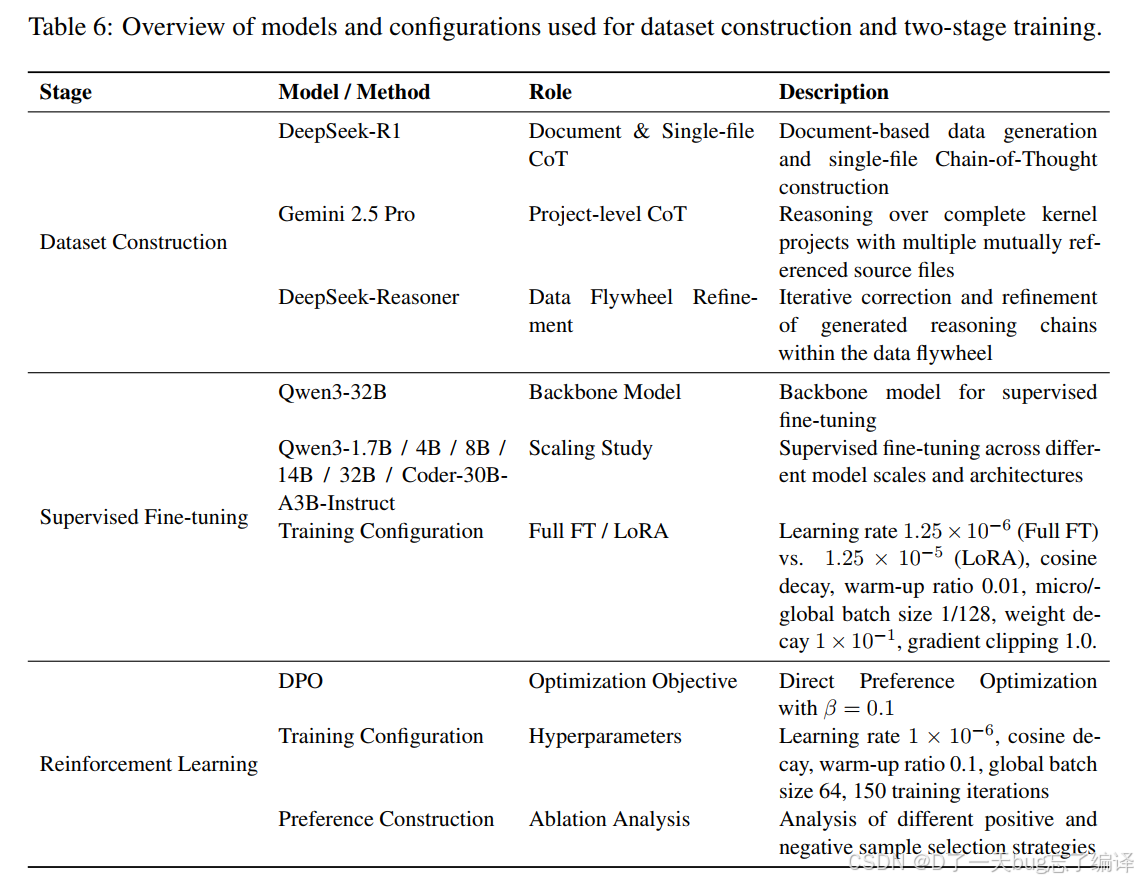
Table 6 汇总了数据构建、SFT、RL 阶段的模型和配置。作者不只训了一个模型,而是还比较了不同规模的 Qwen 变体,并分析了 full fine-tuning 和 LoRA。
这使得论文更像“systematic study”,而不只是“我们选了一个模型调一调”。
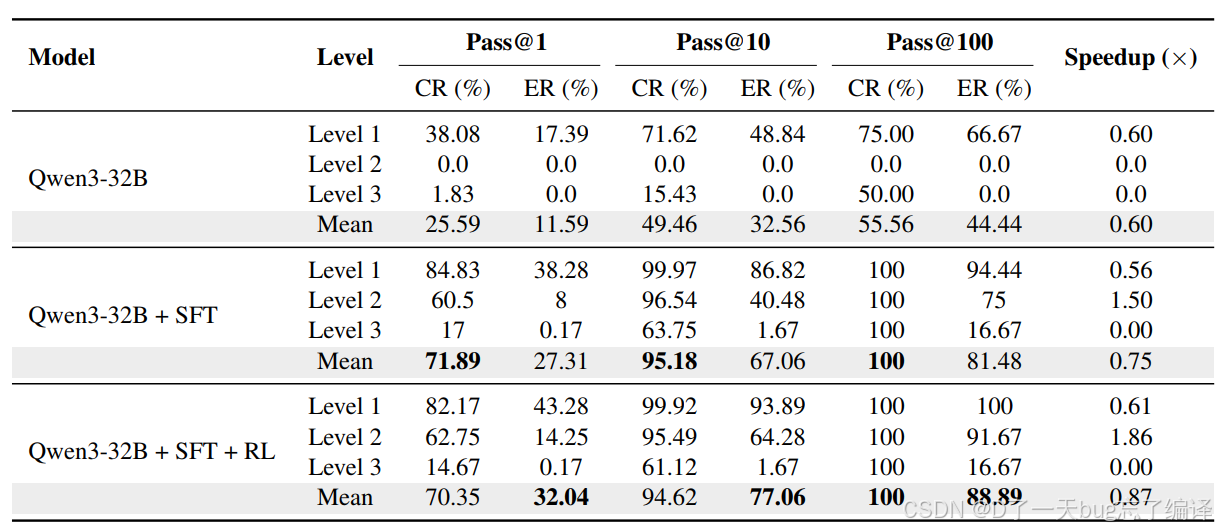
Table 7 是全文最核心的结果表之一。它展示了 base model、SFT、SFT+RL 在不同 level、不同 pass@k 下的编译率和执行率,以及 speedup。
最值得看的点有四个。
第一,base model 基本只在 Level 1 上还有一点点能力。
Qwen3-32B 在 Level 1 上 Pass@1 编译率 38.08%,执行率 17.39%,说明它能碰巧写出一些简单 kernel;但到了 Level 2,Pass@1 和 Pass@10 几乎全灭;Level 3 更是基本无执行成功。
这再次证明,普通代码能力不能直接迁移到底层 NPU 代码能力。
第二,SFT 带来了决定性的跃升。
Qwen3-32B + SFT 在 Level 2 上:
1. Pass@1 编译率到 60.5%
2. Pass@10 编译率到 96.54%
3. Pass@10 执行率到 40.48%
4. Pass@100 执行率到 75%
这说明领域数据和领域训练确实把模型从“几乎不会”拉到了“能做相当一部分复杂任务”。
第三,RL 的增益主要体现在执行正确性和性能,而不是简单编译率。
加入 RL 后,Level 2 上 Pass@10 执行率从 40.48% 提升到 64.28%,速度提升从 1.50x 提升到 1.86x。这个变化很符合作者方法设计的逻辑,因为 RL 更像是在细化已经基本可用的候选实现。
第四,Level 3 依然很难。
即便在 SFT+RL 后,Level 3 还是处在“编译率有所提高,但执行正确率接近没有真正突破”的状态。这一点非常重要,因为它说明作者的方法不是“已经解决了 NPU kernel 生成”,而是主要把 Level 1/2 打通了。
所以如果客观评价 Table 7:
1. 在中等复杂度任务上,结果是很强的。
2. 在真正最难的任务上,离实用还有明显距离。
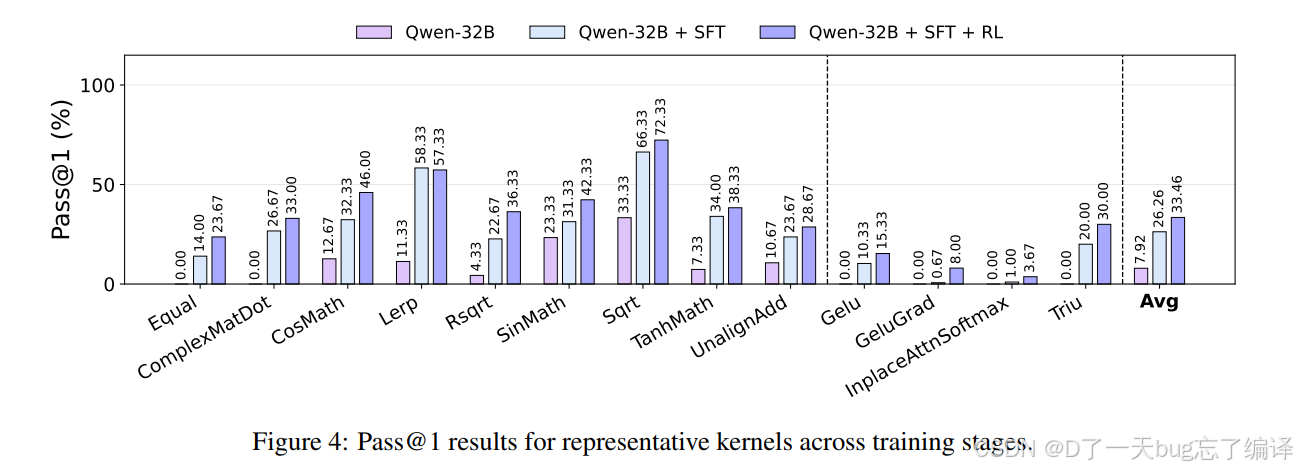
Figure 4 画的是若干代表 kernel 在 base、SFT、SFT+RL 三阶段下的 Pass@1 表现。
这张图的价值在于,它说明模型提升不是只靠少数容易任务把平均分拉高,而是在多个典型 kernel 上都有明显改善。
作者给出的平均 Pass@1:
1. base:7.92%
2. SFT:26.26%
3. SFT+RL:33.46%
从解释上看:
1. SFT 主要教会模型“正确的结构和接口”;
2. RL 则进一步帮助模型在多个“看起来都差不多像对了”的候选中,偏向真正执行正确的版本。
这张图还能帮你理解一个问题:为什么 RL 没有像 SFT 那样带来数量级提升?因为 RL 不是从零教模型写 AscendC,而是在已有基础上做细修。它更像打磨,而不是从无到有地立框架。
Table 7 的 speedup 列值得单独说。
base model 在 Level 1 上只有 0.60x,意思是连专家基线的 60% 都达不到;在 Level 2/3 基本没有有效性能结果。
SFT 后 Level 2 达到 1.50x,RL 后进一步到 1.86x。也就是说,在部分中等复杂算子上,模型生成的 kernel 已经不只是“能跑”,而是可能比人工基线更快。
这里有两种解读都要保留:
1. 正向解读:说明模型确实学到了一些有效的 tiling、memory reuse、pipeline 组织方式。
2. 保守解读:这里比较的是“专家实现基线”,但我们需要进一步知道这些基线有多强、是否充分优化、不同任务间方差多大。
所以这个 1.86x 是有说服力的积极信号,但还不能被简单解读成“模型全面超过专家”。
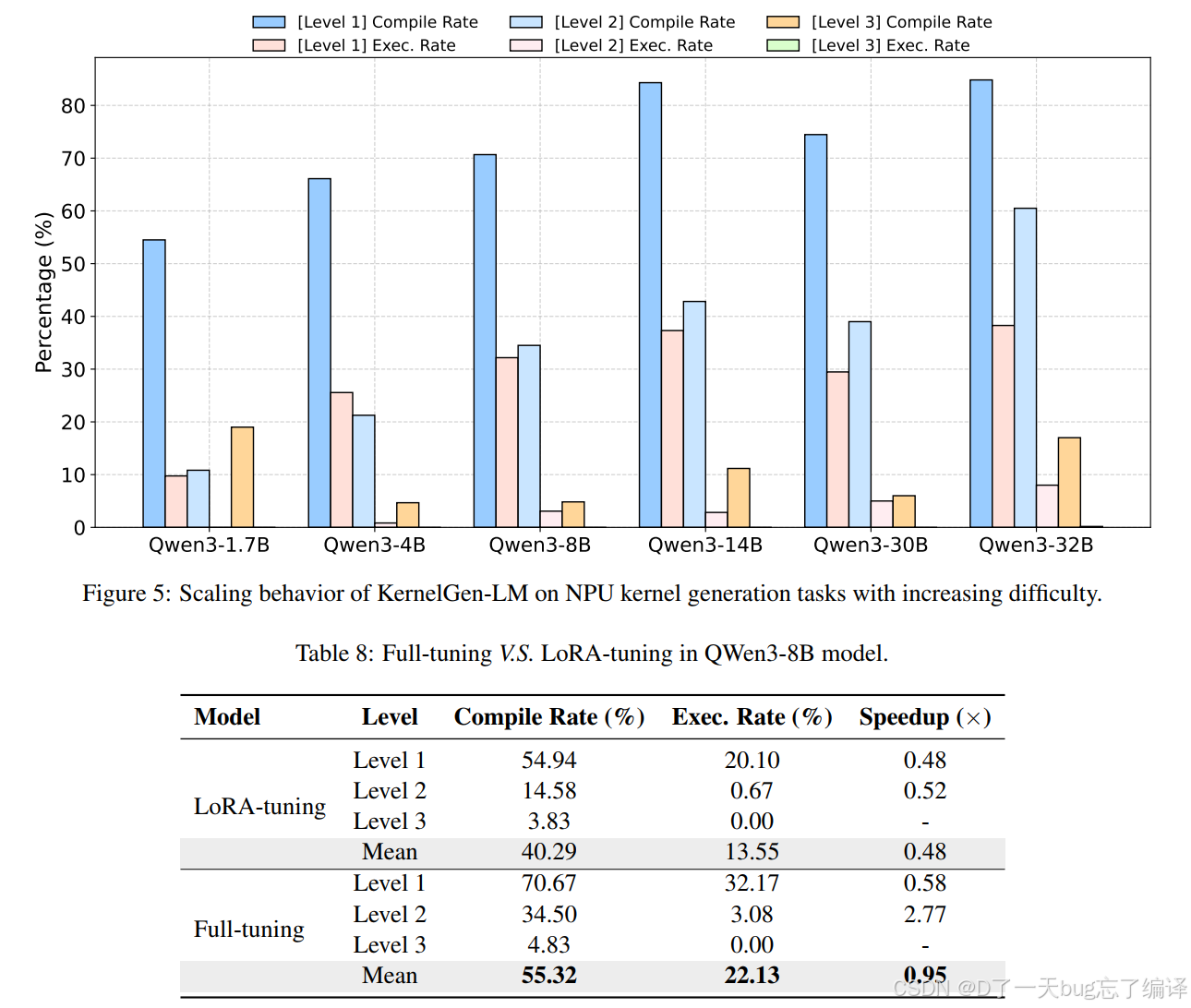
Figure 5 说明随着模型规模增大,Level 1 和 Level 2 的表现稳步提升,而 Level 3 仍然难。
这告诉我们两件事:
1. 更大的模型确实更能吸收这种专门知识。
2. 但仅靠加参数,解决不了最复杂 kernel 的结构推理问题。
Table 8 则比较了 full fine-tuning 和 LoRA。结果很鲜明:full tuning 在各层级都显著优于 LoRA,尤其在复杂任务上差距更大。
比如在 Qwen3-8B 上:
1. LoRA 的 Level 2 执行率只有 0.67%。
2. Full tuning 的 Level 2 执行率是 3.08%。
3. Full tuning 的 Level 2 speedup 还能到 2.77x,而 LoRA 只有 0.52x。
这个结论其实很合理。因为 NPU kernel 生成不是简单的“输出风格适配”,而是要把很多硬件相关的深层知识写进模型。LoRA 这种低秩适配往往够做格式对齐,不一定够做深层知识重塑。
这也是这篇论文一个比较有价值的经验结论:在这种 precision-critical、知识密集型代码任务上,full tuning 可能比参数高效微调更必要。
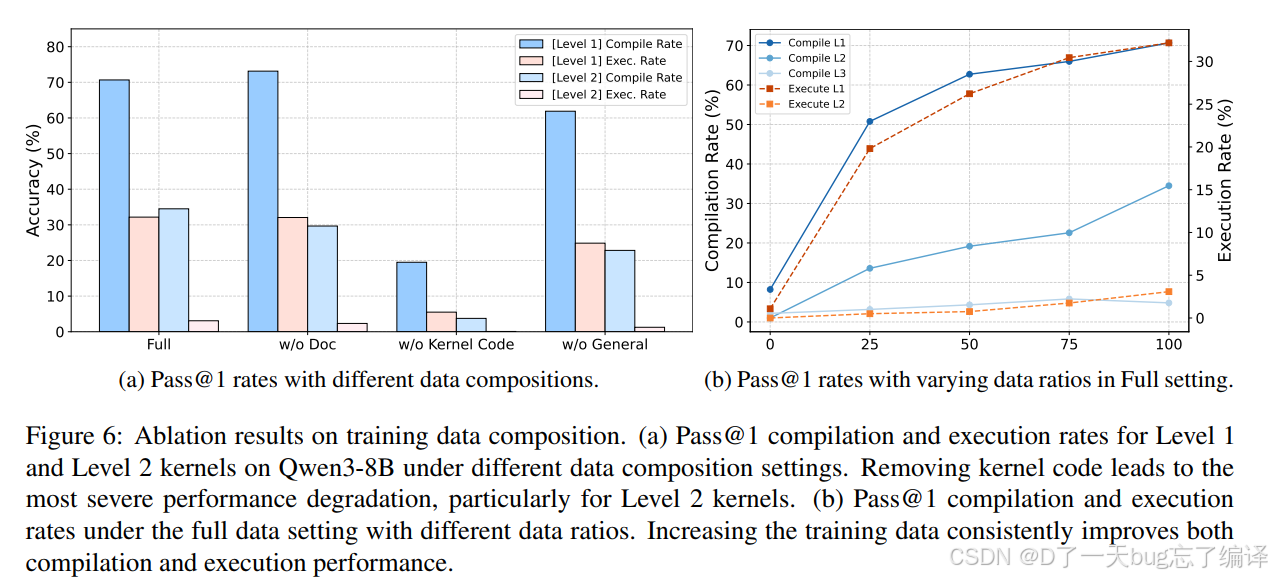
Figure 6a 比较了不同数据组成的影响。结论非常清楚:
1. 去掉 kernel code,性能掉得最厉害。
2. 去掉文档数据或通用数据,也会变差,但没有那么致命。
这说明:
1. 文档能教规则;
2. 通用数据能保推理基础;
3. 但真正让模型学会写 kernel 的,还是高质量真实 kernel 及其 reasoning。
Figure 6b 又说明,数据量增加会持续带来提升。这种结果通常意味着领域还没有被“喂饱”,更多高质量数据大概率仍然有效。
这也是这篇文章最有现实启发的一点之一:在硬件代码生成里,数据稀缺是头号瓶颈,而不是单纯缺一个更花哨的训练技巧。
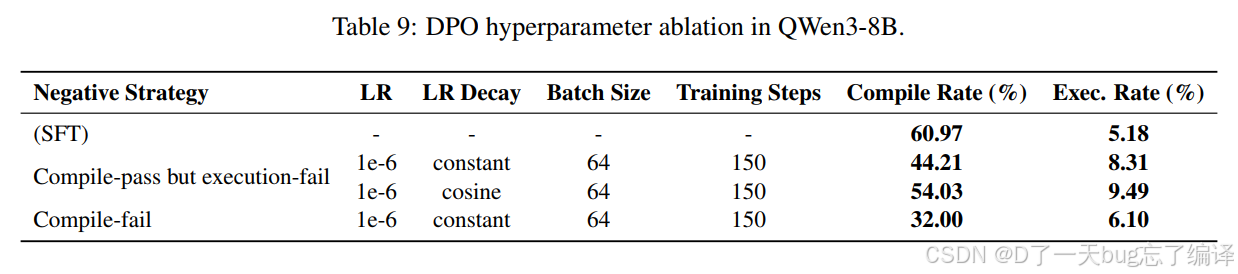
Table 9 比较了不同 DPO 设置。最关键的发现是:
1. 用“编译通过但执行失败”的样本做负例,比用“编译失败”的样本做负例更好。
2. cosine 学习率衰减优于 constant。
这个结果和方法论是统一的。因为编译失败太“初级”了,负例信息密度不高;而执行失败的样本更接近正确实现,模型才能学到真正关键的差别。
这张表虽然不是全篇最显眼的结果,但它证明作者对 RL 训练并不是拍脑袋。
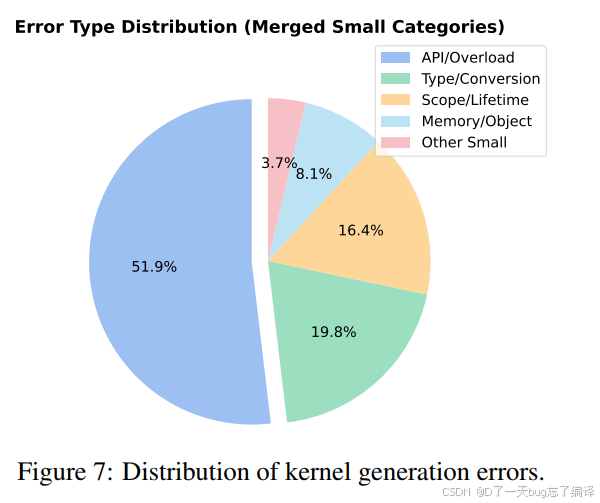
作者统计了约 4000 个失败样本,Figure 7 给出错误分布:
1. API 签名/重载错误占 51.9%
2. 数据类型与类型转换错误占 19.8%
3. 变量作用域和生命周期错误占 16.4%
4. 内存与对象使用错误占 8.1%
5. 纯语法和结构错误只是小头
这个结论非常重要。它说明当前模型的主要问题已经不是“不会写 C++ 语法”,而是不会处理硬件 DSL 中那些严格的语义契约。
换句话说,难点并不在表面文本生成,而在:
1. API 合法性推理;
2. 类型规则;
3. host/device 跨边界变量一致性;
4. 内存对象语义。
这个发现也反过来支持了作者的方法路线:为什么要做文档 CoT、错误驱动监督、执行反馈学习?因为真正的失败点就在这些语义约束上。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)