
昇腾多机推理极速上手:10倍简化的 DeepSeek R1 超大规模模型部署(上)
在昇腾 NPU 上部署超大规模模型,往往面临一个现实难题:目前主流的官方推理引擎的虽然性能表现尚可,但。从环境准备、配置初始化到参数细节调整,每一步都需要格外谨慎,否则极易因细节遗漏或配置错误而导致部署失败,问题定位也十分困难。是一个,提供,能够运行在等多种 GPU 上,轻松构建异构 GPU 集群,支持等各种推理引擎。为了降低部署门槛,GPUStack 提供了,用户只需少量 UI 配置,就能完成过
在昇腾 NPU 上部署超大规模模型,往往面临一个现实难题:目前主流的官方推理引擎 MindIE 的多机分布式推理虽然性能表现尚可,但配置流程异常复杂。从环境准备、配置初始化到参数细节调整,每一步都需要格外谨慎,否则极易因细节遗漏或配置错误而导致部署失败,问题定位也十分困难。
GPUStack 是一个100%开源的模型服务平台(MaaS,Model-as-a-Service),提供高性能推理与完善的模型服务管理能力,能够运行在 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程、天数智芯、寒武纪、沐曦等多种 GPU 上,轻松构建异构 GPU 集群,支持 vLLM、MindIE、llama-box 等各种推理引擎。
为了降低部署门槛,GPUStack 提供了对 MindIE 分布式推理的完整封装和简化,用户只需少量 UI 配置,就能完成过去需要大量手动步骤、文档比对与重复调试的部署流程。相比原生方案,GPUStack 大幅简化了部署复杂度,减少了错误发生的可能性,使得在昇腾上运行大规模模型的过程更加高效、丝滑且稳定。
本文将带来一篇实践教程,演示如何通过 GPUStack 快速在昇腾上丝滑运行 MindIE 分布式推理,并部署以 DeepSeek R1 671B 为例的超大规模模型。

2、已安装 NPU 驱动和相应固件(https://www.hiascend.com/hardware/firmware-drivers/community?product=4&model=26&cann=8.2.RC1&driver=Ascend+HDK+25.2.0)
在 GPUStack v0.7.1 镜像中,内置的 CANN 版本为 8.2.RC1,该版本依赖 25.2 及以上驱动。用户可通过执行以下命令检查当前驱动版本:npu-smi info
注意,在后续安装或升级时,应根据镜像中所包含的 CANN 版本,选择与之匹配的驱动版本,以确保功能正常。
3、通过 hccn_tool(/usr/local/Ascend/driver/tools/hccn_tool)配置:
NPU 设备 RoCE 网卡的 IP
网关(按需,仅跨 L3 需要)
网络检测对象 IP(双机直连为对端 NPU 设备 IP,多机互联为任一对端节点 NPU IP,L3 则为网关 IP)
在每个节点上,通过以下命令检查并优化 RoCE 配置:
1.检查物理链接
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
# 2.检查链接情况
for i in {0..7}; do hccn_tool -i $i -link -g ; done
# 3.检查网络健康情况
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done
# 4.查看网络检测IP配置是否正确
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done
# 5.查看网关是否配置正确(按需)
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done
# 6.检查NPU底层tls校验行为一致性,建议统一全部设置为0,避免hccl报错
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
# 7.NPU底层tls校验行为置0操作,建议统一全部设置为0,避免hccl报错
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done
获取 NPU IP 地址:for i in {0..7}; do hccn_tool -i $i -ip -g | grep ipaddr; done
检查跨节点 NPU 之间的连通性,需要替换为实际配置的对端节点 NPU IP:
# 指定节点 NPU 0 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 0 -ping -g address 192.168.1.9
# 指定节点 NPU 1 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 1 -ping -g address 192.168.1.10
# 指定节点 NPU 2 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 2 -ping -g address 192.168.1.11
# 指定节点 NPU 3 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 3 -ping -g address 192.168.1.12
# 指定节点 NPU 4 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 4 -ping -g address 192.168.1.13
# 指定节点 NPU 5 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 5 -ping -g address 192.168.1.14
# 指定节点 NPU 6 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 6 -ping -g address 192.168.1.15
# 指定节点 NPU 7 光纤直连的对端节点 NPU IP(或通过 RoCE 交换机则为任一对端节点 NPU IP)
hccn_tool -i 7 -ping -g address 192.168.1.16
HCCN Tool 帮助文档:https://support.huawei.com/enterprise/zh/doc/EDOC1100493980?idPath=23710424|251366513|22892968|252309113|250702818
4、下载模型权重,若需要量化模型,下载社区量化好的模型权重,或通过 msModelSlim 昇腾模型压缩工具进行量化(https://gitcode.com/Ascend/msit/tree/master/msmodelslim)
本文以 BF16 精度的 DeepSeek-R1 模型为例,该模型需要四台 Atlas 800T A2(8 卡 910B 64G)服务器才可运行。模型权重地址:https://huggingface.co/unsloth/DeepSeek-R1-BF16,两台则需要使用 W8A8 量化。
5、GPUStack 昇腾 910B NPU 镜像,以下镜像内置 MindIE 2.1RC1 与 vLLM Ascend v0.9.1
通过 Docker 下载 GPUStack 镜像:docker pull --platform=linux/arm64 crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.7.1-npu-vllm-v0.9.1
安装 GPUStack
参考 GPUStack MindIE 多机分布式推理教程(https://docs.gpustack.ai/latest/tutorials/running-deepseek-r1-671b-with-distributed-ascend-mindie/)安装 GPUStack:
1、在节点1启动 Server 与内置 Worker:
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware:ro \
-v /etc/hccn.conf:/etc/hccn.conf:ro \
-v /etc/ascend_install.info:/etc/ascend_install.info:ro \
-v gpustack-data:/var/lib/gpustack \
-v /data/models:/data/models \
--shm-size=1g \
--network=host \
--ipc=host \
crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.7.1-npu-vllm-v0.9.1 \
--cache-dir /data/models
启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为 /data/models,可按实际修改,多节点需要统一路径
查看容器日志确认 GPUStack 是否已正常运行:
docker logs -f gpustack
若容器日志显示服务启动正常,使用以下命令获取 GPUStack 控制台的初始登录密码和用于其它节点加入 GPUStack 的认证 Token:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
docker exec gpustack cat /var/lib/gpustack/token
2、在其它节点启动 Worker 并注册到节点1的 GPUStack,按实际修改 --server-url 和 --token:
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware:ro \
-v /etc/hccn.conf:/etc/hccn.conf:ro \
-v /etc/ascend_install.info:/etc/ascend_install.info:ro \
-v gpustack-data:/var/lib/gpustack \
-v /data/models:/data/models \
--shm-size=1g \
--network=host \
--ipc=host \
crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.7.1-npu-vllm-v0.9.1 \
--cache-dir /data/models \
--server-url http://<节点1的 GPUStack URL 地址> \
--token <从节点1获得的认证 Token>
1) 启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为 /data/models,可按实际修改,多节点需要统一路径
(2) http://<节点1的 GPUStack URL 地址> 表示 GPUStack 的访问地址,默认为节点1的 IP 地址 + 80 端口
(3) <从节点1获得的认证 Token> 为在节点1通过 docker exec gpustack cat /var/lib/gpustack/token 命令获得的认证 Token
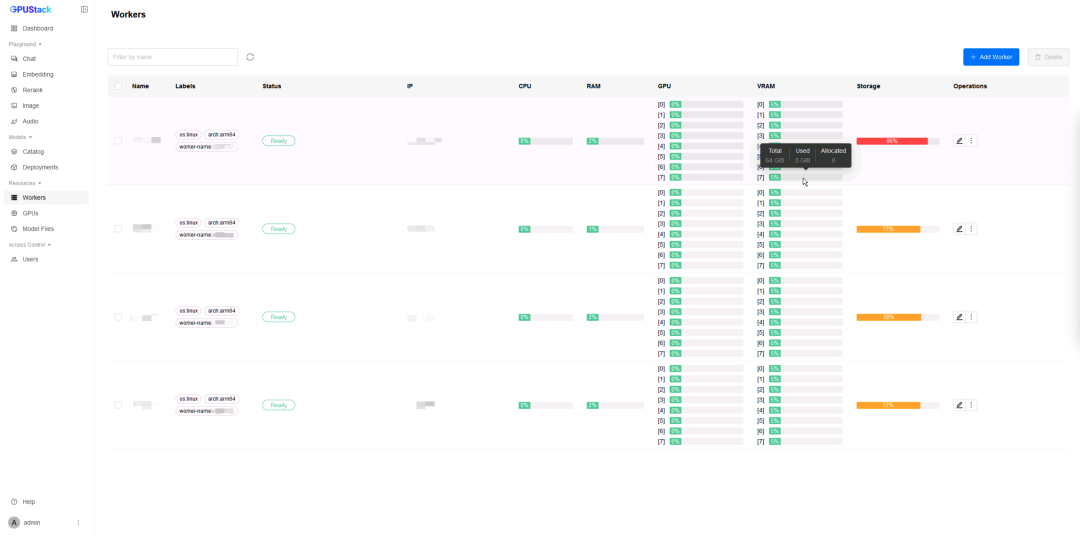
在浏览器中通过节点1的 IP 访问 GPUStack 控制台(http://HOST_IP),使用默认用户名 admin 和前面获取的初始密码登录。登录 GPUStack 后,在资源菜单可查看识别到的昇腾节点和 NPU 资源:

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)