
Python-对excel文件操作-pandas库
表格函数 / 方法核心参数作用read_excelsheet_nameusecolsdtypena_values精准读取 Excel,避免加载无关数据to_excelstartrowna_rep美化 Excel 输出,避免多余索引列lociloc行标签 / 列名 / 行号 / 列号精准定位单元格 / 行列dropnaaxishowsubset灵活删除缺失值fillnavaluemethodinpl
前言:
我们能使用pandas库来干什么?
我查到的是,pandas库在数据计算和数据清洗上的优势,数据计算大家可能都明白,但是数据清洗又是怎么回事?
数据清洗(Data Cleaning)就是把 “脏数据” 变成 “干净数据” 的过程,是数据分析前的核心步骤。
简单来说,原始数据里经常会有各种问题:
- 缺失值:比如表格里某行 “年龄” 是空的
- 重复值:同一条用户记录出现了好几次
- 异常值:比如 “身高” 列出现了 2000cm 这种明显错误
- 格式不一致:比如 “日期” 有的写 2025-03-06,有的写 2025/3/6,有的写 3/6/25
- 错误数据:比如 “性别” 列出现了 “未知”“保密” 等无效标签
特点:
专门处理结构化数据(表格、CSV、Excel、数据库数据),能高效(即)完成:数据筛选、排序、分组、合并、缺失值处理、统计分析等,比纯 openpyxl 处理数据快 10~100 倍。
一、pandas 核心基础
1. 核心数据结构(必须掌握)
pandas 只有两个核心结构,所有操作都围绕它们展开:
表格
| 结构 | 维度 | 类比 | 说明 |
|---|---|---|---|
Series |
一维 | Excel 单列数据 | 带「索引」的数组(索引默认是 0,1,2...,也可自定义) |
DataFrame |
二维 | Excel 工作表 / 数据库表 | 由多个 Series 组成的表格(有行索引 + 列名) |
快速创建示例:
import pandas as pd
import numpy as np
# 1. 创建 Series(单列)
s = pd.Series([18, 25, 30], index=["小明", "小红", "小刚"], name="年龄")
# 输出:
# 小明 18
# 小红 25
# 小刚 30
# Name: 年龄, dtype: int64
# 2. 创建 DataFrame(表格)
df = pd.DataFrame({
"姓名": ["小明", "小红", "小刚"],
"年龄": [18, 25, 30],
"语文": [99, 67, 55],
"数学": [98, 32, 77]
})
# 输出:
# 姓名 年龄 语文 数学
# 0 小明 18 99 98
# 1 小红 25 67 32
# 2 小刚 30 55 77
1.1、Series (我暂时可以记住为系列组)
是一维的带索引的数据结构,由两部分组成:
- 数据(values):一组同类型数据(数字、字符串、布尔值等)
- 索引(index):给每个数据打标签,默认是
0,1,2...,也可以自定义(比如人名、日期)
形参名 类型 说明 默认值 示例 data列表 / 数组 / 字典 / 标量 必填,要存储的数据 无 [18,25,30]index列表 / 数组 自定义行标签,长度必须和 data一致0,1,2...["小明","小红","小刚"]namestr 给 Series 起名字(列名) None "年龄"dtypestr/numpy 类型 强制指定数据类型(如 int/str/float)自动推断 dtype="int32"copybool 是否复制输入数据 False copy=True- data支持的数据类型中标量,可以理解为单个变量,可以是数字,字符等,代码中如果data为标量,则后续所有索引后的数据都是这个值。
- 表格中的最后一个参数,也需要详细解释一下:即copy参数
copy=False(默认值:不复制,直接引用)pandas 不会创建新的内存副本,新 Series 直接指向原数据的内存地址;如果你修改了原数据,新 Series 里的值也会跟着变;反之,修改 Series 里的值,原数据也会被改掉(如果原数据是可变类型,比如 numpy 数组)。- dtype存在两种类型,一种是python类型,一种是numpy类型,这里如果是指定数据类型,就必须所有数据都是这种类型。当
data里同时存在str、int、float等多种类型时,如果你强行指定一个单一dtype(比如dtype=int),pandas 会尝试转换,转换失败就直接报错;如果不想报错,就必须先做「数据清洗」,统一类型后再创建 Series。当
data里同时存在str、int、float等多种类型时,如果你强行指定一个单一dtype(比如dtype=int),pandas 会尝试转换,转换失败就直接报错;如果不想报错,就必须先做「数据清洗」,统一类型后再创建 Series。
- 用字典创建(键值自动变成索引):
python
s = pd.Series({"小明":18, "小红":25, "小刚":30}, name="年龄")不过这里也存在一个问题,使用字典作为data数据传入时,index参数参数还要不要写,首先建议是不写,但是手欠写了会怎么样
s = pd.Series( {"小明": 18, "小红": 25, "小刚": 30}, index=["小明", "小刚", "小丽"], # 手动指定索引 name="年龄" ) print(s) 输出: plaintext 小明 18.0 小刚 30.0 小丽 NaN Name: 年龄, dtype: float64- 从代码中也可以看出,当index与字典值不符合时,则优先写入index的值,一句话总结就是index先优先考虑我们传入的实参,然后再回考虑字典的值
- 用标量创建(所有值相同):
python
s = pd.Series(0, index=["小明","小红","小刚"], name="年龄") # 所有人年龄都是0最后看一下实际表格中的效果
1.2、DataFrame(我暂时叫做数据帧)是二维的表格结构,由多个
Series组成,每一列是一个Series,先看之前代码中关于dataframe的描述
import pandas as pd import numpy as np # 字典:键=列名,值=每一列的数据(列表形式) df = pd.DataFrame( data={ "姓名": ["小明", "小红", "小刚", "小丽"], # 第一列:姓名(str) "年龄": [18, 25, 30, 22], # 第二列:年龄(int) "语文": [99, 67, 55, 88], # 第三列:语文(int) "数学": [98, 32, 77, 90] # 第四列:数学(int) }, index=["a", "b", "c", "d"], # 自定义行标签(行数=4,和数据行数一致) columns=["姓名", "年龄", "语文", "数学"], # 自定义列标签(和字典键一致,可省略) dtype=int, # 强制所有列类型(这里会把语文/数学转成int,若有np.nan则自动变float) copy=True )
形参名 类型 说明 默认值 示例 data字典 / 列表 / 数组 / Series,这个也是很重要的性质 必填,要存储的二维数据 无 {"姓名":["小明"], "年龄":[18]}index列表 / 数组 自定义行标签,长度 = 行数 0,1,2...index=["小明","小红","小刚"]columns列表 / 数组 自定义列标签,长度 = 列数 字典键 / 0,1,2...columns=["姓名","年龄"]dtypestr/numpy 类型 强制指定所有列的数据类型 自动推断 dtype="float64"copybool 是否复制输入数据 False copy=True
代码中,还引入了一个叫做numpy的模块,
Numerical Python)是 Python 里专门做「数值计算」的底层库,你可以把它理解成:
Python 里的「计算器 + 高速数组」它是 pandas、matplotlib 等数据科学库的「地基」。
- pandas 里所有的数字计算(比如
df["语文"] + df["数学"]、求平均值mean()),底层都是靠 numpy 来完成的。- 你可以把 pandas 看成「Excel 表格」,numpy 就是「表格背后的计算器芯片」—— 你平时用表格(pandas)就够了,但复杂计算都要靠芯片(numpy)算。
数据类型(dtype)
pandas 会自动识别数据类型,也可手动指定,常见类型:
int64:整数(如年龄)float64:浮点数(如成绩、金额)object:字符串(如姓名、性别)datetime64:日期时间(如注册时间)bool:布尔值(如是否及格)
以series为dataframe的data数据,真实代码如下:
# 车载测试场景改造示例
s_case_id = pd.Series([1001, 1002, 1003, 1004], name="用例ID", dtype=int)
s_signal = pd.Series([0x12, np.nan, 0x34, 0x56], name="信号值", dtype=np.float64)
s_result = pd.Series(["PASS", "FAIL", "PASS", "PASS"], name="执行结果", dtype=str)
# 生成测试用例 DataFrame
df_test = pd.DataFrame({
"用例ID": s_case_id,
"信号值": s_signal,
"执行结果": s_result
})二、pandas 高频函数 + 核心参数(按场景分类)
场景 1:读取 / 写入文件(和 Excel/CSV 交互)
2.1. pd.read_excel()(读取 Excel的核心函数)
最常用的函数,核心参数覆盖 90% 场景:
df = pd.read_excel(
io="数据.xlsx", # 必填:文件路径/文件对象
sheet_name="用户信息", # 可选:工作表名/索引(0=第一个),默认0
header=0, # 可选:哪一行作为列名,默认0(第一行)
usecols=["姓名", "语文", "数学"], # 可选:只读取指定列,避免加载无关数据
skiprows=1, # 可选:跳过前1行(如跳过标题行)
nrows=1000, # 可选:只读取前1000行(大数据量时提速)
dtype={"年龄": int, "语文": float}, # 可选:指定列的数据类型
na_values=["无", "空"], # 可选:将指定字符串识别为缺失值(NaN)
engine="openpyxl" # 可选:读取.xlsx用openpyxl,读取.xls用xlrd
)
pd.read_excel(),可以说是核心函数了,也是使用最为频繁的函数。
将 Excel 中的工作表数据读取为 pandas 的 DataFrame(二维表格)或 Series(一维数据),是「Excel 数据 → pandas 分析」的第一步,支持对读取过程做筛选、类型指定、缺失值定义等预处理。
以下是对其形参的详细解释
(一)必选核心形参
打开表格的位置,名称或者链接,这一步也必须最先干,找到后,函数会自己打开这个文档
| 形参名 | 类型 | 说明 | 你的代码示例 |
|---|---|---|---|
io |
str / 文件对象 / 字节流 | 必填,Excel 文件的路径(本地绝对路径 / 相对路径)、文件对象(如 open() 打开的对象)或网络文件链接。 |
io="数据.xlsx"(相对路径,文件需在当前代码目录) |
这里的网络连接,需要知道的是,它可以是基于HTTP/HTTPS 协议的URL地址,比如https://xxx.com/data.xlsx,但是这个地址必须是指向xlsx文件的,也可以是这种形式/“/192.168.1.100/共享文件夹/data.xlsx”即局域网中的共享文件夹。
(二)工作表定位(选哪个表)
也就是pd.read_excel(),形参中的这个sheet_name非必须传入的参数,None是必须读取所有sheet
| 形参名 | 类型 | 可选值 | 默认值 | 说明 | 你的代码示例 |
|---|---|---|---|---|---|
sheet_name |
str / int / list / None |
1. 字符串:工作表名(如 "用户信息") 2. 整数:工作表索引(0 = 第一个表,1 = 第二个) 3. 列表:读取多个表(如 4. None:读取所有表(返回字典) |
0 | 指定要读取的 Excel 工作表,是多表文件的核心参数。 | sheet_name="用户信息"(精准读取名为「用户信息」的表) |
(三)行 / 列筛选(只读需要的数据,提速核心)
表格
| 形参名 | 类型 | 可选值 | 默认值 | 说明 | 你的代码示例 |
|---|---|---|---|---|---|
usecols |
list / str / callable |
1. 列表:列名(如 2. 字符串:Excel 列标(如 3. 函数:过滤列名 |
None(读取所有列) | 大数据量必用,只加载指定列,减少内存占用、提升速度。 | usecols=["姓名", "语文", "数学"](仅读取 3 列) |
skiprows |
int / list / callable | 1. 整数:跳过前 N 行(如 skiprows=1 跳过第一行)2. 列表:跳过指定行索引(如 [0, 2] 跳过第 1、3 行)3. 函数:过滤行 |
None(不跳过) | 用于跳过标题行、注释行、无效行,适配非标准格式 Excel。 | skiprows=1(跳过文件第一行,适用于第一行是无关标题的场景) |
nrows |
int | 正整数 | None(读取所有行) | 大数据量必用,只读取前 N 行,用于「预览数据」或「分批读取」。 | nrows=1000(仅读取前 1000 行,避免加载全量数据卡顿) |
(1)usecols,从字面意思理解就是决定,使用哪些列,这其中当其类型为字符串时,,也就是表中的将excel的列标作为实参传入,但是比较特殊的表达形式,就是采取“A:C”这种形式,而且必须是大写
(2),仔细看skiprows(即指定跳过行)这个参数,和usecols都存在函数作为实参传入,这个在实际复杂项目中也很有用的一个特点,我们也必须掌握。
假设 Excel 列名:["姓名", "年龄", "语文", "数学", "用例ID", "信号值"]
python
import pandas as pd
# 定义筛选函数:只保留包含"信号"或"用例"的列
def filter_columns(col_name):
# col_name 是当前遍历到的列名
if "信号" in col_name or "用例" in col_name:
return True # 保留
else:
return False # 丢弃
# 读取 Excel,只保留符合条件的列
df = pd.read_excel(
"车载测试报告.xlsx",
usecols=filter_columns, # 传入函数
engine="openpyxl"
)
print(df.columns) # 输出:['用例ID', '信号值']
效果:只加载和「信号 / 用例」相关的列,其他列(姓名 / 年龄 / 语文 / 数学)全部丢弃。
3. 示例 2:按「列名是否以特定字符开头」筛选
python
# 筛选:只保留以"信号"开头的列
def filter_signal(col_name):
return col_name.startswith("信号") # 以"信号"开头 → True,保留
df = pd.read_excel("车载测试报告.xlsx", usecols=filter_signal, engine="openpyxl")
效果:只加载 信号1/信号2/信号3 这类列,其他列丢弃。
代码详解:这里的形参不需要手动传参,col本质是字符串,而字符串本身在python,就具有startwith的方法
4. 示例 3:按「列数据类型」筛选(进阶)
python
# 先读取所有列名,再根据类型筛选
df_all = pd.read_excel("车载测试报告.xlsx", engine="openpyxl")
# 定义函数:只保留数值型列(int/float)
def filter_numeric(col_name):
return pd.api.types.is_numeric_dtype(df_all[col_name])
# 重新读取,只保留数值列
df_numeric = pd.read_excel(
"车载测试报告.xlsx",
usecols=filter_numeric,
engine="openpyxl"
)
效果:只保留 年龄/语文/数学 等数值列,姓名/用例结果 等字符串列被丢弃。
(四)数据预处理(读取时直接清洗)
表格
| 形参名 | 类型 | 可选值 | 默认值 | 说明 | 你的代码示例 |
|---|---|---|---|---|---|
header |
int / list / None | 1. 整数:指定哪一行作为列名(如 header=0 用第一行做列名)2. 列表:多级列名(如 [0,1] 用前两行做层级列名)3. None:无列名(列名会变成 0,1,2...) |
0 | 核心参数,决定 DataFrame 的列名来源,适配「无表头」「多级表头」Excel。 | header=0(用读取后的第一行作为列名,与 skiprows=1 配合:跳过原文件第一行,用原第二行做列名) |
dtype |
dict | 键:列名;值:数据类型(如 int, float, str, category) |
None(自动推断) | 避免数据类型错误的核心,强制指定列的类型(如身份证号设为 str,避免变成科学计数法)。 | dtype={"年龄": int, "语文": float}(强制「年龄」为整数,「语文」为浮点数) |
na_values |
list / dict | 1. 列表:全局缺失值映射(如 ["无", "空"] 均视为 NaN)2. 字典:按列指定缺失值(如 {"成绩": ["缺考", "0"]}) |
None(默认仅识别空单元格为 NaN) | 读取时自动将指定字符串转为缺失值(NaN),简化后续清洗。 | na_values=["无", "空"](将表格中「无」「空」均视为缺失值) |
(五)引擎适配(决定能读哪种格式)
表格
| 形参名 | 类型 | 可选值 | 默认值 | 说明 | 你的代码示例 |
|---|---|---|---|---|---|
engine |
str | 1. openpyxl:支持 .xlsx(Excel 2007+),可读可写2. xlrd:支持 .xls(Excel 97-2003),仅可读(xlrd 2.0+ 仅支持 .xls)3. odf:支持 .ods/.odt 格式 |
自动推断(.xlsx 用 openpyxl,.xls 用 xlrd) | 必设参数,避免因引擎缺失导致读取失败,尤其是 .xlsx 文件。 | engine="openpyxl"(明确用 openpyxl 引擎,适配 .xlsx 文件) |
odf的全称是open data format 是一种跨平台通用类型的数据格式,一套开放、无专利、跨平台(Windows/macOS/Linux)的办公文档标准,用来替代微软的 .docx/.xlsx/.pptx 等封闭格式,基于 XML 存储,可读性强,便于程序解析(比如 pandas)。
按照是表格还是文档类型的,具体可以分为ods和odt。
()
补充:pd.read_csv()(读取 CSV)
和
read_excel类似,核心差异参数:python
df = pd.read_csv( "数据.csv", encoding="utf-8", # 可选:编码格式(中文常用utf-8/gbk) sep=",", # 可选:分隔符(默认逗号,制表符用"\t") decimal="." # 可选:小数点符号(欧洲用",") )我们先来了解下什么是CSV,
CSV 是 Comma-Separated Values(逗号分隔值) 的缩写。
- 本质:它是一个纯文本文件(
.csv后缀),不是像 Excel 那样的二进制文件。- 规则:用特定的分隔符(通常是逗号
,,也可以是制表符\t)把一行数据的不同字段分开。- 结构:
- 第一行通常是列名(如:用例 ID, 信号值,结果);
- 从第二行开始是数据(如:1001,0x12,PASS)。
2. 直观对比(用你的测试数据举例)
表格
形式 样子 特点 Excel 文件 有颜色、字体、公式、多个工作表 二进制,复杂,体积大 CSV 文件 用记事本打开就是纯文字: 用例ID,信号值,执行结果1001,18.5,PASS1002,22.3,FAIL纯文本,简单,体积小
二、CSV 格式的核心优点(为什么车载测试常用?)
在你的汽车电子测试工作中,CSV 几乎是自动化脚本与工具之间交换数据的 “lingua franca(通用语)”,原因如下:
1. 极致的轻量与速度(最关键)
- Excel 文件包含大量格式信息,读取慢、占内存。
- CSV 是纯文本,读写速度极快,处理海量 CAN 报文日志时,CSV 比 Excel 效率高一个数量级。
2. 跨工具兼容性(万能接口)
- 你的 Python 脚本:原生支持,无需额外库(虽然用 pandas 更方便)。
- CANoe/CANalyzer:可以直接导出报文为 CSV。
- MATLAB:可以直接导入 CSV 做数据分析。
- Excel:双击就能打开(Excel 完美兼容 CSV)。
- 嵌入式上位机:资源受限,解析纯文本 CSV 比解析 Excel 容易 100 倍。
3. 不易损坏,可读性强
- Excel 文件一旦损坏可能无法打开。
- CSV 即使损坏,用记事本打开也能看到大部分数据,便于修复。
4. 版本控制友好
- 如果你用 Git 管理测试用例,CSV 的改动在 Git 里能清晰看到(哪一行数据变了);Excel 是二进制,Git 无法识别内部改动。
场景 2:数据筛选 / 查询(核心操作)
语法是:df[ 条件逻辑 ],这里的df是先前打开pd.read_excel()或pd.to_excel()函数返回的值。
本质就是:按条件(如数值大小、文本包含、逻辑组合)从 DataFrame 中「挑出」你需要的数据。
我将从 基础布尔索引(最常用)、 进阶查询(query 函数)来讲。
另外还有重要的一点,需要特别注意,筛选出来的数据,python解释器会生成一块新的内存来重新存储,而不是将原先的给覆盖掉
2.3、按列筛选
python
# 单列
df["姓名"] # 等价于 df.姓名(列名无空格时可用)
# 多列
df[["姓名", "语文", "数学"]]
这里的条件逻辑,最为简单,就是直接给出列名称,然后就筛选出这一列的数据了。
2.4、按行筛选(布尔索引)
python
# 条件1:年龄>20
df[df["年龄"] > 20]
# 条件2:语文成绩≥60 且 数学≥60
df[(df["语文"] >= 60) & (df["数学"] >= 60)] # 多条件用&(且)/|(或),必须加括号
# 条件3:姓名是小明或小红
df[df["姓名"].isin(["小明", "小红"])]
# 条件4:包含缺失值的行
df[df.isnull().any(axis=1)]
这里如何理解这句,布尔索引,本质上就是构建一个表达式,这个表达式为真,就能将数据提取出来。
此外这里支持的逻辑运算符和算术运算符,也需要知道;
| 逻辑符 | 含义 | 代码示例 | ||
|---|---|---|---|---|
& |
且(AND) | df[(df['信号值'] > 18) & (df['执行结果'] == 'PASS')] |
||
| | | ` | 或(OR)“、” | `df [(df [' 电压 '] > 14.5) | (df [' 电流 '] > 10)]` |
~ |
非(NOT) | df[~df['备注'].str.contains('测试')](排除包含 “测试” 二字的行) |
这里需要注意的是,这个和传统python使用的,and,or、not不一样,python这些关键字是比较英文口语化的表达
| 运算符 | 含义 | 你的车载测试场景示例 |
|---|---|---|
> / < |
大于 / 小于 | df[df['信号值'] > 50](筛选信号值大于 50 的用例) |
== |
等于 | df[df['执行结果'] == 'PASS'](筛选所有通过的用例) |
!= |
不等于 | df[df['报文ID'] != '0x123'](筛选 ID 不为 0x123 的报文) |
>= / <= |
大于等于 / 小于等于 | df[df['响应时间'] <= 2.0](筛选响应超标的用例) |
2.5、 df.loc[] / df.iloc[](精准定位)
loc:按「行索引 + 列名」定位(标签索引)iloc:按「行号 + 列号」定位(位置索引,从 0 开始)
python
# loc:取小明的语文成绩
df.loc[df["姓名"] == "小明", "语文"] # 输出99
# iloc:取第2行第4列(小红的数学成绩)
df.iloc[1, 3] # 输出32
# 切片:取前2行的姓名和年龄列
df.iloc[:2, :2]
表达形式上,行索引+列名,看起来是比较复杂的,而采取行号+列号,则是看起来比较简洁
场景 3:数据清洗(处理缺失值 / 重复值)
1. 缺失值处理
python
# 1. 查看缺失值
df.isnull().sum() # 统计每列缺失值数量
# 2. 删除缺失值
df.dropna(
axis=0, # 可选:0=删除行,1=删除列,axis关键参数
how="any", # 可选:any=有缺失值就删,all=全是缺失值才删
subset=["语文"] # 可选:只检查语文列的缺失值
)
# 3. 填充缺失值
df.fillna(
value={"语文": 0, "数学": 0}, # 可选:按列填充不同值
method="ffill", # 可选:ffill=向前填充,bfill=向后填充
inplace=True # 可选:是否修改原数据,默认False(返回新数据)
)
这里也是利用pandas自带的一些函数实现数据筛选的,我们一个一个来看
df.isnull().sum() 作用是统计每列缺失值数量,
这是一个链式调用,分为两步:
df.isnull():生成一个和原表大小一样的布尔矩阵。- 单元格是缺失值(NaN)→
True - 单元格有数据 →
False
- 单元格是缺失值(NaN)→
.sum():对每一列的布尔值求和(True记为 1,False记为 0)。- 结果:返回一个Series,显示每一列有多少个缺失值。
df.dropna(),函数,
以上代码,的作用如下
“只盯着语文列看,只要语文缺考,不管其他科多少分,直接把这行学生删掉”。
| 参数 | 取值 | 含义解析 | 本代码中的效果 |
|---|---|---|---|
axis |
0 (默认) |
按行删除。如果是 1,则按列删除。 |
删掉整行学生数据。 |
how |
"any" (默认) |
只要有一个缺失值就删。如果是 "all",必须整行全空才删。 |
只要语文列有空,就触发删除。 |
subset |
["语文"] |
限定检查范围。只看语文列,数学 / 英语列的缺失值忽略不计。 | 即使小刚数学缺考,但语文有分,所以小刚不会被删;小红语文缺考,小红被删。 |
df.fillna()函数的作用
作用:填充 DataFrame 中的缺失值(NaN),不会删除行 / 列,而是用指定规则把空值补上
2. 重复值处理
python
# 查看重复值
df.duplicated(subset=["姓名"]) # 按姓名判断是否重复
# 删除重复值
df.drop_duplicates(
subset=["姓名"], # 可选:按姓名去重
keep="first", # 可选:保留第一个/last/False(全删)
inplace=True
)
duplicated()函数和drop_duplicates,注意这里两个函数名称上的细微不同
| 项目 | 说明 |
|---|---|
| 函数作用 | 检查每行是否为重复行,按指定列判断重复 |
| 返回值 | 布尔 Series:True= 该行是重复行,False= 非重复行 |
形参 subset |
- 类型:list/str,默认 None- 作用:指定要检查重复的列(如 ["姓名"] 只按姓名判断)- 不传则检查所有列 |
| 是否必须传参 | 否(默认 subset=None) |
| 项目 | 说明 |
|---|---|
| 函数作用 | 删除重复行,返回新 DataFrame(或原地修改) |
| 返回值 | 新 DataFrame(inplace=False 时);None(inplace=True 时) |
形参 subset |
- 类型:list/str,默认 None- 作用:按指定列去重(如 ["姓名"] 只按姓名去重)- 不传则按所有列判断重复 |
形参 keep |
- 类型:str/bool,默认 "first"- 可选值: - "first":保留第一个出现的行,删后面重复 - "last":保留最后一个出现的行 - False:全删所有重复行(包括第一次出现的) |
形参 inplace |
- 类型:bool,默认 False- 作用:True= 原地修改原表;False= 返回新 DataFrame |
| 是否必须传参 | 否(全用默认值即可) |
场景 4:数据计算 / 新增列
1. 新增列
python
# 新增总分列
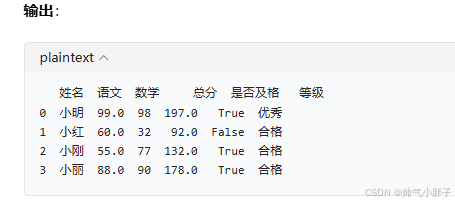
df["总分"] = df["语文"] + df["数学"]
# 新增是否及格列(布尔值)
df["是否及格"] = df["总分"] >= 120
# 新增等级列(条件判断)
df["等级"] = np.where(df["总分"] >= 180, "优秀", "合格")
- 作用:给原 DataFrame 新增一列
总分,值为「语文 + 数学」的和。- 逻辑:对每一行,把
语文和数学列的数值相加,结果存入新列总分。- 示例效果:
- 小明:99 + 98 = 197 →
总分=197- 小红:60 + 32 = 92 →
总分=92- 注意:如果
语文/数学有缺失值(NaN),相加结果也会是NaN。
python
运行
# 2. 新增是否及格列(布尔值) df["是否及格"] = df["总分"] >= 120
- 作用:新增一列
是否及格,用布尔值表示总分是否≥120。- 逻辑:对每一行判断
总分 >= 120,结果为True(及格)或False(不及格)。- 示例效果:
- 小明总分 197 →
True- 小红总分 92 →
False- 返回:直接在原
df上新增一列,列类型为bool。
python
运行
# 3. 新增等级列(条件判断) df["等级"] = np.where(df["总分"] >= 180, "优秀", "合格")
- 作用:新增一列
等级,按总分区间赋值(np.where是 numpy 条件判断函数)。- 参数拆解:
df["总分"] >= 180:判断条件;"优秀":条件为True时的赋值;"合格":条件为False时的赋值。- 示例效果:
- 小明总分 197 ≥ 180 →
"优秀"- 小红总分 92 < 180 →
"合格"- 返回:在原
df上新增一列,列类型为object(字符串)。
2. 统计计算
python
# 基本统计
df["语文"].mean() # 平均分
df["数学"].max() # 最高分
df["总分"].sum() # 总和
df["年龄"].median()# 中位数
# 按列统计所有指标
df.describe() # 输出计数、均值、标准差、最小值、四分位数、最大值
场景 5:数据分组 / 聚合(groupby)
python
# 按性别分组,计算各科平均分
df_group = df.groupby(
by="性别", # 必填:指定按哪一列分组(这里是「性别」列)
as_index=False # # 可选:是否把分组列(性别)设为行索引,默认True;设为False更易读(性别作为普通列)
)["语文", "数学", "总分"].mean() # 对选中的3列,分别求每组的平均值
# 多聚合函数(同时算平均分和最高分)
df_group = df.groupby("性别").agg(
语文平均分=("语文", "mean"),
数学最高分=("数学", "max")
)
这段代码是 pandas 中分组聚合的典型用法:先按「性别」把数据分成男生 / 女生两组,再对每组的成绩列做统计计算(如平均分、最高分)
df.groupby(by="性别"):- 把原表
df按「性别」列的值拆分成多个子表(比如男生组、女生组); - 不直接返回结果,而是一个
GroupBy对象,等待后续聚合操作。
- 把原表
as_index=False:- 默认
True:分组列(性别)会变成新表的行索引,看起来像男/女作为行号; - 设为
False:「性别」作为普通列保留,表结构更直观,方便后续导出 / 筛选。
- 默认
["语文", "数学", "总分"]:- 只对这三列做聚合,忽略其他列(如姓名、年龄);
.mean():- 对每个分组的这三列分别求平均值;
- 最终返回一个新 DataFrame,行是性别分组,列是各科平均分。
| 性别 | 语文 | 数学 | 总分 |
|---|---|---|---|
| 男 | 85.5 | 90.2 | 260.3 |
| 女 | 88.1 | 87.4 | 258.9 |
.agg():全称 aggregate,(翻译为集合;总计)支持对不同列应用不同聚合函数,也支持同一列应用多个函数;
语法格式:新列名=("原列名", "聚合函数名"):
("语文", "mean"):对「语文」列执行 mean() 操作;
语文平均分=:给结果列自定义名称,避免默认的 语文_mean 这种冗长名字;
聚合函数可以是:mean/max/min/sum/count/std 等,也可以是自定义函数。()
总结groupby函数的形参
| 形参 | 核心作用 | 新手推荐值 |
|---|---|---|
by |
指定分组列 / 规则 | 单列:"列名";多列:["列1", "列2"] |
as_index |
分组列是否为索引 | False(结果更易读) |
sort |
分组结果排序 | False(大数据提速) |
dropna |
是否保留 NaN 分组 | 排查缺失:False;常规统计:True |
observed |
分类列是否只显示有数据类别 | True(避免空分组) |
agg函数的形参列表
| 形参 | 作用 | 常用形式 |
|---|---|---|
func |
要应用的聚合函数 / 映射规则 | - 单个函数:"mean"/max/np.sum- 字典:{"列名": ["函数1", "函数2"]}- 命名元组:新列名=("原列名", "函数") |
axis |
按行 / 列聚合 | 0(按列,默认)/ 1(按行) |
*args/**kwargs |
传给聚合函数的额外参数 | 如 skipna=True 等 |
场景 6:数据排序(sort_values)
python
df.sort_values(
by=["总分", "语文"], # 可选:按总分降序,总分相同按语文降序
ascending=[False, False], # 可选:False=降序,True=升序
na_position="last" # 可选:缺失值放最后/first
)
sort_values数据排序函数:
对 DataFrame 按指定列的值排序,返回新 DataFrame,不修改原数据(这个性质也很重要)。
| 参数 | 含义 | 你这段代码中的效果 |
|---|---|---|
by |
排序依据列,可传单列名或多列名列表() | ["总分", "语文"] → 先按「总分」排序,总分相同再按「语文」排序 |
ascending |
排序方向:True= 升序(小→大),False= 降序(大→小);多列时传列表 |
[False, False] → 总分降序、语文也降序 |
na_position |
缺失值(NaN)的摆放位置:"last"(放最后)/ "first"(放最前) |
"last" → 所有缺失值都排在末尾 |
axis(默认0) |
排序方向:0= 按行排序(最常用),1= 按列排序 |
按行排序,不改变列顺序 |
ignore_index(默认False) |
是否重置行索引为 0,1,2... |
设为True时,排序后行号会重新从 0 开始 |
注意:当形参by采取列表时,需要知道是从左往右,先优先排序左边的,当左边值无法比较大小时,如图中的总分相同时,则依据第二个参数的列来排序。
sort_values,支持的排序数据类型
| 数据类型 | 是否支持排序 | 排序规则 |
|---|---|---|
| int/float(数值) | ✅ 支持 | 按数值大小(1<2<3) |
| str(字符串) | ✅ 支持 | 按 Unicode 编码(如 a<b < 中) |
| datetime(时间) | ✅ 支持 | 按时间先后(2024-01-01 < 2024-01-02) |
| bool(布尔) | ✅ 支持 | False(0)< True(1) |
| 分类列(Categorical) | ✅ 支持 | 按自定义分类顺序(如「低 < 中 < 高」) |
可以说是比较全面了
看了这么多,我们发现了没,我们在excel表格中能实现的功能,通过一些第三方库,也能精确实现这些功能。
2. 2、df.to_excel()(写入 Excel)
python
df.to_excel(
excel_writer="结果.xlsx", # 必填:输出文件路径
sheet_name="筛选结果", # 可选:工作表名,默认Sheet1
index=False, # 可选:是否保留行索引,默认True(必设为False,否则多一列索引)
header=True, # 可选:是否保留列名,默认True
startrow=1, # 可选:从第2行开始写入(留空行给表头样式)
startcol=0, # 可选:从第1列开始写入
na_rep="0", # 可选:缺失值填充为0
engine="openpyxl" # 可选:写入.xlsx用openpyxl,写入.xls用xlwt
)
三、pandas 高频参数速查表(核心总结)
表格
| 函数 / 方法 | 核心参数 | 作用 |
|---|---|---|
read_excel |
sheet_name/usecols/dtype/na_values |
精准读取 Excel,避免加载无关数据 |
to_excel |
index=False/startrow/na_rep |
美化 Excel 输出,避免多余索引列 |
loc/iloc |
行标签 / 列名 / 行号 / 列号 | 精准定位单元格 / 行列 |
dropna |
axis/how/subset |
灵活删除缺失值 |
fillna |
value/method/inplace |
填充缺失值 |
groupby |
by/as_index/agg |
分组聚合计算 |
sort_values |
by/ascending/na_position |
多列排序,控制缺失值位置 |
四、关键避坑点
inplace=True:设置为 True 会直接修改原 DataFrame,False 返回新 DataFrame(推荐用 False,避免数据覆盖);- 布尔索引多条件:必须用
&/|,不能用and/or,且每个条件加括号; read_excel的engine:.xlsx 用openpyxl,.xls 用xlrd(需装 xlrd==1.2.0);- 中文编码:读取 CSV 时,中文乱码试
encoding="gbk",写入用encoding="utf-8-sig"。
总结
- pandas 核心是
DataFrame表格结构,所有操作围绕「读→洗→算→写」流程; - 高频参数集中在「读取文件(
read_excel)、筛选数据(布尔索引 /loc)、清洗数据(dropna/fillna)、分组计算(groupby)」; - 记住
index=False(写入 Excel 必设)、inplace=False(避免改原数据)、axis(0 = 行 / 1 = 列)三个核心参数,能解决 80% 的问题。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)