
Qwen2.5-VL-7B模型GRPO训练实践指南
在大语言模型训练过程中,强化学习优化是提升模型性能的关键环节。本文记录了基于昇腾Atlas 800T A2设备,使用GRPO算法对Qwen2.5-VL-7B模型进行强化学习训练的全过程。通过详细的配置说明和问题解决方案,为开发者提供一套完整的训练实践指南,帮助快速搭建训练环境并完成模型优化。
作者:昇腾实战派
知识地图链接:强化学习知识地图
背景概述
在大语言模型训练过程中,强化学习优化是提升模型性能的关键环节。本文记录了基于昇腾Atlas 800T A2设备,使用GRPO算法对Qwen2.5-VL-7B模型进行强化学习训练的全过程。通过详细的配置说明和问题解决方案,为开发者提供一套完整的训练实践指南,帮助快速搭建训练环境并完成模型优化。
一、版本信息
硬件平台:Atlas 800T A2
软件版本:
| 工具 | 版本 | 备注 |
|---|---|---|
| python | 3.11 | |
| cann | 8.3.rc1 | |
| hdk | 25.2.0 | |
| torch | 2.7.1 | |
| torch_npu | 2.7.1 | |
| vllm | 0.11.0 | https://github.com/vllm-project/vllm/tree/v0.11.0 |
| vllm-ascend | 0.11.0.rc1 | https://github.com/vllm-project/vllm-ascend/tree/v0.11.0rc1 |
| verl | 0.7.0.dev0 |
二、核心参数
2.1 数据配置
data.train_batch_size=512 \
data.max_prompt_length=1024 \
data.max_response_length=2048 \
2.2 并行配置
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
2.3 节点显卡配置
trainer.n_gpus_per_node=8 \
三、数据集及预处理
使用开源GSM8K数学推理数据集,该数据集包含高质量的数学问题及其推理过程,适合用于强化学习训练。
数据集链接:https://huggingface.co/datasets/openai/gsm8k
数据集预处理:
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k
将数据集预处理为parquet格式,以便包含计算RL奖励所需的必要字段。
四、部署指导
4.1 镜像拉取
参考verl官方仓中,昇腾镜像构建文档
昇腾会发布每日基于dockerfile构建的最新docker,发布链接:https://quay.io/repository/ascend/verl?tab=tags&tag=latest
拉最新的镜像:
docker pull quay.io/ascend/verl:verl-8.3.rc1-910b-ubuntu22.04-py3.11-latest
4.2 容器启动
新建start_docker.sh,执行sh start_docker.sh启动容器
#!/bin/b
# 容器名称
CONTAINER_NAME="verl-qwen25VL"
# 镜像名称(需替换为实际使用的镜像名+标签,如 mindspeed-llm:v1.0)
IMAGE_NAME="quay.io/ascend/verl:verl-8.3.rc1-910b-ubuntu22.04-py3.11-latest"
WORK_VOLUME="/data02/weights:/models/"
WORK_VOLUME2="/home/l00919516:/workspace/"
echo -e "\033[32m[操作] 开始启动容器 $CONTAINER_NAME,使用镜像 $IMAGE_NAME...\033[0m"
docker run -dit \
--ipc=host \
--network host \
--name "$CONTAINER_NAME" \
--privileged \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /etc/localtime:/etc/localtime \
-v "$WORK_VOLUME" \
-v "$WORK_VOLUME2" \
"$IMAGE_NAME" \
/bin/bash
# ========================== 启动结果校验 ==========================
if [ $? -eq 0 ]; then
echo -e "\033[32m[成功] 容器 $CONTAINER_NAME 启动完成!\033[0m"
echo -e "\033[32m[后续操作] 执行以下命令进入容器:\033[0m"
echo -e " docker exec -it $CONTAINER_NAME bash"
else
echo -e "\033[31m[失败] 容器 $CONTAINER_NAME 启动失败,请检查镜像名称/挂载路径是否正确!\033[0m"
exit 1
fi
- CONTAINTER_NAME:自定义容器名
- IMAGE_NAME: 使用的镜像名称,<仓库地址:tag>
- WORK_VOLUME: 物理机与容器对应的文件路径,<物理机路径: 容器内路径>
启动后执行docker exec -it <container_name> bash进入容器
4.3 启动训练
新建tune_qwen25vl7b_grpo.sh
set -x
ENGINE=${1:-vllm}
# Some models are optimized by vllm ascend. While in some case, e.g. rlhf training,
# the optimized model may not be suitable. In this case, set this value to 0 to disable the optimized model.
export USE_OPTIMIZED_MODEL=0
export VLLM_ASCEND_ENABLE_NZ=0
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=/workspace/verl/gsm8k/train.parquet \
data.val_files=/workspace/verl/gsm8k/test.parquet \
data.train_batch_size=512 \
data.max_prompt_length=1024 \
data.max_response_length=2048 \
data.filter_overlong_prompts=True \
data.truncation='error' \
data.image_key=images \
actor_rollout_ref.model.path=/models/Qwen2.5-VL-7B-Instruct \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=32 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=2 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.01 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.actor.use_torch_compile=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
actor_rollout_ref.rollout.name=$ENGINE \
+actor_rollout_ref.rollout.engine_kwargs.vllm.disable_mm_preprocessor_cache=True \
actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \
actor_rollout_ref.rollout.enable_chunked_prefill=False \
actor_rollout_ref.rollout.enforce_eager=True \
actor_rollout_ref.rollout.free_cache_engine=True \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger=console \
trainer.project_name='verl_grpo_example_geo3k' \
trainer.experiment_name='qwen2_5_vl_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=-1 \
trainer.total_epochs=15 \
trainer.device=npu $@
执行 sh tune_qwen25vl7b_grpo.sh启动训练
4.4 报错解决
4.4.1 OSError: Not enough disk space
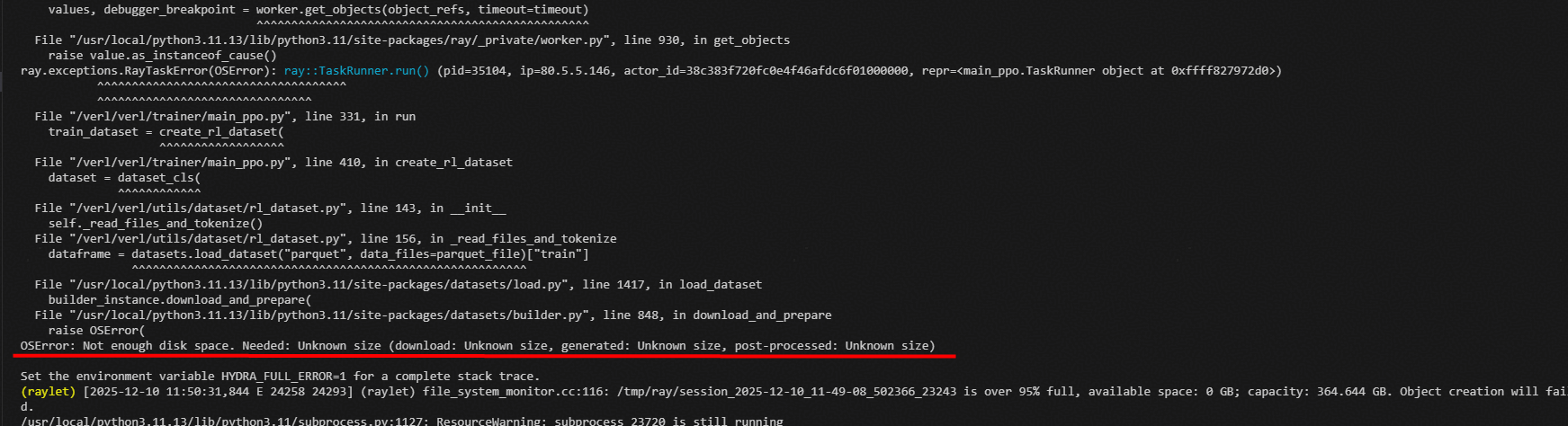
解决:找一块空间充足的盘,在启动脚本前,将ray的存储路径更换至空间充足的盘中
# 1. 创建 Ray/数据集/系统临时目录
mkdir -p /models/ray_tmp /models/ray_spill /models/dataset_cache /models/system_tmp
# 2. 设置 Ray 相关环境变量:指向 /models 下的目录
export RAY_TMPDIR=/models/ray_tmp # Ray 临时文件目录
export RAY_DISK_SPILLING_DIR=/models/ray_spill # Ray 磁盘溢出目录
export RAY_OBJECT_STORE_ALLOW_SLOW_STORAGE=1 # 允许 /models(非高速磁盘)存储 Ray 对象
export RAY_LOGDIR=/models/ray_logs # Ray 日志目录(可选,避免日志占满根目录)
# 3. 设置数据集缓存目录:指向 /models
export HF_DATASETS_CACHE=/models/dataset_cache # HuggingFace 数据集缓存
export DATASETS_CACHE=/models/dataset_cache # 兼容 datasets 库的不同环境变量
# 4. 设置系统临时目录:替换默认 /tmp(根目录)为 /models
export TMPDIR=/models/system_tmp
export TEMP=/models/system_tmp
export TMP=/models/system_tmp
4.4.2 ValueError: FRACTAL_NZ mode is enabled.
- ValueError: FRACTAL_NZ mode is enabled. This may cause model parameter precision issues in the RL scenarios. Please set VLLM_ASCEND_ENABLE_NZ=0.
解决:sh中添加
export VLLM_ASCEND_ENABLE_NZ=0
五、复现结果
a2单机8卡,13step
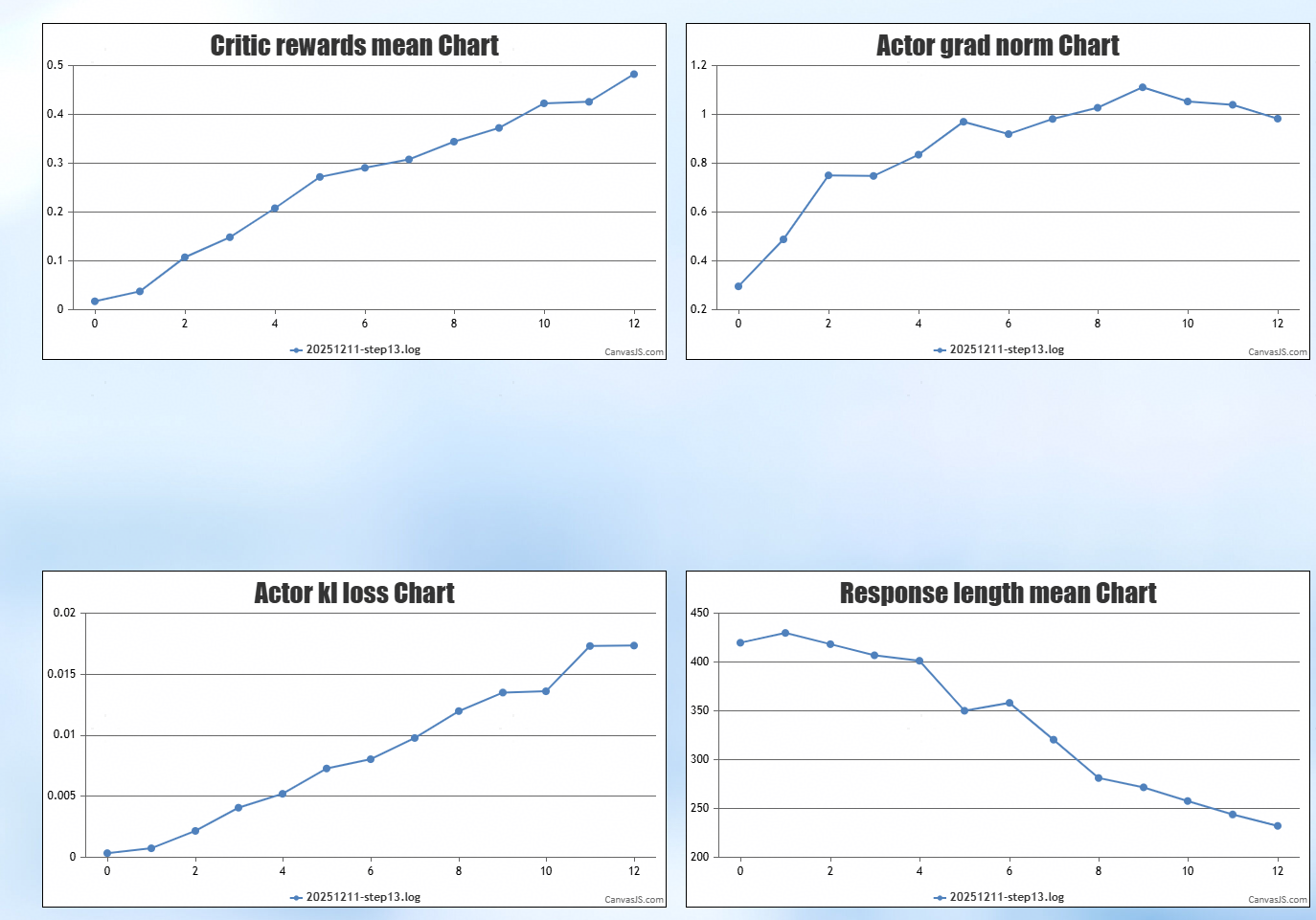
5.1 精度数据
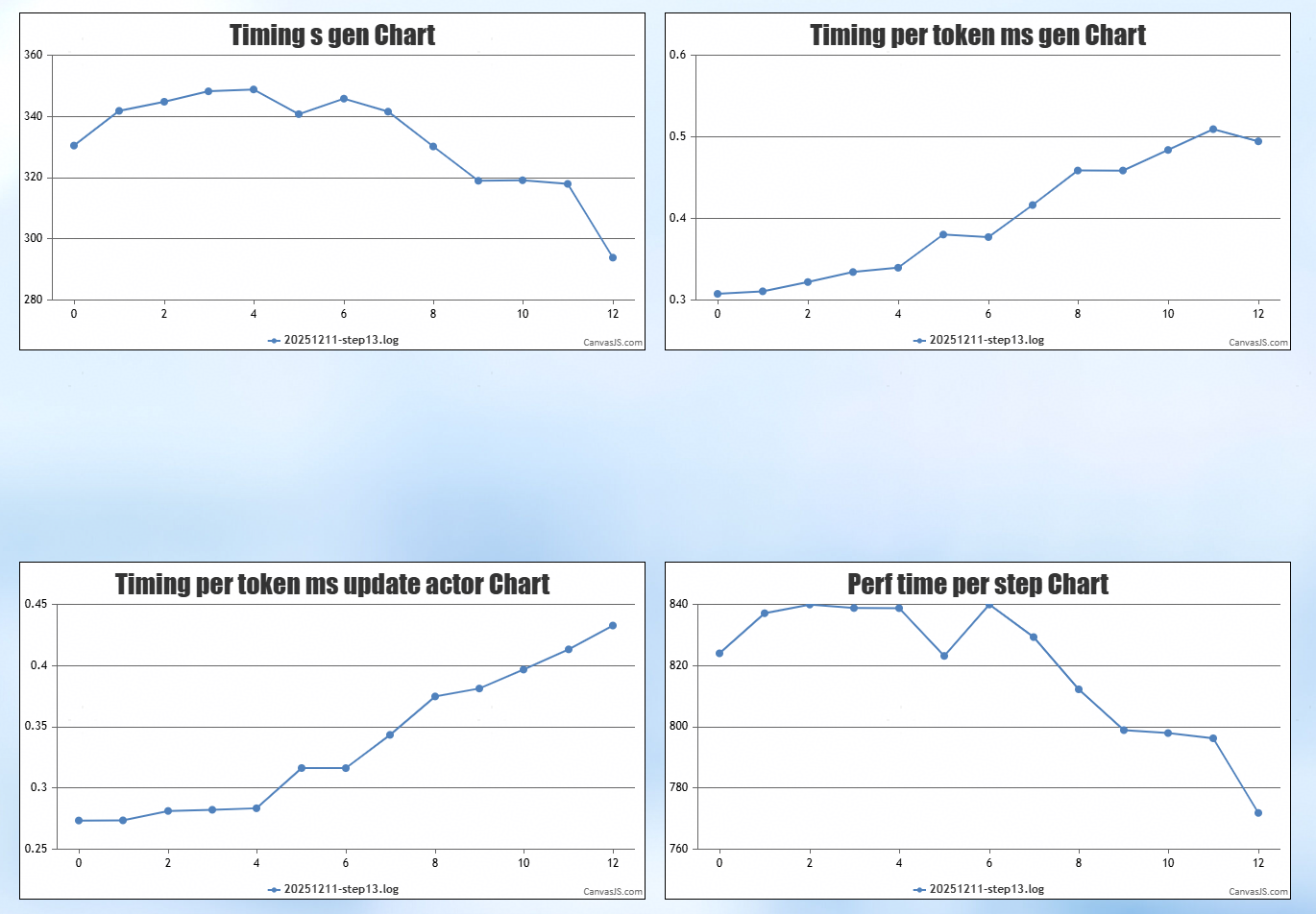
5.2 性能数据

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)