
PD混部服务化调优
1.可以尝试调整prefill阶段的批次;2.可以调整调度策略;3.可以调整客户端的请求并发量和请求频率;由于是基于上面优化基础上,叠加优化,所以要和上面最好的一次性能做比较,即2655.测试性能比默认还要差?分析可能是客户端并发设置太小了(当前设置100)数据解析后生成的内容:(在命令执行路径下的output目录)
文章目录
背景
- 基于MindIE推理引擎,使用昇腾NPU
- 使用PD混合部署方式
- 目标是调测服务化的极致性能
服务化性能调优流程
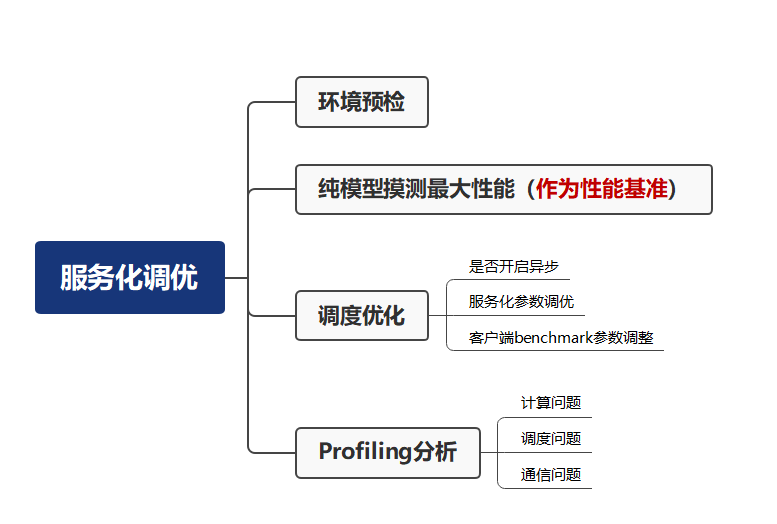
服务化调优实践
性能指标计算逻辑
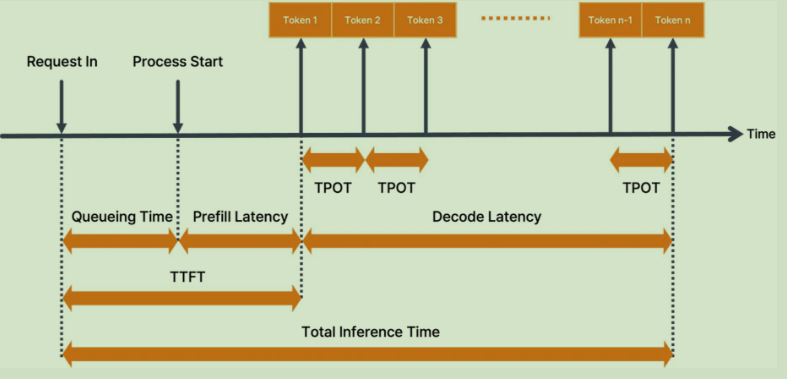
-
纯模型:
non_first_token_throughput = batch_size / non_first_token_time
e2e_throughput = batch_size * seq_len_out / e2e_time -
服务化
OutputGenerateSpeed = round(sum(result.generate_tokens_len) / infer_time, 4)
InputGenerateSpeed = round(sum(result.input_tokens_len) / infer_time, 4)
TotalGenerateSpeed = round(sum(result.input_tokens_len + result.generate_tokens_len) / infer_time, 4)
测试环境/场景
| 驱动、固件 | MindIE | 模型 | 输入/输出 | 数据量 | 场景 | 服务器 |
|---|---|---|---|---|---|---|
| 25.0.rc1 | 2.1.RC1 | Qwen2.5-7B-Instruct | 256/256 | 500条 | 单卡最大吞吐 | 800I A2(32GB) |
benchmark测试数据脚本synthetic_config.json:
{
"Input":{
"Method": "uniform",
"Params": {"MinValue": 256, "MaxValue": 256}
},
"Output": {
"Method": "gaussian",
"Params": {"Mean": 100, "Var": 200, "MinValue": 256, "MaxValue": 256}
},
"RequestCount": 500
}
前置准备
- 服务化正常部署,参考MindIE文本生成推理快速入门
# 初始化环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh
export MINDIE_LOG_TO_STDOUT=1
# 拉起服务
/usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
- 基于初始环境、默认服务化配置,跑个基本性能
执行命令如下:
benchmark \
--DatasetType "synthetic" \
--ModelName qwen \
--ModelPath "/models/Qwen2.5-7B-Instruct/" \
--TestType vllm_client \
--Http http://127.0.0.1:1025 \
--ManagementHttp http://127.0.0.2:1026 \
--Concurrency 100 \
--MaxOutputLen 256 \
--TaskKind stream \
--Tokenizer True \
--SyntheticConfigPath ./synthetic_config.json
环境预检
msprechecker工具使用
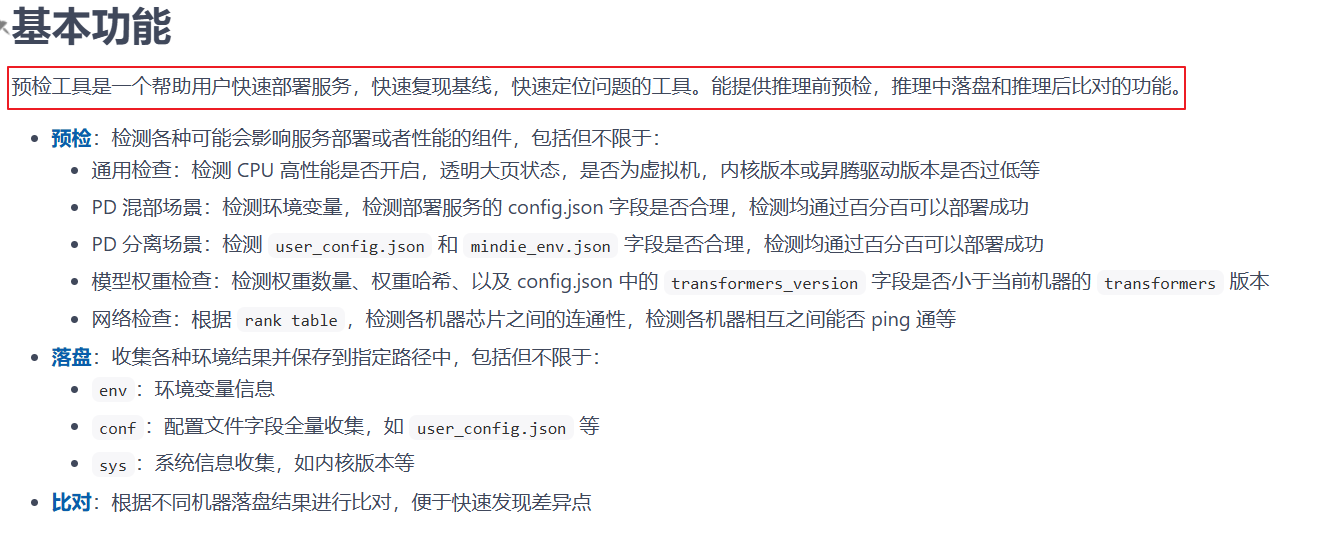
执行预检:
pip install msprechecker
# 默认进行环境变量、系统配置的校验
msprechecker precheck
环境变量说明
基线变量:
# 先使能各组件的默认环境变量
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh
# atb-models环境变量
export ATB_LLM_HCCL_ENABLE=1
export ATB_WORKSPACE_MEM_ALLOC_ALG_TYPE=3
export ATB_LAYER_INTERNAL_TENSOR_REUSE=1
export ATB_OPERATION_EXECUTE_ASYNC=1 # 默认开启
export ATB_CONVERT_NCHW_TO_ND=1
export ATB_WORKSPACE_MEM_ALLOC_GLOBAL=1
export ATB_CONTEXT_WORKSPACE_SIZE=0
export ATB_LAUNCH_KERNEL_WITH_TILING=1
export ATB_LLM_ENABLE_AUTO_TRANSPOSE=0
# CANN
unset ASCEND_LAUNCH_BLOCKING
export HCCL_DETERMINISTIC=false
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_CONNECT_TIMEOUT=7200
export HCCL_EXEC_TIMEOUT=0
export HCCL_RDMA_PCIE_DIRECT_POST_NOSTRICT=TRUE
# Ascend Extension for Pytorch
export INF_NAN_MODE_ENABLE=1
export TASK_QUEUE_ENABLE=2
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
# MindIE Service
# 异步发射,几乎所有情况下推荐开启
export MINDIE_ASYNC_SCHEDULING_ENABLE=1
非基线变量:
# host侧性能相关
export OMP_NUM_THREADS=10: 建议设置8-16之间的值,利用Numpy的OpenMP多线程能力,加速host侧前后处理
# 内存相关
export=NPU_MEMORY_FRACTION=0.96: 0-1之间,推荐0.96/0.97,比例越高吞吐越高,遇到oom报错或服务化无响应卡死调小至0.9左右
# 通信相关
export HCCL_BUFFSIZE=1024:一般使用默认推荐值即可,多机配置需相同,通信数据量大的场景下可适当调大,如通信域占用显存过多出现显存瓶颈可适当调小
# 日志相关(关闭所有日志,开箱不建议这么使用)
for var in $(compgen -e | grep 'STDOUT$'); do
export "$var=0"
done
for var in $(compgen -e | grep 'LOG_TO_FILE$'); do
export "$var=0"
done
# 系统和硬件相关
# CPU高性能模式:可使用cpupower frequency-set -g performance设置,cpupower freqeuncy-info查询
# 大页内存:通过cat /sys/kernel/mm/transparent\_hugepage/enabled检查
# 绑核:CPU瓶颈时,建议使用将mindie绑核至奇数NUMA节点,避免服务化框架和算子下发等host侧任务竞争CPU资源
lscpu # 查看CPU规格
# 168-191要根据实际情况修改
taskset -c 168-191 ./bin/mindieservice_daemon
服务化性能测试
- 尝试1:
export MINDIE_ASYNC_SCHEDULING_ENABLE=1
export OMP_NUM_THREADS=10
# 跑benchmark测试:
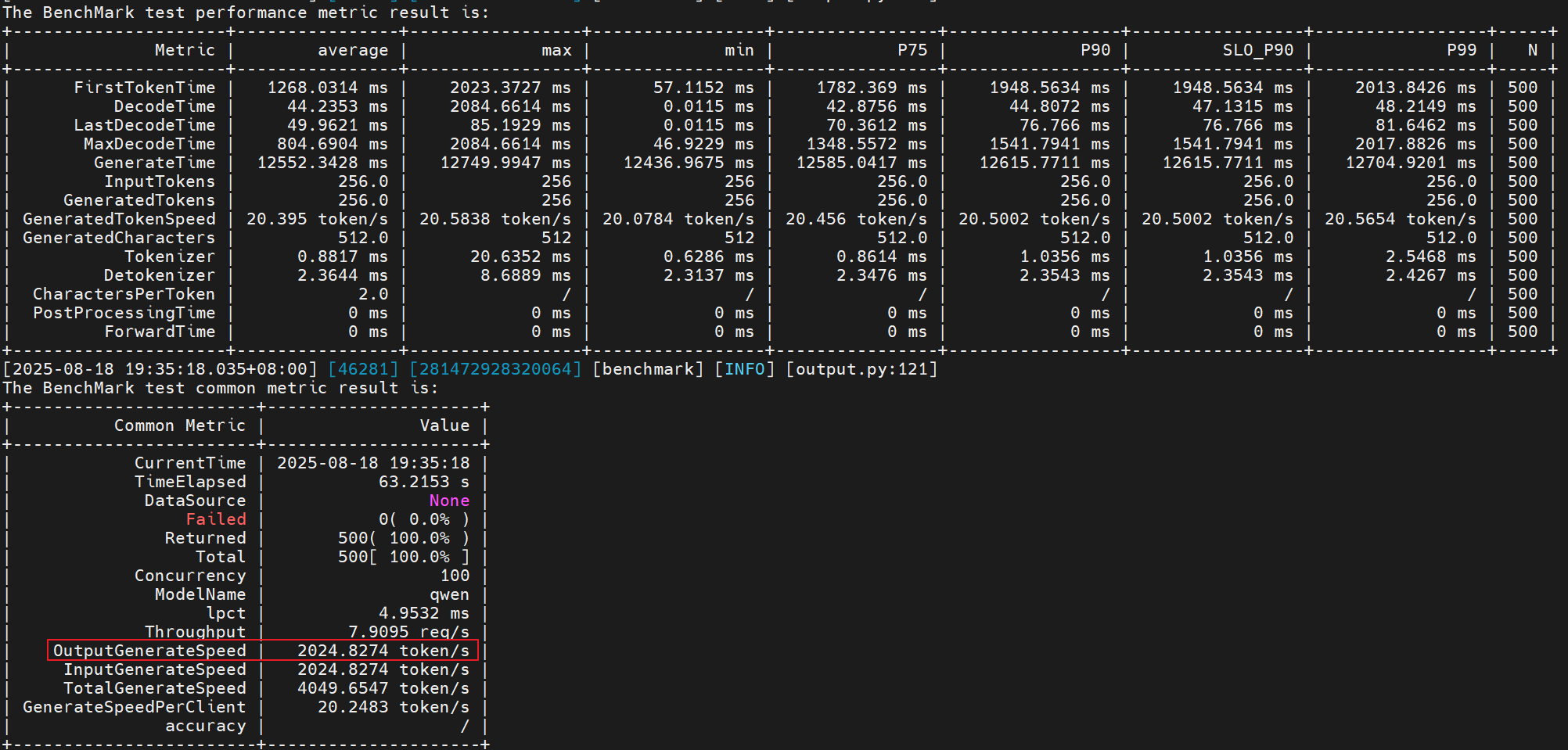
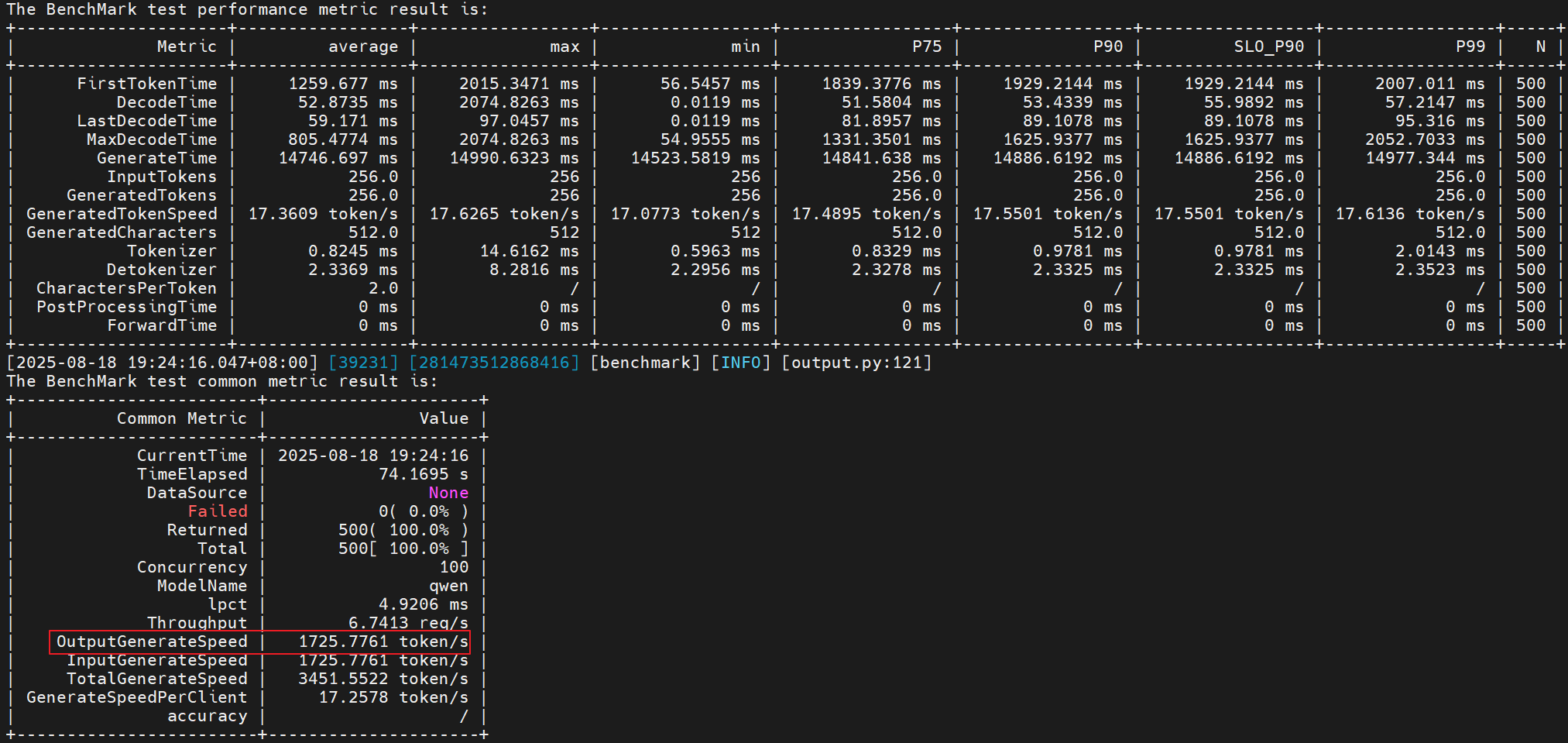
性能提升:(2024 - 1725) / 1725 = 17.33%
- 尝试2:基于尝试1的基础上,增加奇节点绑核
lscpu
taskset -c 32-63 /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
# 跑benchmark测试:
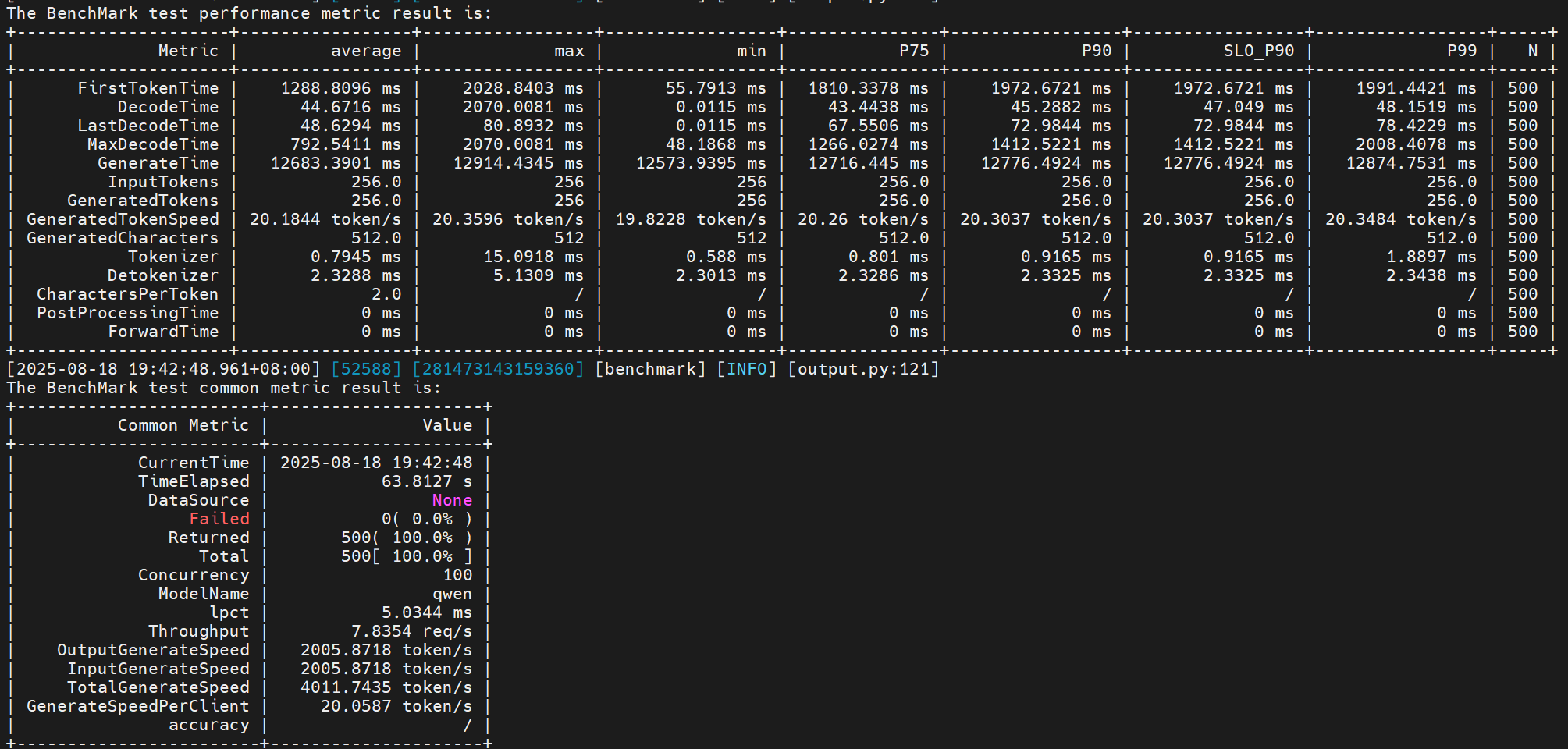
性能提升:(2005 - 1725) / 1725 = 16.23%
可以看到绑核反而让性能变差了,所以绑核不是必须的,要依具体场景而设置,后续有相关案例会补充。
摸测纯模型最大吞吐&最大batchsize(可选)
## 单机场景
bash run.sh pa_[data_type] performance_maxbs [case_pair] [batch_range] [time_limit] [model_name] ([is_chat_model]) [weight_dir] ([trust_remote_code]) [chip_num] ([max_position_embedding/max_sequence_length])
说明:
1. case_pair接收一组或多组输入,格式为[[seq_in_1,seq_out_1],...,[seq_in_n,seq_out_n]], 中间不接受空格,如[[256,256],[512,512]]
2. batch_range接收一组或多组输入,数量与case_pair的组数一致,表达对应的case_pair会在给定的batch_range中寻找摸测满足time_limit的最大batch_size.
格式为[[lb1,rb1],...,[lbn,rbn]],其中区间均为闭区间。如[[1,1000],[200,300]]
3. time_limit:摸测最大bs时的非首token时延最大值。
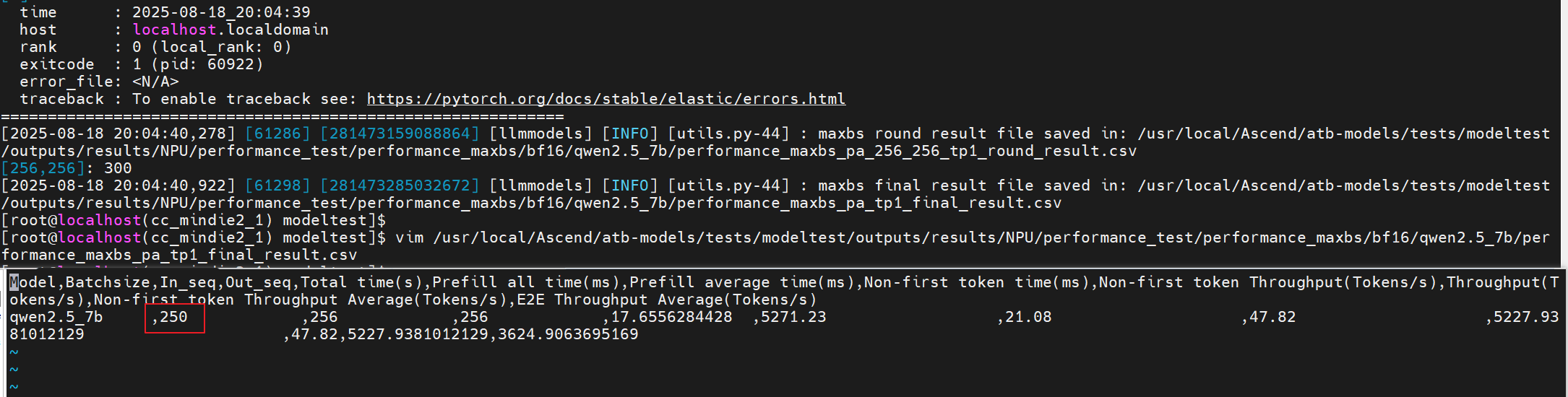
4. 结果保存: [...]/tests/modeltest/result/模型名/ 下,
1. 以"_round_result.csv"结尾的文件内保存了过程数据
2. 以"_final_result.csv"结尾的文件内保存了最终数据, 会呈现在控制台末尾
# 如何计算batch_range:待补充??
# 样例
cd /usr/local/Ascend/atb-models/tests/modeltest
bash run.sh pa_bf16 performance_maxbs [[256,256]] [[200,300]] 1000 qwen /models/Qwen2.5-7B-Instruct/ 1
# 如设置batchsize过大,需要调整batch_range
使用服务化专家建议工具
msserviceprofiler工具使用
执行命令:
# 工具安装
pip install -U msserviceprofiler
# 指定输入输出的 token 长度 `-in, --input_token_num` 以及 `-out, --output_token_num`
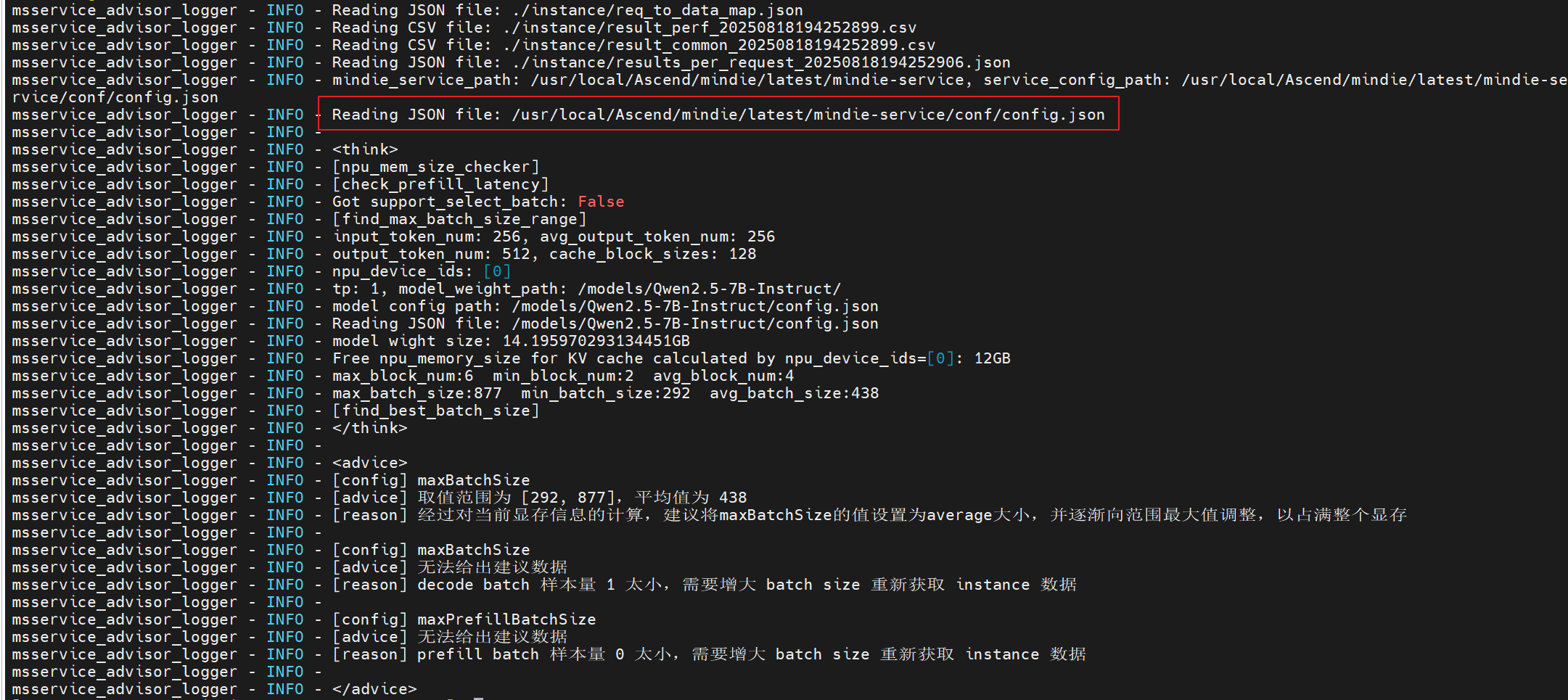
msserviceprofiler advisor -in 256 -out 256
# 或提供 `instance` 文件夹
msserviceprofiler advisor -i ${path}/instance/
服务化性能测试
- 尝试1:参考建议,把maxBatchSize改为438
测试性能比默认还要差??分析可能是客户端并发设置太小了(当前设置100)
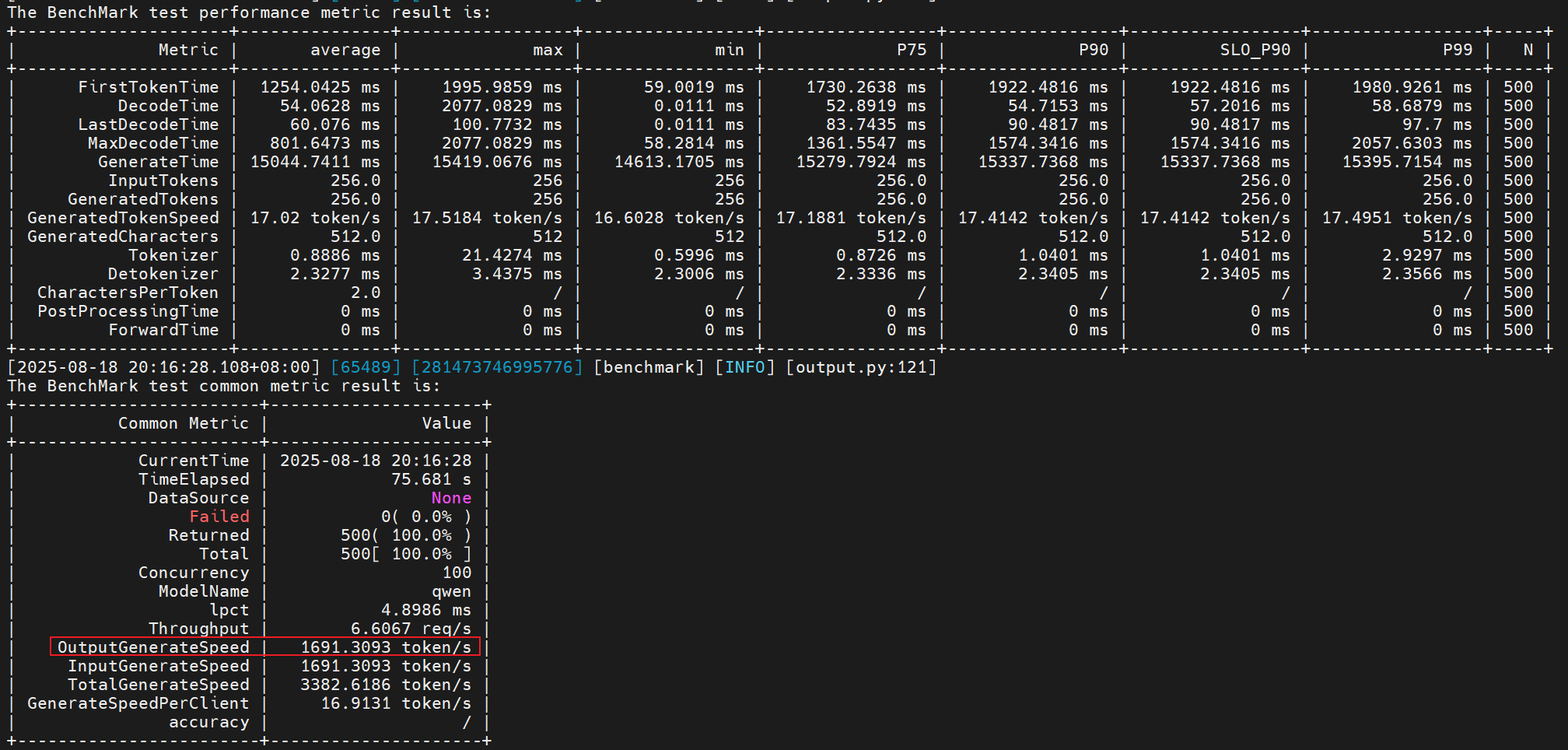
- 尝试2:基于尝试1,增加客户端并发量,由100->250
# benchmark命令
benchmark \
--DatasetType "synthetic" \
--ModelName qwen \
--ModelPath "/models/Qwen2.5-7B-Instruct/" \
--TestType vllm_client \
--Http http://127.0.0.1:1025 \
--ManagementHttp http://127.0.0.2:1026 \
--Concurrency 250 \
--MaxOutputLen 256 \
--TaskKind stream \
--Tokenizer True \
--SyntheticConfigPath ./synthetic_config.json
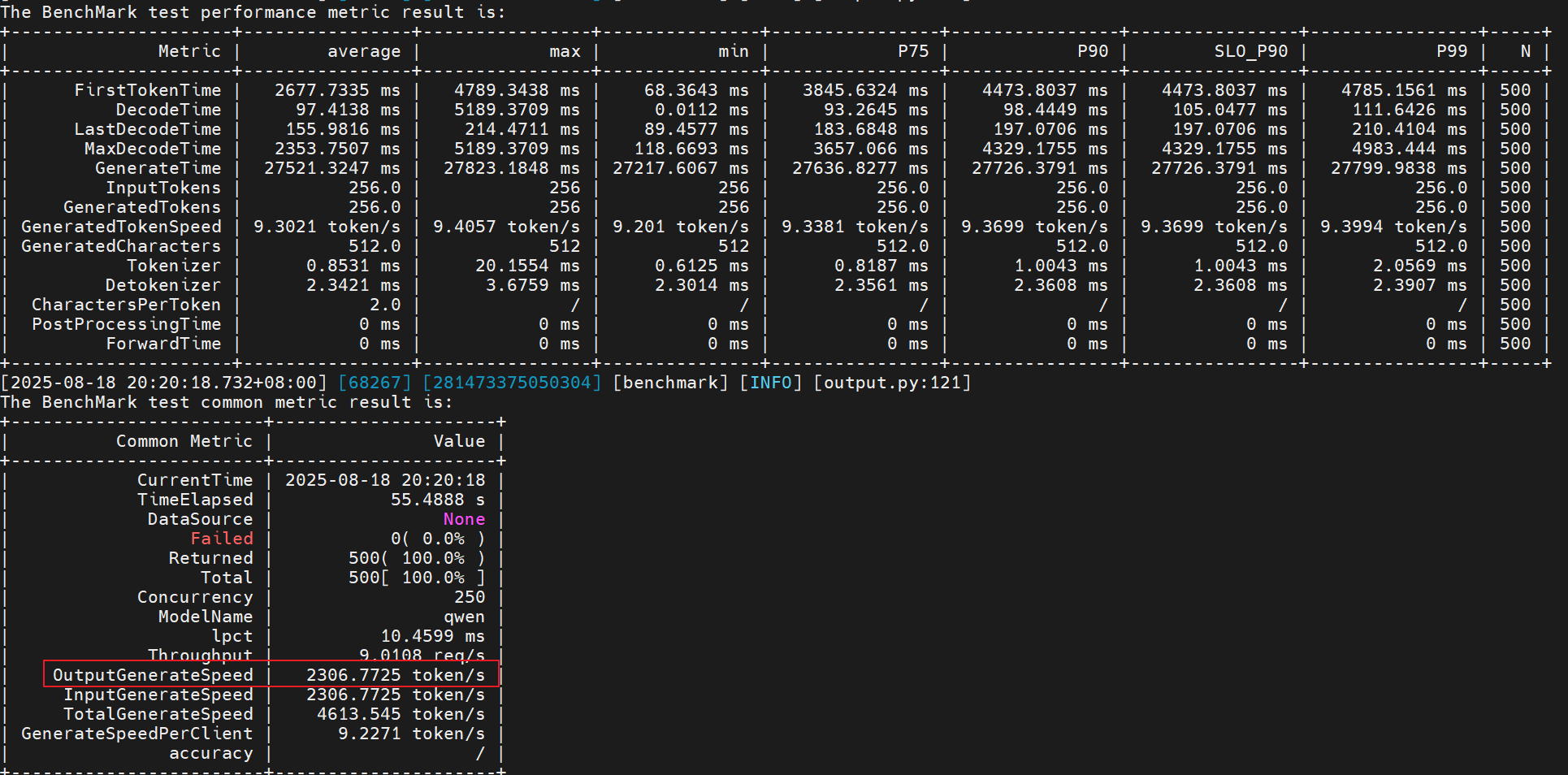
性能提升:(2306 - 1725) / 1725 = 33.68%
- 尝试3:继续增大maxBatchSize和客户端并发量
maxBatchSize: 438->600 #当前测试数据量只有500条,batchsize设置超过500没什么作用。
Concurrency: 250->500
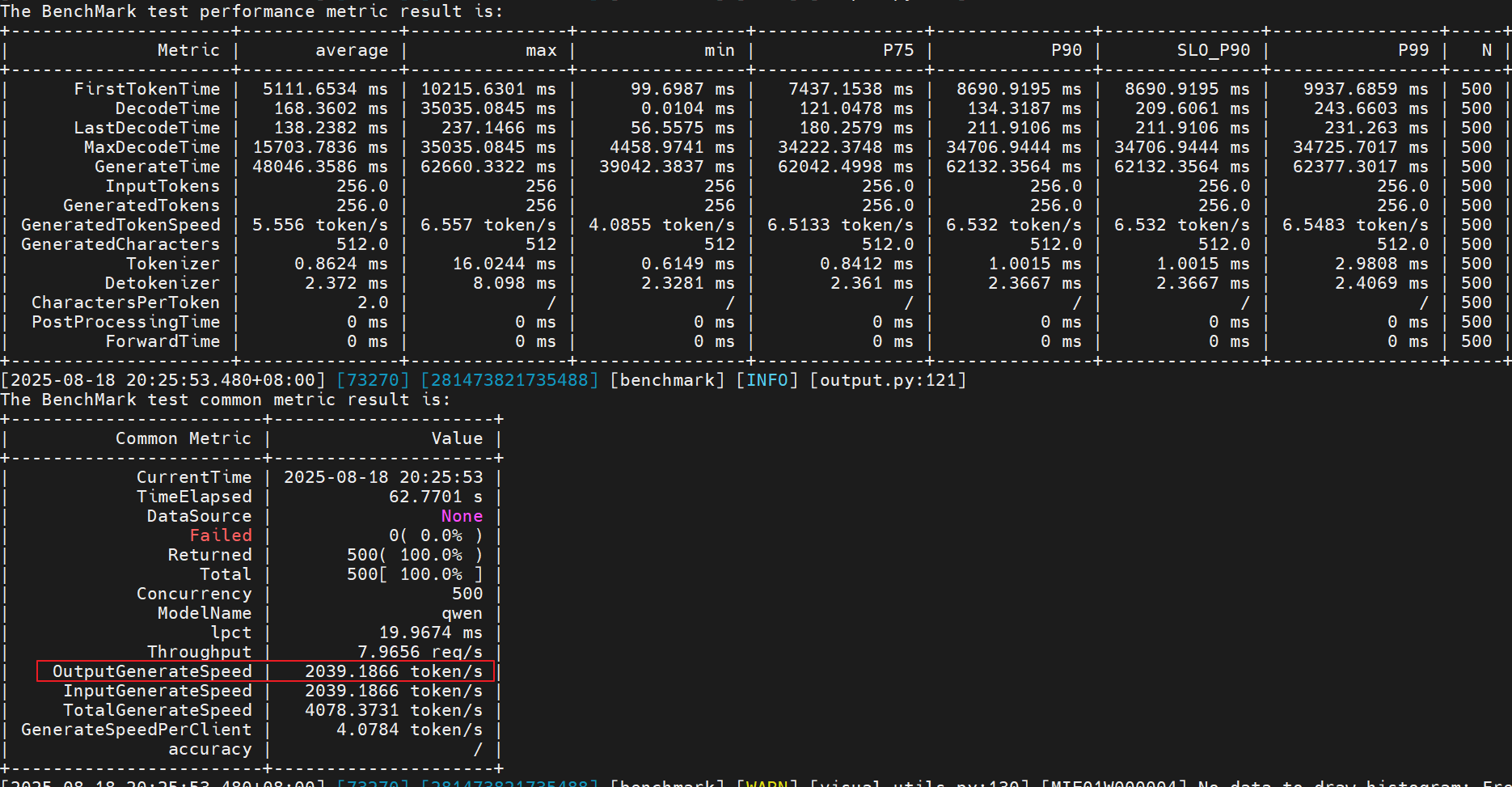
性能提升:(2306 - 1725) / 1725 = 18.20%
- 尝试4:基于尝试3开启异步和多线程处理
export MINDIE_ASYNC_SCHEDULING_ENABLE=1
export OMP_NUM_THREADS=10
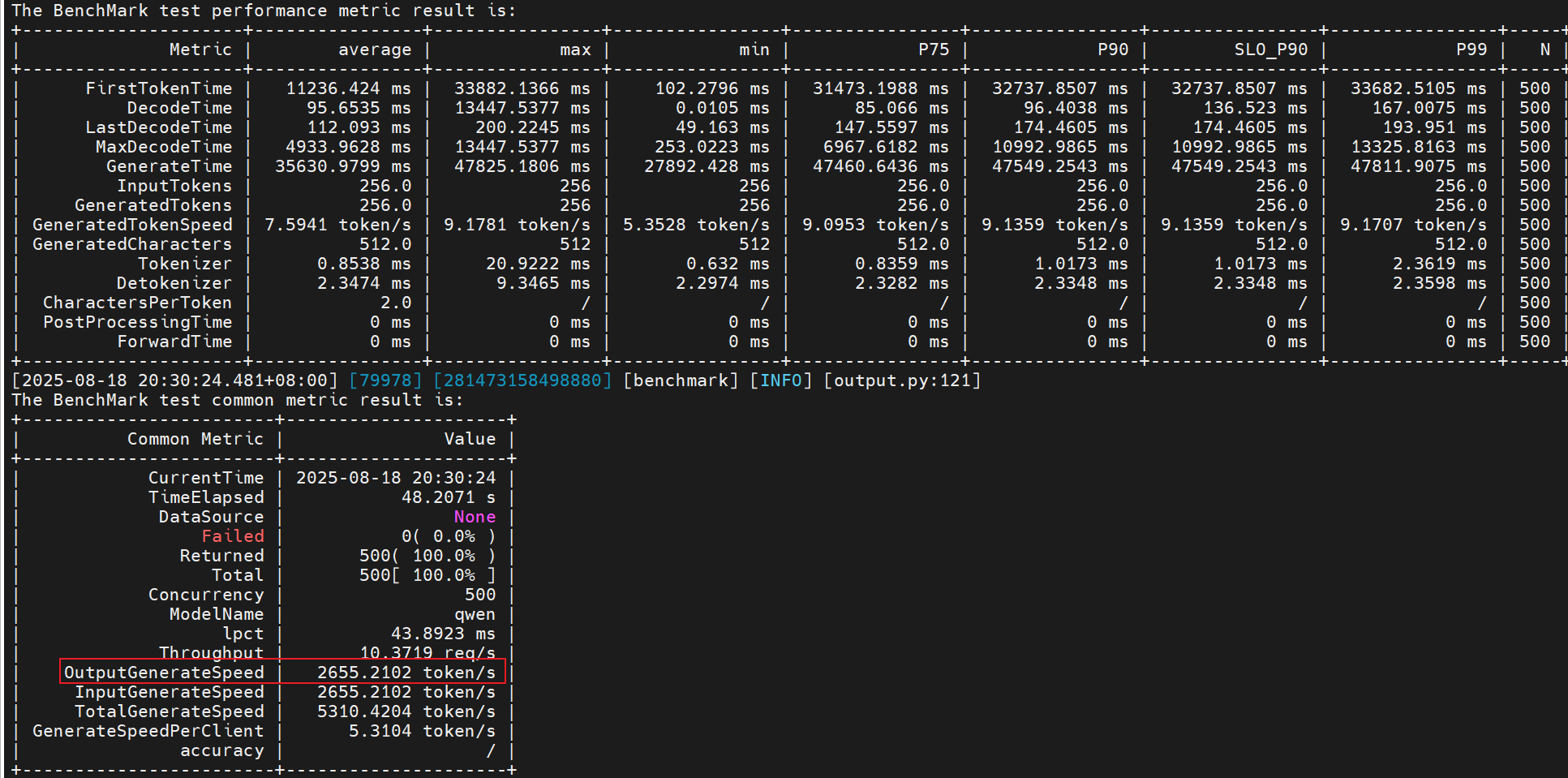
性能提升:(2655 - 1725) / 1725 = 53.91%
-
更多尝试
1.可以尝试调整prefill阶段的批次;2.可以调整调度策略;3.可以调整客户端的请求并发量和请求频率;
以上内容可以参考官方文档指导:服务化性能调优流程 -
总结:纯模型测试性能为3624 TPS,服务化最大为2655 TPS,服务化是纯模型的0.73倍。需要采集服务化性能进一步分析,详见下文。
服务化性能采集&分析
性能采集&解析
# 数据采集
# 1准备采集配置文件ms_service_profiler_config.json
# 参数说明详见上面指导链接
{
"enable": 1,
"prof_dir": "${PATH}",
"profiler_level": "INFO",
"host_system_usage_freq": -1,
"npu_memory_usage_freq": -1,
"acl_task_time": 0,
"acl_prof_task_time_level": "L0",
"timelimit": 0
}
# 2 执行采集(在服务化端session设置)
export SERVICE_PROF_CONFIG_PATH="${PATH}/ms_service_profiler_config.json"
# 拉起服务化,跑性能测试
# 数据解析
python3 -m ms_service_profiler.parse --input-path=${PATH}/prof_dir/
# 数据可视化
性能数据采集如下:
数据解析后生成的内容:(在命令执行路径下的output目录)
性能分析
性能问题可分为三大类:下发(调度)、计算、通信
- 总览图
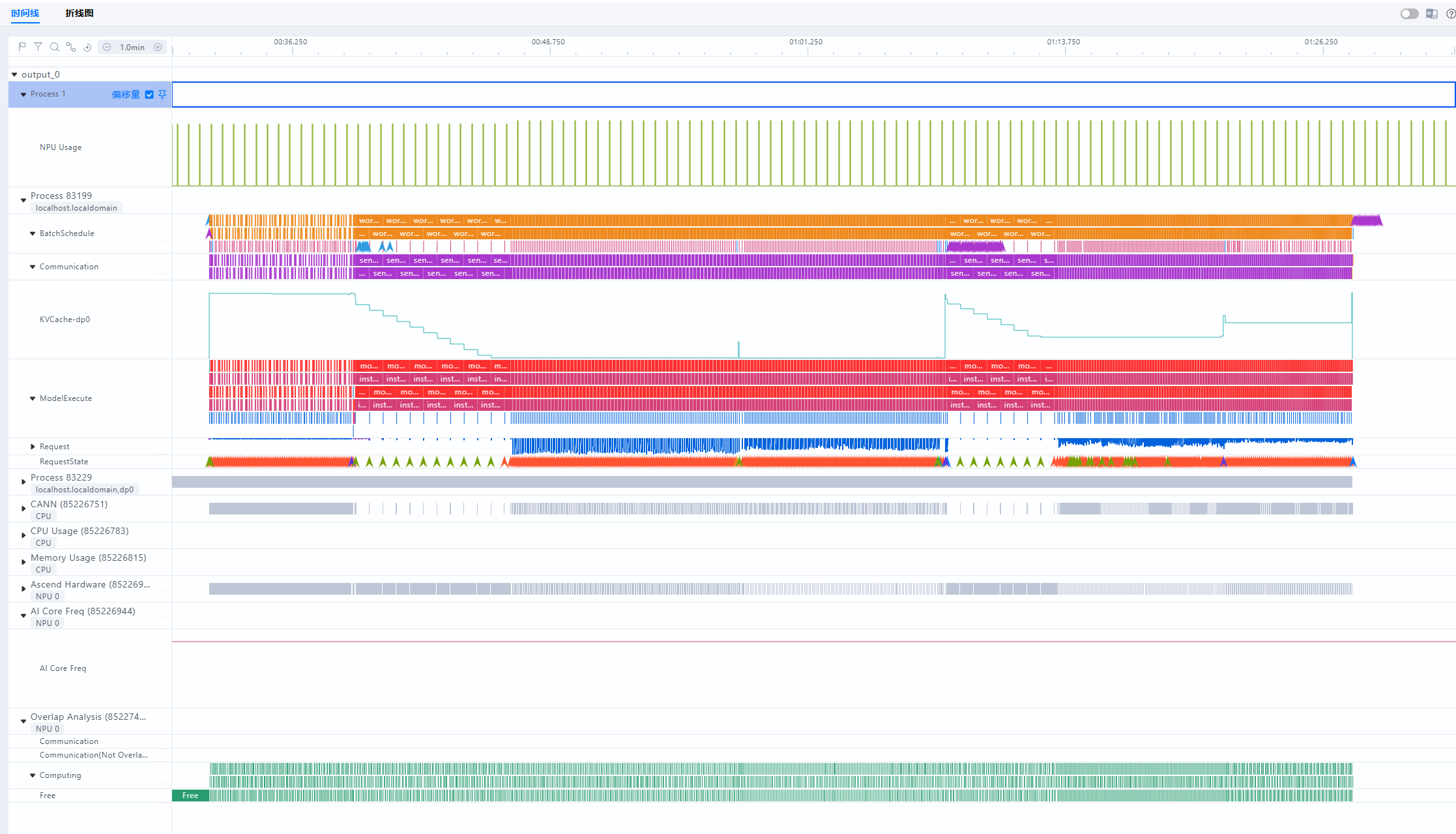
- 问题1:推理过程中,free时间占比为16%,判断host下发存在瓶颈
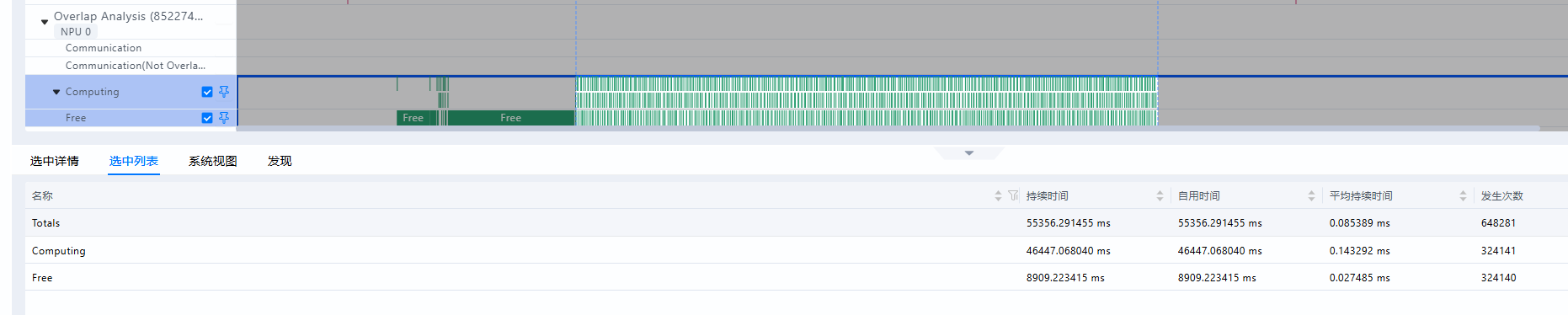
- 问题2:分析batch.csv,发现prefill的batch最大为32,decode batch最大为371
prefill batch被maxPrefillTokens给限制了。
服务化性能测试
- 问题1:一级流水优化
详细说明参考:TASK_QUEUE_ENABLE环境变量解析
# 在服务端设置
# 当前环境TASK_QUEUE_ENABLE=1
export TASK_QUEUE_ENABLE=2
# benchmark测试如下:
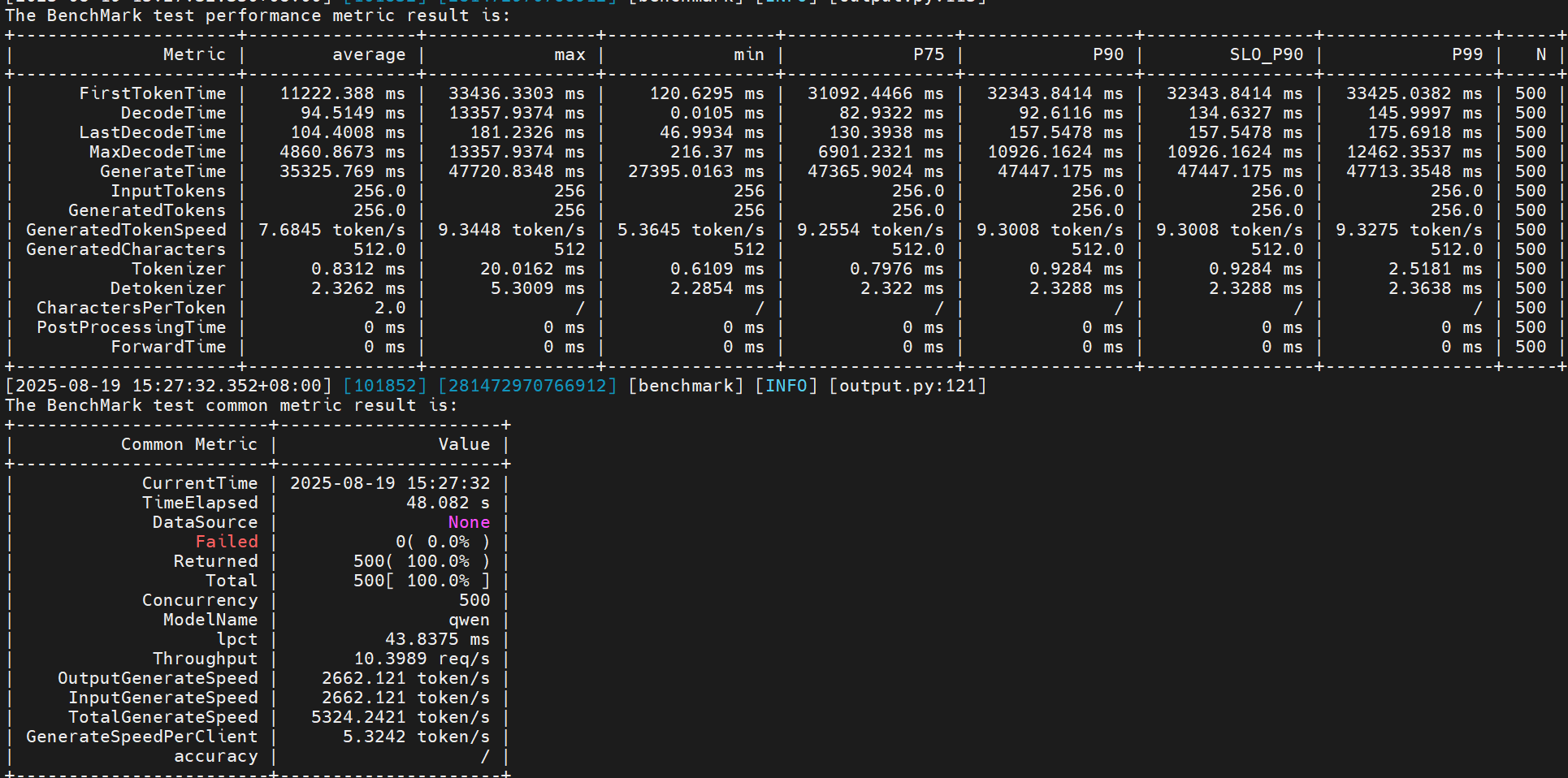
由于是基于上面优化基础上,叠加优化,所以要和上面最好的一次性能做比较,即2655.
性能提升:(2662 - 2655) / 2655 = 0.26%
- 问题2:优化prefill
maxPrefillTokens: 由8192->12800. (输入平均是256, prefill batchsize是50)
叠加上面所有优化,跑benchmark测试:
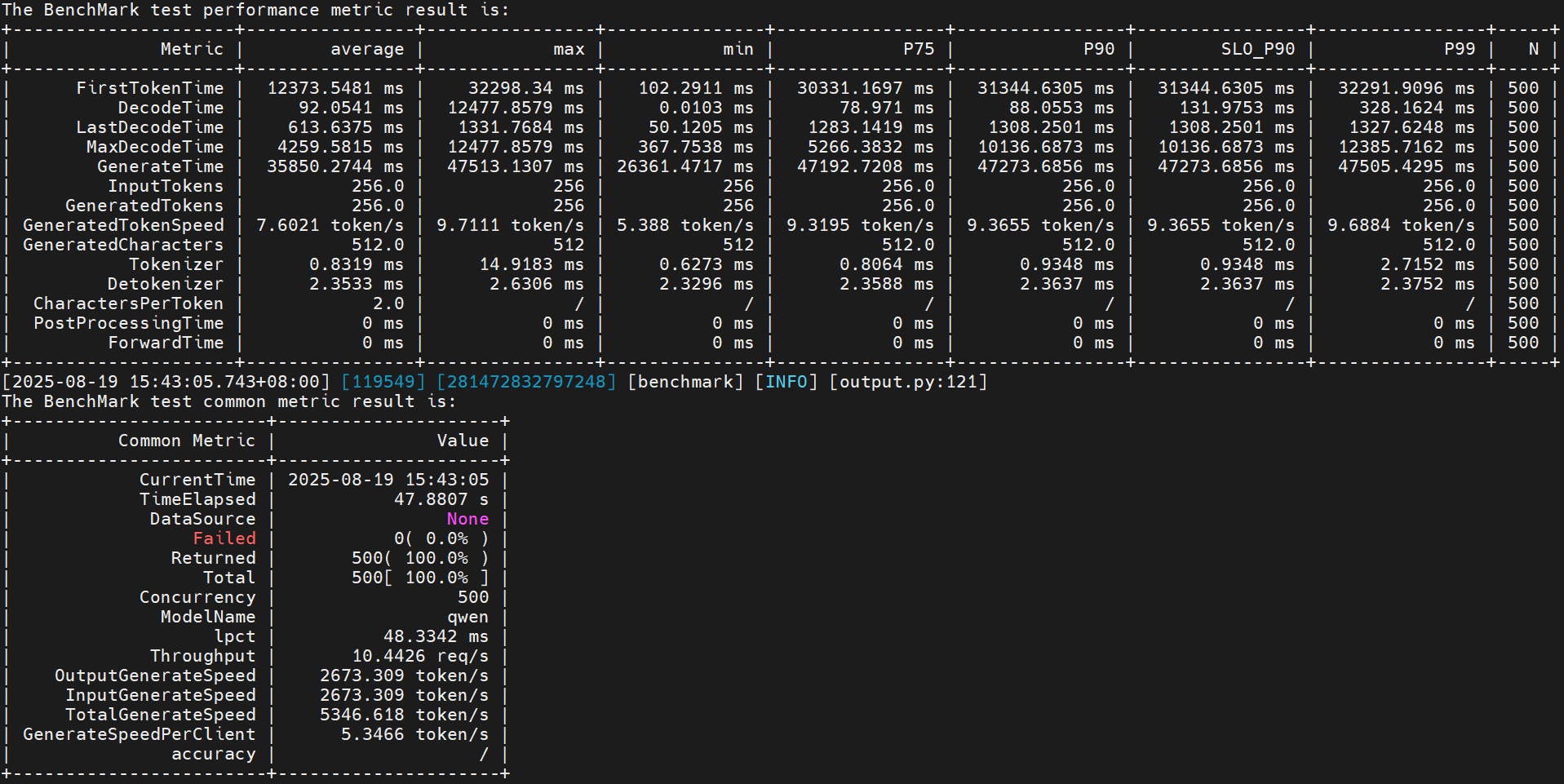
性能提升:(2673 - 2662) / 2662 = 0.41%
- 总结:整体性能调优提升了(2673 - 1725) / 1725 = 55%,服务化是纯模型的0.74倍
自动寻优
整体概述
参考指导:链接
基本功能: 通过服务化自动寻优工具,自动生成服务化参数组合(包括服务化和客户端),尽可能逼近最优解;开发者可以基于推荐的参数组合进行微调,进一步优化。
两种模式:
- 轻量化模式 : 注重精度和可靠性,结合参数验证、参数寻优模块,通过真机实测给出可靠的服务化参数推荐值。
- 仿真模式 : 注重速度及资源占用,调动所有模块快速、精确地预测各组参数的吞吐,在较低NPU资源占用的前提下给出服务化参数推荐值。
快速上手(轻量化模式)
前置条件
用户需要提前确认服务化(如MindIE Service/VLLM Server)、压测工具(如benchmark/vllm_benchmark/aisbench)可以正常运行。这里包括环境变量的设置、服务化配置文件的修改等要先完成。
自动寻优工具的安装
# 如果使用轻量化的方式进行寻优则只需安装最少的依赖即可
git clone https://gitcode.com/Ascend/msit.git
cd msit/msserviceprofiler
pip install -e .[real]
# 仿真模式需安装相关加速包
pip install -e .[speed]
# 如果上述安装失败,可尝试安装较少依赖的三方包,但训练模型时,大数据量时性能较低。
pip install -e .[train]
export PYTHONPATH=$PWD:$PYTHONPATH
配置修改
具体修改内容详见链接
配置文件路径:msit/msserviceprofiler/msserviceprofiler/modelevalstate/config.toml
-
寻优参数:
n_particles (寻优种子数)、iters (迭代轮次数)、 tpot_slo (time_per_output_token的限制时延)等。 用户可根据预估时间来自行配置种子和迭代次数。我们单个种子使用时间为拉起服务+测试数据。比如用户拉起服务+完成测试需9-10min,且愿意用8小时来进行寻优,则一共可跑约50个种子,建议用户配置5 * 10。设置种子数为10,迭代次数为5,建议用户配置种子数为迭代次数的2倍左右。
配置说明:参数 说明 建议值 n_particles 寻优种子数,即一组生成的参数组合数 建议设为 15 ~ 30,范围为1-1000 iters 迭代轮次数 建议设为 5 ~ 10,范围为1-1000 ttft_penalty time_to_first_token 即首token时延超时惩罚系数,若对 time_to_first_token 没有时延要求设置为0即可 按需开启设为1 tpot_penalty time_per_output_token 即非首token时延超时惩罚系数,若对time_per_output_token没有时延要求设置为0即可 按需开启设为1 success_rate_penalty 请求成功率惩罚系数,默认值为5 建议设为5 ttft_slo time_to_first_token的限制时延 单位s,如对time_to_first_token限制为2s内,则设为2 tpot_slo time_per_output_token的限制时延 单位s,如对time_per_output_token限制为50ms内,则设为0.05 service 标注多机启动时为主机或从机 多机场景下从机设为 slave sample_size 对原始数据集采样大小,用采样后的数据进行调优,可增加寻优效率 建议设为原数据集请求的1 / 3, 要求不小于1000 -
测评工具参数(参考上面链接)
-
服务化参数(参考上面链接)
日志配置
export MODELEVALSTATE_LEVEL=INFO
启动寻优
msserviceprofiler optimizer -e mindie -b ais_bench
# 注意,启动寻优命令不需要先拉起服务化,寻优工具会自动拉起。
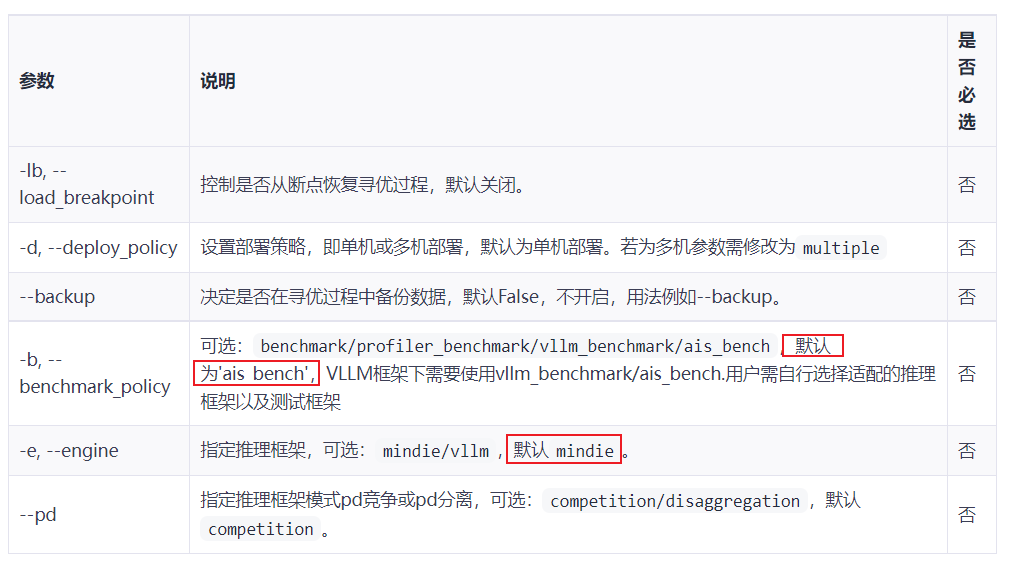
输出结果说明
可以使用export MODEL_EVAL_STATE_CUSTOM_OUTPUT来设置输出路径。 输出件为csv,若不指定输出路径则在modelevalstate/result/store下存放。 输出csv中的每一行对应一组参数,前四列为性能指标。用户可以根据需求筛选满足要求的性能行,将MindIE参数以及benchmark的参数改为csv中的数据即可。
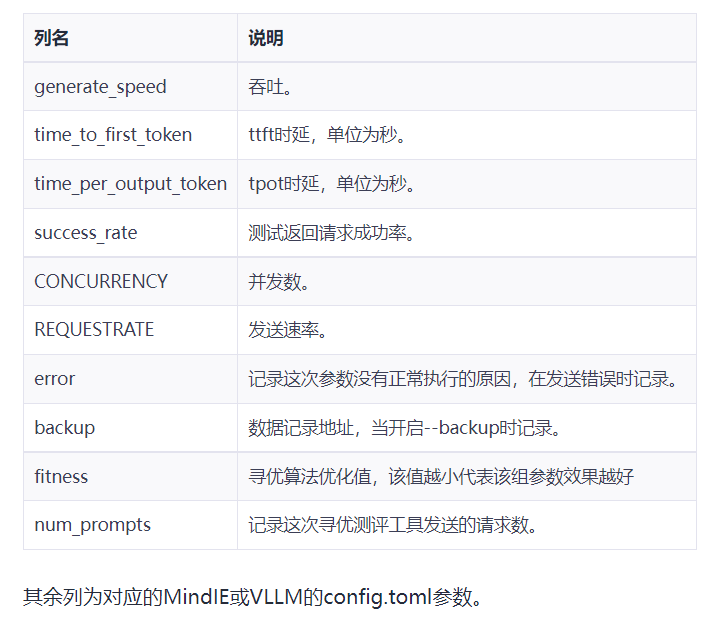
调优案例
自动寻优案例
环境信息:
| 驱动、固件 | MindIE | 模型 | 输出长度 | 数据集 | 场景 | 服务器 |
|---|---|---|---|---|---|---|
| 25.2.0 | 2.1.RC1 | DeepSeek-R1-Distill-Qwen-7B | 512 | gsm8k(1319条) | 单卡最大吞吐 | 800T A2(64GB) |
默认配置吞吐:
# 服务化启动
/usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
# ais_bench执行命令
/usr/local/bin/ais_bench --models vllm_api_stream_chat --datasets gsm8k_gen_0_shot_cot_str_perf --mode perf --num-prompts 1319 --work-dir /root/result/ais_bench --debug
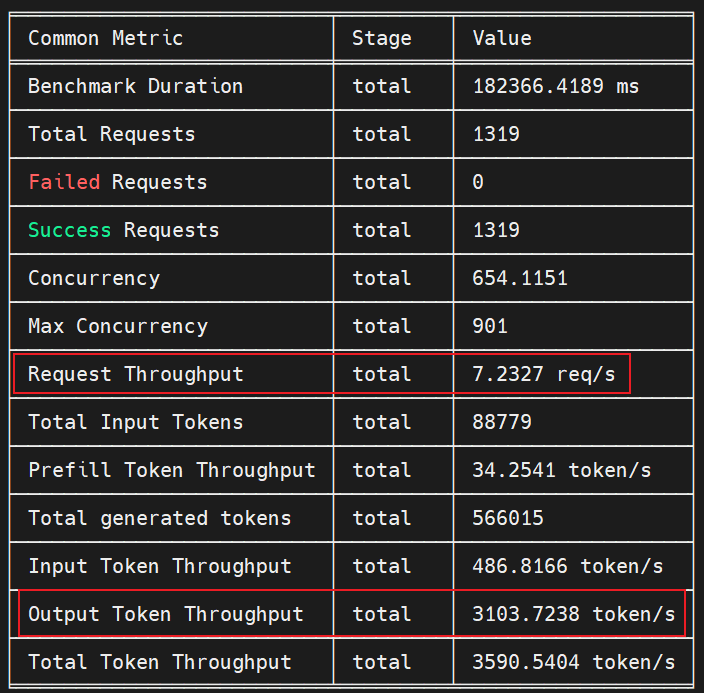
自动寻优生成参数组合及吞吐:
- 前置准备:参考
自动寻优->快速上手完成寻优动作; - 根据自动寻优生成的data_storage_*.csv文件,找到最高吞吐的参数组合,如下(绿色为寻优生成的参数):
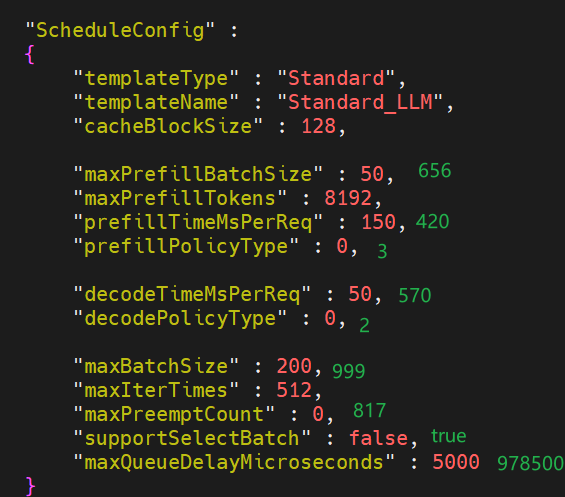
- 基于最优参数,执行测试
# 服务化启动
/usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
# ais_bench执行命令
/usr/local/bin/ais_bench --models vllm_api_stream_chat --datasets gsm8k_gen_0_shot_cot_str_perf --mode perf --num-prompts 1319 --work-dir /root/result/ais_bench --debug
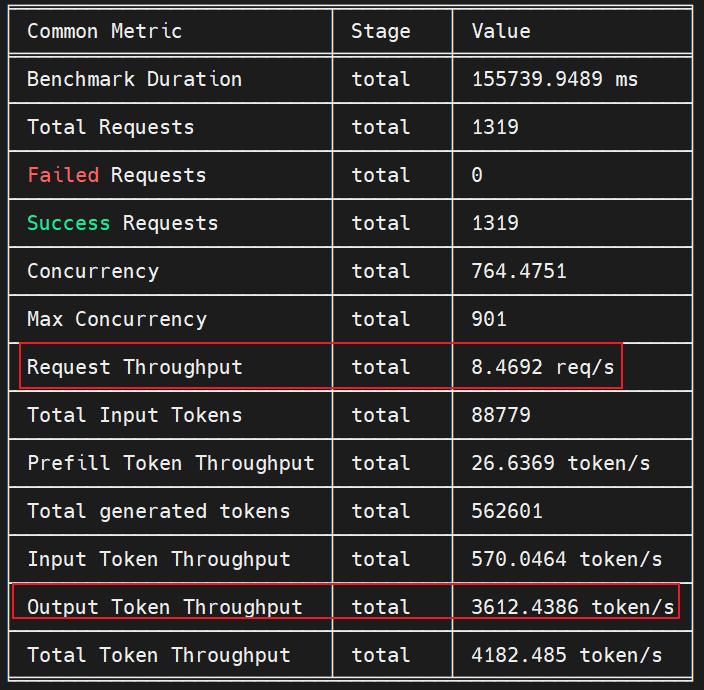
寻优前后性能提升:
整体性能调优提升了(3612 - 3103) / 3103 = 16.4%

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)