
sd3.5基于mindiesd适配
深入浅出完整解析Stable Diffusion(SD)核心基础知识深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识。
文章目录
SD模型结构介绍
- 深入浅出完整解析Stable Diffusion(SD)核心基础知识
- 深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
- 深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
原生脚本迁移到npu(使用torch_npu)
提炼原始模型脚本
方式1: 查看sd3.5在huggingface的实现:
如:https://huggingface.co/stabilityai/stable-diffusion-3.5-large
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-large", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
image = pipe(
"A capybara holding a sign that reads Hello World",
num_inference_steps=28,
guidance_scale=3.5,
).images[0]
image.save("capybara.png")
通过上面官方样例,可以通过diffusers来获取sd3.5的模型实现和流程调用;
方式2:通过github搜索官方代码仓:
如:https://github.com/Stability-AI/sd3.5
视图生成推理流程
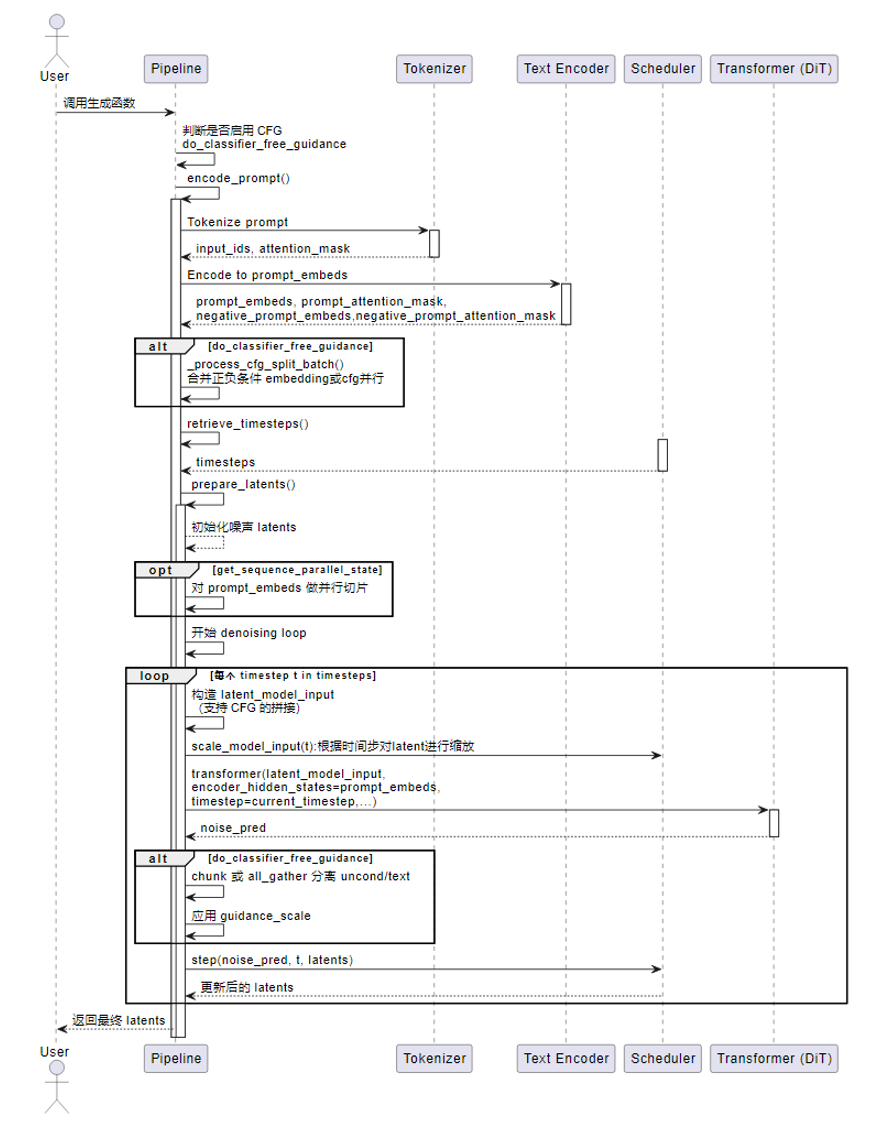
使能原始脚本跑在npu上
-
如上面方式1,diffusers框架原生支持npu,可以直接执行;
-
大部分为方式2,需要做npu适配:
# 在推理脚本添加下面代码
# 无算子缺失问题;或是否可改为可替换算子
# cuda相关API自动转换成npu API
import torch_npu
from torch_npu.contrib import transfer_to_npu
...
# 指定哪张卡执行(可选),不显式指定默认跑在device0上
device_id = 1
torch.npu.set_device(device_id)
MindIE SD使能加速
替换为mindiesd提供的融合算子
主要有RoPE/Norm/Linear/activation/attention_forward融合算子,详情参考:MindIE SD融合算子
以attention_forward为例: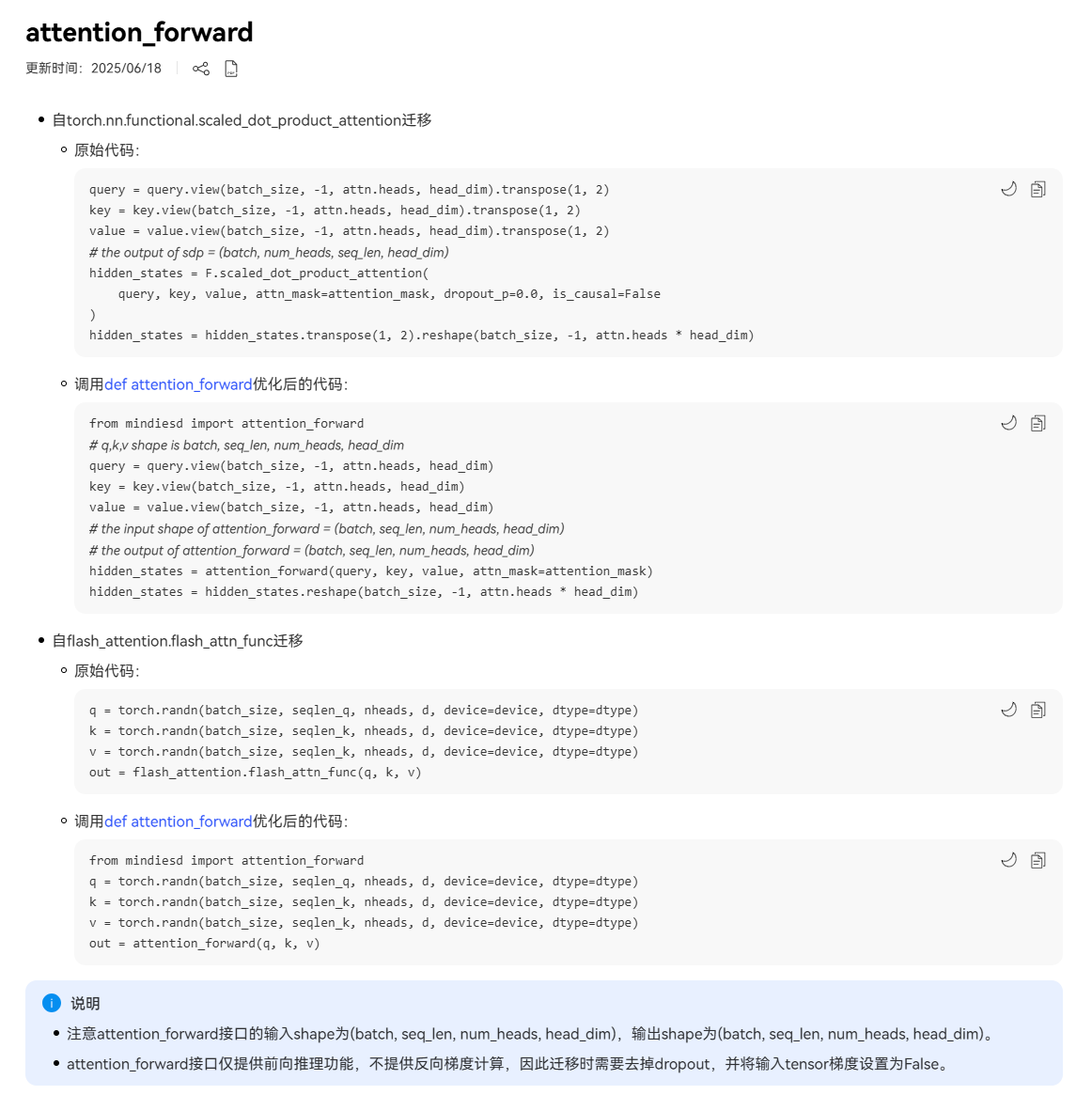
Runtime层Cache算法
AttentionCache/DitCache等,详情参考:MindIE SD cache使能
cache可以通过搜索脚本自动生成最优CacheConfig参数,如step_start/step_interval/step_end/block_start等,搜索脚本需要找MindIE SD开发提供,现在未对外发布。
搜索脚本样例可参考:https://modelers.cn/models/MindIE/hunyuan_video/blob/main/attentioncache_search.py
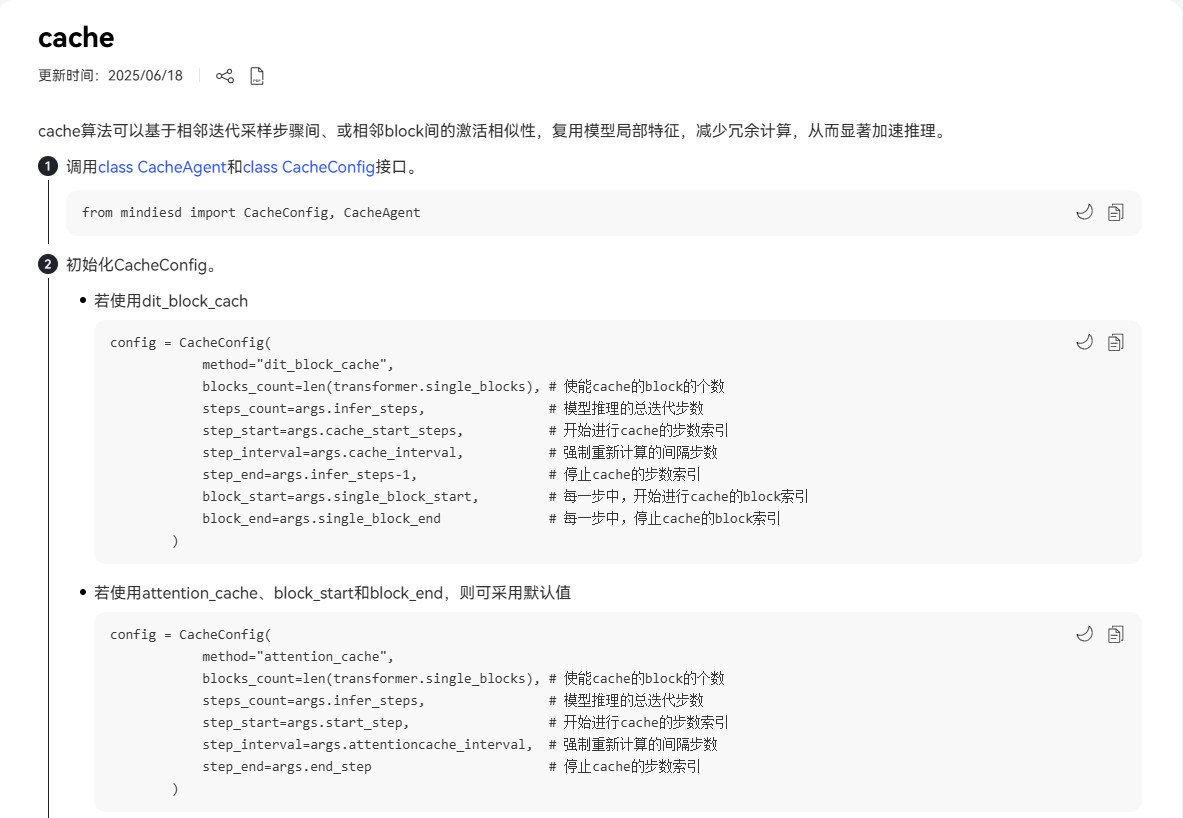
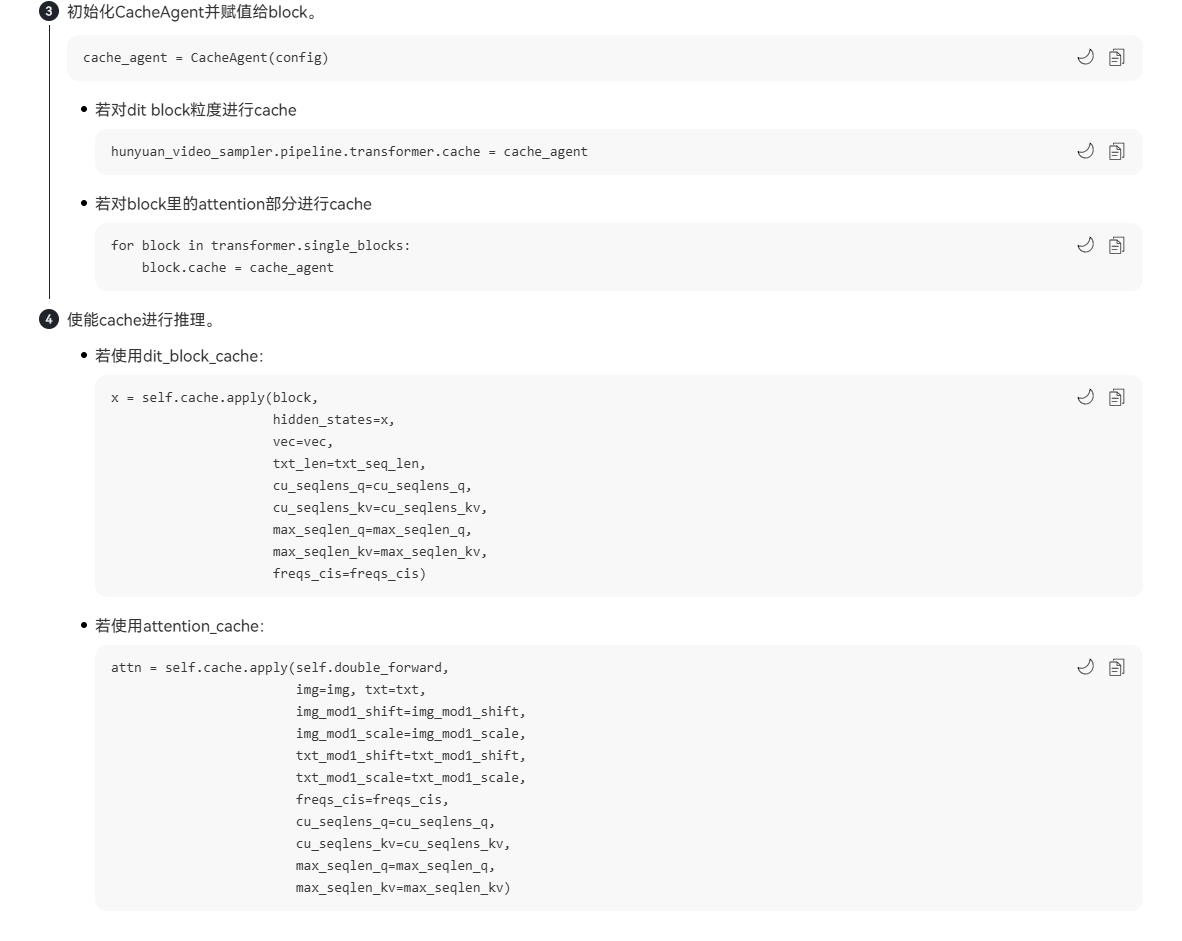
量化
- 权重/激活值量化:
多模型生成模型量化:https://gitee.com/ascend/msit/tree/master/msmodelslim/example/multimodal_sd - MindIE SD量化接口:
# 以sd3.5为例
from mindiesd import quantize
pipe = StableDiffusion3Pipeline.from_pretrained(path, torch_dtype=torch.bfloat16)
# args.quant_path为量化权重的描述文件路径,如:/models/stable-diffusion-3.5-large/quant/safetensors/quant_model_description_w8a8.json
pipe.transformer = quantize(pipe.transformer, args.quant_path)
...
性能分析&优化
性能数据采集
msprof --output=./msprof_out --application="python3 ./sd35_large/inference_sd3.py \
--model /models/stable-diffusion-3.5-large/ \
--prompt_file ./prompts.txt \
--prompt_file_type plain \
--device 1 \
--save_dir ./results_large \
--steps 28 \
--guidance_scale 3.5 \
--batch_size 1 \
--quant_path /models/stable-diffusion-3.5-large/quant/safetensors/quant_model_description_w8a8.json \
--use_quant"

性能分析
- 使用msprof-analyze工具分析性能数据(专家建议)
pip install msprof-analyze
msprof-analyze advisor all -d ./msprof_out/
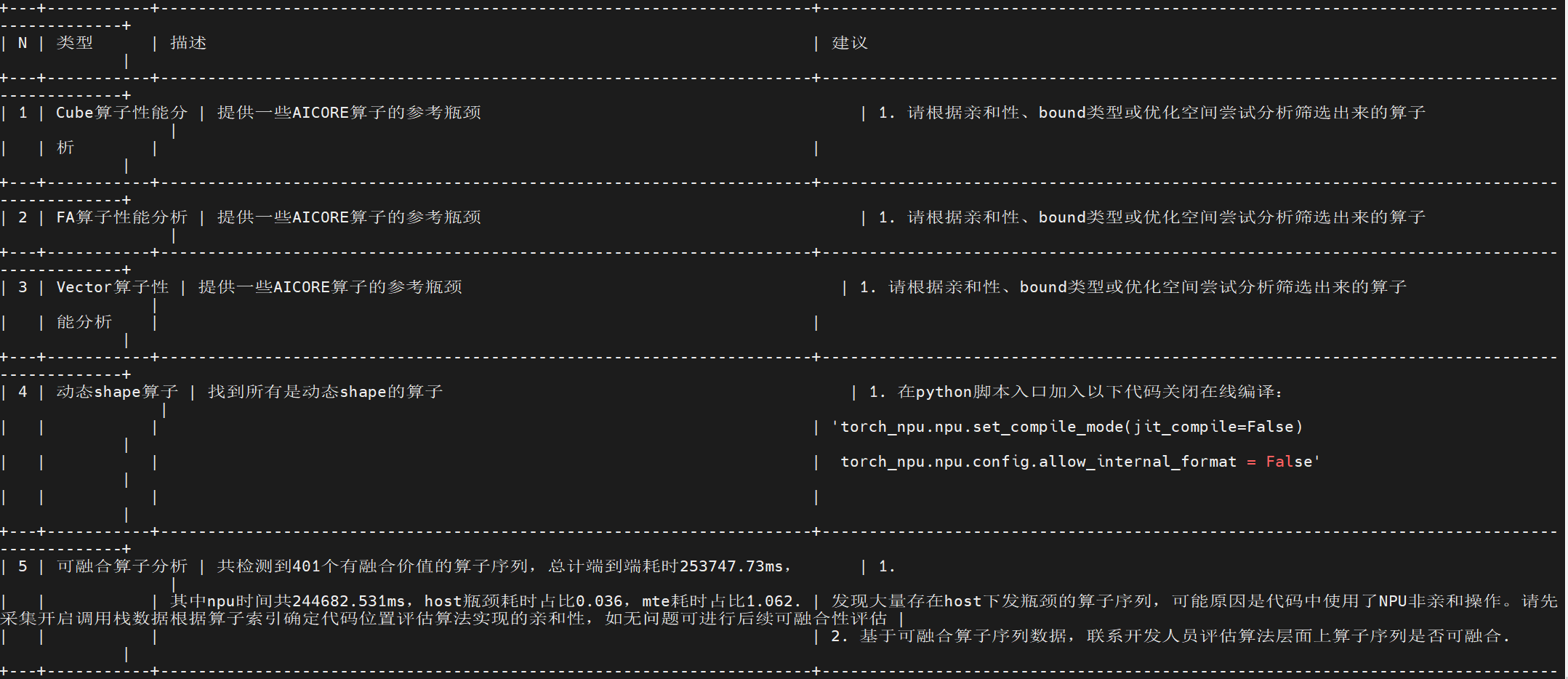
性能优化过程
测试环境:800I A2(910B4) 32GB
参数:steps: 28, prompts: 13, guidance_scale: 3.5
| 优化前 | 接融合算子 | +Cache | +量化 | +关掉在线编译 | +环境变量 | +亲和算子替换 | |
|---|---|---|---|---|---|---|---|
| torch_npu | RMSNorm/FA | DitCache | transformer量化 | torch_npu.npu.set_compile_mode(jit_compile=False) | 绑核等 | 暂无 | |
| 18.350s | 18.337s | 12.122s | 17.981s | 17.924s | / | / |
常见问题
- 使用mindiesd提供的forward_attention函数,环境要安装c++,且配置环境变量CPLUS_INCLUDE_PATH
- 使用DitCache时,cache.apply返回的格式必须是(hidden_states, encoder_hidden_states)
- 使用DitCache要计算step_start/step_end/block_start等参数,需要借助search_tools
- 最新版本mindie 2.1.rc1才支持量化功能;量化能力要看modelslim文档(在msit仓库)

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)