
2025年7月29日CANN通过msopgen创建算子项目
本文介绍了在华为Ascend平台创建自定义加法算子的完整流程。首先配置环境变量并运行初始化脚本,然后创建描述算子输入输出的JSON文件(包含两个float类型输入和一个输出)。通过msopgengen工具生成算子工程框架,重点需要开发op_host和op_kernel目录中的实现文件。文章详细说明了JSON文件中各字段的配置规则,包括输入输出参数的类型、格式要求及其对应关系,并强调了参数配置的注意
测试项目内容A+B返回C。
前置环境
export no_proxy=127.0.0.1,localhost,172.16.*,iam.cn-southwest-2.huaweicloud.com,pip.modelarts.private.com
export NO_PROXY=127.0.0.1,localhost,172.16.*,iam.cn-southwest-2.huaweicloud.com,pip.modelarts.private.com
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/ascendc/init_env.sh
运行脚本-都要运行不能少
chmod 777 init_env.sh
./init_env.sh
source ~/.bashrc
source /home/ma-user/Ascend/ascend-toolkit/set_env.sh
PIP环境必要
pip3 install xlrd==1.2.0
创建add_test.json文件
直接vi编辑就行。
[
{
"op": "Add",
"language": "cpp",
"input_desc": [
{
"name": "x",
"param_type": "required",
"format": ["ND"],
"type": ["float16", "float32"]
},
{
"name": "y",
"param_type": "required",
"format": ["ND"],
"type": ["float16", "float32"]
}
],
"output_desc": [
{
"name": "z",
"param_type": "required",
"format": ["ND"],
"type": ["float16", "float32"]
}
]
}
]编辑完成cat查询一下:
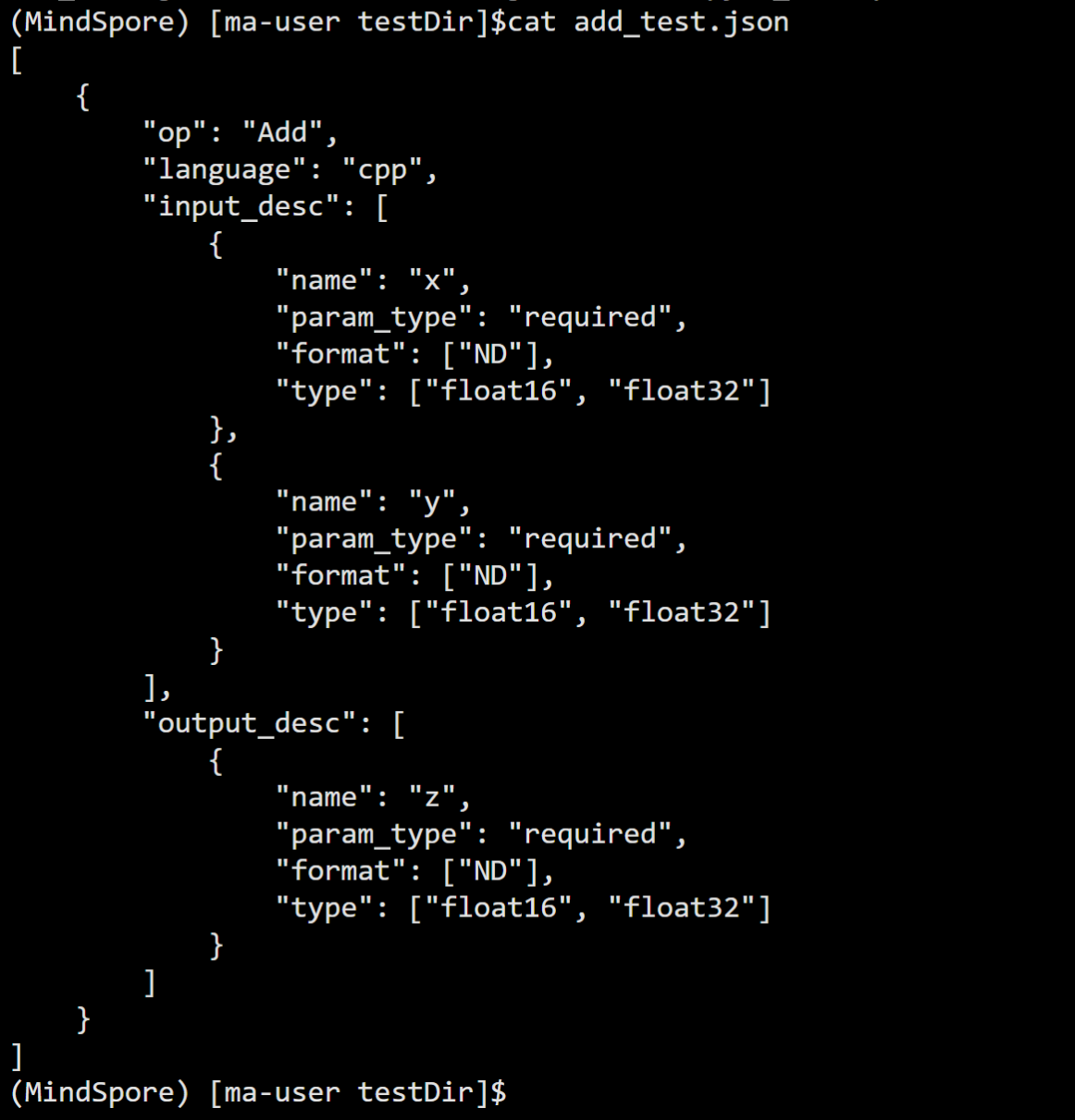
运行创建命令
msopgen gen -i ./add_test.json -c ai_core-ascend910b -lan cpp -out ./AddTestProject
可以看到创建的效果:
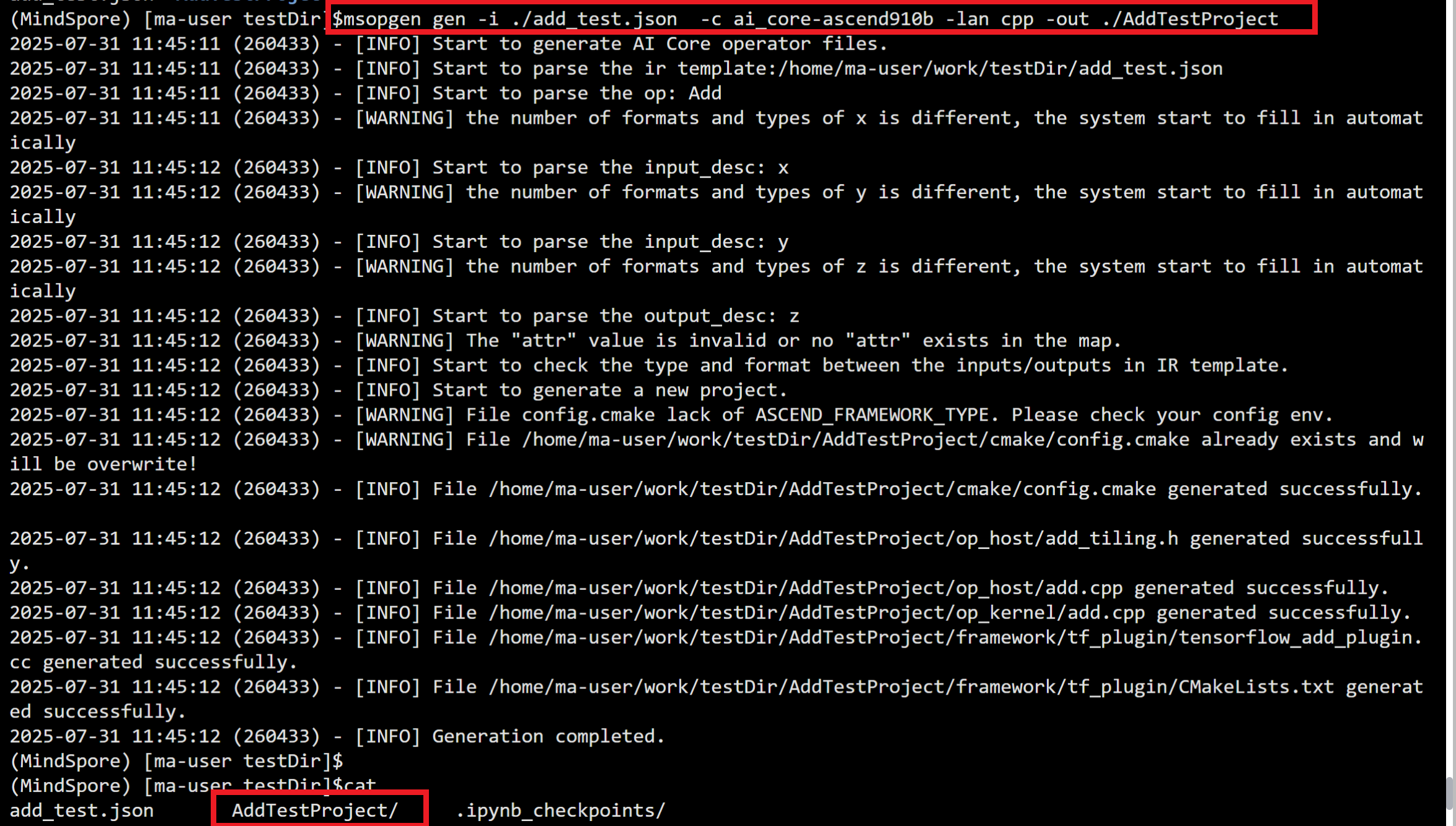
文档结构
创建完毕,我们主要处理op_host和op_kernel即可。
当前环境就代表创建完毕。
编辑op_kernel/add.cpp文件
#include "kernel_operator.h"
using namespace AscendC;
// 定义缓冲区数量,用于双缓冲技术
constexpr int32_t BUFFER_NUM = 2;
// 加法算子的核心实现类
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
// 初始化函数,设置全局内存、缓冲区和计算参数
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum)
{
// 确保block数量不为零
ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
// 计算每个block处理的数据长度
this->blockLength = totalLength / GetBlockNum();
this->tileNum = tileNum;
// 确保tile数量不为零
ASSERT(tileNum != 0 && "tile num can not be zero!");
// 计算每个tile处理的数据长度,考虑双缓冲
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
// 设置全局内存缓冲区,每个block处理自己的数据部分
xGm.SetGlobalBuffer((__gm__ half *)x + this->blockLength * GetBlockIdx(), this->blockLength);
yGm.SetGlobalBuffer((__gm__ half *)y + this->blockLength * GetBlockIdx(), this->blockLength);
zGm.SetGlobalBuffer((__gm__ half *)z + this->blockLength * GetBlockIdx(), this->blockLength);
// 初始化输入输出队列的缓冲区
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(half));
}
// 处理函数,实现计算流水线
__aicore__ inline void Process()
{
// 计算需要处理的循环次数
int32_t loopCount = this->blockLength / this->tileLength;
// 循环处理所有数据块
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i); // 将数据从全局内存复制到本地
Compute(i); // 执行计算
CopyOut(i); // 将结果从本地复制回全局内存
}
}
private:
// 将数据从全局内存复制到本地缓冲区
__aicore__ inline void CopyIn(int32_t progress)
{
// 为X输入分配本地张量并复制数据
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);
inQueueX.EnQue(xLocal);
// 为Y输入分配本地张量并复制数据
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
DataCopy(yLocal, yGm[progress * this->tileLength], this->tileLength);
inQueueY.EnQue(yLocal);
}
// 执行加法计算
__aicore__ inline void Compute(int32_t progress)
{
// 从输入队列获取本地张量
AscendC::LocalTensor<half> xLocal = inQueueX.DeQue<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.DeQue<half>();
// 为输出分配本地张量
AscendC::LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 执行加法操作:z = x + y
AscendC::Add(zLocal, xLocal, yLocal, this->tileLength);
// 将结果放入输出队列
outQueueZ.EnQue<half>(zLocal);
// 释放输入张量
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
// 将计算结果从本地缓冲区复制回全局内存
__aicore__ inline void CopyOut(int32_t progress)
{
// 从输出队列获取结果张量
AscendC::LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// 将结果复制到全局内存
DataCopy(zGm[progress * this->tileLength], zLocal, this->tileLength);
// 释放输出张量
outQueueZ.FreeTensor(zLocal);
}
private:
// 管道对象,用于管理数据流
TPipe pipe;
// 输入队列,用于X和Y的数据
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX;
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueY;
// 输出队列,用于Z的结果
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
// 全局内存张量
GlobalTensor<half> xGm;
GlobalTensor<half> yGm;
GlobalTensor<half> zGm;
// 计算参数
uint32_t blockLength; // 每个block处理的数据长度
uint32_t tileNum; // tile数量
uint32_t tileLength; // 每个tile处理的数据长度
};
// 加法算子的入口函数
extern "C" __global__ __aicore__ void add(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) {
// 获取tiling数据
GET_TILING_DATA(tiling_data, tiling);
// 创建并初始化加法算子对象
KernelAdd op;
// 计算合适的tile数量,每个tile处理1024个元素
uint32_t tile_num = tiling_data.size / 1024;
if (tile_num == 0) tile_num = 1; // 确保至少有一个tile
op.Init(x, y, z, tiling_data.size, tile_num);
// 执行计算
op.Process();
}
执行编译:
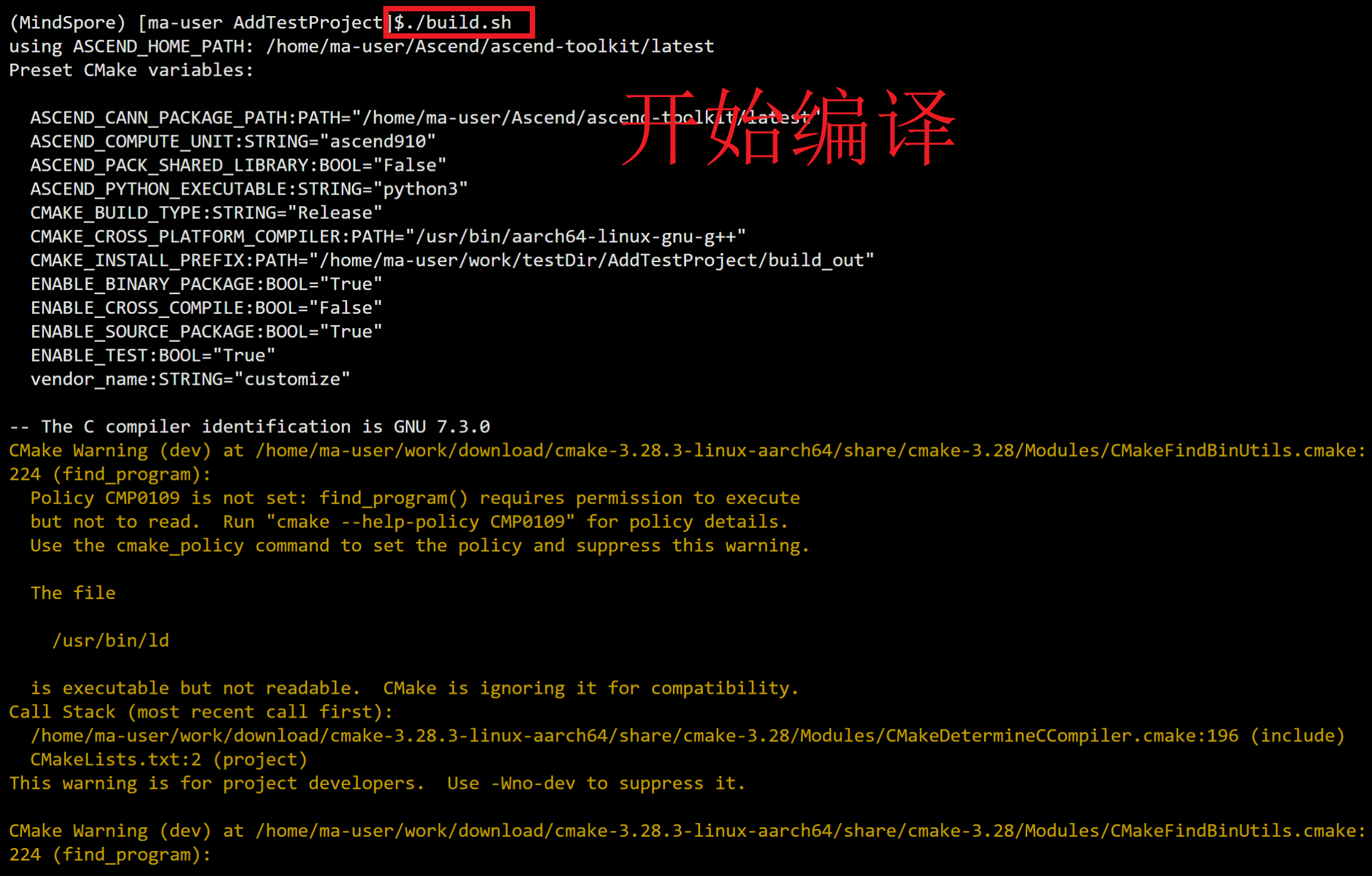
看到正确的编译反馈:
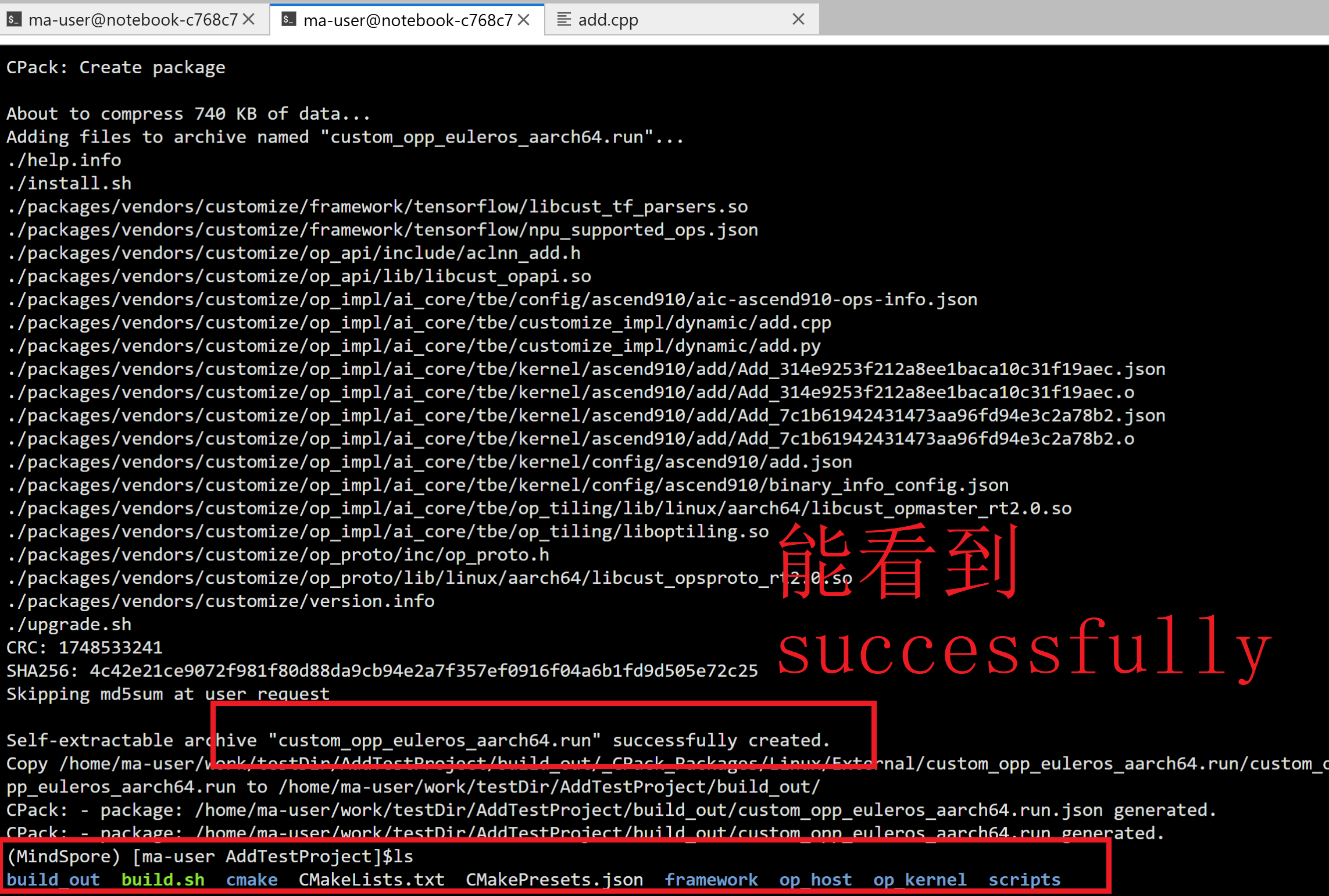
进入运行一下:
cd build_out
./custom_opp_euleros_aarch64.run
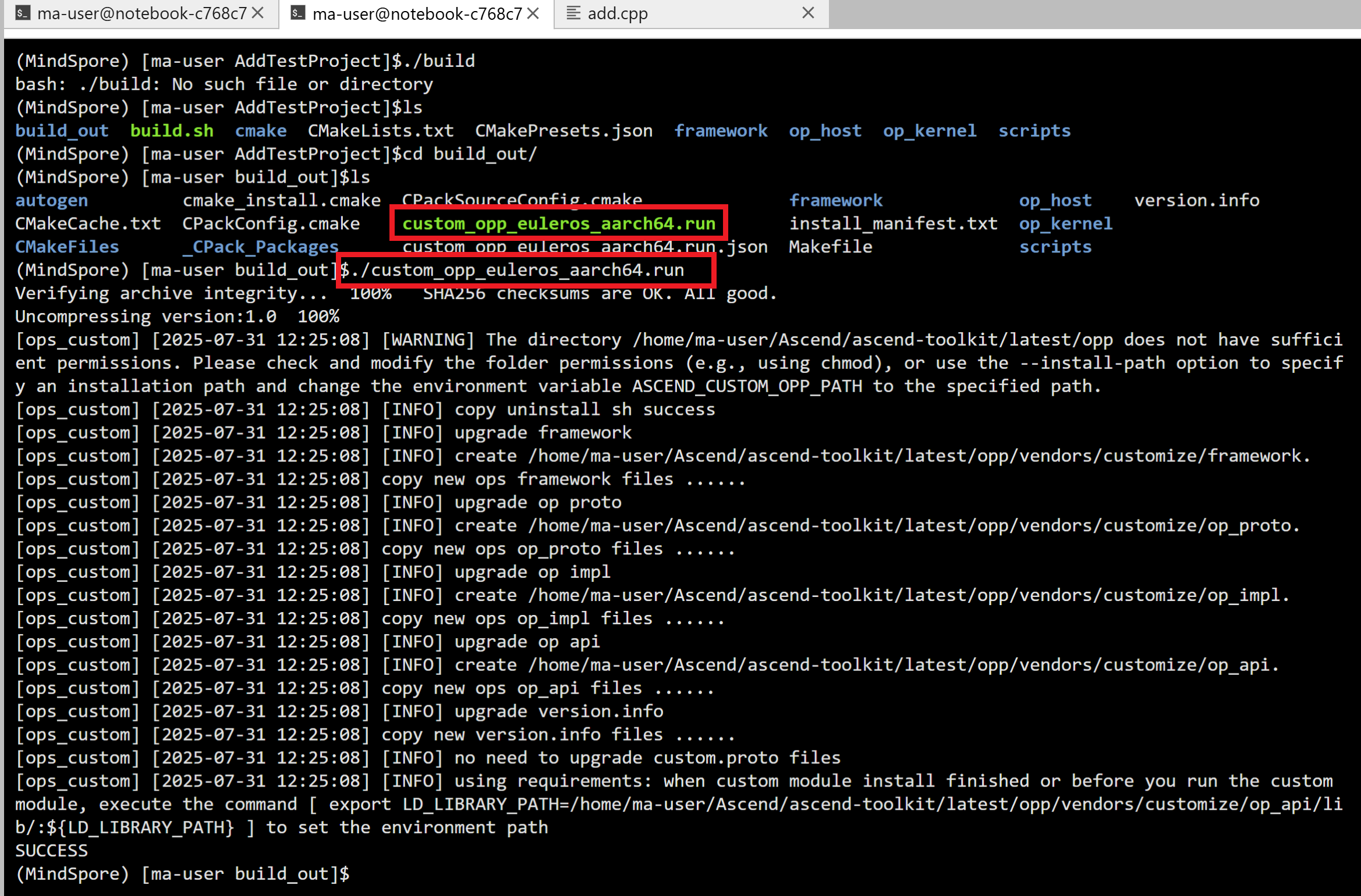
这就是比编译完成的状态了。
|
配置字段 |
类型 |
含义 |
是否必选 |
|
|---|---|---|---|---|
|
op |
- |
字符串 |
算子的Operator Type。 |
是 |
|
input_desc |
- |
列表 |
输入参数描述。 |
否 |
|
name |
字符串 |
算子输入参数的名称。 |
||
|
param_type |
字符串 |
参数类型:
未配置默认为required。 |
||
|
format |
列表 |
针对类型为Tensor的参数,配置为Tensor支持的数据排布格式。 包含如下取值: ND、NHWC、NCHW、HWCN、NC1HWC0、FRACTAL_Z等。 说明 format与type需一一对应。若仅填充其中一项的唯一值,msOpGen工具将会以未填充项的唯一输入值为准自动补充至已填充项的长度。例如用户配置为format:["ND"] /type:["fp16","float","int32"],msOpGen工具将会以format的唯一输入值("ND")为准自动补充至type参数的长度,自动补充后的配置为format:["ND","ND","ND"]/type:["fp16","float","int32"]。 |
||
|
type |
列表 |
算子参数的类型。
说明
|
||
|
output_desc |
- |
列表 |
输出参数描述。 |
是 |
|
name |
字符串 |
算子输出参数的名称。 |
||
|
param_type |
字符串 |
参数类型:
未配置默认为required。 |
||
|
format |
列表 |
针对类型为Tensor的参数,配置为Tensor支持的数据排布格式。 包含如下取值: ND、NHWC、NCHW、HWCN、NC1HWC0、FRACTAL_Z等。 说明 format与type需一一对应。若仅填充其中一项的唯一值,msOpGen工具将会以未填充项的唯一输入值为准自动补充至已填充项的长度。例如用户配置为format:["ND"] /type:["fp16","float","int32"],msOpGen工具将会以format的唯一输入值("ND")为准自动补充至type参数的长度,自动补充后的配置为format:["ND","ND","ND"]/type:["fp16","float","int32"]。 |
||
|
type |
列表 |
算子参数的类型。
说明
|
||
|
attr |
- |
列表 |
属性描述。 |
否 |
|
name |
字符串 |
算子属性参数的名称。 |
||
|
param_type |
字符串 |
参数类型:
未配置默认为required。 |
||
|
type |
字符串 |
算子参数的类型。 包含如下取值: int、bool、float、string、list_int、list_float、list_bool、list_list_int,其他请自行参考OpAttrDef中的“ Host API > 原型注册与管理 > OpAttrDef > OpAttrDef”章节进行修改。 |
||
|
default_value |
- |
默认值。 |
||
说明
- json文件可以配置多个算子,json文件为列表,列表中每一个元素为一个算子。
- 若input_desc或output_desc中存在相同name参数,则后一个会覆盖前一参数。
- input_desc,output_desc中的type需按顺序一一对应匹配,format也需按顺序一一对应匹配。
例如,第一个输入x的type配置为[“int8”,“int32”],第二个输入y的type配置为[“fp16”,“fp32”],输出z的type配置为[“int32”,“int64”],最终这个算子支持输入(“int8”,“fp16”)生成int32,或者(“int32”,“fp32”)生成int64,即输入和输出的type是垂直对应的,类型不能交叉。
- input_desc,output_desc中的type与format需一一对应匹配,数量保持一致。type的数据类型为以下取值("numbertype"、"realnumbertype"、"quantizedtype"、"BasicType"、"IndexNumberType"、"all")时,需识别实际的type数量是否与format数量保持一致,若数量不一致,创建工程会收到报错提示,同时format按照type的个数进行补齐,继续生成算子工程。若type的取值为基本数据类型(如:“int32”),且与format无法一一对应时,创建工程会收到报错提示,并停止运行。
- json文件可对“attr”算子属性进行配置,具体请参考编写原型定义文件。
- 算子的Operator Type需要采用大驼峰的命名方式,即采用大写字符区分不同的语义,具体请参见算子工程编译的须知内容。
- 生成算子的开发工程。
以生成AddCustom的算子工程为例,执行如下命令,参数说明请参见表2。
msopgen gen -i {*.json} -f {framework type} -c {Compute Resource} -lan cpp -out {Output Path} - 命令执行完后,会在指定目录下生成算子工程目录,工程中包含算子实现的模板文件,编译脚本等。算子工程目录生成在-out所指定的目录下:./output_data,目录结构如下所示:
output_data ├── build.sh // 编译入口脚本 ├── cmake │ ├── config.cmake │ ├── util // 算子工程编译所需脚本及公共编译文件存放目录 ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 编译配置项 ├── framework // 算子插件实现文件目录,单算子模型文件的生成不依赖算子适配插件,无需关注 ├── op_host // Host侧实现文件 │ ├── add_custom_tiling.h // 算子tiling定义文件 │ ├── add_custom.cpp // 算子原型注册、shape推导、信息库、tiling实现等内容文件 │ ├── CMakeLists.txt ├── op_kernel // Kernel侧实现文件 │ ├── CMakeLists.txt │ ├── add_custom.cpp // 算子代码实现文件 ├── scripts // 自定义算子工程打包相关脚本所在目录
- 可选:在算子工程中追加算子。若需要在已存在的算子工程目录下追加其他自定义算子,命令行需配置“-m 1”参数。
msopgen gen -i json_path/**.json -f tf -c ai_core-{Soc Version} -out ./output_data -m 1在算子工程目录下追加**.json中的算子。MindSpore算子工程不能够添加非MindSpore框架的算子。
- -i:指定算子原型定义文件add_custom.json所在路径。
- -c:参数中{Soc Version}为昇腾AI处理器的型号。
- 完成算子工程创建,进行算子开发。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 39
39 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)