
昇腾框架梳理以及部分使用经验分享(含CANN,Mindfomers,torch_npu)
最底层是华为自主的独立计算框架CANN(类比CUDA)向上是基于CANN计算框架的开发工具,其中包括独立的MindSpore和依赖于传统框架TensorFlow/PyTorch的CANN支持方案如(torch-npu)再向上可能是类似,Mindfomers,LLama-Factory,Transfomers,Diffusers等依赖于上面框架集成的更快速的开发工具再最后就是实际应用部分下面简单介绍
文章目录
昇腾体系总体介绍
主页地址:https://www.hiascend.com/software/cann 自底向上的说:
自底向上的说:
- 最底层是华为自主的独立计算框架CANN(类比CUDA)
- 向上是基于CANN计算框架的开发工具,其中包括独立的MindSpore和依赖于传统框架TensorFlow/PyTorch的CANN支持方案如(torch-npu)
- 再向上可能是类似,Mindfomers,LLama-Factory,Transfomers,Diffusers等依赖于上面框架集成的更快速的开发工具
- 再最后就是实际应用部分
下面简单介绍一下各个部分涉及的内容,以及官方提供的相关资源。
一、CANN计算框架(算子开发场景)
主页:https://www.hiascend.com/software/cann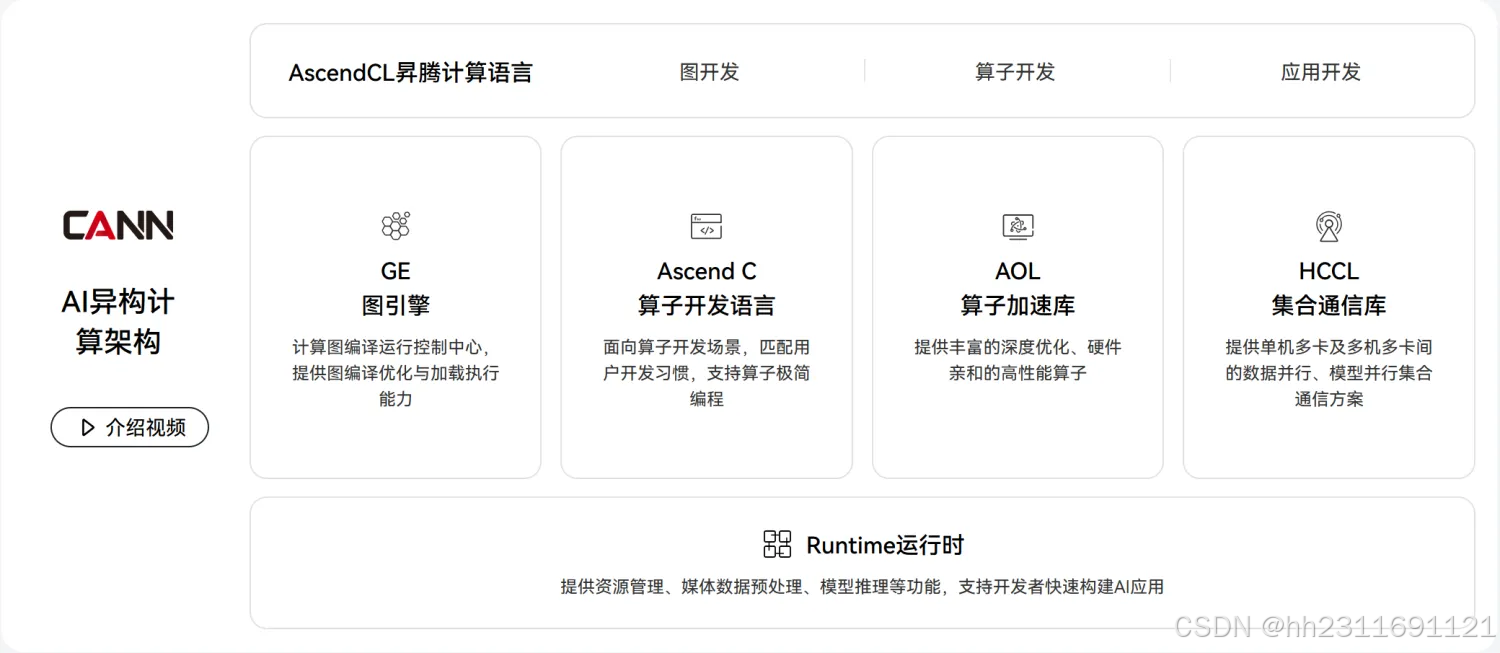
CANN组成:
- 图引擎: 是计算图编译和运行的控制中心,提供图优化、图编译管理以及图执行控制等功能。GE通过统一的图开发接口提供多种AI框架的支持,不同AI框架的计算图可以实现到Ascend图的转换。
- Ascend C 算子开发:Ascend C 是CANN针对算子开发场景推出的编程语言, 通过使用Ascen C语言实现对算子的高效开发。
- 算子加速库(简称AOL ):提供了丰富的深度优化、硬件亲和的高性能算子,包括神经网络(Neural Network,NN)库、线性代数计算库(Basic Linear Algebra Subprograms,BLAS)等
- 集合通信库(HCCL): 是基于昇腾硬件的高性能集合通信库,提供单机多卡以及多机多卡间的数据并行、模型并行集合通信方案。
可以说CANN是使用昇腾体系的基础和重中之重,下面介绍下如何安装:
CANN安装流程:
- 首先确定你所需要的CANN版本,这取决于你的机器型号、系统架构、以及你后续要安装的torch-npu或者Mindspore的版本。
- 根据官方文档(注意版本号),安装NPU驱动以及想要的CANN,以8.0RC1.beta1社区版本为例。
(假设已经安装好了NPU驱动与固件)
- 在资源官网,找到你想要的CANN版本的toolkit与对应版本的kernels。如: Ascend-cann-toolkit_8.0.RC1_linux-aarch64.run表示arm架构的8.0.RC1版本CANN的toolkit,kernels同理。
- 将下载好的资源执行下面的命令进行安装:
chmod +x Ascend-cann-toolkit_8.0.RC1_linux-aarch64.run
./Ascend-cann-toolkit_8.0.RC1_linux-aarch64.run --install
- 如果是root用户安装,检查/usr/local/Ascend/ascend_toolkit目录下是否包含set_env.sh文件,可以初步判断是否成功安装,另外建议将source /usr/local/Ascend/ascend_toolkit/set_env.sh加入到~/.bashrc中,否则可能每次启动都需要初始化环境变量。
- 如何卸载CANN:进入到
/usr/local/Ascend/ascend_toolkit目录下对应版本的文件夹中,如/usr/local/Ascend/ascend_toolkit/8.0执行cann_uninstall.sh即可完成对CANN的卸载
可能出现的问题:
1. 安装时提示版本不兼容检查是否安装成x86版本。
2. 使用时没有启动set_env.sh, 可以通过export $ASCEND_TOOLKIT_HOME查看环境变量有没有被正确设置。
3. 如果后续出现运行过程的问题可以对照torch_npu版本是否对应,如果对应,根据经验基本上不会是CANN包的问题。
社区版CANN资源下载:
torch_npu版本对应链接:
Mindspore版本对应链接: Mindspore对CANN宽容度较高,但也可以在gittee下对应分支查看推荐的CANN版本。
二、Mindspore与Torch_npu安装(模型开发场景)
Torch_npu安装:
torch_npu是昇腾为了兼容Pytorch制作的一个扩展性质文件,通过安装torch_npu,可以通过简单的修改原本的torch代码就能够实现对昇腾NPU的使用。
torch_npu版本对应与安装教程见链接对应分支:https://gitee.com/ascend/pytorch/tree/v2.3.1/
torch_npu官方文档(含安装教程,模型开发说明):https://www.hiascend.com/document/detail/zh/Pytorch/60RC2/configandinstg/instg/insg_0001.html(推荐)
-
确定安装版本,你所安装的Python,Pytorch,Torch_npu,CANN版本最好都进行对应如:
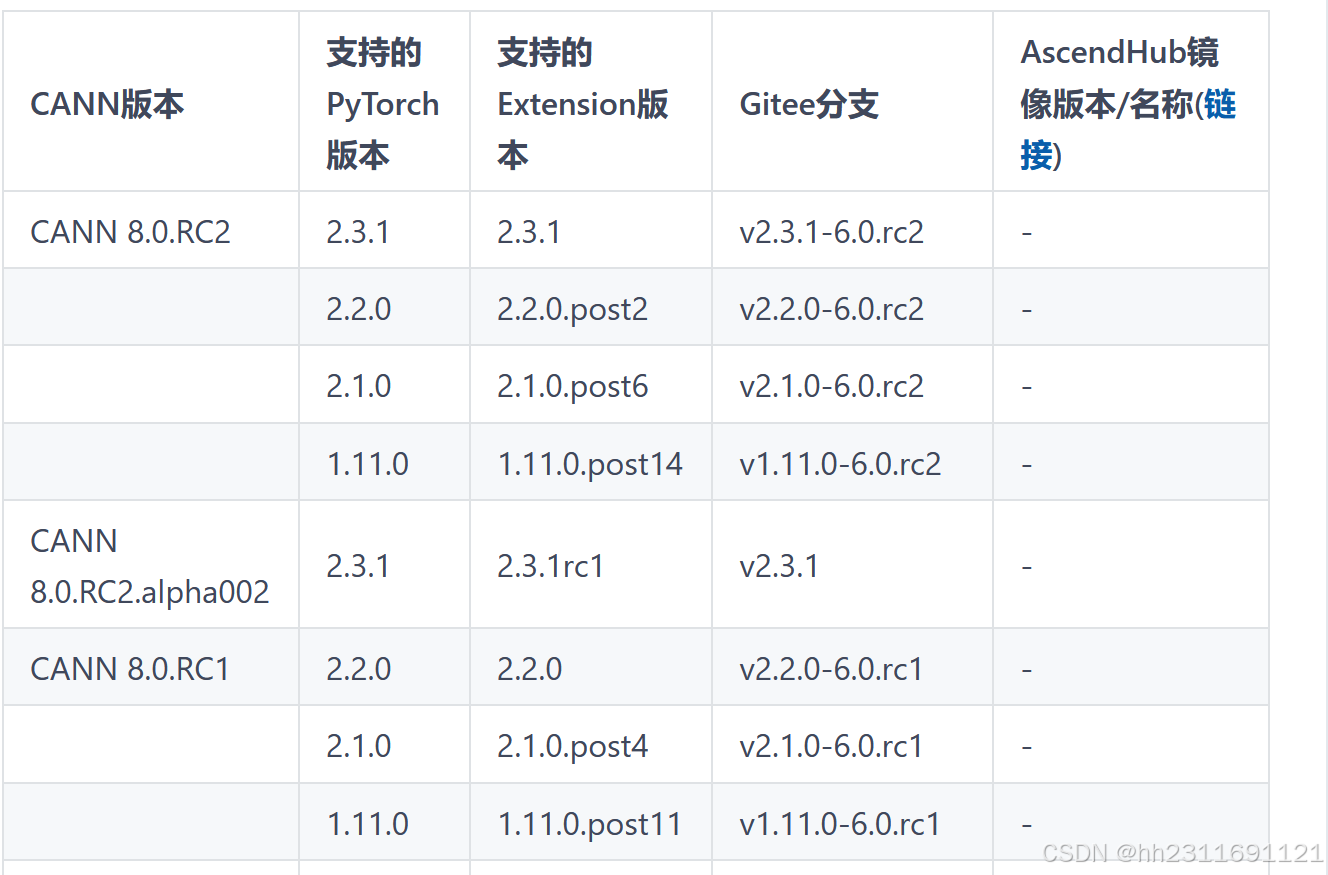 或者可以通过官方提供的链接进行勾选:
或者可以通过官方提供的链接进行勾选: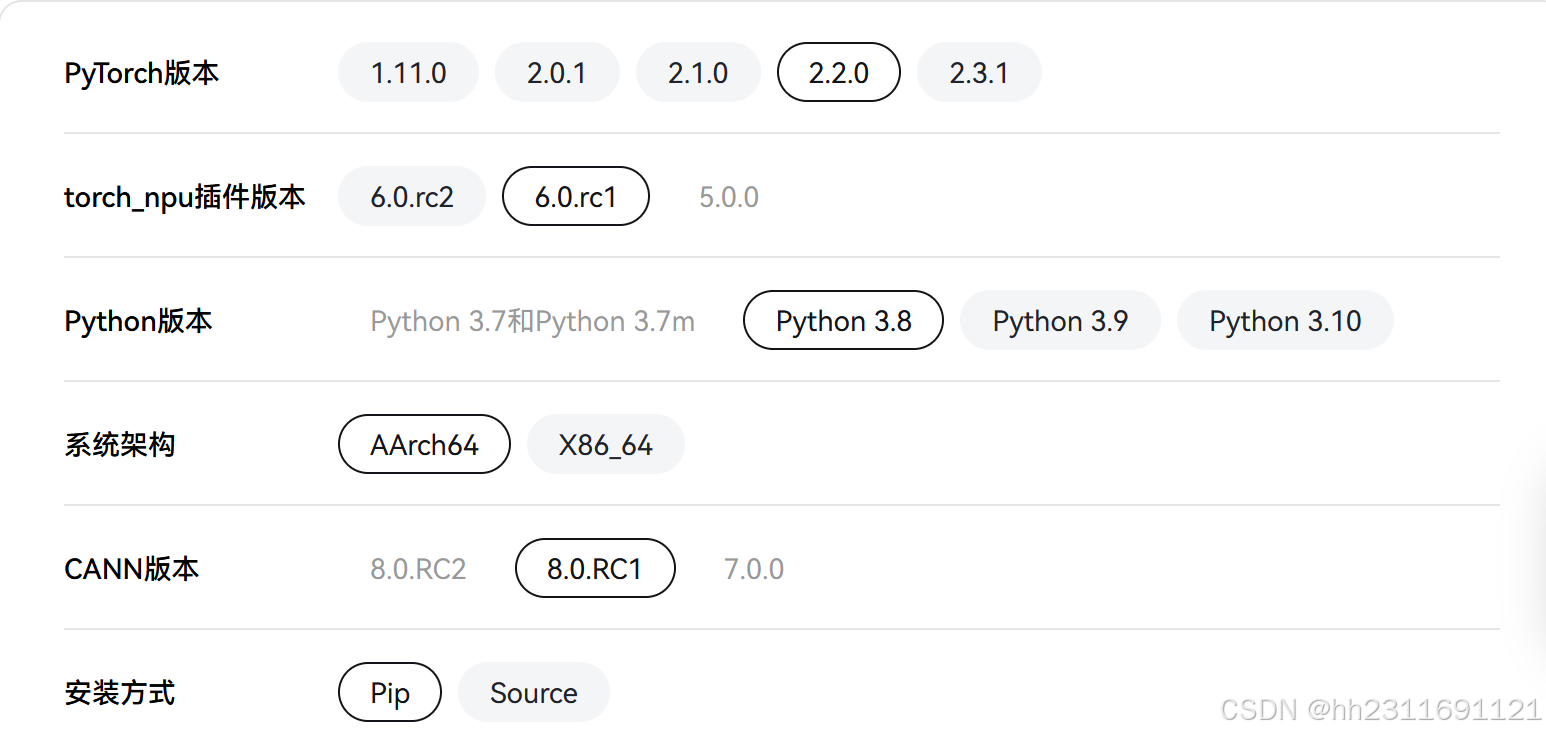
-
通过pip命令就可以安装torch_npu, torch
pip3 install torch==2.2.0 pip3 install torch_npu==2.2.0或者通过上面勾选完成后官方提供的方法进行安装,如果你需要torchvision或者其他的torch组件留意官方文档中的版本需求。

-
检验是否安装成功,运行下面的代码, 如果都能够通过则可以认为成功安装,:
import torch import torch_npu x = torch.randn(2,2).npu() y = torch.randn(2,2).npu() z = x.mm(y) print(z)import torch import torch_npu def test_cpu(): input = torch.randn(2000, 1000).detach().requires_grad_() output = torch.sum(input) output.backward(torch.ones_like(output)) def test_npu(): input = torch.randn(2000, 1000).detach().requires_grad_().npu() output = torch.sum(input) output.backward(torch.ones_like(output)) if __name__ == "__main__": test_cpu() test_npu() -
如何卸载:与其他python组件包一致,通过pip uninstall即可卸载torch_npu
pip uninstall torch-npu
Mindspore安装:
Mindspore是一个独立的开发框架,它等同于昇腾体系下的Pytorch或者Tensorflow,因此如果想要实现一个模型从Pytorch到Mindspore的移植则通常需要对模型进行更加深入的修改。但是通常Mindspore在昇腾上拥有比torch-npu更优秀的表现。
官方文档(含安装教程,使用教程,模型库,文档等):https://www.mindspore.cn/install/
官方gitee:https://gitee.com/mindspore/docs/blob/r2.1/install/mindspore_ascend_install_pip.md(注意分支)
安装流程:
- 安装Mindspore的版本需要考虑python,CANN版本,以及gcc。不过个人感觉不同版本的Mindspore对CANN的兼容性比较强。
- 安装流程中需要我们安装gcc,可以通过
gcc --version查看是否已经安装 - 安装Mindspore,可以通过
pip install mindspore==x.x.x进行安装也可以通过官网的命令进行安装对应的版本。此处Mindspore版本更多取决于你后续需要使用的如Mindfomers,Mindone等依赖于特定版本Mindspore框架实现的方法,它们通常需要指定的Mindspore版本实现。 - 校验是否安装成功:
import numpy as np import mindspore as ms import mindspore.ops as ops ms.set_context(device_target="Ascend") x = ms.Tensor(np.ones([1,3,3,4]).astype(np.float32)) y = ms.Tensor(np.ones([1,3,3,4]).astype(np.float32)) print(ops.add(x, y)) - 如何卸载:
pip uninstall mindspore
可能出现的问题:
1. import部分出错:通过如pip show torch-npu检查torch-npu是否被正常安装。如果没有并且使用的是conda镜像环境,请检查安装的地点是否正确,必要时可以通过--target 指定安装地址如:pip install ** --target /root/anaconda3/envs/py3.9/lib/python3.9/site-packages
2. 正常安装torch_npu但无法运行或者导入,请检查source /usr/local/Ascend/ascend-toolkit/set_env.sh是否正常执行,环境变量是否正常设置。
3. 如果使用Jupyter Notebook可能由于环境变量问题无法运行,可以改用py脚本或者命令行使用python输入测试。
4. 安装Mindspore时,必须先安装CANN再安装Mindspore否则ms.set_context(device_target="Ascend")可能提示只有CPU设备。
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
三、Mindfomers、Mindones、Transfomers、Diffusers使用(应用开发场景)
Transfomers,Diffusers是Huggingface上为了让开发者更加便捷的使用预训练模型所创造的一个工具,它能够帮助用户快捷的部署、训练基于pytorch或者tensorflow框架的模型。而Mindfomers、Mindones则是类似的工具,能够更方便的帮助用户部署、训练以Mindspore为框架的预训练模型,下面简单介绍一下各个工具的使用。
Transfomers、Diffusers案例:
由于torch已经基本原生支持NPU,在完成安装torch_npu之后,基本上可以将原本的torch模型直接部署到npu上完成和在其他平台上同样的使用,只不过可能在性能上存在缺陷,需要进行针对性的调优。
想要在昇腾下更好的使用torch可以看:
昇腾官方学习路线:https://www.hiascend.com/edu/growth(中的Ascend Extension for PyTorch部分)
昇腾官方在线课程:https://www.hiascend.com/edu/courses(中搜索pytorch)
也可以通过LLaMa_Factory实现对大模型的NPU推理
下面简单使用Transfomers案例:
案例暂时存在Bug无法调用NPU的Ai Core导致推理过程很慢
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import GenerationConfig
import numpy as np
import torch
import torch_npu
device = "npu" # the device to load the model onto
#model_dir = snapshot_download('qwen/Qwen1.5-7B-Chat',cache_dir="models")
model_dir = "/data/XuYL_test/models/qwen/Qwen1___5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map=device,
torch_dtype=torch.float16,
#bf16 = True,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
def infer(model, tokenizer, prompt):
#prompt = "帮助我制定一份去上海的旅游攻略。"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text,text,text,text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
do_sample = False,
use_cache = True,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
question = ""
while(question != 'quit'):
question = input("输入一个问题:")
response = infer(model, tokenizer, question)
print(response)
下面简单使用Diffusers案例:注意使用的Diffusers版本,版本过高可能导致速度过慢或者无法运行
from diffusers import StableDiffusionPipeline
import torch
import torch_npu
model_id = "models/AI-ModelScope/stable-diffusion-v1___5-no-safetensor"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("npu:2")
prompt = "A photo of an astronaut riding a horse on mars"
while(prompt):
prompt = input("输入想生成的图片:")
image = pipe(prompt).images[0]
image.save(f"{prompt}.png")
基本上与原本的内容一致,只是将模型部署到NPU上。
Mindfomers、Mindone案例:
可以将Mindfomers与Mindone看作基于Mindspore的Transfomers与Diffusers,它的使用依赖于特定版本的Mindspore。
具体环境需求需要参考特定版本的gitee仓库描述:
Mindformers:https://gitee.com/mindspore/mindformers
Mindones:https://github.com/mindspore-lab/mindone/tree/master
使用时需要考虑机器、CANN、Mindspore与Mindformers的对应关系。
Mindformers使用:
Mindformers是一个可以进行大模型训练、推理、部署的全流程套件,使用时通常需要找到对应的说明文档,根据指引设置yaml文件启动脚本即可。
下面是使用Mindformers的基本流程:
- 安装Mindformers特定版本(此处为r1.0.a)
- 在gitee的特定分支中找到research目录下目标模型的文件夹(此处为qwen)
- 此处则可以找到qwen.md文件,其中包含对qwen模型的推理、微调、训练说明
- 根据说明可以学习如何使用Mindformers运行特定模型,大体上是设置yaml文件调用脚本。
或者你可以使用Mindfomers的API进行调用,下面是使用API调用Qwen1.5的案例:
- py文件需要在/research/qwen1_5目录下
import sys
import mindspore as ms
from mindspore import context
from mindformers import MindFormerConfig
from mindformers.core.context import build_context
from mindformers.core.parallel_config import build_parallel_config
from mindformers.pet import get_pet_model, LoraConfig
from mindformers.pipeline import TextGenerationPipeline
from mindformers import AutoModel, AutoConfig
##这是为什么需要将py文件放到指定目录下
from qwen1_5_tokenizer import Qwen2Tokenizer
#读取config文件,可以照着仿写
config_file_path = "/data/XuYL_test/resource/mindformers/research/qwen1_5/run_qwen1_5_7b_infer.yaml"
config = MindFormerConfig(config_file_path)
build_context(config)
build_parallel_config(config)
context.set_context(mode=ms.GRAPH_MODE, device_target="Ascend", device_id=2)
tokenizer = Qwen2Tokenizer(**config.processor.tokenizer)
model_config = AutoConfig.from_pretrained(config_file_path)
model = AutoModel.from_config(model_config)
text_generate = TextGenerationPipeline(model=model, tokenizer=tokenizer)
while True:
user_input = input("Please enter your predict data: \n")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_input}
]
messages = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
if not user_input:
continue
if user_input == "exit":
print("Task is over.")
sys.exit()
output = text_generate(user_input)
print(output)
910a推理qwen1_5教程:https://gitee.com/mindspore/mindformers/tree/r1.0.a/docs/910a_adaptdocs
官方教程文档:https://mindformers.readthedocs.io/zh-cn/latest/
API调用方法教程:https://mindformers.readthedocs.io/zh-cn/r1.1.0/research/qwen/qwen.html(model.generator()部分)
Mindone使用:
Mindone的使用类似于Mindformers,需要在官网上找到examples目录下的特定模型目录,以及对应指导文件即可。
比如:https://github.com/mindspore-lab/mindone/tree/master/examples/stable_diffusion_v2
可能出现的问题:
1. 调用模型时输出内容乱码,请检查yaml文件中模型位置是否正确,模型是否被正常读入2. 模型无法加载检查自己是否转换了大模型的权重
学习资源路径:
昇腾官方学习路线:https://www.hiascend.com/edu/growth
昇腾官方在线课程:https://www.hiascend.com/edu/courses
昇腾官方模型仓:Mindspore ModleZoo,
模型库

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)