
MindIE服务化性能MindIE service如何调优?首token时延限制严格,非首token时延也有限制
MindIE Service是面向通用模型场景的推理服务化框架,通过开放、可扩展的推理服务化平台架构提供推理服务化能力,支持对接业界主流推理框架接口,满足大语言模型的高性能推理需求。
1 简介
MindIE Service是面向通用模型场景的推理服务化框架,通过开放、可扩展的推理服务化平台架构提供推理服务化能力,支持对接业界主流推理框架接口,满足大语言模型的高性能推理需求。
MindIE Service的组件包括MindIE Service Tools、MindIE Client、MindIE MS(MindIE Management Service)和MindIE Server,通过对接昇腾推理加速引擎带来大模型在昇腾环境中的性能提升,并逐渐以高性能和易用性牵引用户向MindIE原生推理服务化框架迁移。其架构图如图1所示。
MindIE Service 提供推理服务化部署和运维能力。
- MindIE Service Tools:昇腾推理服务化工具;主要功能有大模型推理性能测试、精度测试、可视化以及自动寻优的能力,并且支持通过配置提升吞吐。
- MindIE Client:昇腾推理服务化完整的Client客户端;配套昇腾推理服务化MindIE Server提供完整的推理服务化能力,包括对接MindIE Server的通信协议、请求和返回的接口,提供给用户应用对接。
- MindIE MS:服务策略管理,提供服务运维能力。主要功能包括模型Pod级和Pod内实例级管理、简化部署并提供服务质量监控、模型更新、故障重调度和自动扩缩负载均衡能力,不仅能够提升服务质量,同时也能提高推理硬件资源利用率。
- MindIE Server
:推理服务端;提供模型推理服务化能力,支持命令行部署RESTful服务。- EndPoint:提供RESTful接口;EndPoint面向推理服务开发者提供RESTful接口,推理服务化协议和接口封装,支持Triton/OpenAI/TGI/vLLM主流推理框架请求接口。
- GMIS:模型推理调度器,提供多实例调度能力;实现从推理任务调度到任务执行的可扩展架构,适应各类推理方法。
- BackendManager:模型执行后端,昇腾后端和自定义后端的管理模块;Backend管理模块面向不同推理引擎,不同模型,提供统一抽象接口,便于扩展,减少推理引擎、模型变化带来的修改。
- MindIE Backends:支持昇腾MindIE LLM后端。
- MindIE LLM:提供大模型推理能力,同时提供多并发请求的调度功能。
2 性能调优流程
通过参数调优,使吞吐率(TPS)达到时延约束条件下的最大值。
首先,大家需要对调优的一些参数做一个了解。
2.1 最优性能参数配置项
最优性能配置各参数说明及取值如下表所示。
最优性能参数配置
| 配置类型 | 配置项 | 配置介绍 | 推荐配置 |
|---|---|---|---|
| 调度配置 | maxPrefillBatchSize | Prefill阶段一个batch中包含请求个数的上限。 | 小于等于maxBatchSize的值,建议设置为:maxBatchSize/2 ,若显存溢出可适当调小。 |
| maxPrefillTokens | Prefill阶段一个batch中包含input token总数的上限。 | maxPrefillBatchSize * 数据集token id平均输入长度。不建议设置过大,若显存溢出可适当调小。 | |
| maxBatchSize | Decode阶段一次推理包含请求的最大个数。 | 根据ScheduleConfig参数说明maxBatchSize参数中的公式计算出最大值。如果需要限制Decode时延,可适当调整maxBatchSize大小,一般情况maxBatchSize越小,吞吐量会降低,Decode时延越小。 | |
| supportSelectBatch | false:关闭,表示优先执行Prefill。true:开启,优化stage执行优先级;根据prefillTimeMsPerReq和decodeMsPerReq数值动态优化,prefillTimeMsPerReq设置越高,Prefill被优先执行的概率越低,也就是Prefill会等到多轮Decode后再执行。 | 吞吐优先时,建议设置为:true。首token时延优先时,建议设置为:false。 | |
| prefillTimeMsPerReq | 平均每个请求Prefill时间。“supportSelectBatch”设置为“true”时生效。 | 建议值:600,单位为ms;若需要降低首token时延可适当调小。计算与decodeTimeMsPerReq的比值,即prefillTimeMsPerReq/decodeTimeMsPerReq,该比值越大,调度时优先做Decode,会降低Decode时延,提高首token时延。 | |
| decodeTimeMsPerReq | 平均每个请求Decode时间。“supportSelectBatch”设置为“true”时生效。 | 建议值:50,单位为ms。建议仅调整prefillTimeMsPerReq值,该值固定为50ms。 | |
| maxQueueDelayMicroseconds | 请求在队列中的最大等待时间。 | 在队列中的请求数量达到最大maxBatchSize、maxPrefillBatchSize或maxPrefillTokens前,请求在队列中的最大等待时间,单位:us。只要等待时间达到该值,即使请求数量未达到最大maxBatchSize、maxPrefillBatchSize或maxPrefillTokens,也要进行下一次推理。必填,默认值:5000。 | |
| maxPreemptCount | 每一批次最大可抢占请求的上限,即限制一轮调度最多抢占请求的数量,最大上限为maxBatchSize,取值大于0则表示开启可抢占功能。 | [0, maxBatchSize],当取值大于0时,cpuMemSize取值不可为0。建议值:0(关闭)。当环境变量MIES_USE_MB_SWAPPER为"1"时该参数生效。 | |
| 模型配置 | worldSize | 节点可以使用的NPU卡数。 | 根据用户实际环境情况启用NPU卡数量。 |
| npuDeviceIds | 推理使用的一组NPU卡号。 | [0, 1, 2, …, worldSize-1] | |
| npuMemSize | 单个NPU中可以用来申请KV Cache的size上限,单位GB。 | npuMemSize=(单卡总空闲-权重/NPU卡数-后处理占用)*系数,其中系数取0.8。通常情况下,大模型推理主要是显存bound,因此该值配置的越大,KV Cache可用的显存越多,BatchSize就越大,吞吐量将会更优。说明在一些小模型场景下,显存充足,主要是计算bound,调大显存效果并不明显。 | |
| cpuMemSize | 单个CPU中可以用来申请KV Cache的size上限。单位:GB。开启Swap时生效,如何开启请参考性能调优环境变量配置中的MIES_USE_MB_SWAPPER环境变量。 | 上限根据显存和用户需求来决定。只有当maxPreemptCount为0时,才可以取值为0。建议值:5。 | |
| cacheBlockSize | 表示一个block块的大小;NPU显存会被分成单个的block。例如配置128,表示一个block实际大小为128*sizof(cache数据类型)字节。如果相同的显存,设置的block size越小,那么block num越多。 | 根据请求平均输入输出大小确定,一般默认为128,如果平均输入较小可以适当调小。 | |
| 其他配置 | logLevel | 设置日志级别。“Verbose”:打印Verbose、Info、Warning和Error级别的日志。“Info”:打印Info、Warning和Error级别的日志。“Warning”:打印Warning和Error级别的日志。“Warn”:打印Warning和Error级别的日志。“Error”:打印Error级别的日志。“Debug”:打印Verbose、Info、Warning和Error级别的日志。 | 建议值:“Error”,打印Error级别的日志。 |
3 具体示例
各个参数操作的具体示例可以参见:
https://www.hiascend.com/document/detail/zh/mindie/20RC2/mindieservice/servicedev/mindie_service0105.html
本文只对场景“不考虑时延的极限吞吐”进行说明
4 首token时延限制严格,非首token时延也有限制
以首token平均时延限制在8000ms以内、Decode平均时延限制50ms以内为目标,首token时延限制严格,且非首token时延也有限制的调试方式如下所示。
- 服务端:
- “maxBatchSize”调小到卡对应的时延,一般情况下“maxBatchSize”越小,则Decode时延越小。
- 设置supportSelectBatch为false。
- 客户端:
- 按并发数发送请求:客户端Concurrency通常配置为maxBatchSize-1。
- 按频率发送请求:则Concurrency可设置为1000,请求发送频率根据实际业务场景或按模型实际QPS设置。
-
在裸机中执行以下命令开启CPU高性能模式和透明大页,开启后可提升性能,建议开启。
-
开启CPU高性能模式,在相同时延约束下,TPS会有约3%的提升。
cpupower -c all frequency-set -g performance -
开启透明大页,多次实验的吞吐率结果会更稳定。
echo always > /sys/kernel/mm/transparent_hugepage/enabled说明
服务化进程可能与模型执行进程抢占CPU资源,导致性能时延波动;可以在启动服务时将服务化进程手动绑核至CPU奇数核,以减少CPU抢占影响,降低性能波动,具体方法如下所示。
- 使用lscpu命令查看系统CPU配置情况。
lscpu
CPU相关配置回显信息如下所示:
NUMA: NUMA node(s): 8 NUMA node0 CPU(s): 0-23 NUMA node1 CPU(s): 24-47 NUMA node2 CPU(s): 48-71 NUMA node3 CPU(s): 72-95 NUMA node4 CPU(s): 96-119 NUMA node5 CPU(s): 120-143 NUMA node6 CPU(s): 144-167 NUMA node7 CPU(s): 168-191- 使用taskset -c命令将服务化进程绑核至CPU奇数核并启动。
$cpus:为CPU配置回显信息中node1、node3、node5或node7的值。taskset -c $cpus ./bin/mindieservice_daemon
- 使用lscpu命令查看系统CPU配置情况。
-
-
使用以下命令启动服务,以当前所在Ascend-mindie-service_{version}_linux-*{arch}*目录为例。
./bin/mindieservice_daemon回显如下则说明启动成功。
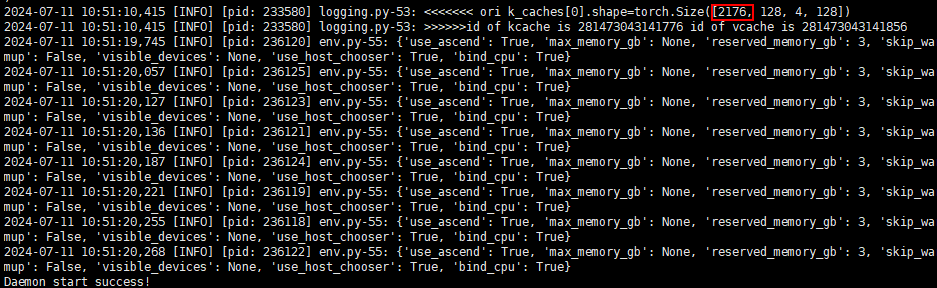
Daemon start success!服务启动后,可通过info级打屏日志k_caches[0].shape=torch.Size([npuBlockNum, x, x, x])中torch.Size的第一个值获取npuBlockNum的值,如图1所示,与3.a中计算出来的值一致。
图1 启动成功
-
根据3.c计算出“maxBatchSize”的取值范围为[90,272],设置初始值为200;“maxPrefillBatchSize”参数的值设置为“maxBatchSize”值的一半,取值为100。
说明
需要将“supportSelectBatch”参数设置为false,以获取更低的首token时延。 -
配置完成后,用户可使用HTTPS客户端(Linux curl命令,Postman工具等)发送HTTPS请求,此处以Linux curl命令为例进行说明。
重开一个窗口,使用以下命令发送请求,获取当前首token平均值(Average)和DecodeTime的平均值(Average),此时首token平均时延为21252.0612ms,decode平均时延为73.7486ms。
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType "gsm8k" \
--ModelName LLaMa3-8B \
--ModelPath "/{模型路径}/LLaMa3-8B" \
--TestType client \
--Http https://{ipAddress}:{port} \
--ManagementHttp https://{managementIpAddress}:{managementPort} \
--Concurrency 1000 \
--TaskKind stream \
--Tokenizer True \
--MaxOutputLen 512
以上结果超过了首token平均时延为8000ms和Decode平均时延为50ms的限制,所以需要调小“maxBatchSize”的值继续调试。
5. 设置“maxBatchSize”的值为150,“maxPrefillBatchSize”参数的值设置为75。然后执行4,继续观察首token平均时延和Decode平均时延,此时首token平均时延为11265.0242ms,Decode平均时延为61.9161ms。
以上结果同样超过了首token平均时延为8000ms和Decode平均时延为50ms的限制,所以需要调小“maxBatchSize”的值继续调试。
6. 设置“maxBatchSize”的值为100,“maxPrefillBatchSize”参数的值设置为50。然后执行4,继续观察首token平均时延和Decode平均时延,此时首token平均时延为6364.6507ms,Decode平均时延为49.9804ms。
以上结果可以看到首token平均时延和Decode平均时延已经在限制的8000ms和50ms以内,且Decode平均时延已经很接近50ms,此时几乎已达到限制首token时延和Decode时延下的最大吞吐量。如需获取Decode平均时延更接近50ms时的“maxBatchSize”值,请根据以上操作步骤继续调试。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)