
从零开始:在昇腾环境用MindIE部署Qwen3-30B-A3B大模型的踩坑实录

大家好,最近折腾了好几天,终于在昇腾上用MindIE部署好了Qwen3-30B-A3B模型。过程中踩了无数坑,从设备识别到端口冲突,从Tokenizer错误到局域网访问,几乎把能遇到的问题都经历了一遍。今天就把整个过程整理成一篇保姆级教程,希望能帮大家少走弯路。
前置准备:这些东西你得先有

在开始之前,咱们得先确认手头有这些东西:
- 一台带昇腾NPU的服务器(我用的是910B(32G),4张卡)
- 已经安装好CANN驱动(版本2.1及以上,这步很重要,驱动不对后面全白搭)
- Docker环境(方便隔离部署,避免污染系统环境)
- Qwen3-30B-A3B-Instruct模型文件(包括权重、config、tokenizer等,建议从官方渠道下载)
- 至少100GB的存储空间(模型本身就快60GB,加上容器和缓存,空间一定要够)
第一步:拉取MindIE镜像并启动容器
MindIE是华为昇腾推出的大模型部署框架,专门优化了昇腾NPU的性能。咱们直接用官方镜像,省去编译安装的麻烦。最好自己去按官方教程:
方式一:镜像部署方式https://www.hiascend.com/document/detail/zh/mindie/20RC1/envdeployment/instg/mindie_instg_0021.html
拉取镜像
先拉取镜像(这个镜像有点大,耐心等会儿):
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.1.RC1-800I-A2-py311-openeuler24.03-lts
然后启动容器,这里有几个关键点:
- 必须用
--net=host模式,不然端口映射能烦死你 - 要把昇腾设备文件挂载进去,不然容器里看不到NPU
- 模型文件要挂载到容器内,建议用绝对路径
我的启动命令是这样的(记得把路径换成你自己的):
docker run -it -d --net=host --shm-size=1g \
--name qwen3-30b \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
-e ASCEND_VISIBLE_DEVICES=0,1,2,3 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /devdata/Qwen3-30B-A3B-Instruct-2507:/models/Qwen3-30B-A3B-Instruct-2507:rw \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.1.RC1-800I-A2-py311-openeuler24.03-lts bash
这里踩过的第一个坑:一开始挂载模型用了ro(只读)权限,后面需要修改tokenizer文件时发现改不了,只能删掉容器重跑,所以建议先用rw,等稳定了再改回去。
第二步:进入容器,检查基础环境
启动容器后,用docker exec -it qwen3-30b bash进入容器,先做几件事:
- 检查NPU设备是否可见:
ls /dev/davinci*
正常应该能看到davinci0到davinci3,还有davinci_manager,少一个都不行。如果看不到,可能是宿主机驱动没装好,或者容器启动时没加--device参数。
- 检查环境变量:
echo $ASCEND_VISIBLE_DEVICES
应该输出0,1,2,3,和你启动容器时设置的一致。
- 检查模型文件是否挂载成功:
ls /models/Qwen3-30B-A3B-Instruct-2507
确保能看到model-00001-of-00016.safetensors、tokenizer.json、config.json这些文件,少一个都可能启动失败。
第三步:修改MindIE配置文件
MindIE的配置文件在/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json,这是整个部署的核心,很多错误都出自这里。
用vi打开配置文件,重点改这些地方:
- ServerConfig部分:
"ServerConfig": {
"allowAllZeroIpListening": true, // 允许绑定0.0.0.0,局域网访问需要
"ipAddress": "0.0.0.0", // 绑定所有网络接口
"port": 7025, // 业务端口,选个没被占用的
"managementPort": 7026,
"metricsPort": 7027,
"httpsEnabled": false, // 先关HTTPS,不然要配置证书
"maxLinkNum": 1000,
"inferMode": "standard",
"interCommTLSEnabled": false // 关了TLS,省得配置证书
}
- BackendConfig部分:
"BackendConfig": {
"backendName": "mindieservice_llm_engine",
"modelInstanceNumber": 1,
"npuDeviceIds": [[0,1,2,3]], // 和你实际的卡数一致
"tokenizerProcessNumber": 8,
"multiNodesInferEnabled": false,
"ModelDeployConfig": {
"maxSeqLen": 2560, // 模型最大序列长度,别超过模型本身支持的
"maxInputTokenLen": 2048,
"truncation": false,
"ModelConfig": [
{
"modelInstanceType": "Standard",
"modelName": "qwen", // 关键!必须填模型类型,不能瞎写
"modelWeightPath": "/models/Qwen3-30B-A3B-Instruct-2507", // 模型路径要对
"worldSize": 4, // 和卡数一致,4张卡就填4
"cpuMemSize": 5,
"npuMemSize": -1,
"backendType": "atb",
"trustRemoteCode": true // Qwen必须开这个,不然加载失败
}
]
}
}
这里踩过的坑:
- 一开始把
modelName写成了自定义名称,结果MindIE找不到对应的Tokenizer,报了Tokenizer class Qwen2Tokenizer does not exist错误 worldSize和npuDeviceIds的数量必须一致,我试过填4但只挂载了3张卡,直接启动失败- 忘记开
trustRemoteCode: true,Qwen模型加载时会报“远程代码不允许”的错误
完整配置文件:
{
"Version" : "1.0.0",
"ServerConfig" :
{
"ipAddress" : "127.0.0.1",
"managementIpAddress" : "127.0.0.2",
"port" : 1025,
"managementPort" : 1026,
"metricsPort" : 1027,
"allowAllZeroIpListening" : false,
"maxLinkNum" : 1000,
"httpsEnabled" : false,
"fullTextEnabled" : false,
"tlsCaFile" : ["ca.pem"],
"tlsCert" : "security/certs/server.pem",
"tlsPk" : "security/keys/server.key.pem",
"tlsPkPwd" : "security/pass/key_pwd.txt",
"tlsCrlPath" : "security/certs/",
"tlsCrlFiles" : ["server_crl.pem"],
"managementTlsCaFile" : ["management_ca.pem"],
"managementTlsCert" : "security/certs/management/server.pem",
"managementTlsPk" : "security/keys/management/server.key.pem",
"managementTlsPkPwd" : "security/pass/management/key_pwd.txt",
"managementTlsCrlPath" : "security/management/certs/",
"managementTlsCrlFiles" : ["server_crl.pem"],
"kmcKsfStandby" : "tools/pmt/standby/ksfb",
"inferMode" : "standard",
"interCommTLSEnabled" : false,
"interCommPort" : 1121,
"interCommTlsCaFiles" : ["ca.pem"],
"interCommTlsCert" : "security/grpc/certs/server.pem",
"interCommPk" : "security/grpc/keys/server.key.pem",
"interCommPkPwd" : "security/grpc/pass/key_pwd.txt",
"interCommTlsCrlPath" : "security/grpc/certs/",
"interCommTlsCrlFiles" : ["server_crl.pem"],
"openAiSupport" : "vllm",
"tokenTimeout" : 600,
"e2eTimeout" : 600,
"distDPServerEnabled":false
},
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1,
"npuDeviceIds" : [[0,1,2,3]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : false,
"interNodeTlsCert" : "security/grpc/certs/server.pem",
"interNodeTlsPk" : "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrlPath" : "security/grpc/certs/",
"interNodeTlsCrlFiles" : ["server_crl.pem"],
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb",
"ModelDeployConfig" :
{
"maxSeqLen" : 2560,
"maxInputTokenLen" : 2048,
"truncation" : false,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "Qwen3-30B-A3B",
"modelWeightPath" : "/models/Qwen3-30B-A3B-Instruct-2507",
"worldSize" : 4,
"cpuMemSize" : 5,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false
}
]
},
"ScheduleConfig" :
{
"templateType" : "Standard",
"templateName" : "Standard_LLM",
"cacheBlockSize" : 128,
"maxPrefillBatchSize" : 50,
"maxPrefillTokens" : 8192,
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 200,
"maxIterTimes" : 512,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000
}
}
}
第四步:解决Tokenizer加载问题
这是最折磨人的一步,我在这里卡了整整一天。启动服务时总是报safe_get_tokenizer_from_pretrained failed,日志里说找不到Tokenizer。
错误1:权限不足
日志里明确提示make sure the folder's owner has execute permission,但容器里模型目录是只读挂载,改不了权限。解决办法:
- 重新启动容器时把模型挂载改成
rw权限(前面提过) - 宿主机上给模型目录加权限:
chmod -R 755 /devdata/Qwen3-30B-A3B-Instruct-2507
错误2:tokenizer.json文件损坏
用Python手动测试时出现data did not match any variant of untagged enum ModelWrapper,这说明tokenizer文件有问题。解决办法:
- 从Hugging Face官方仓库重新下载Qwen的
tokenizer.json和tokenizer_config.json - 替换到模型目录,注意要和模型版本匹配(30B的别下成7B的)
第五步:启动服务并解决启动错误
配置都改好后,启动服务:
cd /usr/local/Ascend/mindie/latest/mindie-service
./bin/mindieservice_daemon
这时候可能遇到的错误:
错误1:端口被占用
日志里会有Address already in use,解决办法:
- 用
netstat -tulnp | grep 7025找到占用端口的进程(如果没netstat,先装yum install -y net-tools) - 用
kill -9 进程ID杀掉占用进程 - 或者修改
config.json里的port换个端口
错误2:配置文件有重复项
我之前不小心在ServerConfig里写了两个allowAllZeroIpListening,导致服务识别成false,报Input ipAddress [0.0.0.0] is invalid。解决办法:
- 仔细检查配置文件,确保没有重复的键
- 保持
allowAllZeroIpListening: true唯一且正确
错误3:TLS配置错误
如果没关httpsEnabled,又没配置证书,会报一堆tlsCert path is invalid的错误。解决办法:
- 要么把
httpsEnabled设为false,并注释所有tls相关配置 - 要么准备好证书文件,并正确配置路径
第六步:验证服务是否正常运行
服务启动后,先检查进程是否存在:
ps aux | grep mindieservice_daemon
然后检查端口是否监听:
lsof -i :7025 # 安装lsof:yum install -y lsof
正常应该能看到LISTEN状态,并且监听地址是0.0.0.0(局域网访问需要)。
最后用curl测试生成功能:
curl http://127.0.0.1:7025/generate \
--header "Content-Type: application/json" \
--data '{"prompt": "你好,我叫小明,", "max_tokens": 20}'
如果返回类似{"text":["你好,我叫小明,很高兴认识你。我是一个人工智能助手,"]}的结果,恭喜你,部署成功了!
第七步:配置局域网访问
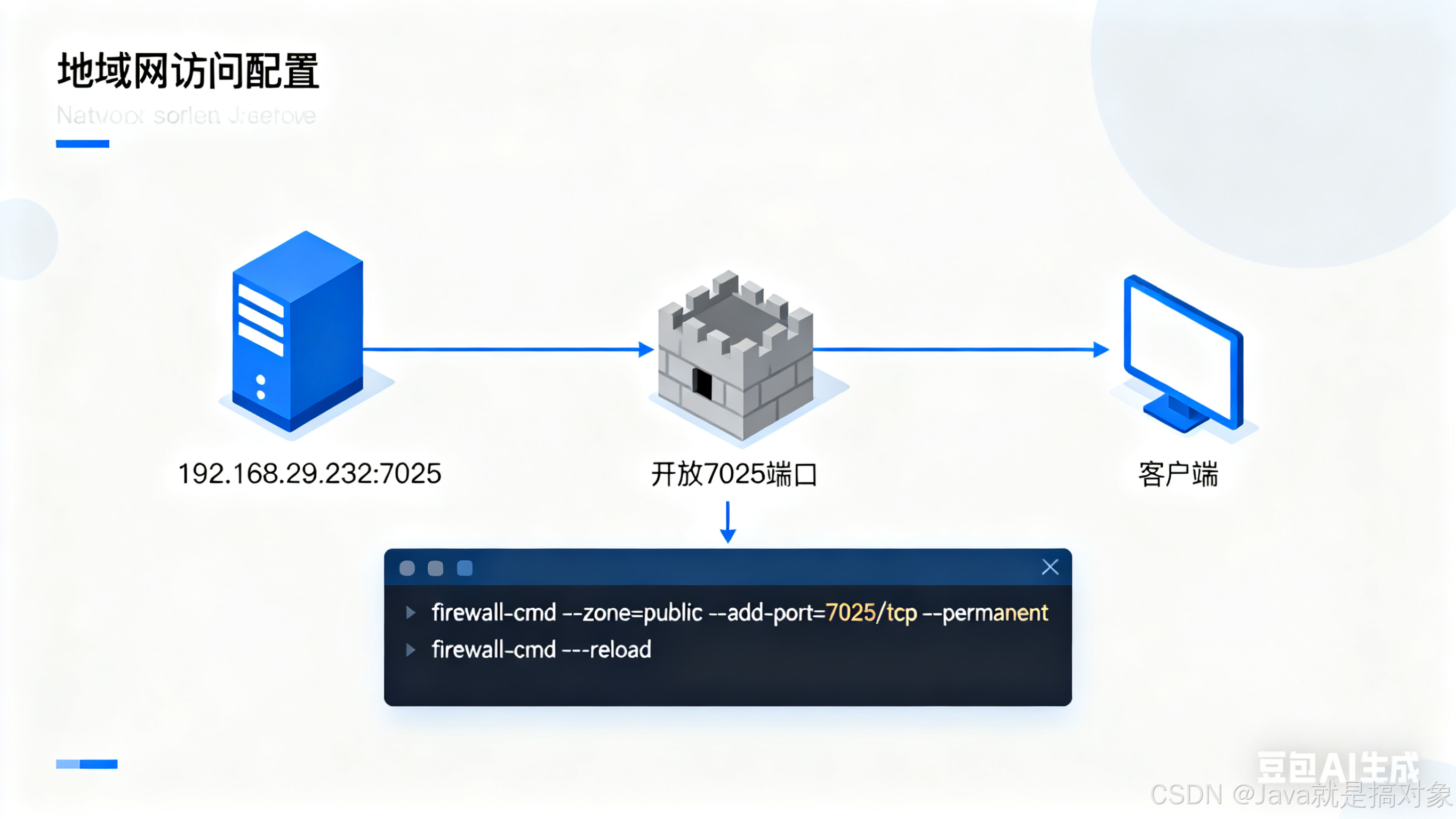
默认情况下服务可能只监听127.0.0.1,局域网其他设备访问不了,需要:
- 确保
config.json里ipAddress: "0.0.0.0"和allowAllZeroIpListening: true - 宿主机开放端口(以firewalld为例):
firewall-cmd --add-port=7025/tcp --permanent
firewall-cmd --reload
- 重启服务让配置生效:
pkill mindieservice_daemon
./bin/mindieservice_daemon
然后在局域网其他设备上用宿主机IP测试:
curl http://192.168.29.232:7025/generate \
--header "Content-Type: application/json" \
--data '{"prompt": "介绍一下昇腾芯片", "max_tokens": 50}'
一些优化建议
- 调整日志级别:默认日志输出太多,影响启动速度,修改环境变量:
export MINDIE_LOG_LEVEL="info"
export ASCEND_GLOBAL_LOG_LEVEL=1
-
合理分配卡数:30B模型用4张卡刚好,每张卡大概占用20GB内存,别用太少卡导致OOM。
-
设置合适的序列长度:根据实际需求调整
maxSeqLen,太长会占用更多内存,太短影响生成效果。 -
定期清理缓存:Hugging Face的缓存会越来越大,定期清理
~/.cache/huggingface/hub/释放空间。
总结
整个部署过程虽然踩了很多坑,但主要问题集中在这几个方面:
- 容器启动时的设备和路径挂载
- 配置文件中的参数匹配(卡数、模型路径、名称)
- Tokenizer文件的完整性和兼容性
- 端口占用和网络配置
只要一步步排查,确保每个环节都验证通过,其实也不算太难。最后成功看到模型生成结果的那一刻,还是挺有成就感的。
希望这篇文章能帮到正在折腾MindIE部署的朋友,有问题欢迎在评论区交流,我会尽量回复~

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)