
Ascend C 算子开发全流程实战:从工程创建到性能调优
以实现MulAddalpha为 float 类型属性,数据类型为 half)为例,完整演示工程创建与配置步骤。创建,明确输入、输出、属性及硬件实现方式:json"input": [],],"attr": [],Ascend C 作为昇腾社区算子开发的核心技术,其学习曲线虽有挑战,但通过工程化实践 + 性能调优方法论的结合,开发者可快速掌握其精髓。昇腾社区官网()提供了更详细的 API 文档与示例,
昇腾社区 Ascend C 算子开发全流程实战:从工程创建到性能调优
昇腾社区围绕 CANN(Compute Architecture for Neural Networks)生态构建了完善的算子开发工具链,Ascend C作为面向 AI 芯片原生的编程范式,是开发者挖掘硬件算力的核心技术抓手。本文将从基础概念辨析、工程实践操作、性能优化分析三个维度,全方位解析 Ascend C 算子开发的核心流程与技术细节,助力开发者高效完成算子从创建到调优的全生命周期管理。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
一、Ascend C 基础概念深度辨析
(一)核心编程范式与 API 分类
Ascend C 以矢量编程范式为核心,将算子执行拆解为 **CopyIn(数据入队)、Compute(核心计算)、CopyOut(数据出队)** 三级流水任务。配合Queue(任务队列,解决写后读同步)、TPosition(逻辑位置抽象,隐藏硬件存储细节)、LocalTensor/GlobalTensor(内存管理,区分片上 / 片外内存)等组件,实现硬件资源的高效调度。
从 API 层级划分,Ascend C 包含三类核心接口:
- 基础 API:如
DataCopy(数据搬运)、AllocTensor/FreeTensor(内存分配释放),负责底层资源管理; - 高阶 API:如
Matmul(矩阵乘法)、Softmax(归一化计算),封装复杂算法逻辑; - 硬件加速 API:如
__aicore__(核函数硬件标识)、Pipe(任务管道调度),直接对接 AI Core 硬件特性。
(二)关键技术概念辨析
| 概念 | 定义与作用 | 典型应用场景 |
|---|---|---|
| Tiling | 数据分片优化技术,将大张量切分为匹配 AI Core 计算能力的小分片 | 大矩阵乘法、卷积运算 |
| ISASI | 硬件兼容层接口,部分 API 可保证跨昇腾硬件(如 Kirin9020/KirinX90)版本兼容 | 多硬件平台算子迁移 |
| 核函数 | 用__aicore__标识的函数,在 AI Core 上执行,是性能优化的核心载体 |
自定义算子的计算逻辑实现 |
二、Ascend C 算子工程实战:从创建到调试
(一)自定义算子工程全流程创建
以实现MulAdd算子(功能:z = x * alpha + y,alpha为 float 类型属性,数据类型为 half)为例,完整演示工程创建与配置步骤。
1. 算子原型定义(JSON 文件)
创建mul_add_custom.json,明确输入、输出、属性及硬件实现方式:
json
{
"op": "MulAdd",
"input": [
{"name": "x", "dtype": ["half"], "format": ["ND"]},
{"name": "y", "dtype": ["half"], "format": ["ND"]}
],
"output": [
{"name": "z", "dtype": ["half"], "format": ["ND"]}
],
"attr": [
{"name": "alpha", "dtype": "float", "default_value": 0.5}
],
"op_impl": {
"ai_core": {
"kernel": "mul_add_custom",
"enable_tiling": true
}
}
}
2. 工程生成与环境配置
通过msOpGen工具生成工程,需先加载 Ascend C 环境变量:
bash
# 加载Ascend C环境变量
source ddk/tools/tools_ascendc/set_ascendc_env.sh
# 生成算子工程
msOpGen -i /path/to/mul_add_custom.json -c ai_core-kirin9020 -out /path/to/MulAdd_Project
生成的工程包含两个核心文件:
op_kernel/mul_add_custom.cpp:实现核函数的CopyIn/Compute/CopyOut三级流水逻辑;op_host/mul_add_custom_tiling.h:定义Tiling 数据结构与分片参数计算函数,用于优化数据分片粒度。
(二)核函数实现与 CPU 孪生调试
1. Compute 函数核心逻辑
在mul_add_custom.cpp中,补充Compute函数实现x * alpha + y的计算逻辑:
cpp
运行
__aicore__ inline void KernelMulAdd::Compute(int32_t progress) {
// 从输入队列获取LocalTensor(片上内存数据)
AscendC::LocalTensor<half> xLocal = inQueueX.DeQue<half>();
AscendC::LocalTensor<half> yLocal = inQueueY.DeQue<half>();
// 分配临时与输出LocalTensor
AscendC::LocalTensor<half> tempLocal = outQueueZ.AllocTensor<half>();
AscendC::LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 执行x*alpha + y的计算(调用Ascend C高阶API)
half alphaHalf = static_cast<half>(this->alpha);
AscendC::Mul(tempLocal, xLocal, alphaHalf, this->tileLength);
AscendC::Add(zLocal, tempLocal, yLocal, this->tileLength);
// 数据入队与内存释放
outQueueZ.EnQue<half>(zLocal);
outQueueZ.FreeTensor(tempLocal);
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
2. CPU 孪生调试与精度比对
使用ascendebug工具进行CPU 孪生调试,命令如下:
bash
ascendebug kernel --backend cpu --chip-version kirin9020 --json-file /path/to/mul_add_custom.json --work-dir /path/to/debug_dir
精度比对配置:在调试配置文件中指定golden_data_path,指向预处理的标杆数据文件(bin 格式),工具会自动比对输出结果与标杆数据的误差。
若结果存在偏差,可通过以下手段排查:
- 打印调试:通过
printf输出标量参数(如alpha值),验证参数传递逻辑; - 张量 Dump:调用
DumpTensor(zLocal)保存输出张量数据,与标杆数据逐元素比对; - 断言检查:用
assert(xLocal.GetLength() == this->tileLength)验证数据分片逻辑的正确性。
三、Ascend C 算子性能优化深度分析
(一)Matmul 算子优化案例:从分核到大包搬运
某开发者实现 Matmul 算子时,通过 Profiling 工具发现aic_mte2_ratio(内存带宽利用率)高达 0.92,执行时间为 11200us。通过多轮优化,性能得到显著提升,优化前后参数对比如表:
| 优化措施 | 分核数 | 基本块参数(baseM/baseN) | 大包搬运 | 执行时间(us) |
|---|---|---|---|---|
| 优化前 | 4 | 64/64 | 关闭 | 11200 |
| 优化分核逻辑 | 20 | 64/64 | 关闭 | 2350 |
| 优化基本块切分 | 20 | 128/256 | 关闭 | 810 |
| 开启大包搬运 | 20 | 128/256 | 开启 | 620 |
1. 分核逻辑优化的原理
aic_mte2_ratio过高说明内存带宽已成为性能瓶颈。分核数从 4 提升到 20 后,每个核的计算负载更均衡,减少了内存访问的串行等待时间,因此性能提升约 5 倍。
2. 基本块切分的理论与实际收益
理论收益公式:
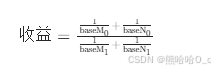
代入数据(优化前baseM=64、baseN=64;优化后baseM=128、baseN=256):
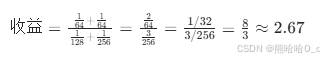
实际收益(从 2350us 到 810us,约 2.9 倍)与理论值存在差异,原因是实际硬件存在缓存命中率、指令流水效率等动态因素,理论模型未完全覆盖这些细节。
3. 大包搬运的优化机制
CANN 7.0.0 支持大包搬运(Large Packet Transfer),可将多次小粒度数据搬运合并为一次大粒度搬运,减少内存访问的指令开销,从而降低aic_mte2_ratio,提升整体吞吐量。
(二)大模型算子痛点解决方案(以 FlashAttention 为例)
在 LLaMA-Factory 框架适配昇腾时,自定义 FlashAttention 算子常出现三类典型问题,结合 CANN 7.0.0 特性的解决方案如下:
| 问题现象 | 解决方案与理论依据 |
|---|---|
| 长序列(8192 tokens)内存溢出 | 启用选择性重计算,通过AscendC::Recompute接口标记可重计算的中间张量,运行时按需重新生成,减少内存占用 |
| BFLOAT16 精度不达标 | 替换为 CANN 优化的BFloat16 高阶 API(如BFloat16Matmul),底层针对昇腾硬件做精度补偿 |
| 多卡并行 All-to-All 通信带宽低 | 采用通信与计算并发,通过Pipe管道将通信任务与计算任务并行调度,隐藏通信延迟 |
结语
Ascend C 作为昇腾社区算子开发的核心技术,其学习曲线虽有挑战,但通过工程化实践 + 性能调优方法论的结合,开发者可快速掌握其精髓。昇腾社区官网(https://www.hiascend.com/document/detail/zh/canncommercial/700/operatordev/Ascendcopdevg/atlas_ascendc_10_0006.html)提供了更详细的 API 文档与示例,建议开发者深入研读,持续打磨算子性能,为昇腾 AI 生态贡献价值。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)