
SGLang框架:原理、优化与比较分析
SGLang是一个针对大型语言模型和视觉语言模型的高效推理框架,通过协同优化前后端架构提升性能。其核心特性包括:高效的RadixAttention前缀缓存、FP8量化推理、多节点张量并行等技术优化计算效率;支持多模态输入和结构化生成的X-Grammar功能;以及通过Rust重构的智能负载均衡器降低服务开销。在DeepSeek模型优化中,SGLang解决了MLA架构冗余计算、高并发内存瓶颈等问题,使
作者:昇腾实战派
背景概述
随着大型语言模型和视觉语言模型的广泛应用,高效推理框架成为支撑实际部署的关键。传统推理引擎在应对高并发、多模态和复杂交互场景时,常面临计算冗余、内存瓶颈和调度开销等挑战。SGLang作为一种新兴的推理框架,通过协同设计后端运行时与前端语言,致力于提升交互速度与控制灵活性,为开发者提供更高效的模型服务能力。本文将从核心特性、性能优化及对比分析等角度,系统介绍SGLang的技术架构与应用实践。
SGLang核心特性
SGLang 是一个用于大型语言模型和视觉语言模型的快速服务框架。它通过共同设计后端运行时和前端语言,使你与模型的交互更快、更可控。其核心功能包括:
- 快速后端运行时: 提供高效的服务,包括 RadixAttention 用于前缀缓存、跳跃式约束解码、连续批处理、令牌注意力(分页注意力)、张量并行、FlashInfer 内核、分块预填充和量化(INT4/FP8/AWQ/GPTQ)。
- 灵活的前端语言: 提供直观的界面用于编程 LLM 应用程序,包括链式生成调用、高级提示、控制流、多模态输入、并行性和外部交互。
- 广泛的模型支持: 支持各种生成模型(Llama 3、Gemma 2、Mistral、QWen、DeepSeek、LLaVA 等)和嵌入模型(e5-mistral),并易于扩展以集成新模型。
- 活跃的社区: SGLang 是开源的,并由一个活跃的社区支持,并在行业中得到应用。
SGLang的发展
参考:当开源创新遇上推理革命:SGLang如何炼就DeepSeek最强开源推理引擎?|推理|内存_新浪科技_新浪网
deepseek模型优化和架构适配
一、MLA 解码计算效率问题
- 问题
- DeepSeek V2 的 Multi-head Latent Attention(MLA)架构在解码过程中存在冗余计算,导致计算负载高、延迟大。
- MLA 解码核设计仅保留一个 KV 头,导致对 KV Cache 的内存访问频繁,成为性能瓶颈。
- 解决方法
- 权重重排优化:使用权重吸收技术重新排列计算步骤,平衡计算与内存访问负载。
- Triton 解码核优化:开发 Triton 内核,在同一计算块内并行处理多个 query 头,减少 KV Cache 访问次数。
- FP8 量化推理:结合 W8A8 FP8、KV Cache FP8 量化技术,开发定制 FP8 批量矩阵乘法(BMM)算子。
- 编译优化:兼容 CUDA Graph 和 Torch.compile,降低小批量推理时的调度开销。
- 效果
- 计算量降低:解码过程中的冗余计算显著减少,提升计算效率。
- 内存访问优化:KV Cache 访问次数减少,解码延迟降低。
- 吞吐率提升:DeepSeek 系列模型的输出吞吐率最高提升 7 倍。
二、高并发场景下的内存与吞吐量问题
- 问题
- 传统注意力机制在处理高并发请求(如 prefill、decode 混合场景)时,KV Cache 重复存储导致内存浪费,吞吐量受限。
- 解决方法
- **数据并行注意力(DP Attention)**:将不同类型的 batch(prefill、decode、extend、idle)分配给独立数据并行单元处理,仅在 MoE 层前后同步。
- 命令行启用:用户可通过
--enable-dp-attention参数一键启用该优化。
- 效果
- 内存优化:KV Cache 重复存储减少,内存利用率显著提升。
- 吞吐量提升:支持更大批量请求的并行处理,特别适合高 QPS(Queries Per Second)场景。
三、单节点内存瓶颈问题
- 问题
- 超大规模模型(如 DeepSeek V3)参数量超过单节点 GPU 内存容量,无法完整部署。
- 解决方法
- **多节点张量并行(MTP)**:将模型参数跨多个 GPU 或节点进行分区部署,通过张量并行技术协同计算。
- 灵活配置:支持集群环境下的动态节点扩展,适应不同资源规模。
- 效果
- 突破内存限制:支持超大规模模型在多节点集群上高效推理。
- 资源利用率优化:避免单节点内存不足导致的计算资源浪费。
四、精度与计算效率平衡问题
- 问题
- 传统量化方法(如 INT8)在降低精度的同时可能影响模型性能,而 FP16/FP32 计算开销大。
- 解决方法
- 块级 FP8 量化:
- 激活值量化:采用 E4M3 格式,对每个 token 内 128 通道子向量在线 casting 并动态缩放。
- 权重量化:以 128×128 块为单位处理,捕捉权重分布特性。
- 默认启用:DeepSeek V3 模型默认集成该量化方案。
- 块级 FP8 量化:
- 效果
- 计算效率提升:FP8 计算比 FP16/FP32 更高效,降低计算成本。
- 精度保障:通过细粒度量化和动态缩放,在保持模型精度的同时实现高效推理。
调度器效能革命
一、传统推理引擎中 CPU 开销过高问题
- 问题
- 传统推理引擎中,CPU 需承担批调度、内存分配、前缀匹配等任务,导致高达 50% 的时间消耗在 CPU 开销上,GPU 因等待 CPU 调度而频繁闲置,整体推理性能受限。
- 解决方法
- CPU 与 GPU 计算重叠执行:批调度器提前一批次运行,在 GPU 处理当前任务时,同步准备下一批次的元数据(如 radix cache 匹配信息)。
- 隐藏调度开销:通过预调度机制,将 CPU 的调度工作(如前缀匹配、批分配)与 GPU 计算并行化,避免 GPU 等待。
- 效果
- GPU 利用率提升:Nsight profiling 测试显示,连续五个解码批次中 GPU 全程高负载,无空闲时段(基于 Triton attention 后端)。
- 性能显著提升:在 batch size 较大场景下,相比上一版本推理效率明显提高,尤其在小模型和大规模张量并行场景中优化效果突出。
- 零配置启用:该技术默认集成于 SGLang v0.4,用户无需额外参数配置即可享受性能优化。
多模态:视觉语言协同加速
一、多模态数据处理效率与兼容性问题
- 问题
- 传统推理方案难以同时高效处理单图像、多图像及视频等多模态任务,且不同模态数据的协同处理能力不足,API 接口不统一导致开发复杂度高。
- 解决方法
- 多模态技术深度集成:与国内外顶尖团队合作,将视觉处理(如图像、视频分析)与语言模型推理能力无缝整合至 SGLang 框架。
- 统一兼容的视觉 API:提供 OpenAI 兼容接口,支持纯文本、文本 - 图像 - 视频混合输入,无需额外开发即可处理多模态数据。
- 高效 Runtime 调度:通过 SGLang Runtime 的轻量化设计和调度优化,实现多类型数据的并行处理。
- 效果
- 性能显著提升:在 VideoDetailDescriptions 和 LLaVA-in-the-wild 数据集上,多模态模型推理性能较 HuggingFace/transformers 原始实现最高提升 4.5 倍。
- 多场景覆盖:支持单图像、多图像及视频任务,在三大计算机视觉场景中实现先进性能。
- 开发便捷性:用户可通过统一 API 调用多模态推理功能,降低应用开发成本。
二、多模态模型扩展与兼容性问题
- 问题
- 传统框架对多模态模型(如 cosmos 世界模型、流式模型)的支持滞后,难以快速适配新型号。
- 解决方法
- 开放开发者生态:邀请开发者重构代码,扩展对 cosmos 世界模型、-o 流式模型等新型多模态模型的支持。
- 交互式输入优化:针对文本、图像、视频的交互式输入场景,优化模型推理流程。
- 效果
- 模型兼容性增强:已实现对主流多模态模型的支持,并持续扩展新型号适配能力。
- 应用场景拓展:为复杂多模态应用(如交互式视频分析、图文协同理解)提供技术保障。
X-Grammar:结构化生成的范式重构
一、传统约束解码的上下文依赖处理低效问题
- 问题
- 传统约束解码在处理复杂语法时,上下文依赖导致大量冗余 token 计算,状态切换开销大,解码效率低。
- 解决方法
- 上下文信息检测增强:XGrammar 为每条语法规则添加额外上下文信息检测,提前识别规则隐含的语义信息,减少依赖 token 数量。
- 效果
- 解码过程中不必要的状态切换开销降低,复杂语法处理效率显著提升。
二、多路径执行状态管理复杂问题
- 问题
- 多条扩展路径产生的执行状态难以高效管理,拆分与合并操作易导致数据结构不稳定,影响解码流畅性。
- 解决方法
- 树结构持久化执行栈:采用树状数据结构管理执行状态,支持多执行栈高效维护,确保拆分合并操作的稳定性。
- 效果
- 多路径解码状态管理效率提升,解码流程保持流畅,支持复杂结构化生成。
三、下推自动机结构冗余问题
- 问题
- 传统下推自动机存在冗余状态节点,语法规则匹配与转换速度慢,制约解码效率。
- 解决方法
- 自动机节点精简优化:借鉴编译器内联优化和等价状态合并技术,减少自动机中不必要的状态节点。
- 效果
- 语法规则匹配与转换速度显著提升,解码效率进一步提高。
四、语法编译过程串行化效率问题
- 问题
- 语法编译过程采用串行化处理,无法充分利用多核 CPU 计算能力,编译时间长。
- 解决方法
- 编译任务并行化:将语法规则编译任务分配至多个 CPU 核心同时执行,实现并行化处理。
- 效果
- 语法编译时间大幅缩短,为多任务解析奠定高效基础。
Cache-Aware Load Balancer:智能路由的架构突破
一、传统负载均衡的服务开销过高问题
- 问题
- 传统推理系统的负载均衡器多采用 Python 开发,服务开销大,难以满足大模型高并发推理的效率需求。
- 解决方法
- Rust 重构负载均衡器:使用 Rust 语言重写负载均衡器,利用其高性能、低内存开销的特性减少 Service Overhead。
- 效果
- 相比 Python 实现,服务开销显著降低,为高并发推理提供高效底层支持。
二、负载均衡策略不智能导致的吞吐量瓶颈问题
- 问题
- 传统轮询调度方式不考虑节点缓存状态,导致 KV 缓存命中率低、吞吐量不足,尤其在多节点场景下性能衰减明显。
- 解决方法
- 基于字符级前缀匹配的智能路由:
- 采用 Radix Tree 实现无需 Tokenization 的前缀匹配,直接基于字符级输入快速路由请求。
- 动态评估各节点的前缀 KV 缓存命中率,优先将请求分配至命中率高的节点。
- 基于字符级前缀匹配的智能路由:
- 效果
- 吞吐量提升:实际测试中吞吐量最高提升近 2 倍。
- 缓存命中率优化:缓存命中率较传统方式提升近 4 倍,节点数量越多优势越明显。
三、缓存资源管理低效导致的内存膨胀问题
- 问题
- 多节点缓存资源缺乏有效管理,低频访问的缓存数据占用内存,导致树结构效率下降。
- 解决方法
- 懒更新 LRU 淘汰策略:
- 对 Radix Tree 中访问频率低的叶子节点定期清理,采用懒更新机制避免实时删除开销。
- 动态维护树结构,防止内存过度膨胀。
- 懒更新 LRU 淘汰策略:
- 效果
- 内存使用效率优化,缓存性能保持稳定,避免因缓存膨胀导致的推理延迟。
四、分布式部署中动态扩缩容效率问题
- 问题
- 传统负载均衡器难以支持集群节点的快速扩缩容,影响大规模服务的弹性伸缩能力。
- 解决方法
- HTTP 接口秒级动态扩缩容:通过 HTTP 接口实现集群节点的实时增减,负载均衡器自动重新分配路由策略。
- 效果
- 多节点集群中吞吐性能呈现近线性扩展趋势,支持大规模在线服务的弹性部署,保障性能与可靠性。
开发者工具链
一、开发者迁移成本高与接口兼容性问题
- 问题
- 传统推理框架与 OpenAI API 接口不兼容,开发者迁移成本高,需重写大量代码。
- 解决方法
- OpenAI API 兼容接口层:提供与 OpenAI 完全兼容的接口(Chat、Completions、Embeddings 等),开发者仅需替换端点即可完成迁移。
- 效果
- 大幅降低迁移成本,实现无缝迁移,减少开发工作量。
二、多节点部署运维复杂问题
- 问题
- 传统多节点推理需独立服务化部署,运维成本高,灵活性不足。
- 解决方法
- **离线引擎模式(Offline Engine)**:支持单脚本驱动多节点推理,无需部署独立服务,简化运维流程。
- 效果
- 运维成本显著降低,部署方式更灵活,适应不同规模的推理需求。
三、模型状态监控与调优困难问题
- 问题
- 缺乏实时监控工具,难以追踪推理性能指标(如吞吐量、延迟、显存使用),调优效率低。
- 解决方法
- Prometheus 监控集成:内置监控系统,实时追踪吞吐量、延迟、GPU 内存压力等核心指标,支持精细化调优。
- 效果
- 开发者可实时掌握模型状态,基于数据进行调优,提升推理效率与稳定性。
四、显存利用率低与 LoRA 切换不便问题
- 问题
- 多 LoRA 适配器切换时显存占用高,无法高效复用,且需重启服务,影响可用性。
- 解决方法
- **多 LoRA 动态加载(Dynamic LoRA Switching)**:支持在显存复用率高达 90% 的情况下热切换不同 LoRA 适配器,无需重启服务。
- 效果
- 显存资源利用率最大化,支持灵活切换不同任务的 LoRA 模型,提升服务可用性与灵活性。
五、生成内容格式错误率高问题
- 问题
- 传统解码方式难以保证输出格式一致性,在 JSON、工具调用等场景中生成错误率高。
- 解决方法
- **约束解码(Constrained Decoding)**:提供 JSON、GBNF 等格式的强制校验能力,在解码过程中严格约束输出格式。
- 效果
- 生成错误率降至极低水平,满足生产场景对输出格式一致性的严格要求,减少后处理成本。
未来展望
目前,SGLang 在全球范围内已经汇聚了 30 余位核心贡献者。在接下来的 2025 H1 阶段中,团队将致力于完善实战场景下的 PD 分离、Speculative Decoding 的长文本优化、推动多级缓存(GPU/CPU/Disk)策略落地,并继续强化并行策略以适配千亿级 MoE 模型。除开本身推理效果的优化,SGLang 团队也将致力推理引擎的广泛落地,继续支持 RAG、multi-Agent、Reasoning、RLHF 等等领域的 AI 落地。最后,SGLang 也将在算子覆盖率与性能上持续优化,支持更多的更广泛的硬件,力争为开源社区提供更加先进的一站式大模型推理方案。
sglang和vllm比较
参考:
- SGLang:比vLLM吞吐还要大5倍的推理引擎 - 文章 - 开发者社区 - 火山引擎
- SGLang:LLM推理引擎发展新方向 - 极术社区 - 连接开发者与智能计算生态
- 大模型推理框架,SGLang和vLLM有哪些区别?
| 对比维度 | SGLang | vLLM |
|---|---|---|
| 技术亮点 | ・采用RadixAttention技术,基于基数树(Radix Tree)自动识别共享前缀的 KV 缓存,无需手动配置:被最近的各种新型推理引擎所采用,比如MoonCake,MemServe等 ・结合LRU淘汰策略和缓存感知调度,动态管理缓存资源,减少冗余计算 ・多轮对话、系统提示等共享前缀场景下,缓存复用率显著提升 ・嵌入式 PythonDSL,支持高级提示技术(如 branch-solve-merge)、控制流、多模态输入 ・示例:多维度论文评分器通过简洁 API 实现复杂逻辑,无需关注底层调用 |
・依赖PagedAttention ,continuous batching等技术优化 ・多卡并行优化(Zero Redundancy Tensor Parallelism):在多GPU环境下,vLLM用NCCL/MPI这些库高效地切分和同步模型权重,优化内存,提高计算效率。 |
| 性能表现 | ・基准测试中吞吐量较 vLLM 提升5倍(Mixtral-8x7B,A10G,FP16,张量并行 = 8) ・自动缓存重用 + 程序并行性,兼顾高吞吐量和低延迟 ・高并发下的表现:另一组用Llama3-70B-FP8在2块H100上的测试,更能说明问题。顺序请求时,SGLang(38tokens/s)比vLLM(35tokens/s)稍快一点。但到了并发请求场景,SGLang能稳定在30-31tokens/s,vLLM却从22tokens/s掉到了16tokens/s。Llama3.1-8B在单H100上的测试也差不多:并发下SGLang稳定在75-78tokens/s,vLLM从37tokens/s降到35tokens/s左右。这说明在高并发压力下,SGLang的稳定性和扩展性可能更好。 |
・TTFT(首字出词时间):在Llama3.170BFP8模型单H100上的测试里,vLLM的TTFT最快(123ms),比SGLang(340ms)和TensorRT(194ms)都好。看来对响应速度要求极高的场景,vLLM还是有优势。 |
| 应用场景适应性 | ・专为复杂场景设计:支持多轮规划(Multi-round Planning)、推理(Reasoning)、工具调用、多模态输入 ・原生兼容高级提示技术:Self-Consistency、Tree-of-Thought(ToT)、Skeleton-of-Thought 等 ・支持单 prompt 生成多结果、约束输出(如 JSON 格式、关键词限制) ・高并发、高吞吐:最新测试显示,尤其是在并发量大的时候,SGLang似乎能提供更稳定、更高的吞吐量。 |
・主要针对高吞吐单轮对话场景:输入 Prompt→Prefill+Decode→输出 ・资源有限但想要最大化吞吐:对于想要部署几十亿参数的模型,vLLM的Paged Attention对内存效率提升比较高。 ・快速集成:vLLM的API相对更成熟,集成起来更省事。 |
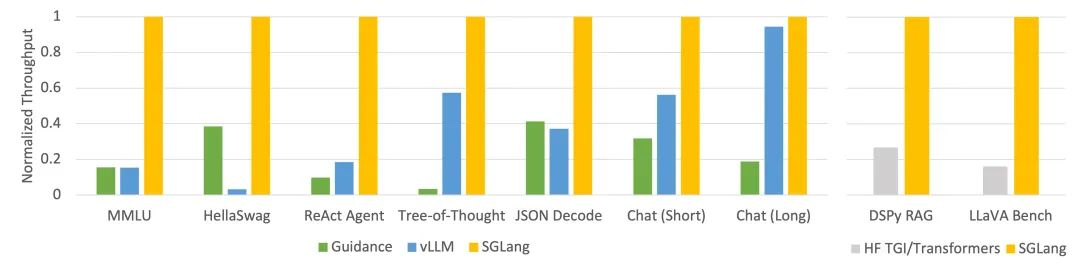
LLM 任务下不同系统 throughput(Llama-7B 在 A10G 上,FP16,张量并行=1)

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)