
vLLM-Ascend 推理服务构建与优化
vLLM-Ascend 推理服务构建与优化
一. 背景与核心指标
在推理服务中,核心关注点始终是吞吐量与延迟,它们直接影响模型的实际应用效果与用户体验。本文以实践记录的方式,深入讲解如何利用 vLLM-Ascend 构建高效的推理服务,从模型转换、任务调度到资源利用优化,涵盖离线批处理与在线实时服务等多种场景。通过系统性的实践分享,我将带大家了解如何在保证推理精度的前提下,最大化硬件性能,提升服务响应速度,并记录调优过程中遇到的问题与解决方案,为构建稳定、高效的 AI 推理平台提供可参考的经验。
1.1 推理服务的关键指标
吞吐量(Throughput):
- 定义:单位时间内处理的 Token 数量(tokens/sec)
- 适用场景:离线批处理、知识库构建
- 优化目标:最大化 GPU 利用率
延迟(Latency):
- TTFT:首个 Token 的生成时间,影响用户体验
- TPOT:后续 Token 的平均生成时间
- 适用场景:在线对话、实时 API 服务
- 优化目标:最小化响应时间
1.2 场景选择指南
不同的应用场景对推理服务有不同的需求:
|
场景 |
吞吐量 |
延迟 |
推荐模式 |
典型应用 |
|
离线批处理 |
高 |
低 |
Offline |
RAG、数据清洗、日志分析 |
|
在线对话 |
中 |
低 |
Online |
ChatBot、问答系统 |
|
API 服务 |
中 |
低 |
Online |
LLM API、集成服务 |
|
大规模推理 |
高 |
中 |
Distributed |
企业级应用 |
二. 离线推理(Offline Inference)
离线推理适用于对实时性要求不高,但追求极致吞吐量的场景,如 RAG 知识库构建、数据清洗等。
- 特点:通过
SamplingParams充分调度计算资源,尽可能增大 Batch Size,提升资源利用率。 - 实现:通过
vllm.LLM类,仅需少量代码即可启动推理引擎进行批处理。
基于 VLLM 框架的 vllm.LLM 类可快速实现离线批处理推理,仅需少量代码即可完成推理引擎初始化、批量请求调度与结果输出,核心代码示例如下:
from vllm import LLM, SamplingParams
import time
# 1. 配置采样参数(适配离线场景,最大化批量处理效率)
sampling_params = SamplingParams(
max_tokens=100, # 单条请求生成长度上限
temperature=0.1, # 低随机性,适配数据清洗/知识库构建的确定性需求
top_p=0.9, # 采样策略,保证生成内容的稳定性
batch_size=256 # 显式指定批量大小(根据硬件显存调整)
)
# 2. 初始化VLLM推理引擎(适配离线场景的资源配置)
llm = LLM(
model="your-model-path", # 本地模型路径/开源模型名(如 "Qwen/Qwen-7B-Chat")
tensor_parallel_size=4, # 多卡并行(根据硬件配置调整)
gpu_memory_utilization=0.95, # 最大化显存利用率(离线场景无资源预留需求)
max_num_batched_tokens=8192, # 单批次最大token数,提升吞吐量
disable_log_requests=True # 关闭请求日志,减少资源消耗
)
# 3. 加载离线批量请求(示例:RAG知识库构建的批量文本处理)
with open("offline_texts.txt", "r", encoding="utf-8") as f:
prompts = [f"基于以下文本提取核心信息:{line.strip()}" for line in f if line.strip()]
# 4. 执行离线批处理推理
start_time = time.time()
outputs = llm.generate(prompts, sampling_params)
end_time = time.time()
# 5. 结果处理与输出(适配离线场景的批量存储)
results = []
for output in outputs:
results.append({
"prompt": output.prompt,
"generated_text": output.outputs[0].text,
"finish_reason": output.outputs[0].finish_reason
})
# 将结果写入文件,完成离线任务
with open("offline_inference_results.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 吞吐量统计(离线场景核心指标)
total_tokens = sum([len(output.outputs[0].token_ids) for output in outputs])
throughput = total_tokens / (end_time - start_time)
print(f"离线推理完成,总处理请求数:{len(prompts)},总生成Token数:{total_tokens},吞吐量:{throughput:.2f} tokens/s")运行效果:

三. 在线服务(Online Serving)
对于在线对话、API 服务等场景,vLLM 提供了兼容 OpenAI 协议的 API Server,方便用户快速集成。
3.1 OpenAI 兼容性
- 无缝迁移:vLLM 兼容 OpenAI 的 API 接口。这意味着现有的基于 OpenAI SDK 构建的应用,只需修改
base_url即可直接调用昇腾算力,无需修改业务代码。 - 启动方式:使用
vllm.entrypoints.openai.api_server模块即可启动服务。
测试代码:
# 文件名:start_vllm_server.py
from vllm.entrypoints.openai import api_server
if __name__ == "__main__":
# 启动本地 OpenAI 兼容 API 服务
# 默认在 http://0.0.0.0:8000
api_server.main()启动命令:
python start_vllm_server.py
启动后,你可以像调用 OpenAI API 一样调用本地服务,例如用 Python requests:
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer fake-token" # vLLM 默认可使用任意 token
}
data = {
"model": "chat-bloom-7b1",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, vLLM!"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())3.2 调用示例
启动 VLLM OpenAI 兼容服务
vllm serve Qwen/Qwen2.5-7B-Instruct --port 8000 --host 0.0.0.0HTTP 客户端调用
在终端执行curl命令,向服务发送请求:
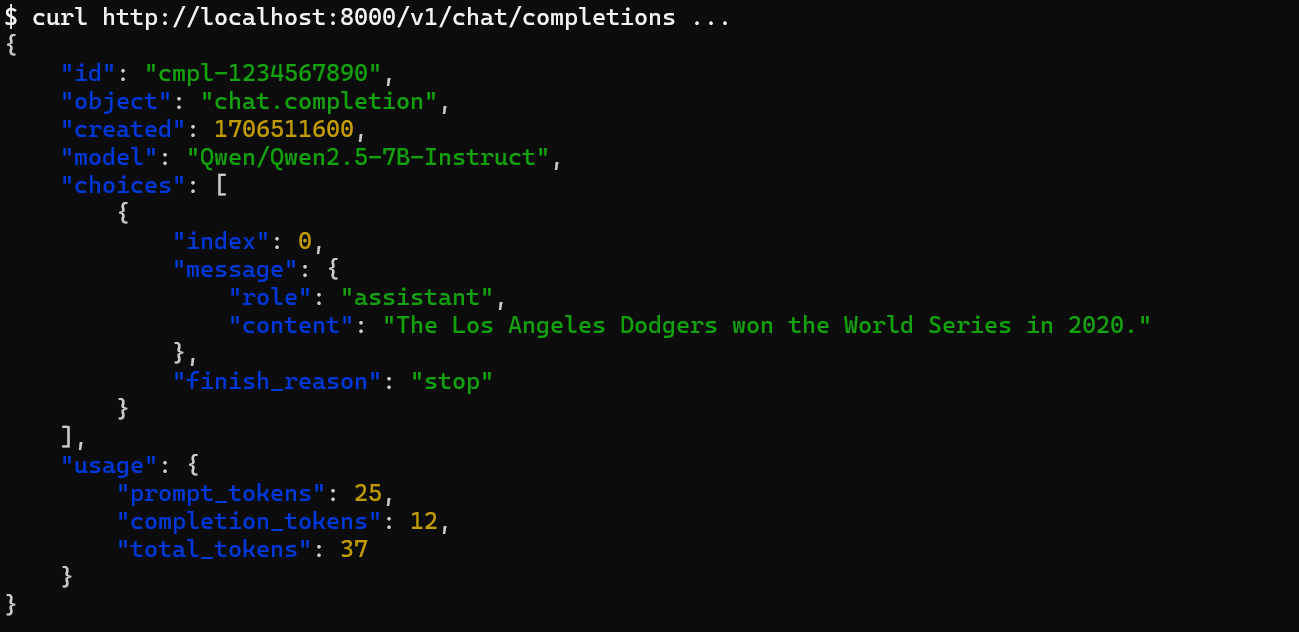
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{
"role": "user",
"content": "Which team won the World Series in 2020?"
}
],
"max_tokens": 50
}'请求结果:
Python SDK 调用
pip install openai编写test_openai_sdk.py代码:
from openai import OpenAI
# 配置客户端,指向本地VLLM服务
client = OpenAI(
base_url="http://localhost:8000/v1", # 本地VLLM服务地址
api_key="dummy_key" # VLLM兼容服务无需真实API Key,填任意值即可
)
# 发送聊天请求
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[
{"role": "user", "content": "写一首关于昇腾AI的七言诗"}
],
max_tokens=100
)
print(response)
print("\n--- Content ---")
print(response.choices[0].message.content)运行代码:
python test_openai_sdk.py
四. 分布式推理(Distributed Inference)
随着模型参数量的增加(如 72B、100B),单卡显存往往无法容纳整个模型。此时需要使用张量并行技术。
- 原理:将矩阵运算切分到多张 NPU 上并行执行,利用 HCCL进行卡间通信。
- 优势:
-
- 显存扩展:解决了单卡显存不足的问题。
- 性能提升:通过并行计算,显著提升了大模型的推理速度。
- 注意事项:多卡推理依赖于服务器内部的高速互联,需确保通信链路畅通。

五. 常见问题与注意事项
在构建服务时,需要注意以下几点以避免常见问题:
- 端口冲突:若使用
--net=host模式,需提前规划好端口,避免冲突。 - 冷启动耗时:首次推理会进行图编译,可能导致超时。建议在服务启动后进行预热。
- 模型名称匹配:客户端请求的
model参数必须与服务端加载的模型名称一致,否则会报错 400。
六. 性能优化策略
6.1 批处理大小优化
批处理大小是影响吞吐量的关键因素。
批处理大小的影响:
- 太小:无法充分利用 NPU 的计算能力,吞吐量低
- 太大:显存溢出,导致 OOM 错误
- 最优:在不溢出显存的前提下,尽可能大
找到最优批处理大小的方法:
# 二分搜索找到最大批处理大小
def find_max_batch_size(model_name, max_tokens=2048):
low, high = 1, 256
max_batch = 1
while low <= high:
mid = (low + high) // 2
try:
llm = LLM(model=model_name, tensor_parallel_size=1)
# 尝试处理 mid 个请求
prompts = ["Hello"] * mid
llm.generate(prompts, SamplingParams(max_tokens=max_tokens))
max_batch = mid
low = mid + 1
except RuntimeError as e:
if "out of memory" in str(e):
high = mid - 1
else:
raise
return max_batch6.2 内存管理优化
显存使用分析:
- 模型权重:占用显存的主要部分
- KV 缓存:随着序列长度增加而增加
- 激活值:前向传播过程中产生的中间结果
优化技巧:
- 使用量化模型:INT8 或 INT4 量化可以减少 75% 的显存占用
- 启用 PagedAttention:vLLM 默认启用,可以减少 KV 缓存的碎片化
- NPU显存比例:通过 npu_memory_utilization参数控制
6.3 推理优化
采样参数优化:
# 对话场景:优先考虑延迟
params_chat = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
use_beam_search=False # 关闭束搜索,降低延迟
)
# 文本生成场景:可以考虑更复杂的采样
params_generation = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=2048,
use_beam_search=True # 启用束搜索,提高质量
)预填充优化:
- 对于长提示词,vLLM 会在预填充阶段一次性处理所有 token
- 这个阶段可以充分利用 NPU 的并行能力
- 合理设计提示词可以提升性能
七. 监控和指标收集
7.1 性能监控
关键性能指标(KPI):
import time
from typing import List
class PerformanceMonitor:
def __init__(self):
self.requests = []
def record_request(self, prompt: str, response: str,
ttft: float, tpot: float):
"""记录单个请求的性能指标"""
self.requests.append({
'prompt_len': len(prompt.split()),
'response_len': len(response.split()),
'ttft': ttft, # Time To First Token
'tpot': tpot, # Time Per Output Token
'timestamp': time.time()
})
def get_stats(self):
"""计算统计指标"""
if not self.requests:
return {}
ttfts = [r['ttft'] for r in self.requests]
tpots = [r['tpot'] for r in self.requests]
return {
'avg_ttft': sum(ttfts) / len(ttfts),
'p99_ttft': sorted(ttfts)[int(len(ttfts) * 0.99)],
'avg_tpot': sum(tpots) / len(tpots),
'p99_tpot': sorted(tpots)[int(len(tpots) * 0.99)],
'total_requests': len(self.requests),
'throughput': len(self.requests) / (self.requests[-1]['timestamp'] - self.requests[0]['timestamp'])
}7.2 资源监控
NPU 资源使用情况:
# 实时监控 NPU 利用率
watch -n 1 'npu-smi info'
# 监控内存使用
npu-smi info | grep "Memory Usage"
# 监控功耗
npu-smi monitor -i 0应用级监控:
import psutil
import os
def monitor_system_resources():
"""监控系统资源使用"""
process = psutil.Process(os.getpid())
return {
'cpu_percent': process.cpu_percent(interval=1),
'memory_mb': process.memory_info().rss / 1024 / 1024,
'num_threads': process.num_threads(),
}八. 故障排查与调试
8.1 常见问题
问题一:推理速度慢
诊断步骤:
- 检查 NPU 利用率:
npu-smi info - 检查批处理大小是否过小
- 检查是否有其他进程占用 NPU
- 尝试增加
gpu_memory_utilization
问题二:显存溢出
症状:
RuntimeError: out of memory解决方案:
- 减小批处理大小
- 减小最大生成长度
- 使用量化模型
- 启用 PagedAttention(默认启用)
问题三:延迟不稳定
原因:
- 系统负载波动
- 垃圾回收(GC)暂停
- 其他进程竞争资源
解决:
- 在专用服务器上部署
- 关闭不必要的后台进程
- 使用 CPU 亲和性绑定进程
8.2 调试工具
启用详细日志:
export VLLM_LOG_LEVEL=DEBUG
export ASCEND_LOG_LEVEL=3
python inference_service.py性能分析:
import cProfile
import pstats
def profile_inference():
"""对推理过程进行性能分析"""
profiler = cProfile.Profile()
profiler.enable()
# 执行推理
llm = LLM(model="meta-llama/Llama-2-7b-hf")
llm.generate(["Hello"] * 10)
profiler.disable()
stats = pstats.Stats(profiler)
stats.sort_stats('cumulative')
stats.print_stats(20) # 打印前 20 个耗时最长的函数九. 总结
vLLM-Ascend 提供了灵活的推理服务构建方式:
- 离线场景:关注高吞吐量,通过增大批处理大小和充分利用 NPU 资源
- 在线场景:关注低延迟,通过优化采样参数和内存管理
- 超大模型:通过 TP 技术实现多卡并行推理
关键优化策略:
- 找到最优批处理大小:在不溢出显存的前提下最大化
- 监控关键指标:TTFT、TPOT、吞吐量
- 定期性能分析:使用 profiling 工具找到瓶颈
- 生产环境部署:使用多副本、负载均衡、监控告警
昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)