
基于MindSpore框架实现PWCNet光流估计
【代码】基于MindSpore框架实现PWCNet光流估计。
·
欢迎加入Mindspore社区一起学习,共同进步!
数据集下载解压
设置训练基本属性
将MindSpore设置为图执行模式,并设置为使用Ascend进行训练。
配置训练集
设置数据集路径,设置训练参数,包括batch_size、epoch_size、learning_rate等。
train_data_path = r"./training"
val_data_path = r"./training"
pretrained_path = r"pretrained_model/pwcnet-mindspore.ckpt"
batch_size = 4
lr = 0.0001
num_parallel_workers = 4
lr_milestones = '6,10,12,16'
lr_gamma = 0.5
max_epoch = 20
loss_scale = 1024
warmup_epochs = 1
设置数据增强方法,包括使用随机颜色变换和随机Gamma变换。
import mindspore.dataset.vision as V
from src.dataset_utils import RandomGamma
augmentation_list = [
V.ToPIL(),
V.RandomColorAdjust(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
V.ToTensor(),
RandomGamma(min_gamma=0.7, max_gamma=1.5, clip_image=True),
]
查看数据集的训练集和测试集的数量。同时查看数据集中RGB图片和光流图片的分辨率大小。
from black import out
from src.dataset import getFlyingChairsTrainData, getSintelValData
dl_train, len_dl_train, dataset = getSintelValData(
root=train_data_path,
split="train",
augmentations=augmentation_list,
batch_size=batch_size,
num_parallel_workers=num_parallel_workers,
)
dl_val, len_dl_val, val_dataset = getSintelValData(
root=val_data_path,
split="train",
augmentations=augmentation_list,
batch_size=batch_size,
num_parallel_workers=num_parallel_workers,
)
train_len = dl_train.get_dataset_size()
dl_train = dl_train.repeat(max_epoch)
print(f"The dataset size of dl_train: {dl_train.get_dataset_size()}")
print(f"The dataset size of dl_val: {dl_val.get_dataset_size()}")
dict_datasets = next(dl_train.create_dict_iterator())
print(dict_datasets.keys())
print(dict_datasets["im1"].shape)
print(dict_datasets["im2"].shape)
print(dict_datasets["flo"].shape)
print(type(dict_datasets["flo"]))
print(dict_datasets["flo"].max(), dict_datasets["flo"].min())
print(dict_datasets["flo"].max() * 0.05, dict_datasets["flo"].min() * 0.05)
dl_train = dl_train.create_tuple_iterator(output_numpy=False, do_copy=False)
dl_val = dl_val.create_tuple_iterator(output_numpy=False, do_copy=False)
禁用一下共享内存,运行
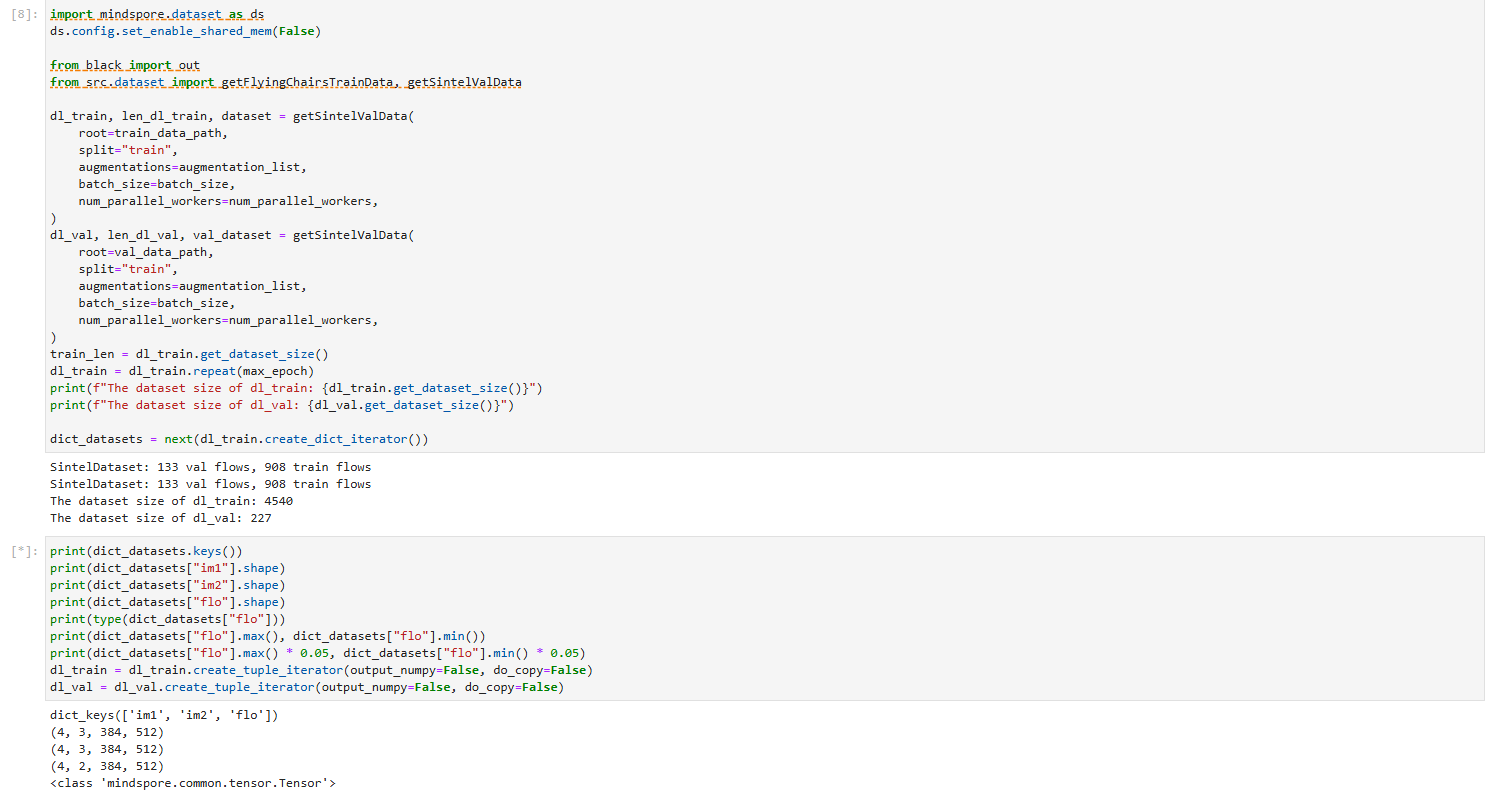
可以使用flow_vis和matplotlib库分别将光流图片与RGB图片可视化。
训练与结果查看
初始化神经网络、损失函数、优化器、模型和回调函数。
from collections import Counter
import numpy as np
class _WarmUp():
"""
Basic class for warm up
"""
def __init__(self, warmup_init_lr):
self.warmup_init_lr = warmup_init_lr
def get_lr(self):
# Get learning rate during warmup
raise NotImplementedError
class _LRScheduler():
"""
Basic class for learning rate scheduler
"""
def __init__(self, lr, max_epoch, steps_per_epoch):
self.base_lr = lr
self.steps_per_epoch = steps_per_epoch
self.total_steps = int(max_epoch * steps_per_epoch)
def get_lr(self):
# Compute learning rate using chainable form of the scheduler
raise NotImplementedError
class _LinearWarmUp(_WarmUp):
"""
Class for linear warm up
"""
def __init__(self, lr, warmup_epochs, steps_per_epoch, warmup_init_lr=0):
self.base_lr = lr
self.warmup_init_lr = warmup_init_lr
self.warmup_steps = int(warmup_epochs * steps_per_epoch)
super(_LinearWarmUp, self).__init__(warmup_init_lr)
def get_warmup_steps(self):
return self.warmup_steps
def get_lr(self, current_step):
lr_inc = (float(self.base_lr) - float(self.warmup_init_lr)) / float(self.warmup_steps)
lr = float(self.warmup_init_lr) + lr_inc * current_step
return lr
class MultiStepLR(_LRScheduler):
"""
Multi-step learning rate scheduler
Decays the learning rate by gamma once the number of epoch reaches one of the milestones.
Args:
lr (float): Initial learning rate which is the lower boundary in the cycle.
milestones (list): List of epoch indices. Must be increasing.
gamma (float): Multiplicative factor of learning rate decay.
steps_per_epoch (int): The number of steps per epoch to train for.
max_epoch (int): The number of epochs to train for.
warmup_epochs (int, optional): The number of epochs to Warmup. Default: 0
Outputs:
numpy.ndarray, shape=(1, steps_per_epoch*max_epoch)
Example:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 80
>>> # lr = 0.0005 if epoch >= 80
>>> scheduler = MultiStepLR(lr=0.1, milestones=[30,80], gamma=0.1, steps_per_epoch=5000, max_epoch=90)
>>> lr = scheduler.get_lr()
"""
def __init__(self, lr, milestones, gamma, steps_per_epoch, max_epoch, warmup_epochs=0):
self.milestones = Counter(milestones)
self.gamma = gamma
self.warmup = _LinearWarmUp(lr, warmup_epochs, steps_per_epoch)
super(MultiStepLR, self).__init__(lr, max_epoch, steps_per_epoch)
def get_lr(self):
warmup_steps = self.warmup.get_warmup_steps()
lr_each_step = []
current_lr = self.base_lr
for i in range(self.total_steps):
if i < warmup_steps:
lr = self.warmup.get_lr(i+1)
else:
cur_ep = i // self.steps_per_epoch
if i % self.steps_per_epoch == 0 and cur_ep in self.milestones:
current_lr = current_lr * self.gamma
lr = current_lr
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
训练代码
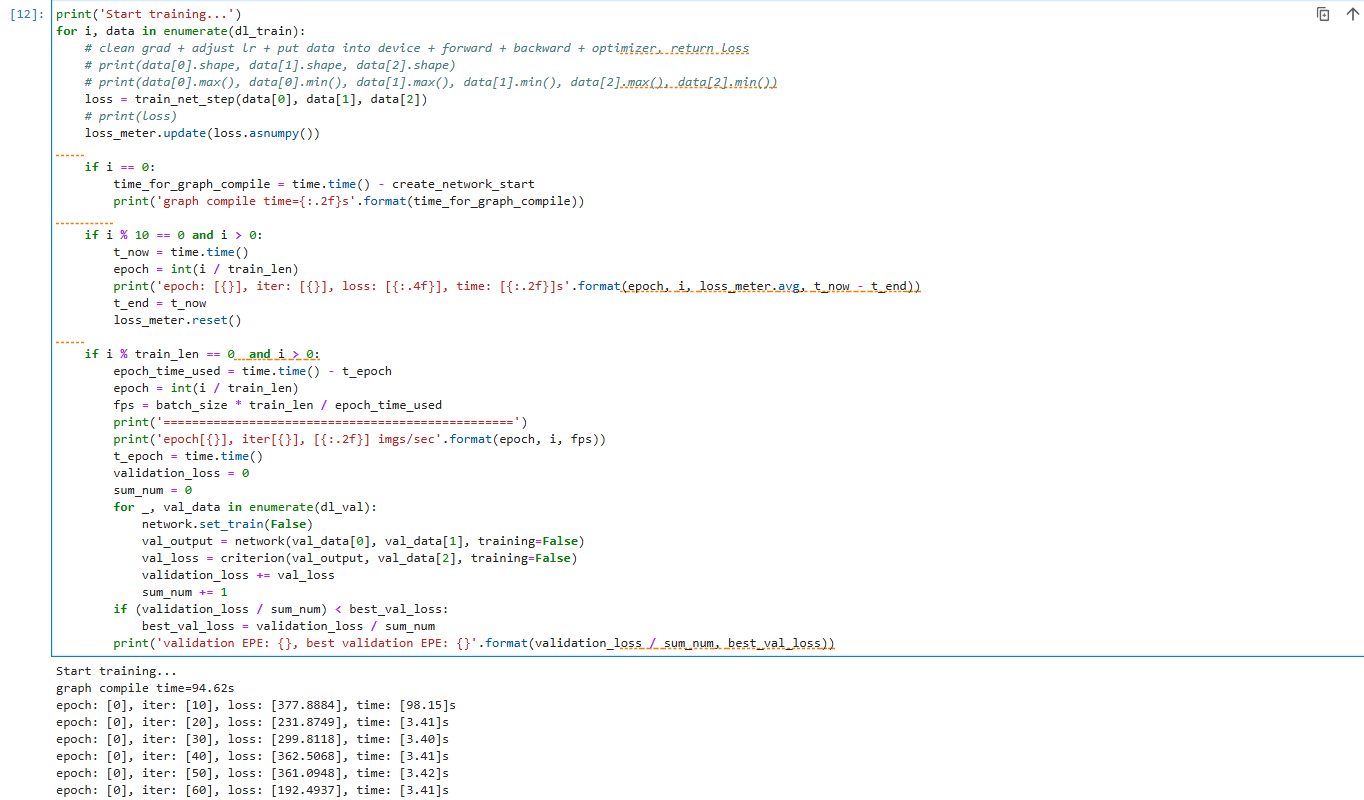
print('Start training...')
for i, data in enumerate(dl_train):
# clean grad + adjust lr + put data into device + forward + backward + optimizer, return loss
# print(data[0].shape, data[1].shape, data[2].shape)
# print(data[0].max(), data[0].min(), data[1].max(), data[1].min(), data[2].max(), data[2].min())
loss = train_net_step(data[0], data[1], data[2])
# print(loss)
loss_meter.update(loss.asnumpy())
if i == 0:
time_for_graph_compile = time.time() - create_network_start
print('graph compile time={:.2f}s'.format(time_for_graph_compile))
if i % 10 == 0 and i > 0:
t_now = time.time()
epoch = int(i / train_len)
print('epoch: [{}], iter: [{}], loss: [{:.4f}], time: [{:.2f}]s'.format(epoch, i, loss_meter.avg, t_now - t_end))
t_end = t_now
loss_meter.reset()
if i % train_len == 0 and i > 0:
epoch_time_used = time.time() - t_epoch
epoch = int(i / train_len)
fps = batch_size * train_len / epoch_time_used
print('=================================================')
print('epoch[{}], iter[{}], [{:.2f}] imgs/sec'.format(epoch, i, fps))
t_epoch = time.time()
validation_loss = 0
sum_num = 0
for _, val_data in enumerate(dl_val):
network.set_train(False)
val_output = network(val_data[0], val_data[1], training=False)
val_loss = criterion(val_output, val_data[2], training=False)
validation_loss += val_loss
sum_num += 1
if (validation_loss / sum_num) < best_val_loss:
best_val_loss = validation_loss / sum_num
print('validation EPE: {}, best validation EPE: {}'.format(validation_loss / sum_num, best_val_loss))
开始训练
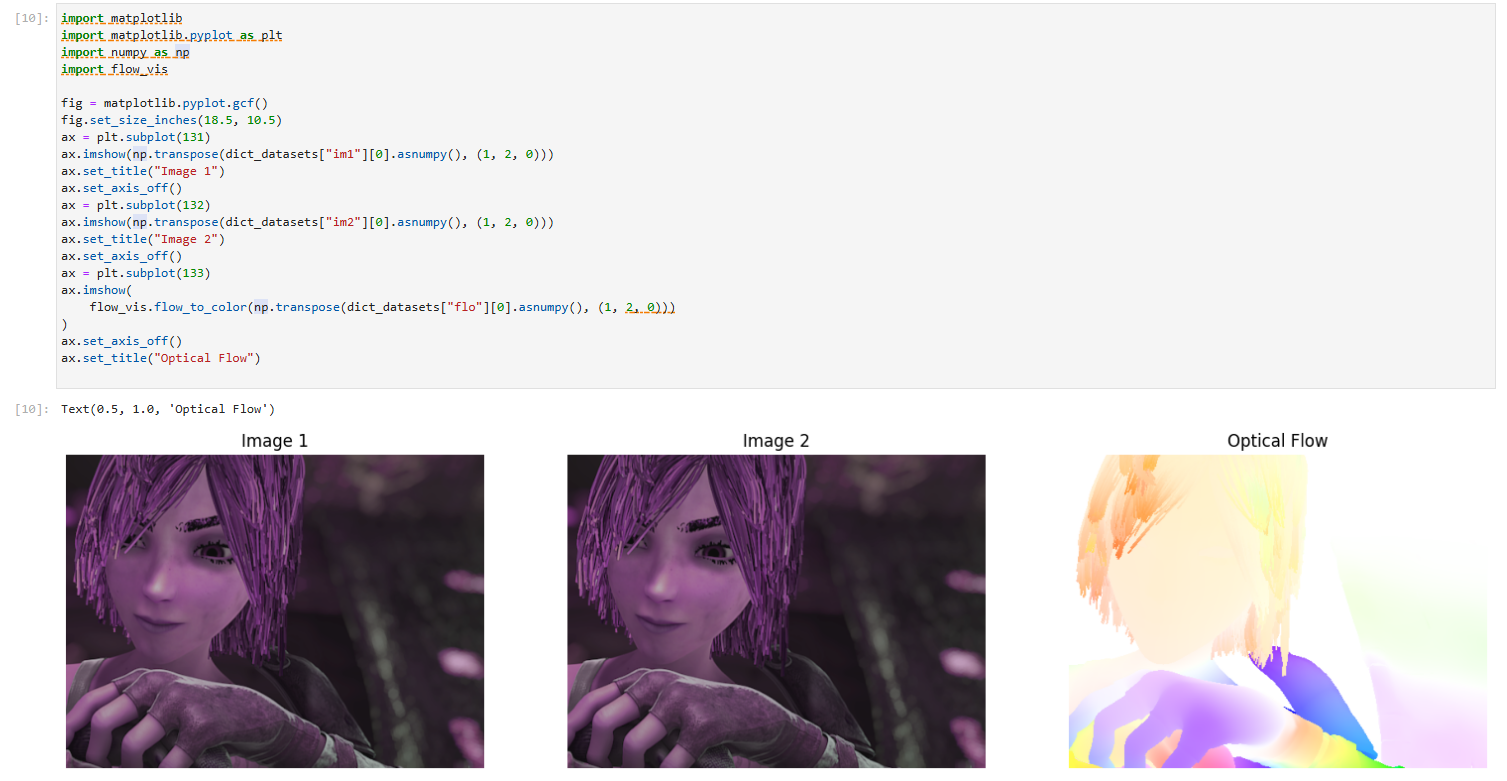
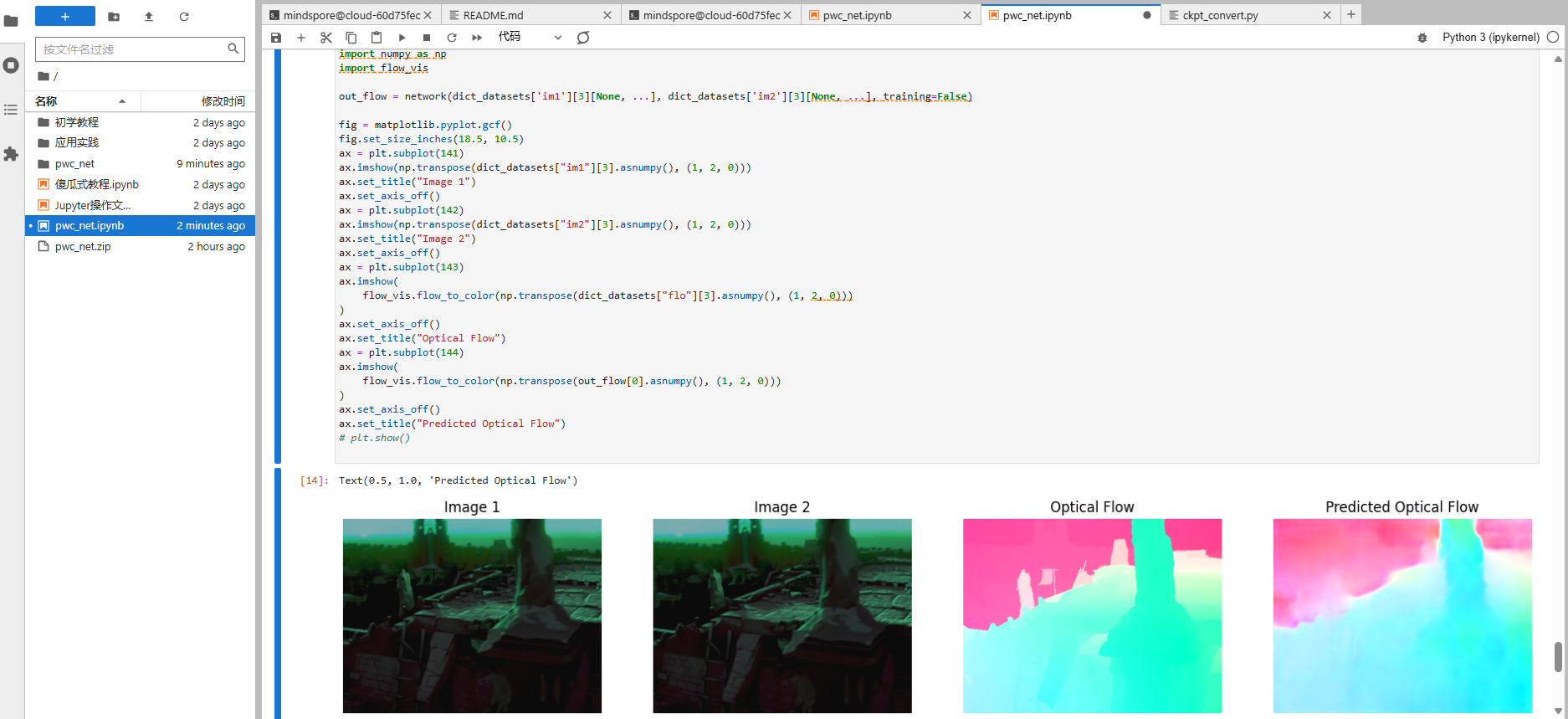
查看运行结果
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import flow_vis
out_flow = network(dict_datasets['im1'][3][None, ...], dict_datasets['im2'][3][None, ...], training=False)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
ax = plt.subplot(141)
ax.imshow(np.transpose(dict_datasets["im1"][3].asnumpy(), (1, 2, 0)))
ax.set_title("Image 1")
ax.set_axis_off()
ax = plt.subplot(142)
ax.imshow(np.transpose(dict_datasets["im2"][3].asnumpy(), (1, 2, 0)))
ax.set_title("Image 2")
ax.set_axis_off()
ax = plt.subplot(143)
ax.imshow(
flow_vis.flow_to_color(np.transpose(dict_datasets["flo"][3].asnumpy(), (1, 2, 0)))
)
ax.set_axis_off()
ax.set_title("Optical Flow")
ax = plt.subplot(144)
ax.imshow(
flow_vis.flow_to_color(np.transpose(out_flow[0].asnumpy(), (1, 2, 0)))
)
ax.set_axis_off()
ax.set_title("Predicted Optical Flow")
# plt.show()

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)