
使用ModelArt平台昇腾芯片,将Restnet50模型迁移到猫狗分类实验
总体实验较为简单,数据集处理较为繁琐,在书写Dataset和DataLoader时需要不断考虑NPU是否可以适配,后经过torch_npu的自动迁移,发现无需将cuda相关的函数以及字符修改,自动迁移可以进行自动更换,方便我们使用。其次需要将模型迁移到不同数据集时更换预训练的网络层,以避免输出与label不匹配。Ascend使用整体情况,发现模型在npu’和cpu之间转换时耗时太长,同样的实验环境
一、实验环境:
Pytorch:1.8.1
Python:3.7
NPU:AICore
二、实验过程:
1.上传数据集“dogs-vs-cats-redux-kernels-edition”,解压得到train和test文件夹。实验过程如下:
加载数据集时遇到的问题,不能传输超出100M的数据集,但是猫狗数据集总共387M,因此采用远程Kaggle链接下载,结果如图所示:
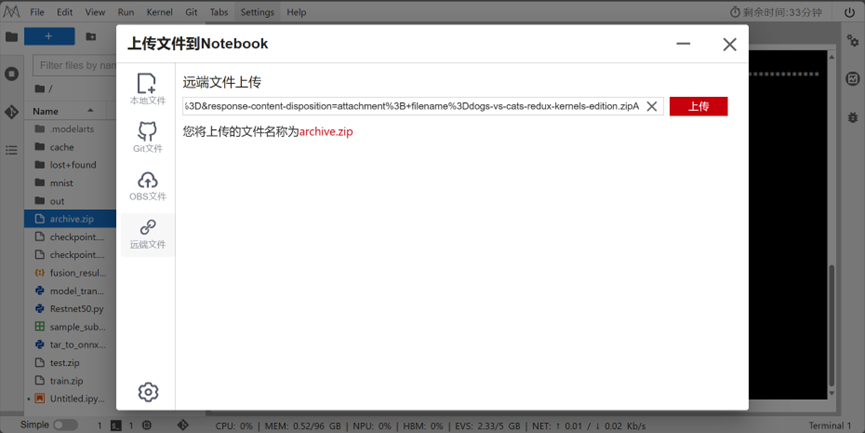
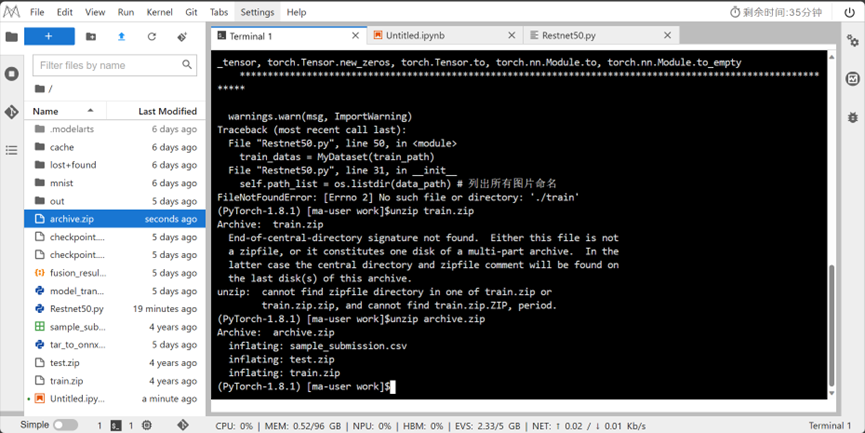
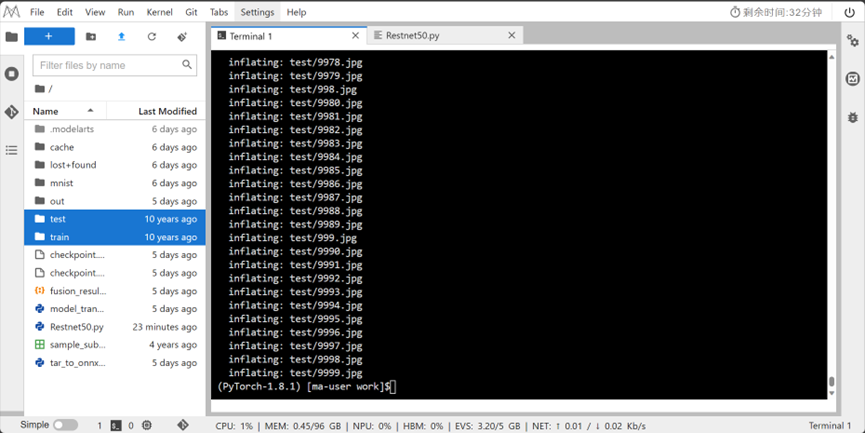
解压后得到train和test文件夹:
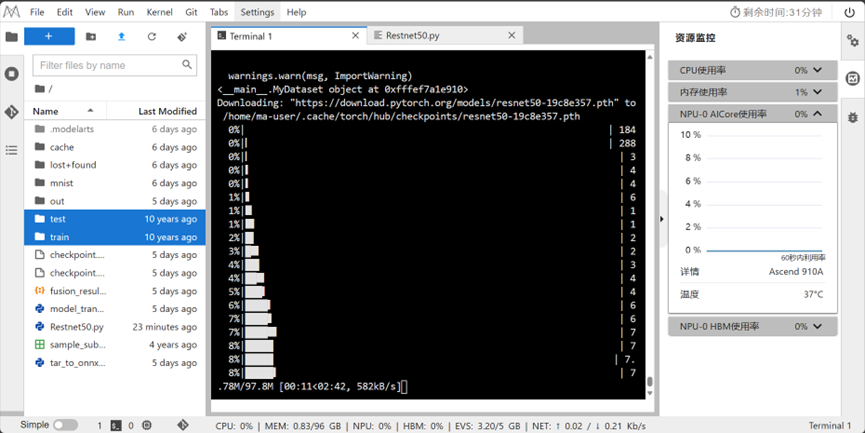
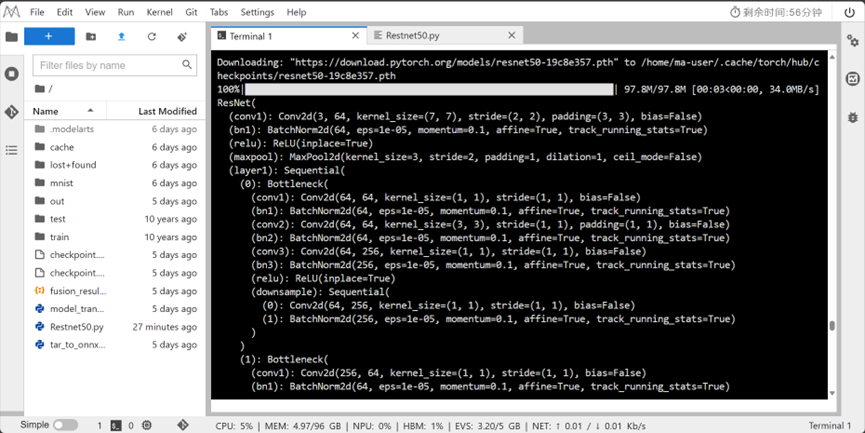
2.训练之前下载Restnet50的预训练模型:
将Resnet的最后一个全连接层更换为2,代码如下:

模型结构:
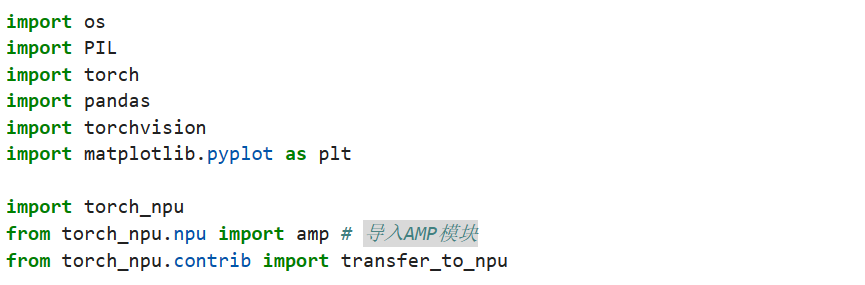
在训练中导入NPU和AMP模块:
重新书写Dataset类,初始化时加载文件路径,完成数据增强操作,在__getitem__方法中实现根据索引index读取对应的数据和标签label,并规定dog是1,cat是0。

训练中将传统的计算模型output和loss语句放入AMP模块下,以自动完成数据的计算并在loss回传和参数更新中使用Ascend自带的scalar模块进行更新:
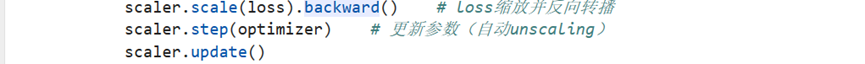
3.开始在训练中使用NPU:
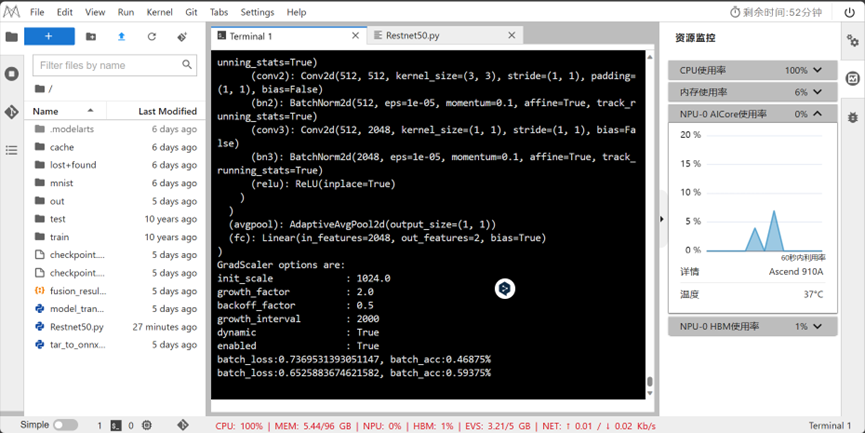
4.训练结果
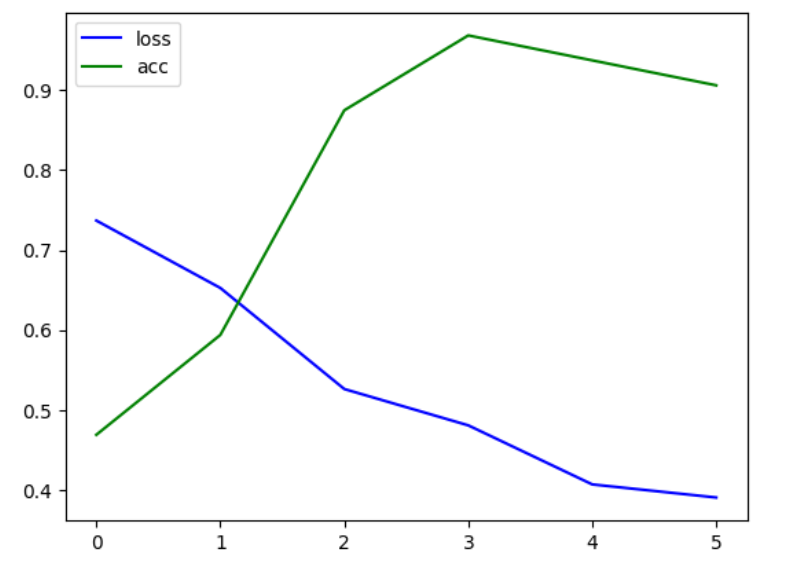
实验总结:
总体实验较为简单,数据集处理较为繁琐,在书写Dataset和DataLoader时需要不断考虑NPU是否可以适配,后经过torch_npu的自动迁移,发现无需将cuda相关的函数以及字符修改,自动迁移可以进行自动更换,方便我们使用。其次需要将模型迁移到不同数据集时更换预训练的网络层,以避免输出与label不匹配。
Ascend使用整体情况,发现模型在npu’和cpu之间转换时耗时太长,同样的实验环境,在gpu中可能需要更少时间,后续计划着重研究如何调用Ascend来优化模型训练时间。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)