
04 基于MindSpore通过GPT实现情感分类
注: 如果想要运行的更快一些,可以在训练时需要V100的算力。
·
环境配置
#安装mindnlp 0.4.0套件
!pip install mindnlp==0.4.0
!pip uninstall soundfile -y
!pip install download
!pip install jieba
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn
from mindnlp.dataset import load_dataset
from mindnlp.engine import Trainer
imdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']
imdb_train.get_dataset_size()
import numpy as np
def process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):
is_ascend = mindspore.get_context('device_target') == 'Ascend'
def tokenize(text):
if is_ascend:
tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)
else:
tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)
return tokenized['input_ids'], tokenized['attention_mask']
if shuffle:
dataset = dataset.shuffle(batch_size)
# map dataset
dataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])
dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")
# batch dataset
if is_ascend:
dataset = dataset.batch(batch_size)
else:
dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})
return dataset
from mindnlp.transformers import OpenAIGPTTokenizer
# tokenizer
gpt_tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
# add sepcial token: <PAD>
special_tokens_dict = {
"bos_token": "<bos>",
"eos_token": "<eos>",
"pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)
#这行代码是为了方便体验流程,把原本数据集的十分之一拿出来体验训练和评估,体验该完整的数据集,可以将这行代码注释掉
imdb_train, _ = imdb_train.split([0.1, 0.9], randomize=False)
# split train dataset into train and valid datasets
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])
dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)
next(dataset_train.create_tuple_iterator())
from mindnlp.transformers import OpenAIGPTForSequenceClassification
from mindnlp import evaluate
import numpy as np
# set bert config and define parameters for training
model = OpenAIGPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
model.config.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)
from mindnlp.engine import TrainingArguments
training_args = TrainingArguments(
output_dir="gpt_imdb_finetune",
evaluation_strategy="epoch",
save_strategy="epoch",
logging_strategy="epoch",
load_best_model_at_end=True,
num_train_epochs=1.0,
learning_rate=2e-5
)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_train,
eval_dataset=dataset_val,
compute_metrics=compute_metrics
)
注: 如果想要运行的更快一些,可以在训练时需要V100的算力
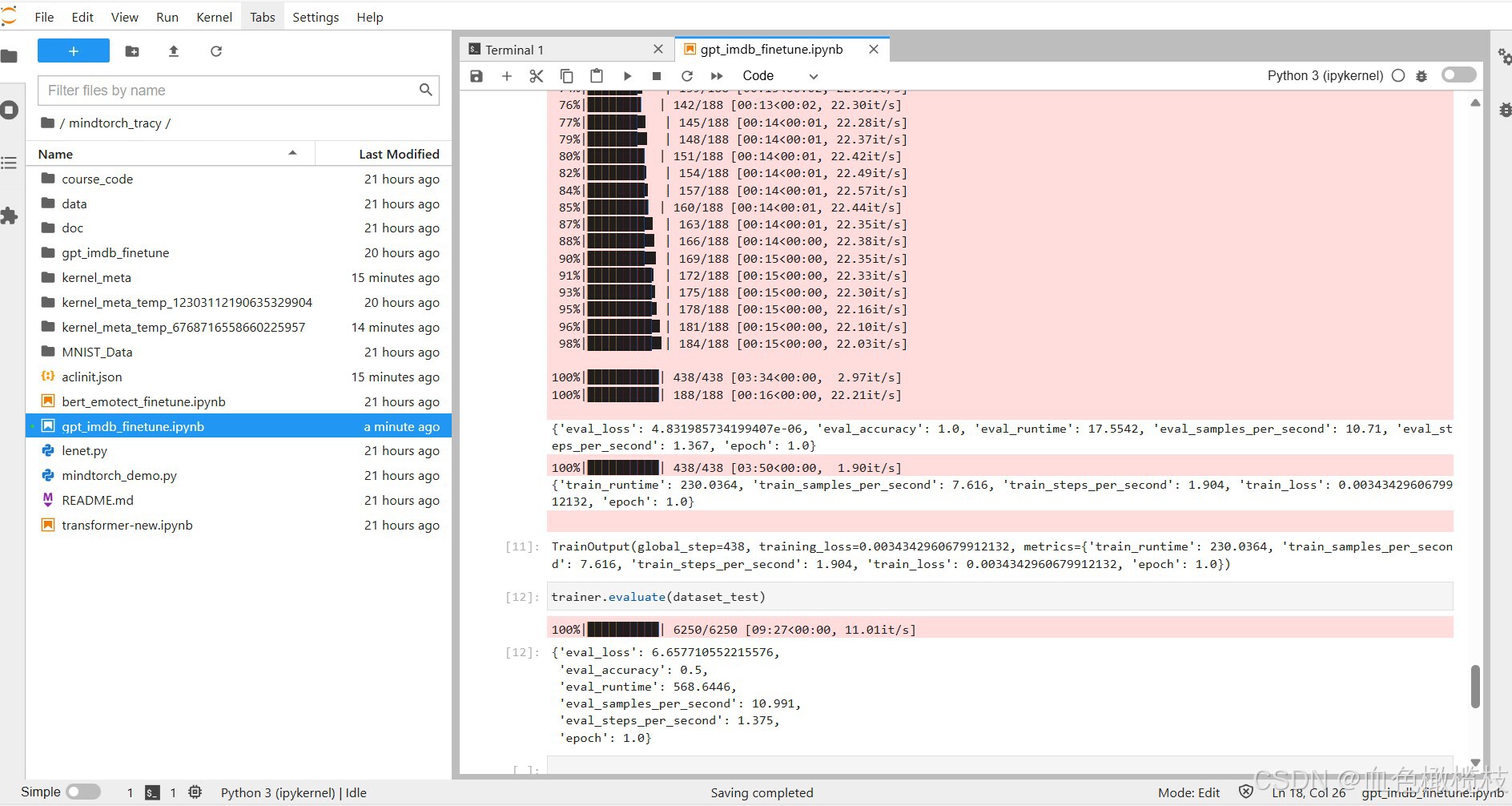
trainer.train()
trainer.evaluate(dataset_test)
运行结果

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)