
昇思25天学习打卡营第16天|xkd007|自然语言处理(1)-LSTM+CRF序列标注
序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。以命名实体识别为例:如上表所示,清华大学和北京是地名,需要将其识别,我们对每个输入的单词预测其标签,最后根据标签来识别实
1 概述
序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。以命名实体识别为例:

如上表所示,清华大学 和 北京是地名,需要将其识别,我们对每个输入的单词预测其标签,最后根据标签来识别实体。
这里使用了一种常见的命名实体识别的标注方法——“BIOE”标注,将一个实体(Entity)的开头标注为B,其他部分标注为I,非实体标注为O。
2 条件随机场(Conditional Random Field, CRF)
从上文的举例可以看到,对序列进行标注,实际上是对序列中每个Token进行标签预测,可以直接视作简单的多分类问题。但是序列标注不仅仅需要对单个Token进行分类预测,同时相邻Token之间有关联关系。以清华大学一词为例:

如上表所示,正确的实体中包含的4个Token有依赖关系,I前必须是B或I,而错误输出结果将清字标注为O,违背了这一依赖。将命名实体识别视为多分类问题,则每个词的预测概率都是独立的,易产生类似的问题,因此需要引入一种能够学习到此种关联关系的算法来保证预测结果的正确性。而条件随机场是适合此类场景的一种概率图模型。下面对条件随机场的定义和参数化形式进行简析。
考虑到序列标注问题的线性序列特点,本节所述的条件随机场特指线性链条件随机场(Linear Chain CRF)

完整的CRF完整推导可参考Log-Linear Models, MEMMs, and CRFs

1、Score计算
首先根据公式(3)计算正确标签序列所对应的得分,这里需要注意,除了转移概率矩阵𝐏外,还需要维护两个大小为|𝑇|的向量,分别作为序列开始和结束时的转移概率。同时我们引入了一个掩码矩阵𝑚𝑎𝑠𝑘𝑚𝑎𝑠𝑘,将多个序列打包为一个Batch时填充的值忽略,使得ScoreScore计算仅包含有效的Token。(代码见原文链接)
2、Normalizer计算
 根据公式(7),可计算Normalizer(代码见原文链接)
根据公式(7),可计算Normalizer(代码见原文链接)
3、Viterbi算法
在完成前向训练部分后,需要实现解码部分。这里我们选择适合求解序列最优路径的Viterbi算法。与计算Normalizer类似,使用动态规划求解所有可能的预测序列得分。不同的是在解码时同时需要将第𝑖个Token对应的score取值最大的标签保存,供后续使用Viterbi算法求解最优预测序列。
取得最大概率得分ScoreScore,以及每个Token对应的标签历史HistoryHistory后,根据Viterbi算法可以得到公式: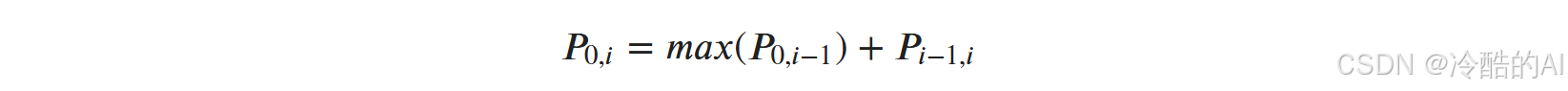
从第0个至第𝑖个Token对应概率最大的序列,只需要考虑从第0个至第𝑖−1个Token对应概率最大的序列,以及从第𝑖个至第𝑖−1个概率最大的标签即可。因此我们逆序求解每一个概率最大的标签,构成最佳的预测序列。(代码见原文链接)
由于静态图语法限制,我们将Viterbi算法求解最佳预测序列的部分作为后处理函数,不纳入后续CRF层的实现。
4、CRF层
完成上述前向训练和解码部分的代码后,将其组装完整的CRF层。考虑到输入序列可能存在Padding的情况,CRF的输入需要考虑输入序列的真实长度,因此除发射矩阵和标签外,加入seq_length参数传入序列Padding前的长度,并实现生成mask矩阵的sequence_mask方法。
综合上述代码,使用nn.Cell进行封装,最后实现完整的CRF层。(代码见原文链接)
3 BiLSTM+CRF模型
在实现CRF后,我们设计一个双向LSTM+CRF的模型来进行命名实体识别任务的训练。模型结构如下:
nn.Embedding -> nn.LSTM -> nn.Dense -> CRF
其中LSTM提取序列特征,经过Dense层变换获得发射概率矩阵,最后送入CRF层。
具体实现如下:(代码见原文链接)
① 完成模型设计后,生成两句例子和对应的标签,并构造词表和标签表。
② 接下来实例化模型,选择优化器并将模型和优化器送入Wrapper。
由于CRF层已经进行了NLLLoss的计算,因此不需要再设置Loss。
③ 将生成的数据打包成Batch,按照序列最大长度,对长度不足的序列进行填充,分别返回输入序列、输出标签和序列长度构成的Tensor。
④ 对模型进行预编译后,训练500个step。
训练流程可视化依赖
tqdm库,可使用pip install tqdm命令安装。
⑤ 观察训练500个step后的模型效果,首先使用模型预测可能的路径得分以及候选序列。
⑥ 使用后处理函数进行预测得分的后处理。
⑦ 最后将预测的index序列转换为标签序列,打印输出结果,查看效果。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)