
我的CANN算子开发“炼成记”:从一行代码都不懂到“手撕”Tiling
幸运的是,对于简单的Add算子,训练营提供了模板化的实现,我依葫芦画瓢,修改了一下数据类型和计算逻辑,然后紧张地按下了编译按钮。“算子”,这个词我听过无数次,知道它是构成神经网络的“原子”,是真正执行计算的单元。大厨每需要一个土豆,就亲自跑到遥远的冰库里,拿一个,再跑回来,在菜板上切好,再跑回去放好。我暂停了视频,在网上查阅了大量资料,又结合昇腾的文档,终于,我构建了一个自认为比较贴切的比喻,才算
前言:为什么要“想不开”去学算子开发?
大家好,我是一个在AI应用层“随波逐流”了很久的开发者。平时的工作就是调参、调模型、用各种框架搭业务。时间久了,总感觉自己像个“调包侠”,对底层那些真正让AI跑起来的魔法一无所知。每当模型训练速度慢、推理性能不达标时,除了干瞪眼,似乎也做不了什么。
“算子”,这个词我听过无数次,知道它是构成神经网络的“原子”,是真正执行计算的单元。但我对它的理解,也仅限于此。它到底长什么样?如何写一个算子?它又是怎么在昇腾这样的NPU上高效运行的?我一概不知。
抱着“打破砂锅问到底”和“提升内功”的想法,我把目光投向了昇腾社区。正好,社区推出了免费的 “昇腾CANN训练营”,号称能带开发者从0到1入门算子开发。这简直是瞌睡遇到了枕头,我毫不犹豫地报了名。
这篇文章,就是我这几周学习的真实记录。它不是一篇高高在上的技术教程,而是一份充满“踩坑”与“顿悟”的学习笔记。希望能给像我一样对AI底层充满好奇,但又望而却步的朋友们一点点勇气和参考。
第一章:初探门径,我的第一个“Hello World”算子
训练营的开篇课程,首先带我们熟悉了整个算子开发的生态和工具链。核心的IDE是 MindStudio,一个集成了代码编写、编译、调试、性能分析于一体的强大工具。对于习惯了VSCode和PyCharm的我来说,上手并不算困难。
跟着老师的引导,我创建了我的第一个算子工程——一个最简单的向量加法(Add)算子。整个流程大致分为几步:
- 算子原型定义 (.proto):用一种类似protobuf的语言定义算子的输入、输出和属性。比如,Add算子就是两个输入
x1、x2,一个输出y。 - 算子信息库配置 (.json):告诉CANN框架这个算子的各种信息,比如它在哪种硬件上生效,输入输出的数据类型支持哪些等等。
- 算子实现(.cpp):这是最核心的部分,包含了三个关键函数:
InferShape:根据输入的形状(Shape)推导出输出的形状。对于Add算子,输出形状和输入形状一致。InferFormat:推导输出的数据排布格式。Kernel:算子的核函数,也就是真正执行计算的地方。
前面的步骤都还算顺利,毕竟主要是配置和声明。直到我打开Kernel函数,看到里面一堆陌生的宏和函数时,我知道,真正的挑战要来了。
__global__ void add_kernel(uint8_t* x1, uint8_t* x2, uint8_t* y) {
// ... 一些复杂的索引计算 ...
// ... 一些奇怪的内置函数 ...
}
代码里充满了__global__、block_idx、thread_idx这些带有并行计算味道的词。虽然我之前对CUDA有一点点了解,但看到这些还是会头大。幸运的是,对于简单的Add算子,训练营提供了模板化的实现,我依葫芦画瓢,修改了一下数据类型和计算逻辑,然后紧张地按下了编译按钮。
“Build Successful”!
当这行绿色的文字出现在控制台时,我长舒了一口气。接着运行测试用例,“Test Case PASS”!那一刻的成就感,不亚于我第一次跑通神经网络。虽然我知道这只是万里长征的第一步,但它给了我巨大的信心。
第二章:撞上南墙——Tiling到底是个什么“鬼”?
信心满满的我,开始挑战更复杂的算子。很快,我就遇到了学习路上的第一个“大魔王”——Tiling。
在稍微复杂一点的算子Kernel实现中,代码不再是简单的循环,而是被一个叫做Tiling的概念所主导。视频里,老师开始讲解Global Memory、Local Memory、AICore、DMA等一连串硬件相关的名词。
我的大脑瞬间宕机了。我只是想做个数学计算,为什么要关心数据是怎么搬运的?为什么不能像在CPU上写代码一样,直接从内存里读取数据,计算,然后写回去?
我当时看到的Kernel代码大概是这样的:
// 1. 定义一个Tiling结构体
TilingData tiling;
// 2. 调用一个宏来获取Tiling配置
GET_TILING_DATA(tiling, ...);
// 3. 根据Tiling配置进行循环
for (int32_t i = 0; i < tiling.blockNum; ++i) {
// 3.1 把数据从“远方”搬到“手边”
DataCopy(local_mem_in, global_mem_in + i * tiling.blockLength, ...);
// 3.2 在“手边”进行计算
ComputeInLocal(local_mem_out, local_mem_in, ...);
// 3.3 把结果从“手边”搬回“远方”
DataCopy(global_mem_out + i * tiling.blockLength, local_mem_out, ...);
}
这套“搬运-计算-搬回”的三部曲让我百思不得其解。我暂停了视频,在网上查阅了大量资料,又结合昇腾的文档,终于,我构建了一个自认为比较贴切的比喻,才算把这个概念彻底搞明白。
第三章:“顿悟时刻”——用“顶级大厨做满汉全席”来理解Tiling
请想象一下,我们的 昇腾AI处理器(NPU) 不是一块芯片,而是一个拥有顶级厨房的超级餐厅。
- 顶级大厨 (
AICore):他就是NPU里负责真正计算的核心单元。他的刀工(计算能力)出神入化,一秒钟能切几亿刀。 - 菜板 (
Local Memory):这是大厨面前的工作台。他所有的操作(计算)都必须在菜板上进行。这块菜板材质极好,用起来得心应手(速度极快),但缺点是——面积非常小。 - 后厨大冰库 (
Global Memory):这是餐厅的中央仓库,存放着制作满汉全席所需的所有食材(我们要处理的整个Tensor数据)。它巨大无比(容量大),但距离大厨的工作台很远(访问速度慢)。 - 传菜员 (
DMA控制器):他负责在冰库和菜板之间传递食材,任劳任怨,速度飞快,而且不需要大厨亲自指挥。
现在,任务来了:大厨需要处理1000斤的土豆(一个巨大的Tensor)。
一种糟糕的做法(没有Tiling):
大厨每需要一个土豆,就亲自跑到遥远的冰库里,拿一个,再跑回来,在菜板上切好,再跑回去放好。结果就是,大厨99%的时间都浪费在了往返跑路上,他惊人的刀工完全被浪费了。这会导致整个餐厅的出菜效率极低。
一种高效的做法(有Tiling):
餐厅老板(CANN框架)制定了一套科学的管理流程,这就是 Tiling(切分) 策略:
- 分批次处理:老板告诉传菜员:“不要一次拿一个,你一次从冰库里拿一筐(一个Tile/Block)土豆过来。”
- 流水线作业:
- 传菜员 (
DMA) 从 冰库 (Global Memory) 里取出第一筐土豆,送到 大厨的菜板 (Local Memory) 上。 - 大厨 (
AICore) 开始在菜板上疯狂施展刀工,处理这一筐土豆。关键在于,此时他的手没有离开过菜板,效率极高! - 与此同时,传菜员也没闲着,他可能已经去冰库取第二筐土豆了,或者正在把大厨处理好的成品送回冰库。
- 传菜员 (
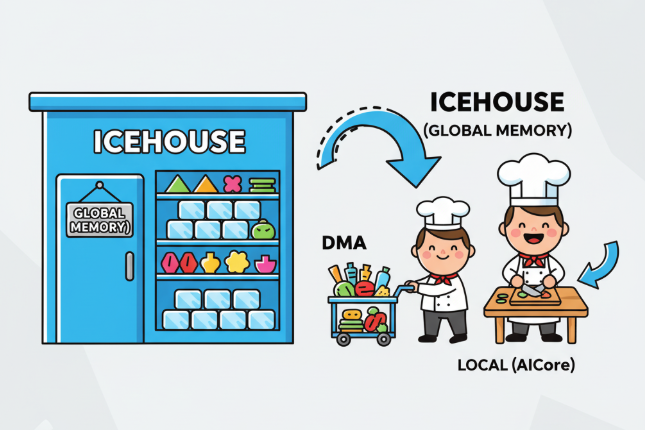
这个过程就是Tiling的核心思想:
将一个大规模的计算任务,切分成一个个大小适中、能完全放进高速缓存(Local Memory,即菜板)的数据块(Tile),然后通过DMA(传菜员)高效地在主存(Global Memory,即冰库)和高速缓存之间进行数据搬运,从而让计算核心(AICore,即大厨)能够持续、不间断地进行高强度计算,最大化地“隐藏”数据访存带来的延迟。
当我用这个比喻再次审视那段“三部曲”代码时,一切都豁然开朗:
DataCopy(local_mem_in, global_mem_in, ...):就是传菜员把食材从冰库搬到菜板。ComputeInLocal(...):就是大厨在菜板上专注地切菜。DataCopy(global_mem_out, local_mem_out, ...):就是传菜员把切好的菜送回冰库。
这个顿悟的瞬间,让我对异构计算的理解提升了一个层次。我明白了,在NPU这种高度并行的硬件上编程,思维方式必须从“面向过程”转变为“面向数据流”。如何设计高效的数据切分与搬运策略,其重要性甚至超过了计算逻辑本身。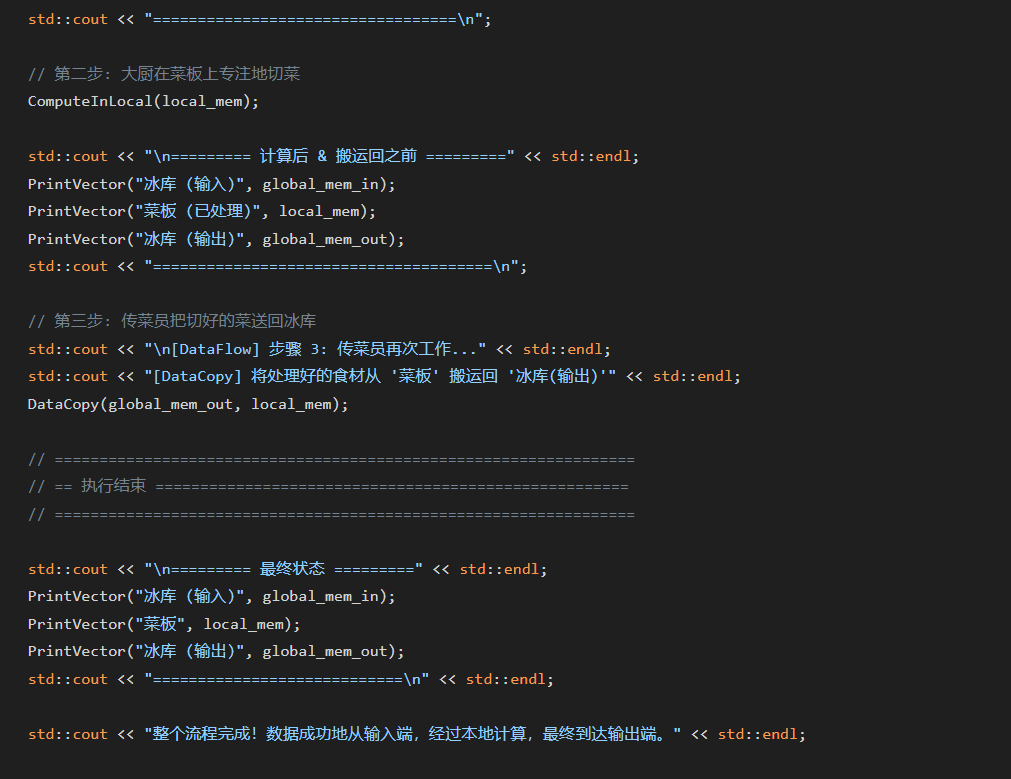
`
第四章:总结与展望
经过这段时间的学习,我成功地独立实现了一个带有Tiling逻辑的算子,并看着它在昇腾硬件上正确地跑出了结果。那种喜悦,是单纯调用API所无法比拟的。
我的几点学习感悟:
- 动手是最好的老师:看再多理论,不如亲手写一个算子,编译、运行、调试一遍。错误信息会告诉你所有答案。
- 建立正确的“心智模型”:对于Tiling这类抽象概念,找到一个好的比喻或模型至关重要。它能帮你快速建立直觉,理解代码背后的设计哲学。
- 善用社区和资源:昇腾社区的文档、Gitee上的开源算子库以及训练营的课程,都是宝贵的学习资料。遇到问题,先从这里找答案,往往事半功倍。
现在,我不再认为算子开发是遥不可及的“屠龙之技”。它更像一门手艺,需要耐心、细致,以及对硬件工作原理的尊重。虽然我离“大师傅”还差得很远,但至少我已经学会了如何“切菜”和“掌勺”,不再是一个只会“点菜”的门外汉了。
如果你也对AI底层技术充满兴趣,渴望提升自己的硬核技能,我真诚地向你推荐昇腾CANN训练营。这里的课程设计系统且对新手友好,从环境搭建到高级算子优化,循序渐进。最重要的是,它能带你亲手实践,真正体验到创造的乐趣。
【昇腾CANN训练营简介】
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有好礼相送!
【报名直通车】
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
愿我们都能在探索AI底层的道路上,不断精进,共同成长!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)