
【昇腾CANN训练营·行业篇】自动驾驶核心:基于Ascend C的Voxelization体素化算子开发
摘要:2025年昇腾CANN训练营第二季推出0基础到进阶的算子开发课程,助力开发者提升技能。本文以3D检测网络中的Voxelization算子为例,详解其核心算法:通过哈希映射将离散点云转换为规则网格,处理动态输入和并发写入问题。重点展示了AscendC实现方案,包括原子操作处理冲突、随机内存访问优化等关键技术,并指出性能瓶颈及优化方向(如点云预排序)。该算子是检验AI芯片编程能力的重要案例,掌握
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在 PointPillars、CenterPoint 等主流 3D 检测网络中,第一步永远是 Voxelization。 它的任务是:把 3D 空间划分为均匀的网格(Voxel),并将落入同一个网格的点聚集起来,形成一个 Feature Map。
这个算子的难点在于:
-
输入不确定:点的数量是动态的(N),分布是稀疏的。
-
冲突处理:多个点可能落入同一个 Voxel,需要并发写入。
-
内存随机写:点在空间中是随机分布的,导致写回 Global Memory 时地址极度不连续。
这是一个典型的 Scatter(驱散) 类算子,也是检验 Ascend C 编程功底的试金石。
一、 核心图解:从“散沙”到“积木”
Voxelization 的过程,就像是在玩《我的世界》(Minecraft)。
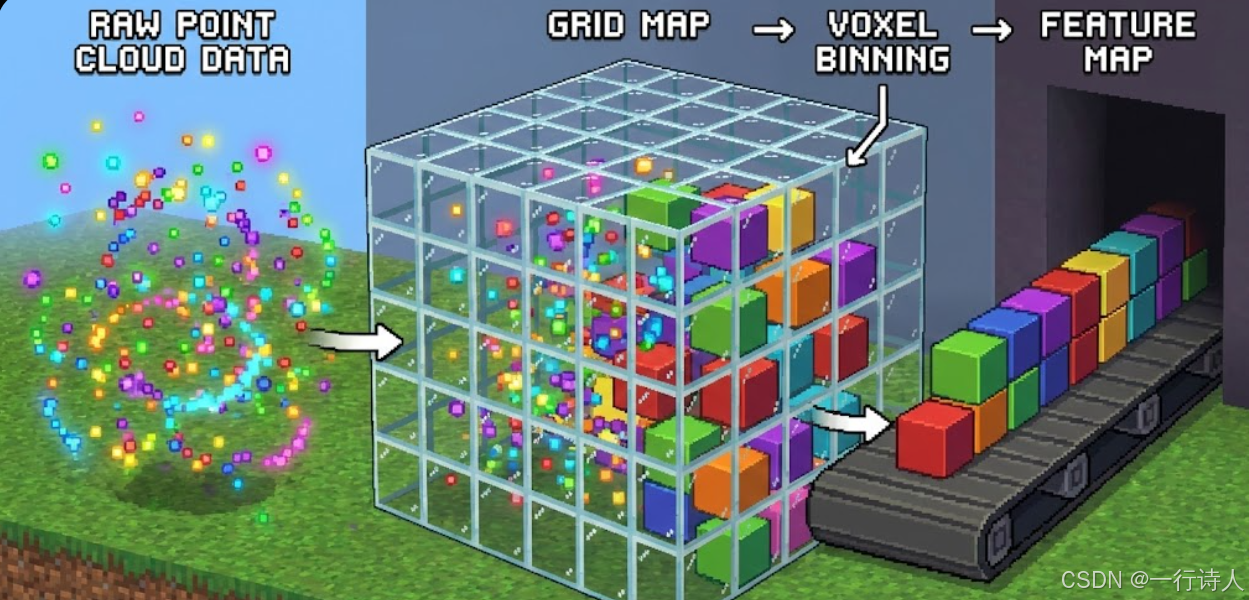
二、 算法逻辑:哈希与冲突解决
假设我们有一个巨大的 Dense Map(代表整个 3D 空间),每个格子存一个计数器。
处理流程:
-
Coordinate:计算每个点 $(x, y, z)$ 对应的网格坐标 $(i, j, k)$。
-
Address:计算网格在 Global Memory 中的线性地址。
-
Atomic:对该地址的计数器做原子加 1 (
cnt = atomic_add(addr, 1))。 -
Filter:如果
cnt < max_points_per_voxel,则将该点的数据写在这个 Voxel 的第cnt个空位上。
三、 实战:Ascend C 实现
3.1 Kernel 类定义
输入是点云 points,输出是 voxels(特征)、coors(坐标)和 num_points(每个voxel里的点数)。
class KernelVoxelization {
public:
__aicore__ inline void Init(GM_ADDR points, GM_ADDR voxels, GM_ADDR coors, GM_ADDR num_points,
VoxelParams params) {
// ... Init ...
// grid_map 是一个辅助的 GM 空间,用于记录每个格子当前存了多少个点
// 需要初始化为 0
this->grid_map.SetGlobalBuffer((__gm__ int32_t*)workspace);
}
__aicore__ inline void Process() {
// 按照点云数量进行 Tiling
for (int i = 0; i < tileNum; i++) {
Compute(i);
}
}
};
3.2 Compute 核心逻辑
这是最关键的部分,涉及大量的标量计算和随机访存。
__aicore__ inline void Compute(int32_t i) {
// 1. 搬运一批点到 UB
LocalTensor<float> pointsLoc = inQueueX.DeQue<float>();
// 2. 遍历每一个点 (Vector 也可以做,但 Index 计算较复杂,这里演示标量逻辑)
// 实际上,为了性能,应该尽量用 Vector 指令并行计算坐标
// Step A: Vector 计算 Grid Index
// grid_x = (x - x_min) / voxel_size_x
// ... 使用 Muls, Adds, Cast ...
// Step B: 标量处理冲突写入 (Scatter)
for (int j = 0; j < points_per_tile; j++) {
int32_t grid_idx = indicesLoc.GetValue(j);
// 3. 原子抢占位置
// SetAtomicAdd 开启
// 这一步必须是原子的,因为不同核可能处理相邻的点
// 注意:Ascend C 的 AtomicAdd 通常针对 GlobalTensor
// 这里模拟逻辑:old_count = AtomicAdd(grid_map[grid_idx], 1)
// 实际开发中,为了性能,通常会先在 UB 内做一次 Reduce/Sort,
// 或者使用特定的 "Voxelization" 高阶指令(如有)
// 假设我们拿到了 old_count 和 voxel_id
if (old_count < max_points) {
// 4. 将点数据写入 Voxels Tensor
// 这是一个极其离散的写操作
// voxels[voxel_id, old_count, :] = point_feature
// 构造 Offset
int64_t dest_offset = voxel_id * max_points * feature_dim + old_count * feature_dim;
// 写入 (使用 DataCopyPad 或 逐个元素赋值)
// 这种随机写带宽极低,是性能瓶颈
DataCopy(voxelsGm[dest_offset], point_data, feature_dim);
// 写入坐标
DataCopy(coorsGm[voxel_id], grid_coor, 4);
}
}
}
四、 性能优化的“生死劫”
上面的 Naive 实现有一个致命弱点:大量的 Global Memory 原子操作和随机写。在海量点云面前,MTE3 单元会崩溃。
进阶优化方案:
-
Point Sorting: 在 Voxelization 之前,先对点云按照
Grid Index进行一次 Sort(排序)。 排序后,属于同一个 Voxel 的点在内存中是连续的!-
效果:随机写变成了连续写(Burst Write)。原子操作变成了局部计数。
-
代价:多了一个 Sort 算子(我们在第 41 期讲过 Bitonic Sort)。
-
-
UB Hashing: 如果 Voxel 数量不多,可以在 UB 中维护一个小的 Hash Table,先在 UB 聚合,满了一批再写回 GM。
五、 总结
Voxelization 是连接物理世界(点云)与数字世界(Tensor)的桥梁。
-
场景:自动驾驶、机器人感知。
-
挑战:极致的稀疏性与冲突处理。
-
对策:如果点云太乱,就先排序;如果写冲突太多,就用原子锁。
掌握了这个算子,你就具备了优化 LiDAR 感知模型(如 PointPillars)底层的能力。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 16
16 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)