
基于vNPU的MindIE服务化部署指南
·
作者:昇腾实战派
一、部署概述
目标:通过vNPU算力切分技术,在容器化环境中部署MindIE服务化框架,实现AI模型的高效推理服务。
核心价值:
- 资源隔离与弹性分配:通过vNPU将物理NPU卡算力动态切分,实现多任务/多用户间的算力隔离与灵活调度。
- 轻量化部署:结合Docker容器技术,快速部署AI服务,提升环境一致性与运维效率。
- 成本优化:单张物理卡可虚拟为多个vNPU,服务低负载时可减少硬件资源浪费。
二、部署步骤
1. 环境检查与资源确认
检查环境查看服务器卡数
# 操作:查看服务器NPU卡数
npu-smi info
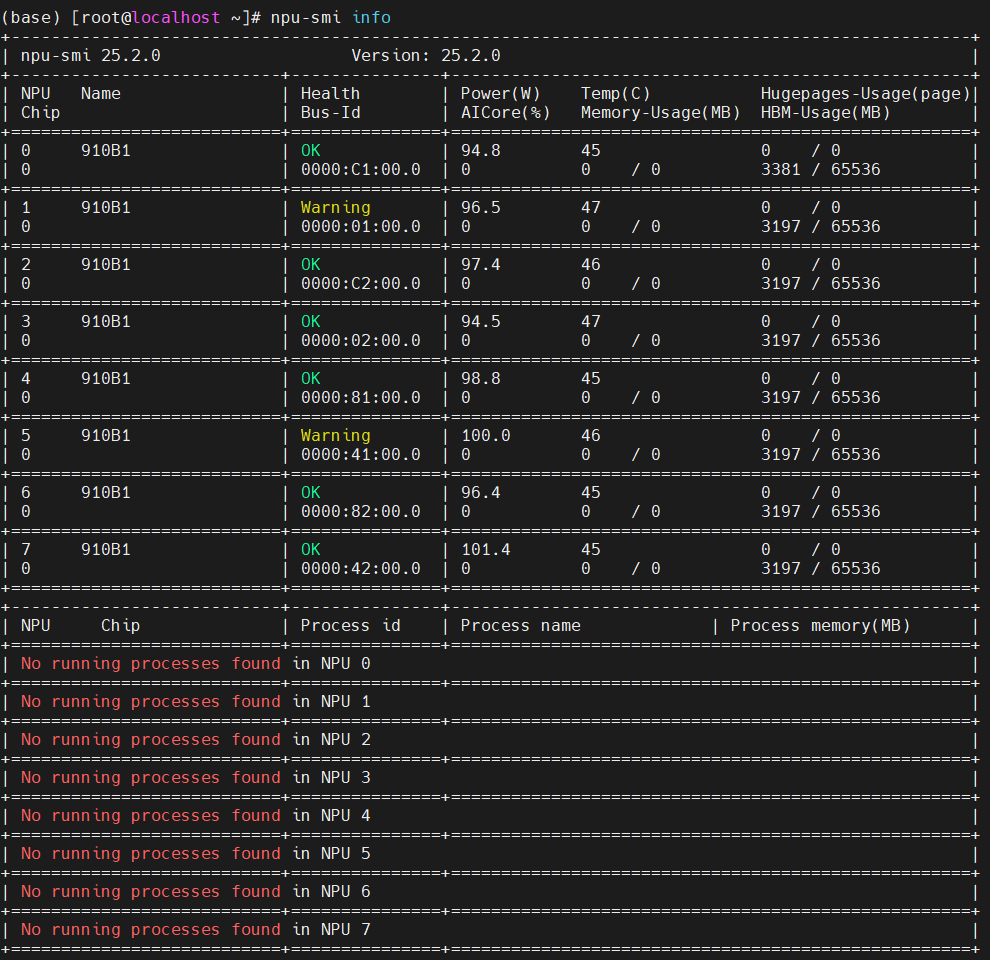
意义:
- 确认物理NPU资源总量,为后续vNPU切分提供依据,避免资源超分。
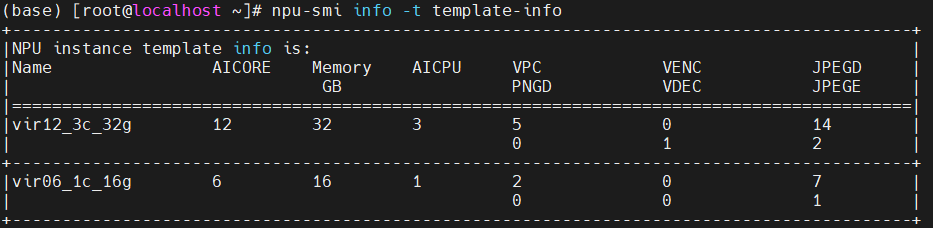
2. 检测可切分模板
npu-smi info -t template-info # 表格列出了切分资源
3. 创建vNPU
- 配置算力切分为docker模式

- 创建指定芯片的vNPU

- 查看创建的vNPU
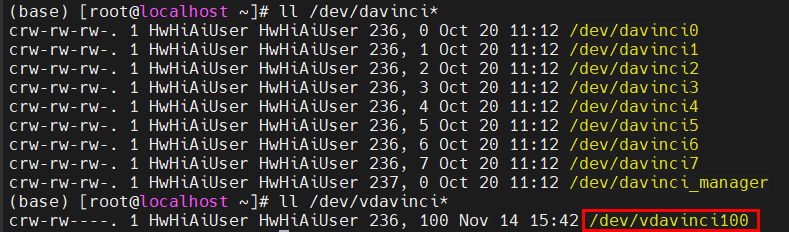
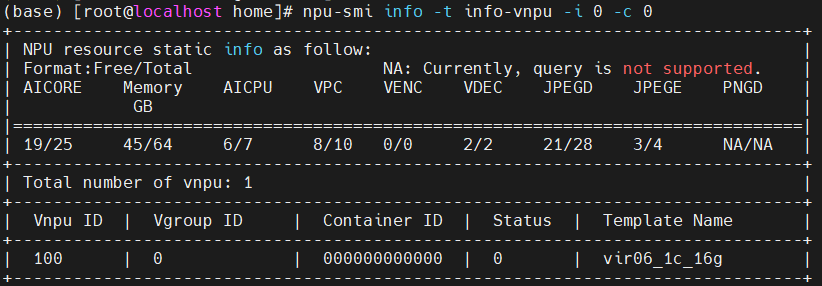
也可以直接用npu-smi info进行查询
4. 创建docker容器
- 注意:创建容器时不支持特权容器(启动脚本不能携带--privileged),其次,映射的vpnu块数必须<=8
查看容器内的vNPU挂载情况
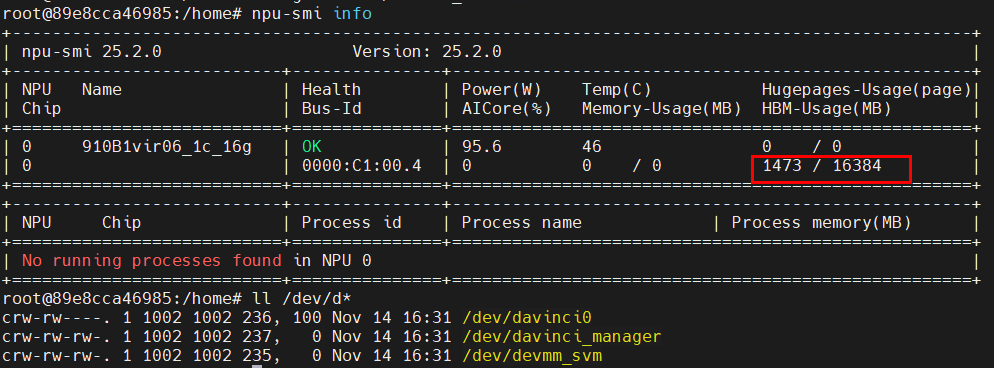
5. 配置与启动MindIE服务
更改config配置,挂载进来的device0,当作正常的npu来使用就行(以Qwen2.5-1.5B-Instruct模型为例)
启动mindie
发送请求,正常返回

6. 销毁vNPU

三、注意事项
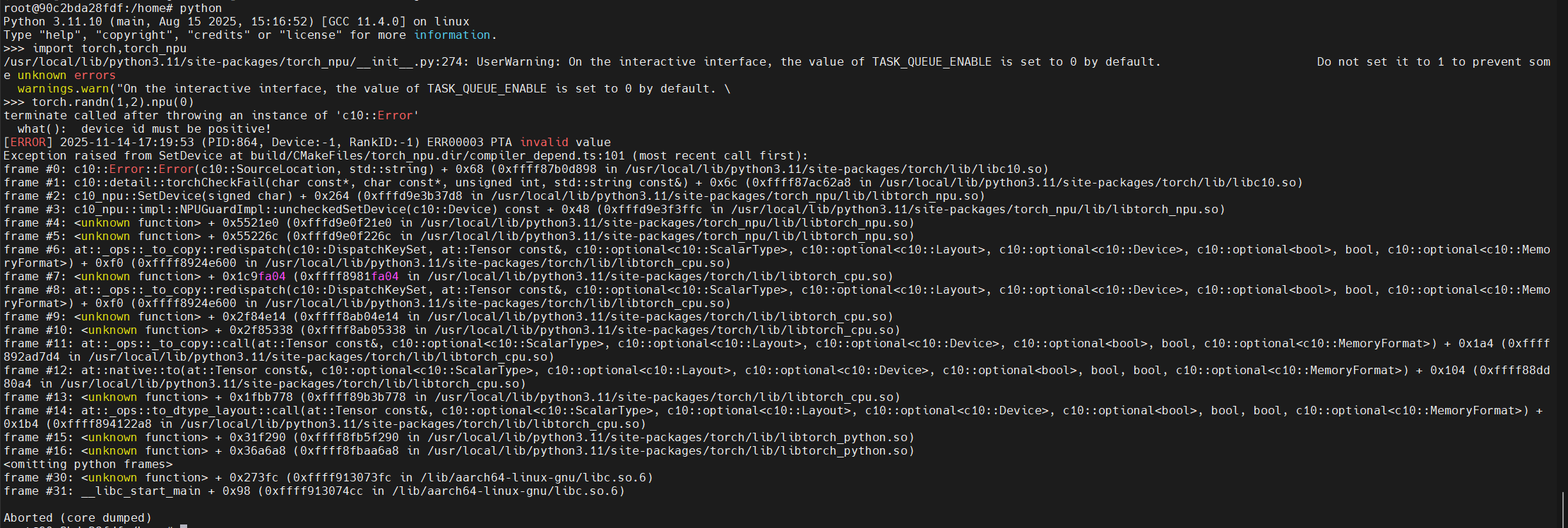
- 不可以使用特权容器,否则会出现以下报错
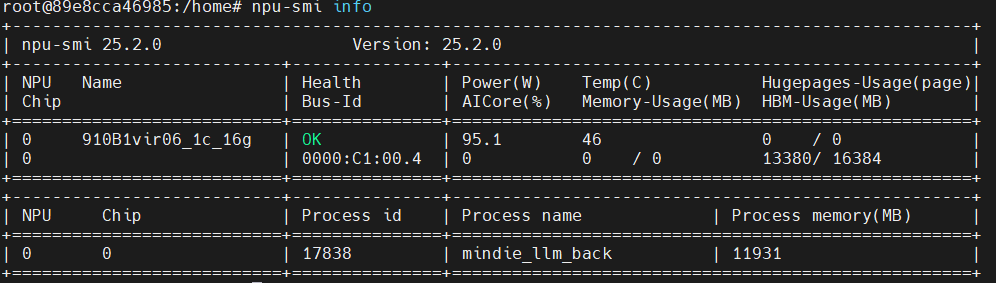
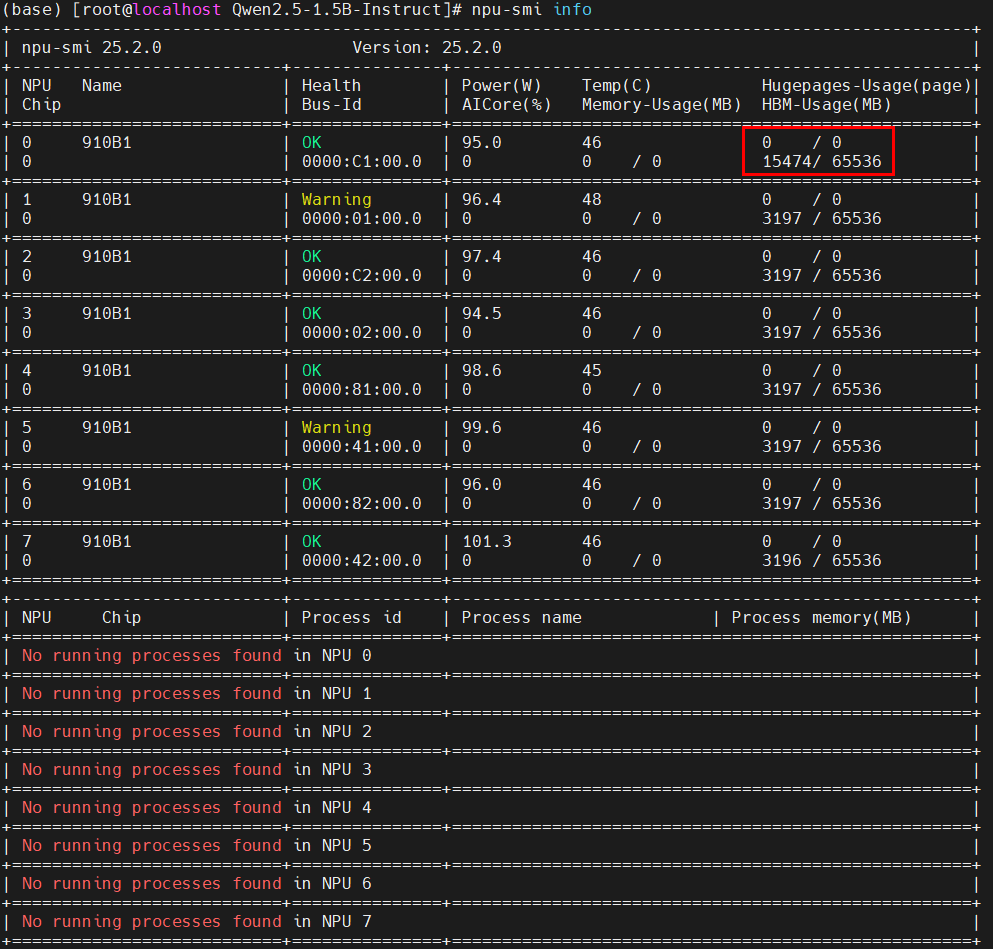
- vNPU的进程只能在容器里查看,容器外只能看到显存占用
容器内:
裸机:

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)