
昇思25天打卡营-mindspore-ML- Day4预处理
学习了数据的变换,背景是,原始数据给到神经网络时往往需要进行归一化等处理,这里给出了详细的预处理方式。
·
学习了数据的变换,背景是,原始数据给到神经网络时往往需要进行归一化等处理,这里给出了详细的预处理方式。主要内容是:
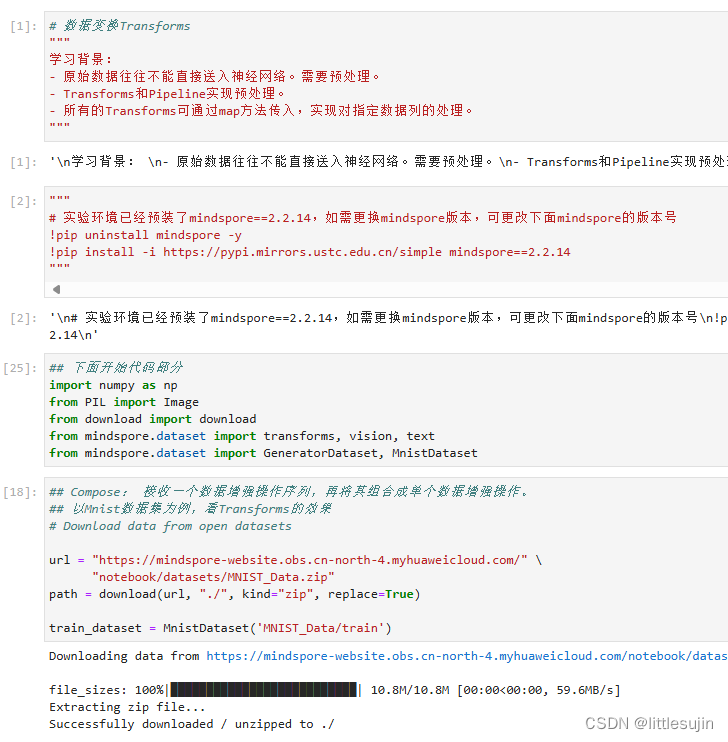
- 从指定的URL下载MNIST数据集,并保存到当前目录下的MNIST_Data.zip文件中。
- 加载训练数据集,并打印第一个图像的形状。
- 使用Compose函数创建一个包含多个数据增强操作的管道,包括重新缩放、归一化和维度转换。
- 对训练数据集应用数据增强操作,并打印第一个图像的形状。
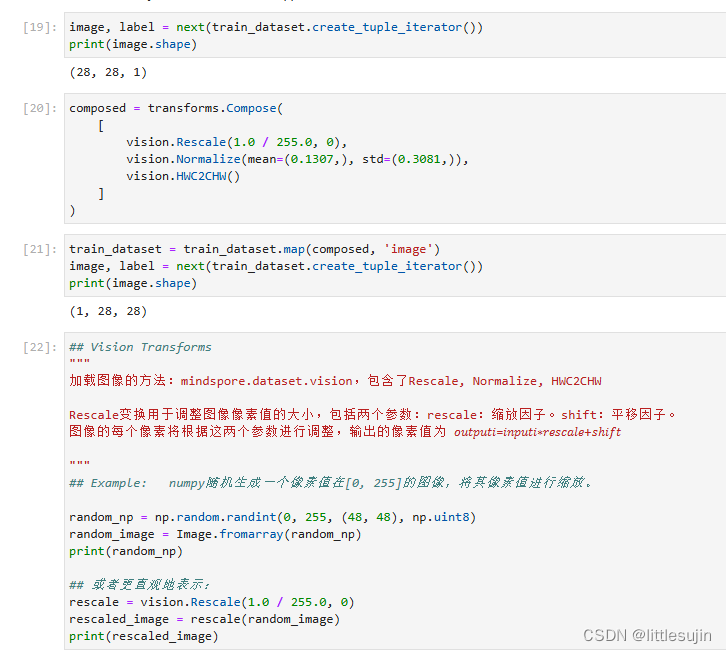
- 生成一个随机的48x48像素的图像,并将其转换为PIL图像对象。
- 使用Rescale函数重新缩放图像,并打印结果。
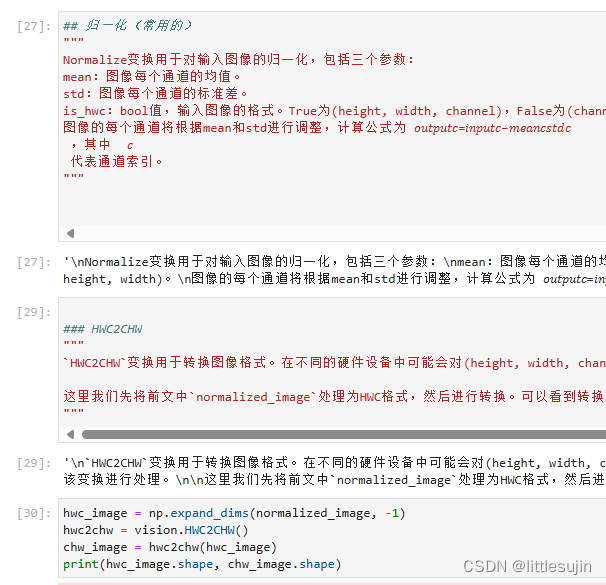
- 使用Normalize函数对图像进行归一化,并打印结果。
- 使用HWC2CHW函数将图像的维度从(height, width, channel)转换为(channel, height, width),并打印结果。
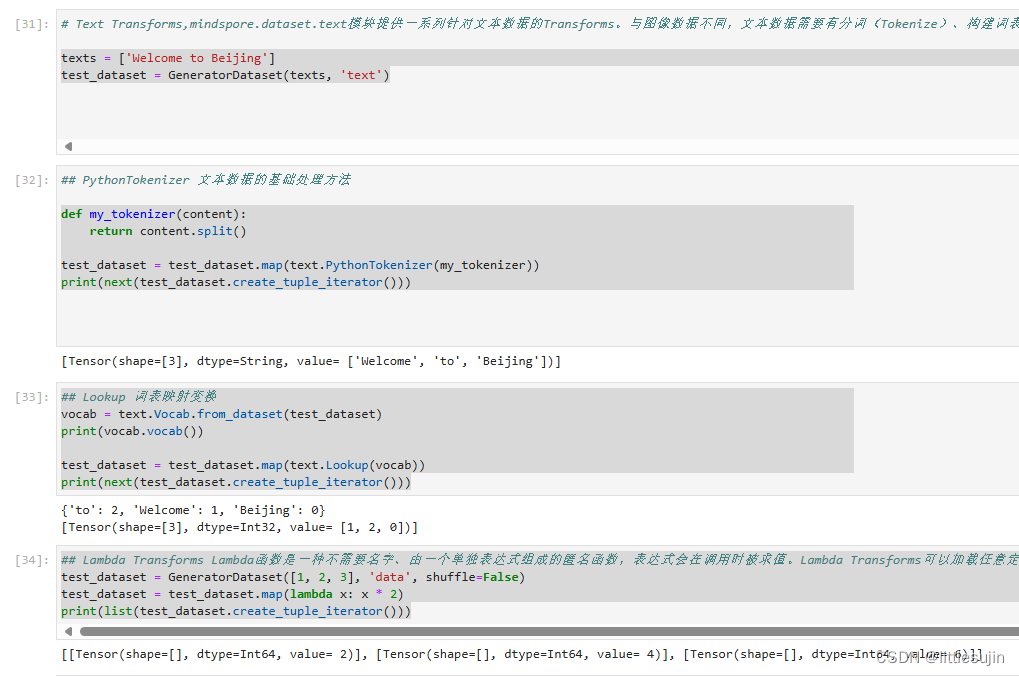
- 创建一个包含文本数据的生成器数据集,并使用自定义的分词器进行分词。
- 使用Vocab.from_dataset函数从数据集创建一个词汇表,并打印词汇表。
- 使用Lookup函数将文本数据转换为词汇表中的索引,并打印结果。
- 使用Lambda函数对数据集中的每个元素进行自定义操作,包括乘以2和计算x*x+2。

总结:
- 数据增强是一种常用的技术,可以提高模型的泛化能力和鲁棒性。
- Compose函数可以将多个数据增强操作组合成一个管道,方便对数据进行预处理。
- 使用PIL库可以方便地进行图像的读取和转换操作。
- 使用Rescale、Normalize和HWC2CHW等函数可以方便地进行图像的缩放、归一化和维度转换。
- 使用自定义的分词器可以方便地对文本数据进行预处理。
- 使用Vocab.from_dataset函数可以方便地从数据集创建一个词汇表。
- 使用Lookup函数可以将文本数据转换为词汇表中的索引,方便进行后续的模型训练。
- Lambda函数可以提供足够的灵活度,对数据进行自定义的预处理操作。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)