
又爆雷了!
技术路线,使用是否合规,而且,目前这种迁移工具并没有在行业内形成统一的标准,不同版本、不同发行者带来的问题可能是不一样的,会造成许多使用和维护上的问题这给我们用户单位带来很多的不可控的风险;三是我们小组在迁移的过程中遇到问题或者困难的时候,想请鲲鹏的技术人员提供技术支持,但是对于迁移过程引发的bug,从需要对源代码的原理、逻辑进行分析,大家都知道任何一个机构的源码是非常非常重要的并且隐私性和机密性
之前跟大家分享过,ARM迁移有多费劲,中间又有多少坑,也梳理过有哪些需要避雷的点。但是万万没想到啊,最近是又遇到新坑了,唉……
近期一个项目,也是往主流的国产化芯片上改造、迁移。客户要求对投资组管理系统向鲲鹏920-7260双路服务器迁移工作。但之前的研发、测试等相关工作都是基于Intel平台设计和产出的,其实甲方技术部门初期替换意向也不是ARM平台,但是因为一些原因(众所周知,这里就不点明了),上头领导最后还是拍板要换成KP。甲方技术部门很无奈,我们更无奈……本次更换为ARM架构,项目推进也颇为曲折。
不说了,下面接着分享些经验干货,帮大家避坑避雷。
不多说,分享一些技术坑给大家,尽量避免踩相同的坑,当然源码不能给大家展示,以大家比较熟悉的以某个glibc-2.17-xx src.rpm包举例。
glibc-2.17的源码目录下共计1万多个文件,除了文本的说明文件外,不能放对于你自身研发所涉及的任何代码,否则后期通过各种测试、跟踪手段及工具去定位功能的完整性和结果的精度将给带来前所未有的酸爽。

首先,从基础的数据类型的定义角度来说。char 类型在不同的 CPU 架构和编译器中可能会有不同的表现。char 是 C 和 C++ 标准中定义的一种基本类型,通常被用于存储小整数值。在许多系统中,char 被视为有符号的,即最高位被用作符号位。然而,在ARM架构,char 被视为无符号的,即所有位都被用作数值,并且ARM和其他架构对char定义数据范围也是不一样的,如果单纯的修改字符型定义类型,可能会对你之前代码的逻辑带来比较大的影响,所以,一定要结合源码的逻辑进行调整。当你在移植代码时,如果你需要确保 char 变量总是被视为有符号的,你可以在变量声明时明确指定 signed char。这样可以确保你的代码在所有平台上都能按照你预期的方式运行。这是移植代码时需要考虑的重要问题。
那在glibc-2.17的源码中有多少处对char的定义呢?答案是38291处位置,所以在进行关键字符替换的途径是不行的,防止除了有char的定义外,还有unsigned char或者signed char,毕竟每个人写代码的风格和习惯是不同的,尤其是在老舅(“老旧”)软件里。

其次,数值类型装换。任何一家的软件代买都有数值转换的操作。因为,在处理不同数据类型的变量时,可能需要进行数值转换。例如,你可能需要将一个字符串(文本数据)转换为整数或浮点数(数值数据),以便进行数学运算或数据分析;而且,有时候,数据可能以不同的格式存储或显示,这时就需要进行数值转换。更重要的是,在某些情况下,将数据转换为特定的类型可以提供更好的性能。比如说double数据向long转换:
|
CPU |
double值 |
转为long变量保留值 |
说明 |
|
x86 |
正值超出long范围 |
0x8000000000000000 |
indefinite integer value |
|
x86 |
负值超出long范围 |
0x8000000000000000 |
indefinite integer value |
|
鲲鹏 |
正值超出long范围 |
0x7FFFFFFFFFFFFFFF |
鲲鹏为long变量赋值最大的正数 |
|
鲲鹏 |
负值超出long范围 |
0x8000000000000000 |
鲲鹏为long变量赋值最大的负数 |
再者,编译环节,优化参数的引入造成精度的丢失。大家写好代码的时候,我们可定会对代码编译引入很多优化选项,比如-O3,我们以下面代码为为例。
|
内容 |
|
|
代码 |
#include <math.h> #include <stdio.h> int main() { double dv[] = {-0.13942759833577333949961030157283, -0.046687081540714665817137785097657, -0.48496455527857718070805503884912, -0.60722091847450498924843032000354, 1, 1, 0, 0, -3.4221570491790771484375}; double dw[] = {0.019916933333333299710465880139054, -0.021317733333333300366208007403657, 0.13007783333333300390677322866395, 0.0013823433333333299752321288167423, 0.11358973333333299837732965897885, 0.21664233333333299258427473432675, -0.078728843333333298204479433479719, 0.31518266666666699959975517231214, 0.10316096666666700609749085515432 }; double dp = 0.0; int i = 0; for(i=0; i<9; i++){ dp += dv[i]*dw[i]; printf("\n========================"); printf("\ndv[%d]:%.32f ", i,dv[i]); printf("\ndw[%d]:%.32f ", i, dw[i]); printf("\ndp=dp+dv[%d]*dw[%d]:%.32f ", i,i,dp); printf("\n"); } return 0; } |
|
不使用-O3 |
# gcc -g test.c -o runtest
无论arm平台还是x86平台输出的结果都是一致的。 |
|
使用-O3 |
同样的代码,在加上-O3参数以后,发现ARM平台的计算结果从小数点后17位开始出现与不加-O3的差异,双精度浮点运算结果精度明显丢失 |
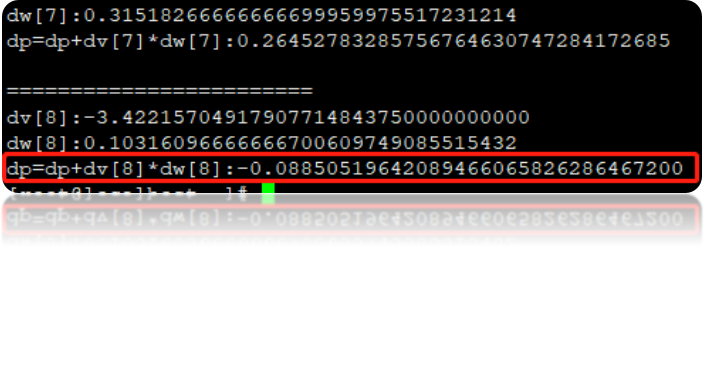

另外,不知道大家有没有注意到一个细节,ARM架构处理器编译后的二进制文件和动态库会明显变大,会导致装载程序的时间增加,内存空间和内存I/O消耗大。例如,写一个简单hello word的C程序。
 最简单编译命令: # gcc helloworld.c
最简单编译命令: # gcc helloworld.c
![]()
所得到的静态二进制文件的大小:x86是8.4K;arm是70K。
软件应用层面,各类生态最大的区别就是指令集的差异,而指令集直接决定了生态结构和体系哪些能用?哪些不能用?以及应用或者业务及性能和效率。
作为开发人员,如果遇到业务迁移到Arm平台,抛开测试不谈,工作量主要集中在两个方面:
一、架构转换带来的成本:将业务系统转移到Arm架构,需要对源代码进行改造,改造后要使用合适的编译器进行重新编译,编译过程中,所使用的动态库或者静态库以及软件运行所需的依赖库,都需要进行调整,这不仅需要投入大量的人力成本和时间成本,还可能涉及到代码结构的调整和优化。尽管有些语言具备跨架构的能力,但仍然可能存在一些架构相关的依赖和特性,使得在新的架构上运行需要做出一些调整,即使有辅助工具加持迁移,但是也无法确保和原有的业务功能、性能保持完全一致,甚至引入新的风险或者bug,因为这本身就是一项非常繁复的工作。
二、开发语言生态的不完善:Arm架构的开发语言可能不那么健全,这会增加开发人员的额外负担,要控制好变量的定义,以及数据在函数处理过程中的输入和输出,同时还要考虑代码的健壮性和数据结果的精确度。他们可能需要关注一些与开发语言本身无关的问题,例如语言运行环境的重新编译和与各种开源中间件的适配工作。
鲲鹏提供了Devkit迁移工具,能够简化迁移过程,但是面临三个问题,一是工具本身是否安全,是否会带来源码泄露的风险,虽然签了保密合规的协议,但是工具不是内部开发的,还是要比较慎重的使用;二是Devkit工具并未开源,我们当下用鲲鹏服务器,可以正常使用,如果换成其他ARM技术路线,使用是否合规,而且,目前这种迁移工具并没有在行业内形成统一的标准,不同版本、不同发行者带来的问题可能是不一样的,会造成许多使用和维护上的问题这给我们用户单位带来很多的不可控的风险;三是我们小组在迁移的过程中遇到问题或者困难的时候,想请鲲鹏的技术人员提供技术支持,但是对于迁移过程引发的bug,从需要对源代码的原理、逻辑进行分析,大家都知道任何一个机构的源码是非常非常重要的并且隐私性和机密性都比较高,源码是不公开的,那么整个迁移的过程对我们的技术人员的能力要求非常高。
整个迁移的过程周期特别长,而且自我消耗非常严重,全员都精疲力尽。所以如果想要迁移到ARM,做好持久战的准备,做好人员成本、时间成本高昂的准备。
不过还是尽量奉劝各位老板,尽量不要异构移植,这种行为劳民伤财。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)