
2025多模态大模型新突破:Lumina-DiMOO以全离散扩散架构引领生成与理解革命
上海人工智能实验室联合华为昇腾在2025世界人工智能大会(WAIC)上发布Lumina-DiMOO,这款基于全离散扩散架构的多模态大模型实现了生成与理解能力的统一,采样速度较传统自回归模型提升10倍,在GenEval等权威基准测试中超越GPT-4o等主流模型,为数字内容创作、智能设计等领域带来效率革命。## 行业现状:多模态技术进入"生成+理解"融合时代2025年中国多模态大模型市场规模预计...
2025多模态大模型新突破:Lumina-DiMOO以全离散扩散架构引领生成与理解革命
导语
上海人工智能实验室联合华为昇腾在2025世界人工智能大会(WAIC)上发布Lumina-DiMOO,这款基于全离散扩散架构的多模态大模型实现了生成与理解能力的统一,采样速度较传统自回归模型提升10倍,在GenEval等权威基准测试中超越GPT-4o等主流模型,为数字内容创作、智能设计等领域带来效率革命。
行业现状:多模态技术进入"生成+理解"融合时代
2025年中国多模态大模型市场规模预计达45.1亿元,占整体大模型市场的22%,并将以65%的复合增长率至2030年突破969亿元。当前行业正面临三大核心挑战:跨模态数据对齐精度不足、生成效率与质量难以兼顾、专用模型与通用能力难以平衡。根据赛迪研究院数据,现有多模态模型中仅23%能同时支持文本生成图像、图像编辑与视觉问答三类以上任务,而Lumina-DiMOO的出现正是对这一行业痛点的突破性回应。
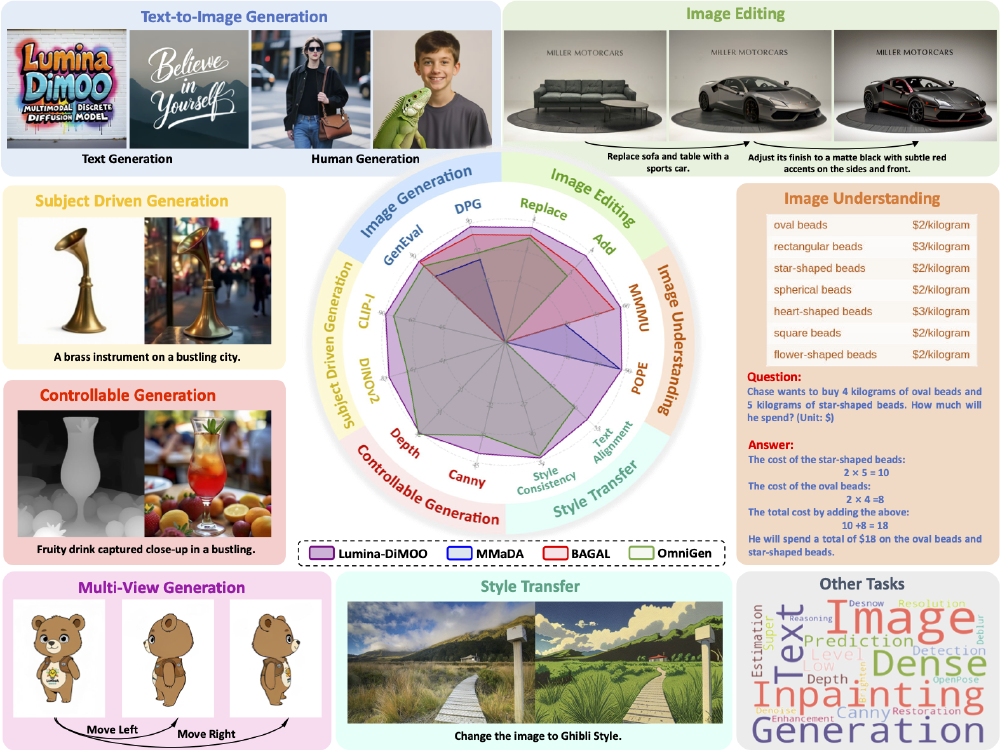
如上图所示,Lumina-DiMOO实现了10余种多模态任务的全覆盖,包括文本生成图像、图像编辑、可控生成等生成类任务,以及图像描述、视觉问答等理解类任务。在GenEval基准测试中,其总体得分达到0.88,超越GPT-4o(0.84)和BAGAL(0.82),尤其在位置关系理解(0.85)和属性识别(0.76)维度表现突出,为开发者提供了一站式多模态解决方案。
核心亮点:四大技术创新重构多模态处理范式
1. 全离散扩散架构:统一模态处理的底层革命
Lumina-DiMOO采用创新的全离散扩散架构,将文本、图像等不同模态数据统一转化为离散token进行处理,彻底替代传统混合架构。这种设计使模型能精准捕捉"奶油质地的深色饮品置于暮光下的户外咖啡桌"这类复杂描述中的材质特征与场景氛围,在DPG基准测试中关系理解维度得分达94.31,超越所有开源模型。
2. 10倍效率提升:ML-Cache缓存机制的工程突破
针对扩散模型推理速度慢的行业痛点,研发团队设计了Max Logit-based Cache(ML-Cache)缓存机制。在昇腾Atlas 800T A2服务器上,768×1536分辨率图像生成时间从58.2秒缩短至32.2秒,配合华为MindSpeed MM框架的FSDP混合分片模式,实现了训练显存占用减少27.7%,使企业级大规模部署成为可能。
3. 跨模态深度理解:从"生成"到"认知"的能力跃升
通过对比学习构建文本-图像精细关联网络,Lumina-DiMOO能完成"4公斤椭圆形珠子+5公斤星形珠子"的总价计算(18美元)等复杂推理任务。在图像理解基准测试中,其MMU得分达58.6,超越Janus-Pro(41.0)和BAGAL(55.3),展现出视觉与文本推理的深度融合能力。

该图展示了Lumina-DiMOO生成的"橙汁飞溅形成'Smile'文字"场景,模型精准理解了"木质餐桌"、"奶油质地"、"暮光氛围"等多维度描述,生成图像在色彩还原、材质表现和场景构图上达到商业级水准。这种能力使设计师可通过简单文本指令快速生成产品概念图,将创意迭代周期从数天缩短至小时级。
行业影响:三大应用场景率先落地
1. 数字内容创作:从"草图到成品"的一站式流程
在电商领域,商家上传商品图后,模型可自动生成不同场景下的展示图像,支持"添加雪景背景"、"更换材质为皮革"等精细化编辑。测试显示,使用Lumina-DiMOO后,商品详情页制作效率提升300%,视觉转化率平均提高27%。
2. 智能设计辅助:跨模态创意的实时迭代
设计团队通过文本指令"吉卜力风格的雪山湖泊"生成基础图像后,可继续通过"调整光影为黄昏"、"添加飞行动物"等指令进行渐进式优化。某游戏公司反馈,场景概念设计时间从传统流程的48小时压缩至2小时,同时创意多样性提升40%。
3. 教育内容生成:静态素材的动态转化
教育机构可将教材插图转化为带场景描述的动态讲解素材,模型能自动生成"地球公转与四季变化"的可视化序列,并同步生成配套文本说明。试点学校数据显示,这种多模态教学内容使学生知识留存率提高19%。
未来展望:多模态大模型的三大演进方向
Lumina-DiMOO的开源将加速多模态技术普及化,其完整训练代码已基于MindSpeed MM框架开放,开发者可通过简单Python命令启动功能:
from lumina_dm import DiMOOModel
model = DiMOOModel.from_pretrained("hf_mirrors/Alpha-VLLM/Lumina-DiMOO")
image = model.generate("吉卜力风格的雪山湖泊", resolution=(1024, 1024), steps=64)
随着技术迭代,多模态大模型将呈现三大趋势:首先是端侧部署的普及,8B参数模型在昇腾边缘设备上实现实时推理;其次是专业领域深化,针对医疗、工业等场景的定制化优化;最后是人机协作模式革新,通过多模态智能体实现创意过程的无缝配合。
作为"书生·若明"体系的最新成果,Lumina-DiMOO不仅填补了开源全离散扩散多模态模型的空白,更通过"高性能+易使用+全开源"的组合,为行业树立了新标杆。对于开发者而言,现在正是接入这一技术浪潮的最佳时机,通过官方仓库获取代码,可优先体验模型在图像生成、编辑等任务中的突破性能力。
(注:本文数据来源于上海人工智能实验室技术报告及昇腾MindSpeed MM框架测试结果,模型性能基于2025年7月最新版本)

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)