
昇思25天打卡训练营第4天|数据集
4)自定义数据集:mindspore提供了一系列公开的数据集和可供调用的API.对于不支持的数据集,可以通过自定义加载类和自定义数据集生成函数的方式来生成,通过GeneratorDataset接口自定义数据集加载方式,该接口支持通过可随机访问数据集对象、可迭代数据集对象以及生成器generator构造自定义数据集.Dataset是Pipeline的起始,用于加载原始数据.mindspore.dat
MindSpore提供基于Pipeline的数据引擎,通过数据集与数据变换实现高效的数据预处理.
Dataset是Pipeline的起始,用于加载原始数据.mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口.
MindSpore领域开发库也提供了大量的预加载数据集.
import numpy as np
from mindspore.dataset import vision,MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt
import time
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())),'xxxx')
![]()
下边代码给出使用mindspore.dataset加载Mnist数据集的方法
from download import download
url="https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/"\
"notebook/datasets/MNIST_Data.zip"
path=download(url,"./",kind="zip",replace=True)

压缩文件删除后直接加载可以看到数据类型为MnistDataset
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))
![]()
数据集加载后可以用create_tuple_iterator与create_dict_iterator接口创建数据迭代器,迭代访问数据.访问的数据类型默认为Tensor,若设置output_numpy=True,访问类型为Numpy.
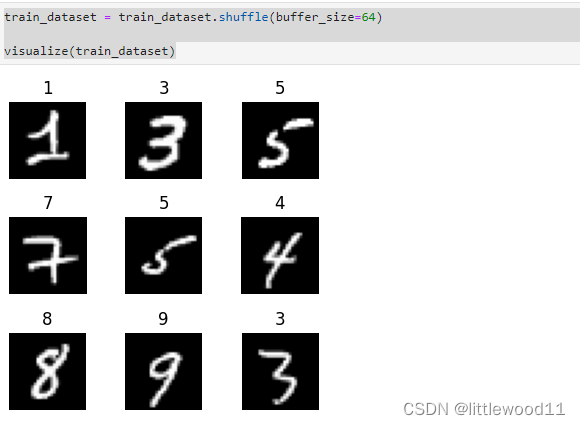
例:定义可视化函数,迭代9张图片进行展示
def visualize(dataset):
figure = plt.figure(figsize=(4,4))
cols,rows=3,3
plt.subplots_adjust(wspace=0.5,hspace=0.5)
for idx,(image,label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows,cols,idx+1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
visualize(train_dataset)

数据集常用操作
Pipeline设计理念使数据集常用操作采用dataset=dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时并行执行整个Pipeline.
1)shuffle:数据集随机可以消除数据排列造成的分布不均匀问题
mindspore.dataset提供的数据集在加载时可以配置shuffle=True,或
train_dataset = train_dataset.shuffle(buffer_size=64)
visualize(train_dataset)
2)map:数据预处理的关键操作,针对数据集指定column添加数据变换Transforms.将数据变换用于该列数据每个元素,返回包含变换后元素的新数据集.
image,label=next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
![]()
这里对Mnist数据集做数据缩放处理,将图像统一除以255,数据类型由uint8转为float32
train_dataset = train_dataset.map(vision.Rescale(1.0/255.0,0))
image,label=next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
![]()
3)batch:将数据集打包为固定大小的batch在有限硬件资源下使用梯度下降进行模型优化折中方法,可以保证梯度下降的随机性和优化计算量(固定batch_size,连续数据分若干批)
train_dataset = train_dataset.batch(batch_size=32)
image,label=next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
![]()
4)自定义数据集:mindspore提供了一系列公开的数据集和可供调用的API.对于不支持的数据集,可以通过自定义加载类和自定义数据集生成函数的方式来生成,通过GeneratorDataset接口自定义数据集加载方式,该接口支持通过可随机访问数据集对象、可迭代数据集对象以及生成器generator构造自定义数据集.
- 可随机访问数据集
实现了__getitem__和__len__接口,可以通过索引、键值直接访问数据集对应位置的数据样本.
class RandomAccessDataSet:
def __init__(self):
self._data = np.ones((5,2))
self._zeros = np.zeros((5,1))
def __getitem__(self, index):
return self._data[index], self._label[index]
def __len__(self):
return len(self._data)
可按下边方式加载数据集:
loader = RandonAccessDataSet()
dataset = GeneratorDataset(source=loader, column_names=['data','label'])
for data in dataset:
print(data)
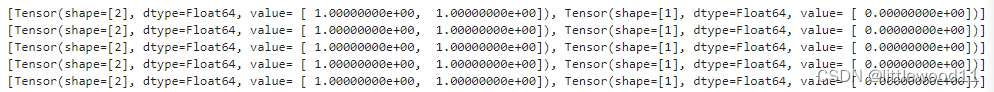
或
loader=[np.array(0), np.array(1), np.array(2)]
dataset = GeneratorDataset(source=loader, column_names=['data'])

- 可迭代数据集
实现了__iter__与__next__接口,可以通过迭代的方式访问数据集,适用于随机访问成本太高或不可行的情况
class IterableDataSet:
def __init__(self, start, end):
self.start = start
self.end = end
def __next__(self):
return next(self.data)
def __iter__(self):
self.data =iter(range(self.start,self.end))
return self
loader = IterableDataSet(1,5)
dataset = GeneratorDataset(source=loader, column_names=['data'])
for data in dataset:
print(data)

- 生成器
属于可迭代的数据集类型,依赖于python的生成器generator得到数据,直至抛出StopIteration异常
def my_generator(start,end):
for i in range(start,end):
yield i
dataset = GeneratorDataset(source = lambda:my_generator(1,5),column_names=['data'])
for d in dataset:
print(d)


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)