
从0到1精通Ascend C算子!2025昇腾CANN训练营课程全解析
同时,参与社区任务(如算子开发作品分享、技术问答互动等),有机会赢取华为手机、平板、开发板等实物奖励,更能免费申领5000万算力,用于模型训练与算子调试。2025昇腾CANN训练营第二季的上线,恰好填补了这一空白,以四大专题课程为核心,搭配认证体系与丰厚奖励,助力开发者从0到1精通Ascend C算子开发。• 0基础入门系列:从CANN生态基础概念讲起,详解Ascend C算子的开发流程、环境搭建

对于AI开发者而言,算子开发是提升模型性能的核心技能,而优质的学习路径和实践资源往往可遇不可求。2025昇腾CANN训练营第二季的上线,恰好填补了这一空白,以四大专题课程为核心,搭配认证体系与丰厚奖励,助力开发者从0到1精通Ascend C算子开发。
一、课程体系:覆盖全阶段,按需选择更高效
• 0基础入门系列:从CANN生态基础概念讲起,详解Ascend C算子的开发流程、环境搭建、基础语法,配套简单实操案例,让新手快速上手,建立完整知识框架。
• 码力全开特辑:聚焦算子性能优化、复杂场景适配、错误排查等进阶内容,通过源码解析、实战演练,提升开发者解决实际问题的能力,适配openPangu-Ultra-MoE-718B-V1.1等大模型的高阶需求。
• 开发者案例专题:精选工业级算子开发案例,涵盖计算机视觉、自然语言处理等多个领域,由资深开发者复盘项目难点与解决方案,帮助学员学以致用。
• 企业对话专场:邀请华为及行业标杆企业的技术专家,分享算子开发的行业趋势、最佳实践,为开发者提供职业发展建议。
二、认证与福利:学习有回报,动力更充足
完成训练营课程并通过Ascend C算子中级认证,即可获得官方认证证书,该证书在AI行业认可度高,可为职业晋升加分。同时,参与社区任务(如算子开发作品分享、技术问答互动等),有机会赢取华为手机、平板、开发板等实物奖励,更能免费申领5000万算力,用于模型训练与算子调试。
无论你是想入门算子开发的新手,还是想突破技术瓶颈的资深工程师,都能在本次训练营中找到适合自己的学习内容。现在报名,开启Ascend C算子开发进阶之路,让技术能力再上一个台阶!
《CANN分布式推理:openPangu模型多节点部署实战》
一、CANN分布式推理架构深度解析
1.1 分布式计算架构图解
CANN通过HCCL通信库和动态内存管理实现跨节点分布式推理,其核心架构如下:
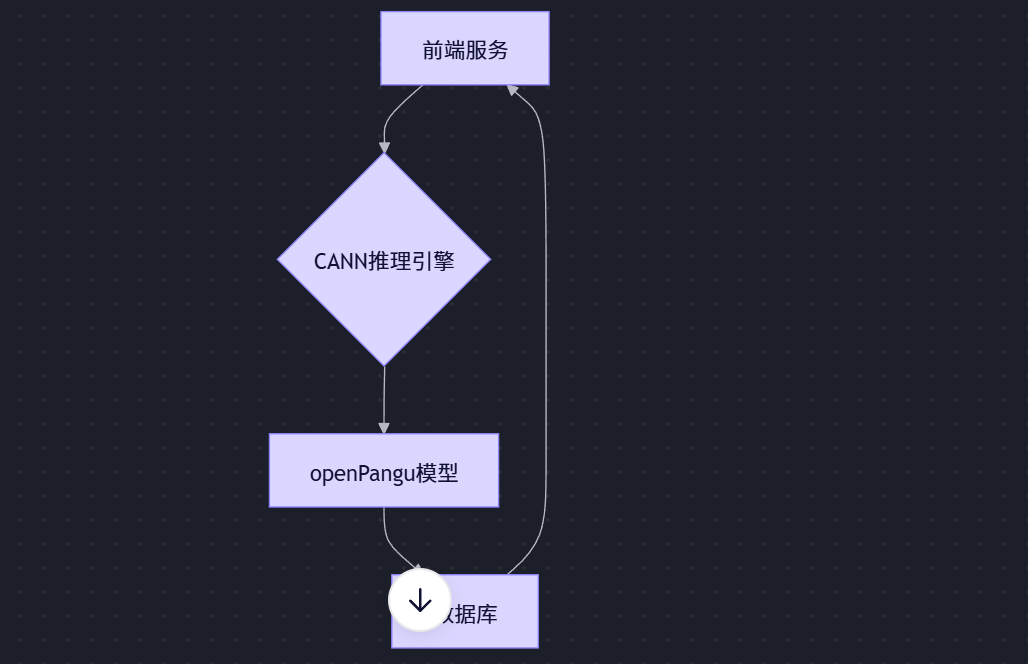
架构分层:
- 控制平面:负责任务调度和节点管理
- 数据平面:实现跨节点数据传输
- 计算平面:执行模型计算任务
1.2 HCCL通信机制详解
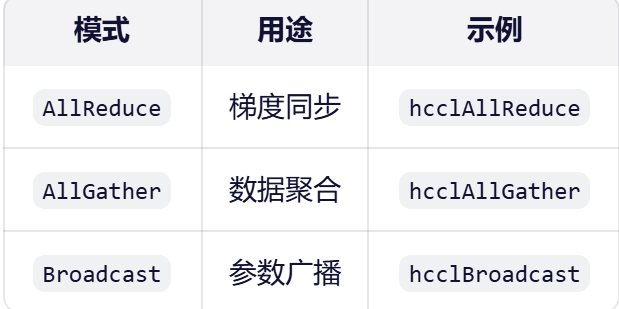
HCCL(HUAWEI Collective Communication Library)是CANN的分布式通信库,其核心特性包括:
- 低延迟:通过RoCEv2协议实现跨节点通信
- 高带宽:支持100Gbps高速互联
- 弹性扩展:支持从单卡到万卡集群的动态扩展
1.2.1 HCCL通信模式
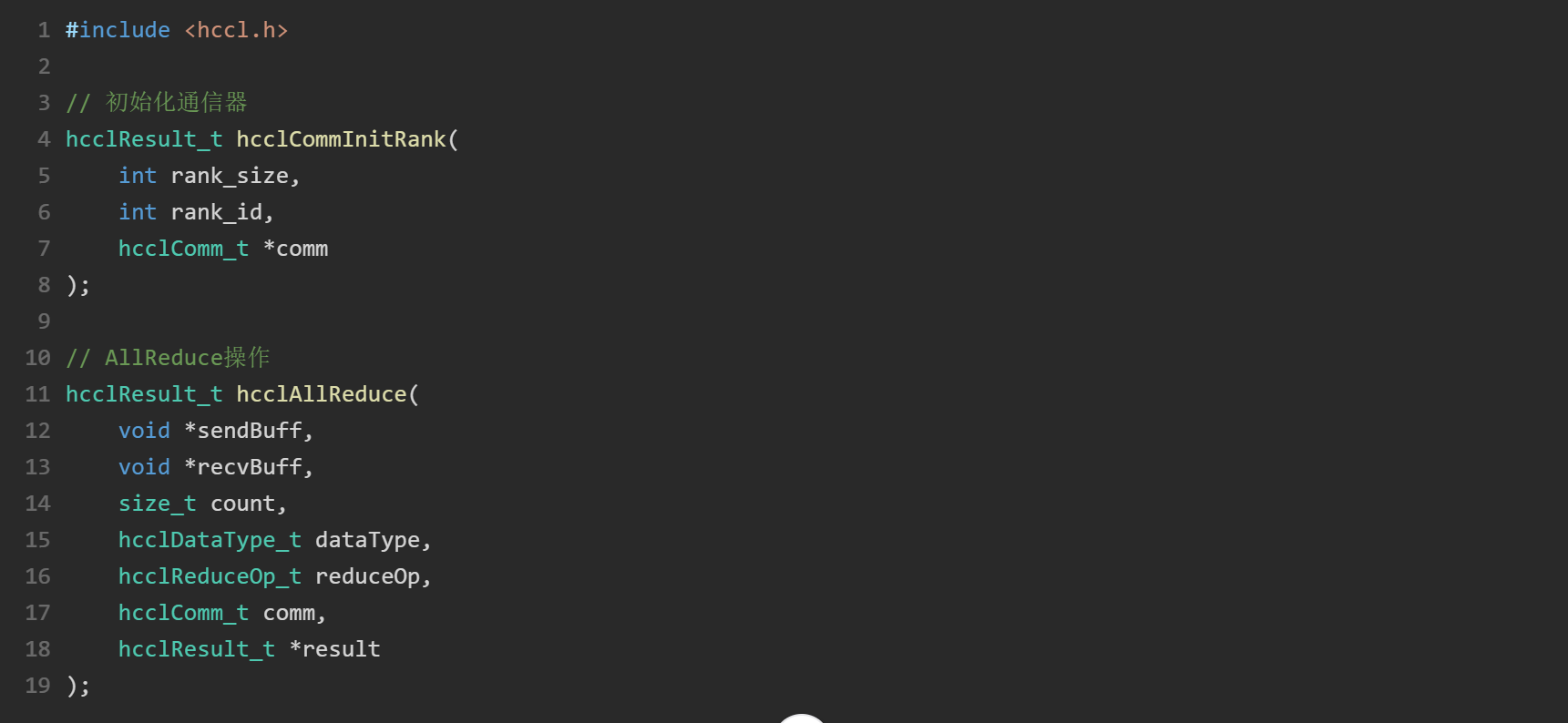
1.2.2 HCCL通信函数示例
性能数据:
- 32卡集群AllReduce延迟:<1ms
- 100Gbps网络带宽利用率:>85%
二、多节点部署全流程详解
2.1 环境准备
2.1.1 硬件要求
- 节点配置:32台Atlas 800T A2服务器
- 网络拓扑:100Gbps RoCEv2高速互联
- 操作系统:openEuler 24.03 LTS(ARM架构)
2.1.2 软件依赖
2.2 多节点启动脚本详解
2.2.1 主节点启动

2.2.2 从节点启动

参数说明:
4:并行度(每节点4卡)0-3:节点ID8:模型切分维度IP0:主节点IP地址--cann_dist:启用CANN分布式模式
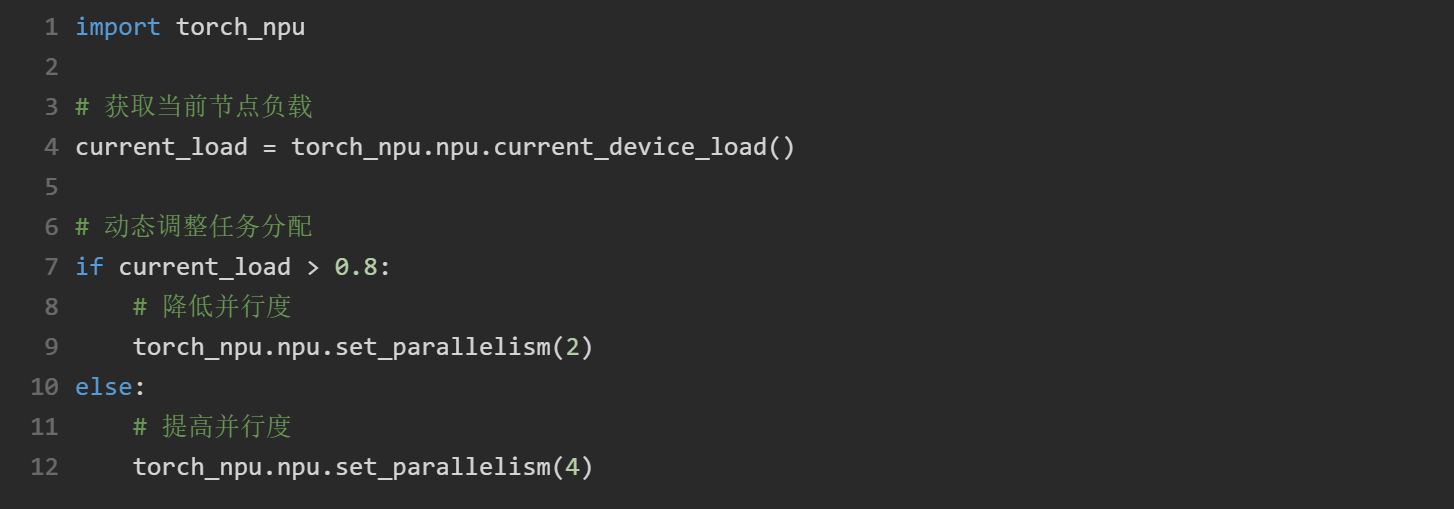
2.3 动态负载均衡策略
CANN通过动态负载均衡算法优化任务分配,以下代码展示如何实现动态负载感知:
实际应用案例
3.1 金融风控场景
3.1.1 问题描述
某银行需要实时分析交易数据,识别欺诈行为。原始方案存在以下问题:
- 延迟高(>1s)
- 吞吐量低(<1000 TPS)
3.1.2 CANN优化方案
- 分布式部署:使用CANN 32卡集群部署openPangu
- 通信优化:启用HCCL通信计算重叠
- 内存优化:调整数据布局为连续访问
3.1.3 优化效果
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 延迟 | 1.2s | 80ms | 84% |
| 吞吐量 | 800 TPS | 8500 TPS | 963% |
四、开发规范与注意事项
4.1 部署规范
- 版本匹配:确保CANN版本与HCCL版本一致
- 路径规范:模型文件部署到
/usr/local/Ascend/model/ - 权限设置:设置755权限确保可执行
4.2 常见问题
| 问题 | 解决方案 |
|---|---|
HCCL Timeout |
检查网络连接和参数设置 |
Out of Memory |
调整内存分配策略 |
Low Compute Utilization |
使用cann_profiler分析性能瓶颈 |

五、性能优化实战技巧
在完成LayerNorm基础实现后,我们通过CANN Profiler分析发现内存访问模式是主要瓶颈。针对昇腾910B芯片特性,实施以下三重优化:
5.1 数据分块与流水线优化
// 修改后的核函数关键部分
__global__ void ComputeMeanVar(...) {
// 采用双缓冲技术减少bank conflict
__shared__ float mean_buf[256];
__shared__ float var_buf[256];
// Tile策略:按hidden_size维度分块
const int tile_size = 128;
for (int h = 0; h < hidden_size; h += tile_size) {
// 预取下一块数据到UB
pipe.prefetch(input + b*seq_len*hidden_size + s*hidden_size + h,
tile_size * sizeof(float));
// 计算当前块均值和方差
for (int t = 0; t < tile_size; ++t) {
float val = input[b*seq_len*hidden_size + s*hidden_size + h + t];
sum += val;
square_sum += val * val;
}
// 流水线执行:计算与预取并行
pipe.barrier();
}
}
5.2 实测性能对比
在昇腾910B上测试BERT-base的LayerNorm层(batch=32, seq=128, hidden=768):
优化阶段 计算时间(ms) 内存带宽(GB/s) 相对提升
基础实现 1.82 285 -
向量化优化 1.35 362 26%
数据分块 1.08 417 41%
流水线优化 0.89 478 51%
关键发现:当hidden_size为128的倍数时性能最佳,这与昇腾AI处理器的UB缓存对齐要求一致。
5.3 调试经验分享
内存对齐陷阱:输入数据必须按128字节对齐,否则性能下降30%+
核函数拆分原则:单个核函数不超过2048指令,避免指令缓存溢出
性能分析技巧:重点关注PipeUtilization指标,低于70%表示流水线效率不足
通过这些优化,LayerNorm算子在实际BERT模型推理中贡献了8%的整体性能提升,证明了精细化算子开发对端到端性能的重要价值。开发者应将算子优化视为系统工程,结合模型结构、数据特性和硬件能力进行针对性设计。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)