
2025年CANN训练营第二季---抽象硬件架构
025年昇腾CANN训练营第二季提供算子开发专题课程,助力开发者技能提升,本章重点讲解AICore计算单元架构。
昇腾训练营报名链接:
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖
一、计算单元
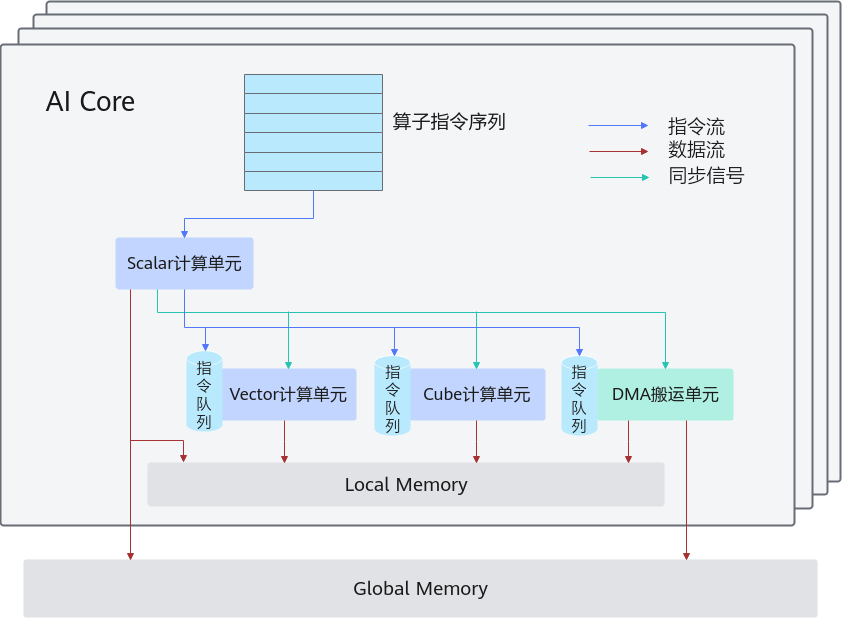
AICore包括三种计算单元,有Scalar计算单元、Vector计算单元和Cube计算单元。而在真实的算子工程中计算分为Host侧跟kernel侧,Host侧主要做的就是Scalar计算,计算包括需要搬运的数据块数量、一次搬运的数据长度,如果涉及到多核还需要计算核的长度、用到几个核参与计算等等,这些都是在Host侧完成,用到所需的Scalar计算单元。
而Vector计算单元和Cube计算单元则是负责具体的kernel侧计算,是运行在NPU上的,在Host侧完成相关计算后,就需要根据搬运的数据长度依次将数据搬运到NPU,调用AscendC 对应的API,在这次训练营中,所需要的API可以直接参考对应tbe算子的实现,不需要自己从头考虑算子设计逻辑,可以直接根据tbe算子的代码找到Ascend C对应的API来实现。Cube计算单元是进行矩阵乘法时,需要用到的计算单元,其开发流程要比Vector算子复杂一些。
二、Local与Global
数据都储存在Global中,计算时需要将数据通过队列从Global搬运到Local中,Host侧需要完成需要搬运的每个核的总长度,然后在Kernel侧,需要先根据计算的长度初始化资源,包括初始化队列,确定每次需要参与计算的数量,通过CopyIn函数搬运至Local中,在Compute函数中完成数据的计算操作,计算完成后通过CopyOut函数将输出的Localtensor搬出至Global,就可以进入下一次的循环计算,而上述的队列操作其实都是通过DMA搬运单元来完成的。
三、异步指令流与同步信号流
在图片中蓝色线条代表的是异步指令流,在AI Core芯片内部,Scalar计算单元充当着"指挥中心"的角色。它解析程序指令后,会将不同类型的任务——包括向量运算任务、矩阵运算任务以及数据传输任务——分发到各自专用处理单元的待执行任务队列中。这些专用单元(向量处理器、矩阵处理器、数据搬运控制器)会独立地、同时地处理各自队列中的指令,互不阻塞。这种工作模式就像流水线作业,确保了高效的并行执行。
图中的绿色箭头为同步信号流,确保单次计算的过程中不会受到其他的干扰,保证了计算过程的完成。由于各个处理单元是独立运行的,但某些指令之间存在先后顺序要求或数据依赖关系。例如,矩阵运算可能需要等待数据搬运完成后才能开始。为了确保这些有依赖关系的操作按正确顺序执行,标量处理器除了分发计算指令外,还会向各单元发送同步指令。这些同步指令就像"路口红绿灯",协调各单元之间的执行时序。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)