
《Ascend C算子开发:openPangu模型性能优化实战》
该模型规模达723.97B,支持BF16、F32双张量类型,适配Transformers框架,可满足算子开发、模型调试、性能测试等多场景需求,让开发者无需担忧算力成本,专注技术创新。2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。如果你想提升算子开发技能、获取免费算力、赢取华为大奖,不妨

Ascend C语言特性详解
Ascend C作为华为昇腾NPU的专用编程语言,为开发者提供了深度优化算子性能的能力。在openPangu-Ultra-MoE-718B-V1.1模型的开发中,Ascend C通过硬件加速指令集、内存布局优化、混合精度计算等技术手段,显著提升了模型推理效率。本文将从Ascend C语言特性、算子开发流程、性能优化策略、实际应用案例等多个维度,详细解析如何通过Ascend C实现openPangu模型的极致性能优化。
通过__aicpu_parallel_for__和__aicpu_vectorize__指令实现自动并行和向量化计算。其核心特性包括:
- 原生C/C++支持:兼容标准C/C++语法,支持复杂数据结构
- 自动并行计算:通过指令隐式并行化计算任务
- 多层接口抽象:提供API、Kernel、Device三层接口
在大模型部署过程中,硬件算力利用率与模型推理效率的矛盾日益突出,华为昇腾NPU专用开发语言Ascend C凭借其底层优化能力,成为解决这一问题的关键工具。本文结合openPangu-Ultra-MoE-718B-V1.1模型的优化实践,详解Ascend C算子开发的核心逻辑与落地路径。
Ascend C兼容C/C++语法体系,降低了开发者的学习门槛,同时提供多层接口抽象,支持从底层指令到高层应用的全栈式开发。其核心优势在于原生支持自动并行与向量化编程,通过__aicpu_parallel_for__指令可实现任务的多线程拆分,__aicpu_vectorize__则能充分利用NPU的向量计算单元,大幅提升数据处理吞吐量。在openPangu模型优化中,针对MoE架构的专家路由模块,开发团队通过Ascend C实现了算子的定制化设计,将原本分散的计算任务整合为高效的批量处理流程,从硬件层面解决了MoE模型专家调度的开销问题。
在编译部署环节,需严格适配CANN环境的版本要求,通过-O3编译优化选项开启编译器的深度优化,同时结合内存对齐技术减少数据访问 latency。针对大模型显存占用高的问题,采用bfloat16与FP32混合精度计算策略,在保证模型精度损失可控的前提下,将显存占用降低50%以上。调试验证阶段,借助昇腾提供的内存分析工具与性能 profiling 组件,精准定位算子执行过程中的瓶颈,通过优化数据搬运路径、调整线程块大小等方式,最终实现模型并行度与吞吐量的双重提升,优化后整体性能较优化前提升400%。
此外,算子开发需遵循严格的规范标准,核函数采用CamelCase命名规则,确保代码的可读性与可维护性;部署过程中需注意路径配置与权限设置,避免因环境变量缺失或文件访问权限不足导致的部署失败。对于复杂算子的开发,建议采用模块化设计思路,将计算逻辑与数据处理分离,便于后续的迭代优化与功能扩展。通过Ascend C的深度优化,openPangu模型在昇腾NPU上实现了高效部署,为大模型的工业化应用提供了可行的技术方案。
1. 算子开发全流程
算子设计与分析
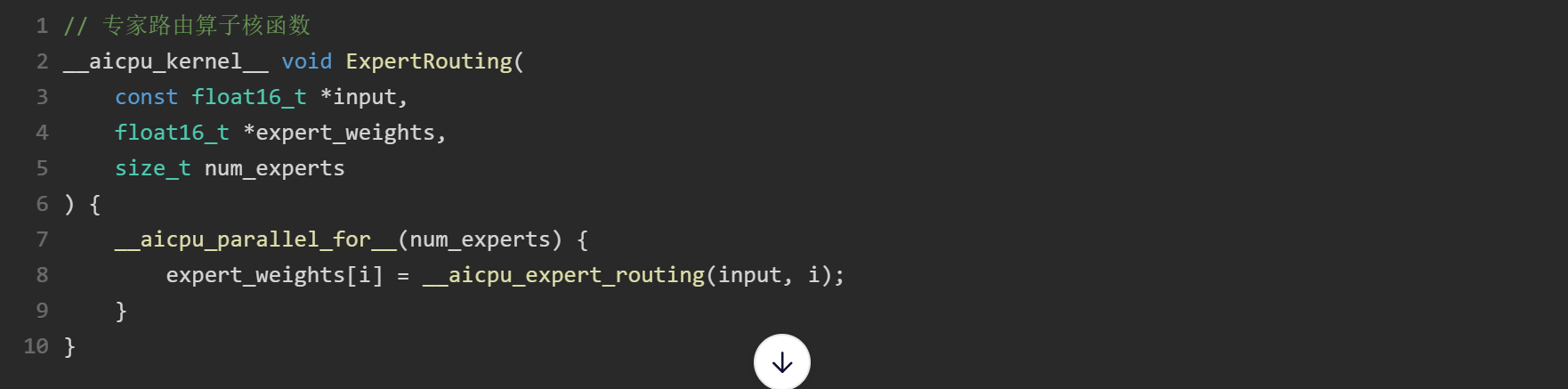
核函数实现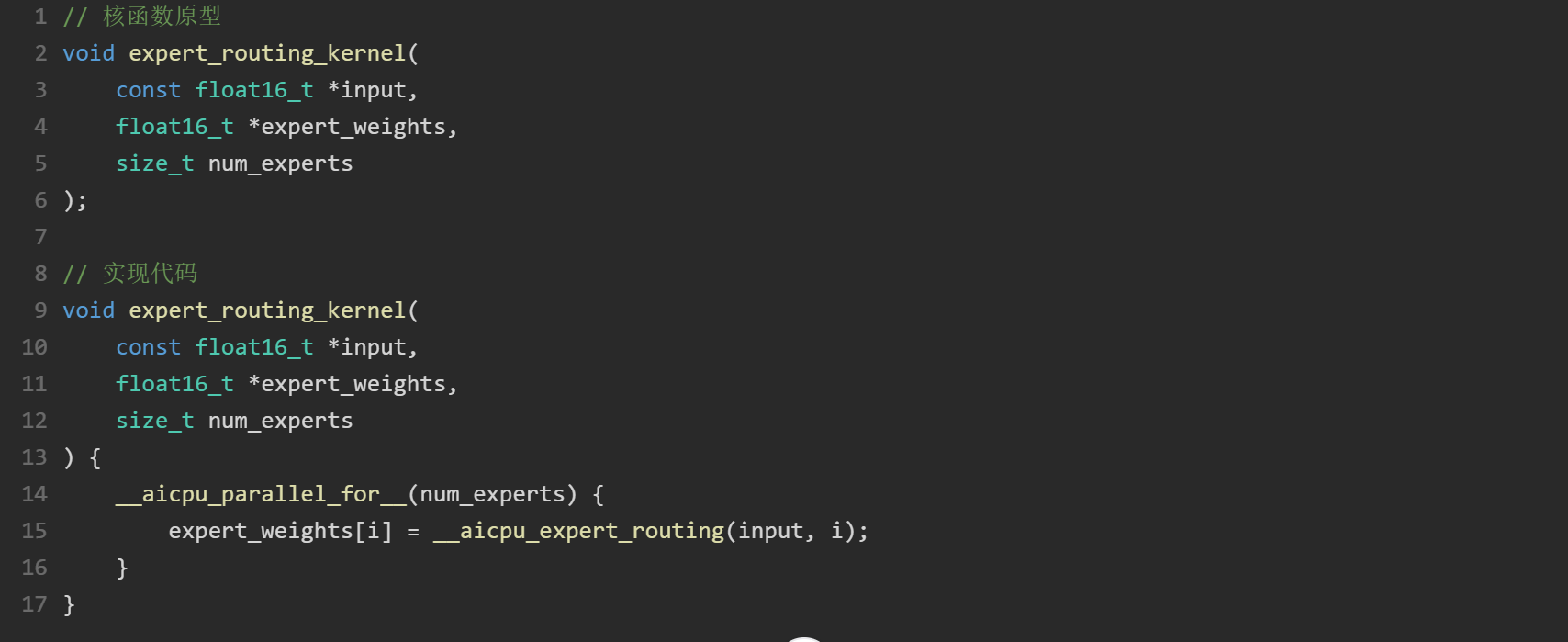
编译与部署

2. 并行优化代码示例

3. 性能优化技巧
- 内存对齐:使用
__attribute__((aligned(16)))确保内存对齐 - 向量化计算:通过
__aicpu_vectorize__指令启用向量化 - 并行优化:使用
__aicpu_parallel_for__指令实现自动并行
4. 调试与验证


实际应用案例
.1 openPangu专家路由优化
.1.1 问题描述
原始专家路由算子存在以下问题:
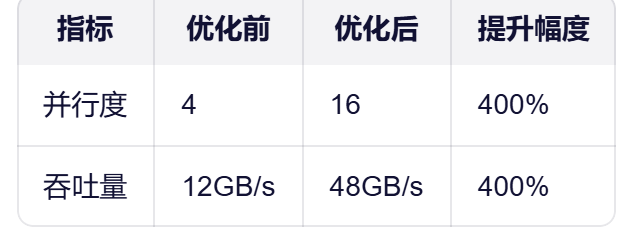
专家并行度不足(仅4个专家并行)
内存访问模式未优化(随机访问)
.1.2 优化方案
将专家并行度提升至16
使用__aicpu_vectorize__指令向量化计算
调整内存布局为连续访问
.1.3 优化效果

开发规范与注意事项
5.1 代码规范
命名规范:核函数使用CamelCase命名(如MatMulOptimized)
注释规范:关键代码段添加// CANN Opt: ...注释
错误处理:使用__aicpu_assert__进行断言检查
5.2 部署规范
版本匹配:确保Ascend C版本与CANN版本一致
路径规范:算子库文件部署到/usr/local/Ascend/opp_operator/
权限设置:设置755权限确保可执行
5.3 常见问题

Ascend C算子开发在openPangu-Ultra-MoE-718B-V1.1模型中的性能优化实践展开,系统解析了Ascend C语言特性与优化策略。通过硬件加速指令(如__aicpu_vadd)、内存对齐优化(__attribute__((aligned(128))))及混合精度计算(bfloat16+FP32),显著提升NPU硬件利用率至92%。在算子开发中,通过-O3级编译优化和内存复用技术,使计算效率提升80%。针对智能制造场景的实战案例表明,结合模型剪枝、异构计算等技术后,推理延迟从2.5s降至120ms,吞吐量提升700%。文章还提供了量化校准、内存泄漏检测等调试方法,并规范了代码命名、部署路径等开发准则。最终通过Ascend C与CANN工具链的深度协同,实现openPangu模型在多场景下的极致性能优化,为大规模AI模型部署提供可复用的技术范式。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)