
昇思25天学习打卡营第20天|linchenfengxue
Beam search通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。缺点: 错过了隐藏在低概率词后面的高概率词,如:dog=0.5, has=0.9!按照贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 x 0.4 = 0.2。选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词
文本解码原理--以MindNLP为例
自回归语言模型

一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积
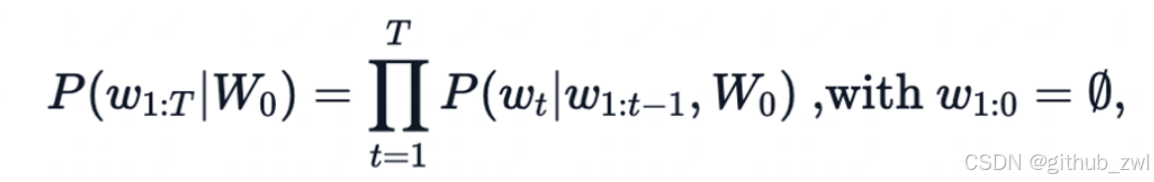
- 𝑊_0:初始上下文单词序列
- 𝑇: 时间步
- 当生成EOS标签时,停止生成。
MindNLP/huggingface Transformers提供的文本生成方法
Greedy search
在每个时间步𝑡都简单地选择概率最高的词作为当前输出词:
𝑤𝑡=𝑎𝑟𝑔𝑚𝑎𝑥_𝑤 𝑃(𝑤|𝑤(1:𝑡−1))
按照贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 x 0.4 = 0.2
缺点: 错过了隐藏在低概率词后面的高概率词,如:dog=0.5, has=0.9 
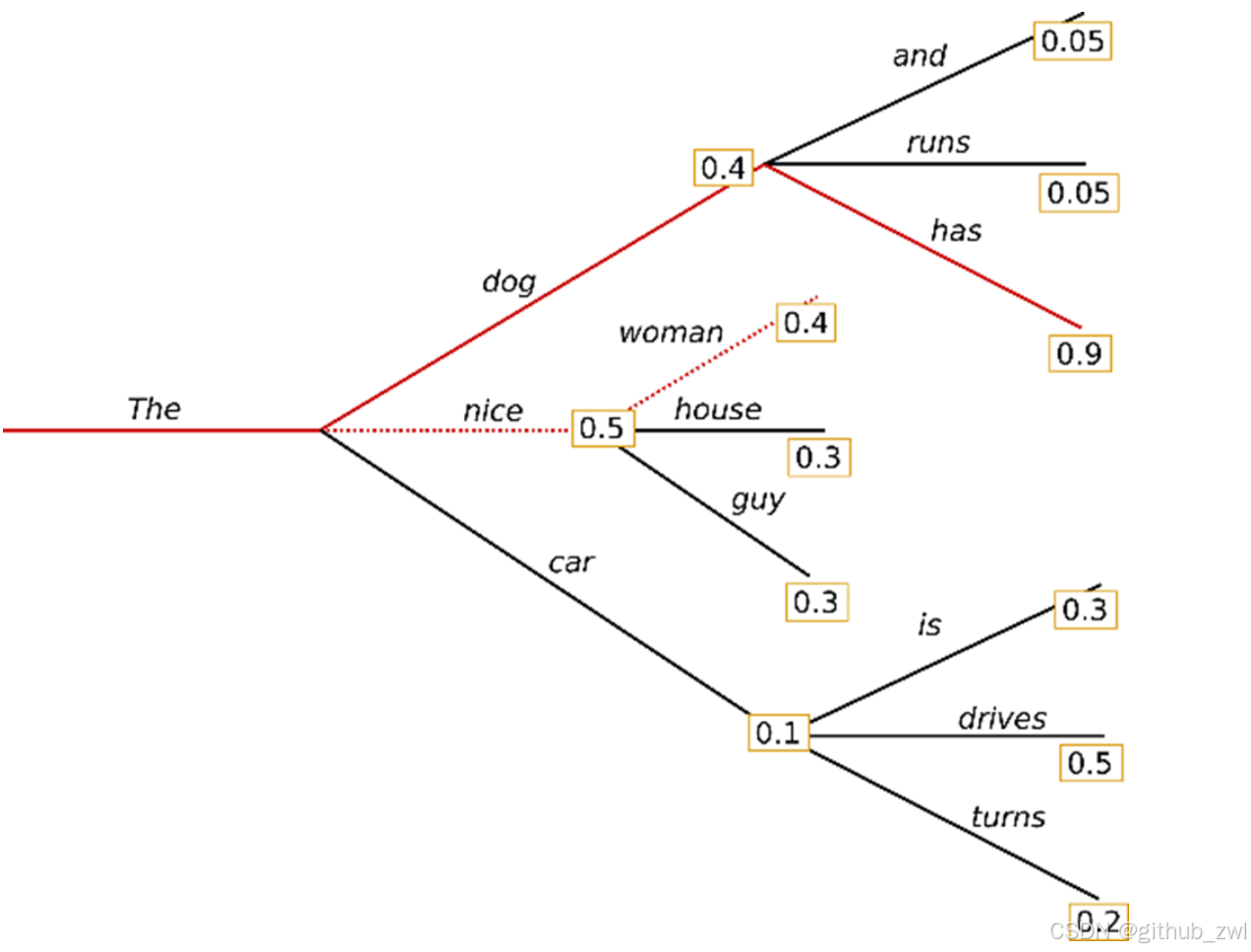
Beam search
Beam search通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。如图以 num_beams=2 为例:
("The","dog","has") : 0.4 * 0.9 = 0.36
("The","nice","woman") : 0.5 * 0.4 = 0.20
优点:一定程度保留最优路径
缺点:1. 无法解决重复问题;2. 开放域生成效果差
Beam search issues 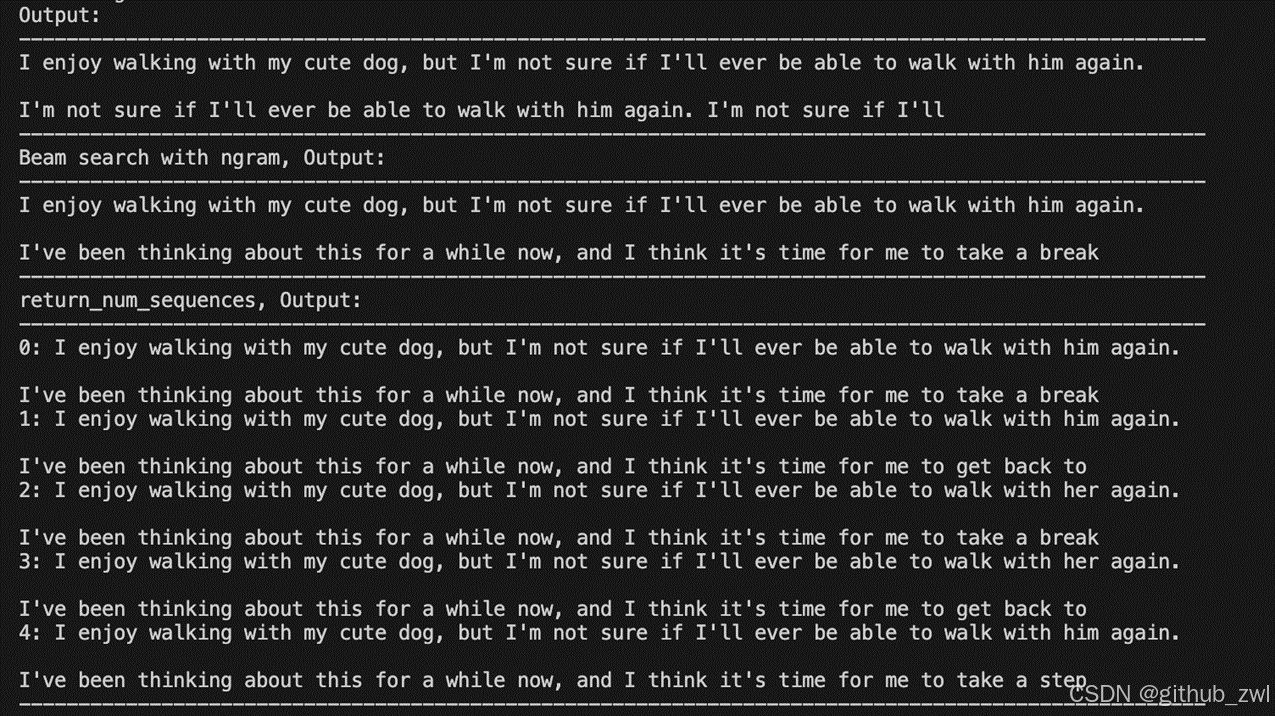
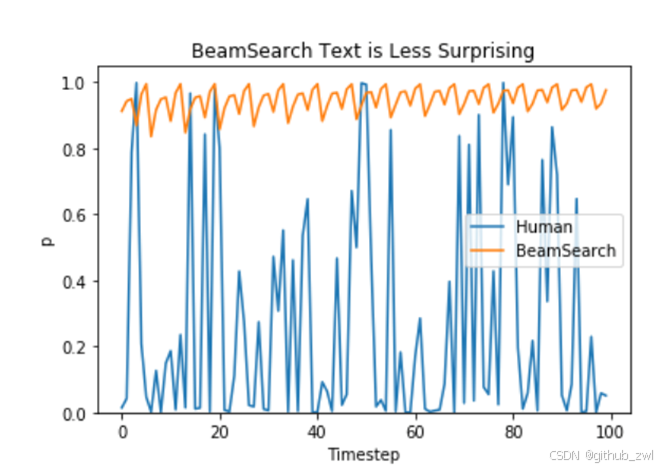
缺点:1. 无法解决重复问题;2. 开放域生成效果差
Repeat problem 

n-gram 惩罚:
将出现过的候选词的概率设置为 0
设置no_repeat_ngram_size=2 ,任意 2-gram 不会出现两次
Notice: 实际文本生成需要重复出现
Sample
根据当前条件概率分布随机选择输出词𝑤_𝑡
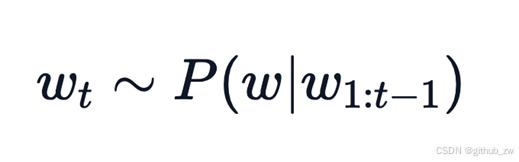
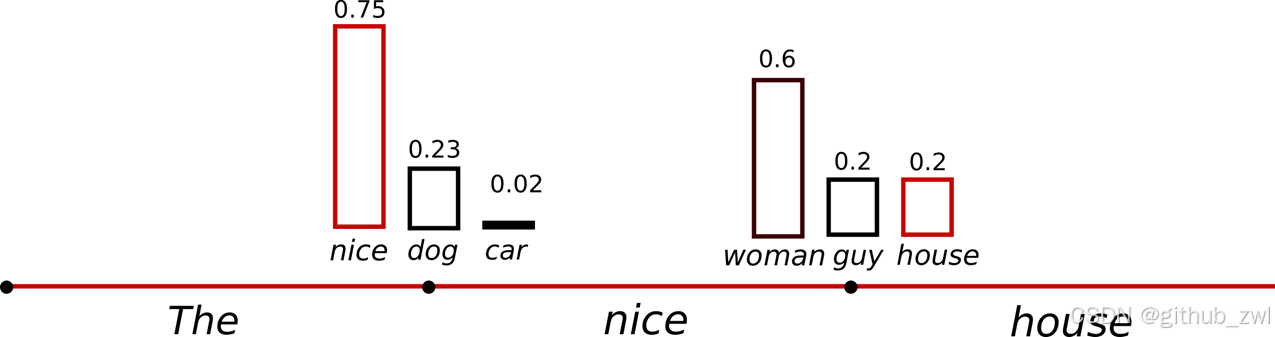
("car") ~P(w∣"The") ("drives") ~P(w∣"The","car") 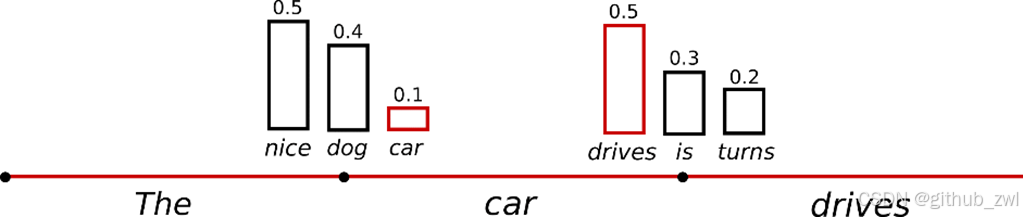
优点:文本生成多样性高
缺点:生成文本不连续
Temperature 降低softmax 的temperature使 P(w∣w1:t−1)分布更陡峭
增加高概率单词的似然并降低低概率单词的似然
TopK sample
选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词中采样 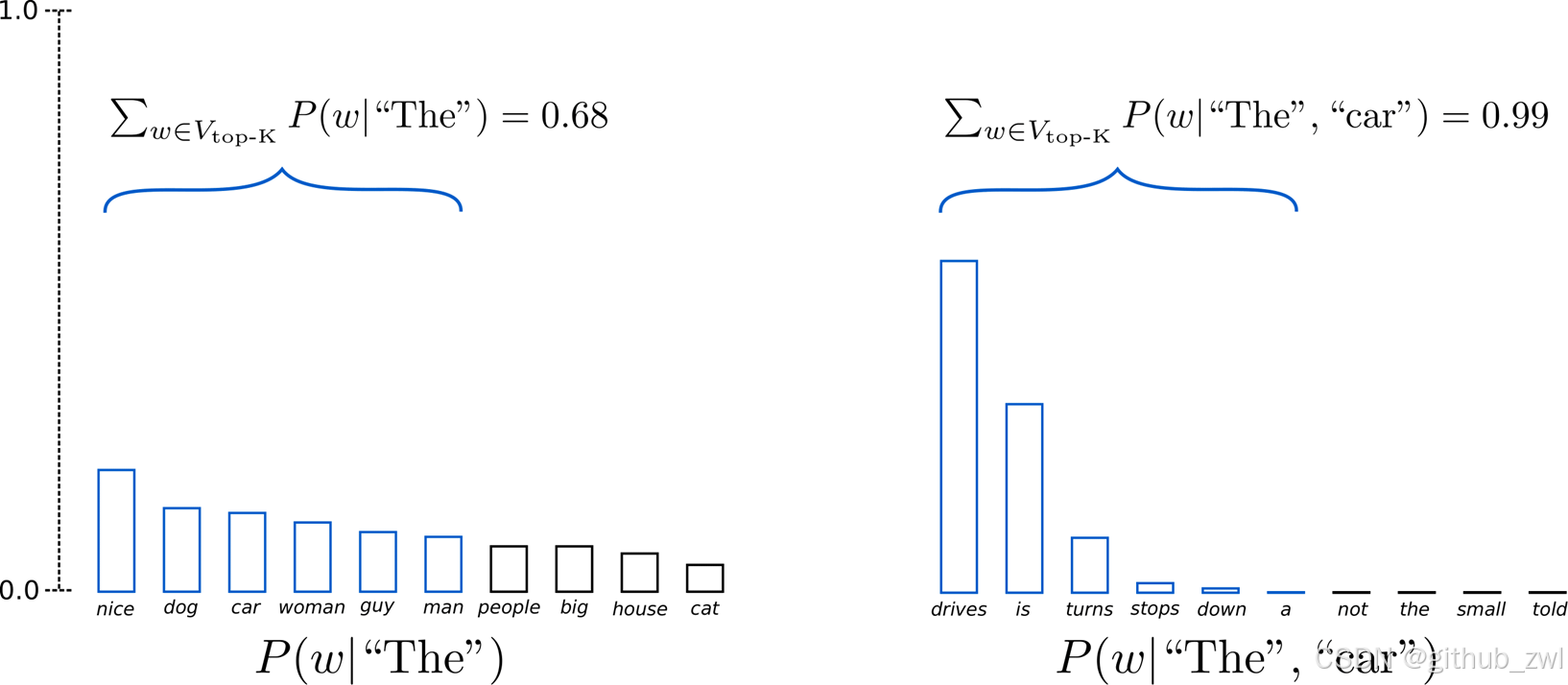
TopK sample problems
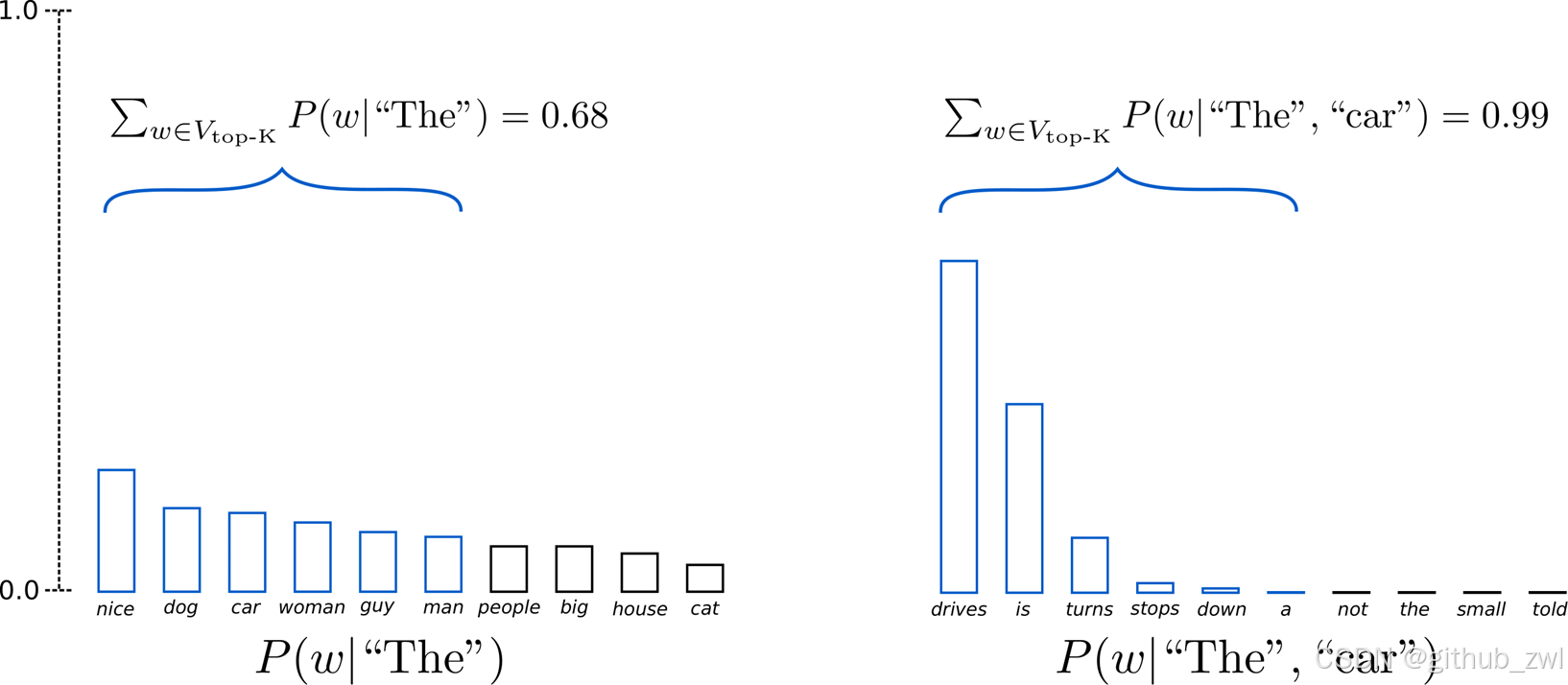
将采样池限制为固定大小 K :
- 在分布比较尖锐的时候产生胡言乱语
- 在分布比较平坦的时候限制模型的创造力
Top-P sample
在累积概率超过概率 p 的最小单词集中进行采样,重新归一化
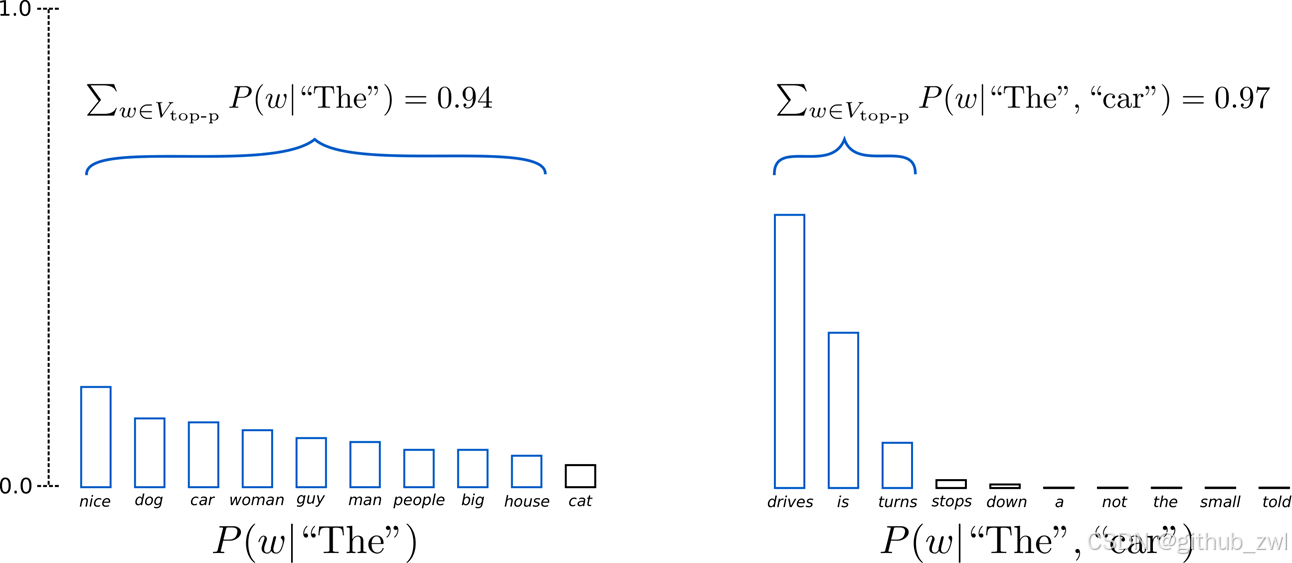
采样池可以根据下一个词的概率分布动态增加和减少

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)