
【2025年昇腾CANN训练营第二季】面向昇腾的Triton 算子调试和性能优化学习记录
训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
昇腾训练营报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
一.Triton-Ascend算子开发回顾
1.Triton kernel开发模式
Triton-Ascend采用SPMD开发模式,多个逻辑核并行执行。每个逻辑核根据其ID计算对应数据块的位置,核心流程包括获取逻辑核ID、根据ID和Block size计算数据位置、将数据加载到片上内存、执行计算逻辑、最后将结果存回全局内存。这种开发模式要求通过grid参数控制逻辑核数量,实现数据的并行处理。
2.Triton关键API
·tl.program_id(axis):获取当前实例在指定轴上的 ID
·tl.num_programs(axis):获取在指定轴上启动的程序实例总数。
·tl.load(pointer, mask):从全局内存加载数据
·tl.store(pointer, value, mask):将数据存储到全局内存
·tl.arange(start, end):生成连续数字序列
·tl.full(shape, value, dtype):创建填充指定值的张量
3.Triton kernel开发的接口使用
基本结构:
@triton.jit # 1. 使用装饰器定义 Triton 内核
def add_kernel(
x_ptr, # 全局内存指针
y_ptr, # 全局内存指针
output_ptr,# 全局内存指针
n_elements,# 数据总大小
BLOCK_SIZE: tl.constexpr # 编译时常量,每个程序处理的元素数
):核心步骤:
·获取程序ID:pid = tl.program_id(axis=0) - 确定当前 kernel 实例序号
·计算数据偏移:根据程序ID和块大小计算要处理的数据位置
·设置掩码:mask = offsets < n_elements - 防止越界访问
·加载数据:x = tl.load(x_ptr + offsets, mask=mask) - 从全局内存加载到片上
·执行计算:在片上内存进行计算操作
·存储结果:tl.store(output_ptr + offsets, output, mask=mask) - 写回全局内存
4.Triton kernel调用和运行
#import torch以及面向昇腾的插件
import torch
import torch_npu
#import triton-ascend的库
import triton
import triton.language as tl #Triton 语言接口
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x) #创建输出张量
n_elements = output.numel() #获取元素总数
#指定triton对数据的分块并行方式,每个继度上的分块数量和大小
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]), )
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
torch.manual_seed(0)
size = 98432
#计算完成后根据偏移存回全局内存
x = torch.rand(size, device='npu')
y = torch.rand(size, device='npu')
output_torch = x + y
output_triton = add(x, y)
print(output_torch)
print(output_triton)
print(f'The maximum difference between torch and triton is '
f'{torch.max(torch.abs(output_torch - output_trition))}')二.Triton-Ascend算子调试
1. Debug 操作符
编译时调试(静态检查):
·tl.static_print:打印编译时常量值
·tl.static_assert:编译时静态断言,检查常量表达式
运行时调试(动态检查):
·tl.device_print:kernel 执行时打印变量值
必须有 prefix 参数,需要设置环境变量TRITON_DEVICE_PRINT=1
·tl.device_assert:运行时动态断言
需要设置环境变量TRITON_DEBUG=1, TRITON_DEVICE_PRINT=1
2. 解释器模式(CPU 调试)
开启 TRITON_INTERPRET=1 环境变量,kernel 使用解释器执行,不在昇腾设备运行。可插入 Python 断点,使用 PDB 调试,但性能较差,只用于正确性调试
3.精度对比
不同数据类型的处理策略:
·浮点类型(float16/32, bfloat16):使用 torch.testing.assert_close,设置相对/绝对误差容限
·整数类型(int8/16/32/64):要求完全相等(torch.equal)
·布尔类型(bool):CPU 上严格比较
三.Triton-Ascend算子性能测试
1.API及参数
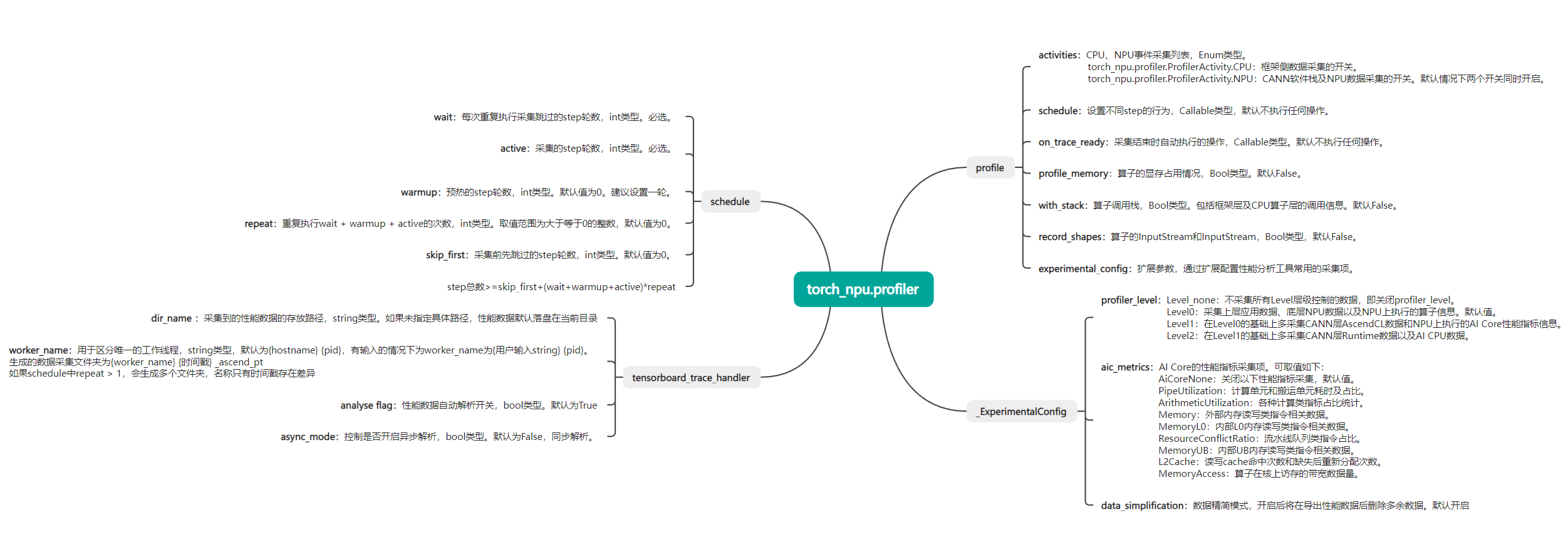
2.torch_npu.profiler案例
def profiler_wrapper(fn, *args):
result_path = "./result_profiling"
skip_first = 10
wait = 0
warmup = 3
active = 30
repeat = 1
experimental_config = torch_npu.profiler._ExperimentalConfig(
atc_metrics=torch_npu.profiler.AidMetrics.PipeUtilization,
profiler_level=torch_npu.profiler.ProfilerLevel.Levell,
data_simplification=False
)
with torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
schedule=torch_npu.profiler.schedule(wait=wait, warmup=warmup, active=active, repeat=repeat,
skip_first=skip_first),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(result_path),
record_shapes=True,
profile_memory=False,
with_stack=False,
with_flops=False,
experimental_config=experimental_config) as prof:
torch.npu.synchronize()
for i in range(skip_first + (wait + warmup + active) * repeat):
fn(*args)
prof.step()
torch.npu.synchronize()
def triton_func(x0, x1):
y0 = torch.empty_like(x0)
triton_kernel_add[1, 1, 1](y0, x0, x1, N)
return y0
def wrapper_func(x0, x1):
torch_ref = torch_func(x0, x1)
triton_cal = triton_func(x0, x1)
profiler_wrapper(wrapper_func, x0, x1)3.数据
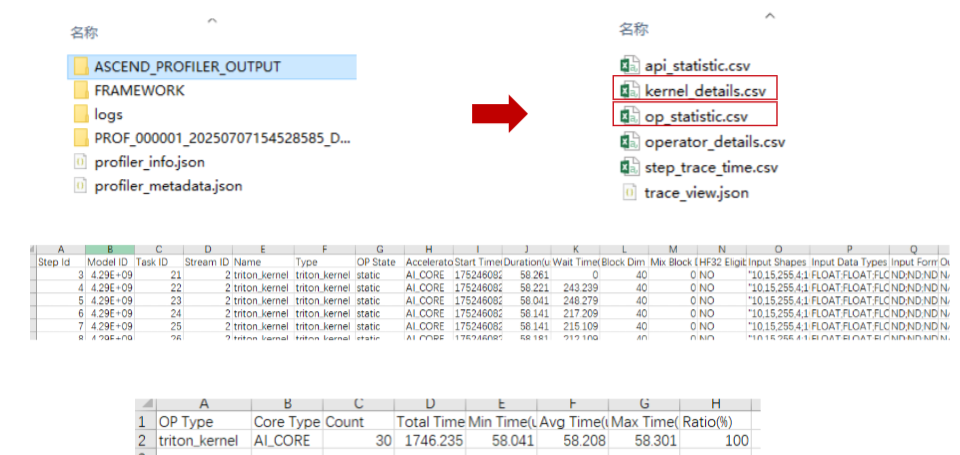
四.Triton-Ascend算子性能优化
1.数据类型
矢量运算单元不支持部分特定数据类型,计算时会退化为标量运算,影响性能,在确定不影响精度的情况下,使用支持的数据类型可以提升性能。

2.离散访存优化
原生Triton作为面向GPU设计的语言,支持SIMT写法,通过自由设置mask实现离散访存;异腾作为SIMD架构,在连续访存场景下可达到更高性能。

3.访存调度优化
提升 L2 Cache 命中率以优化算子/模型的性能。
同一时间避免访问离散内存位置
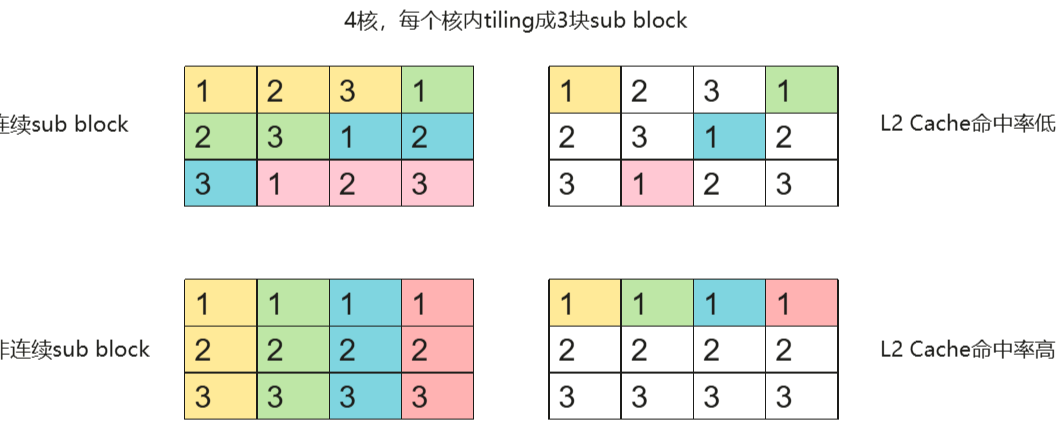
避免同一时间需要数据过大,超出L2 Cache的部分访存速度较慢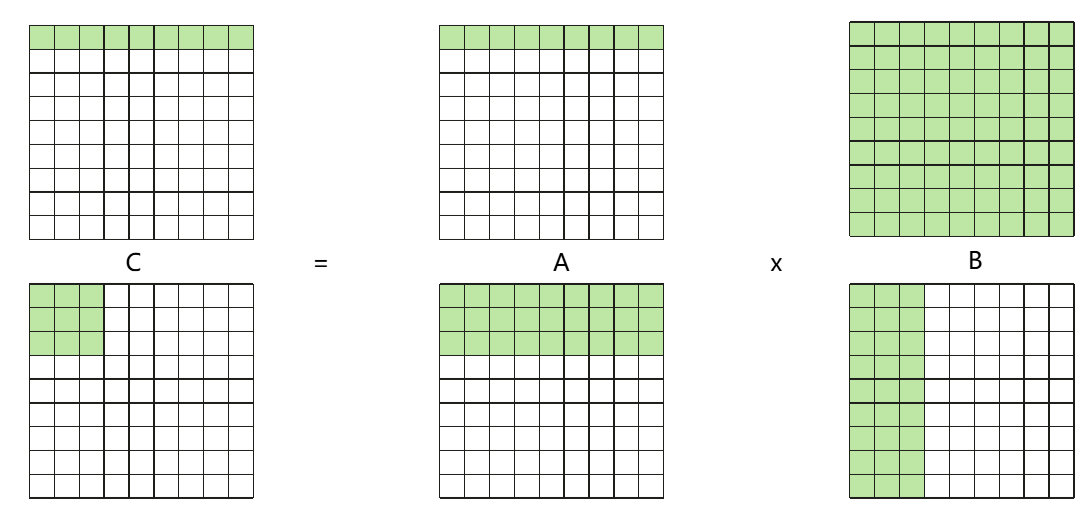
避免同一时间大量访问同一内存区域导致读读冲突
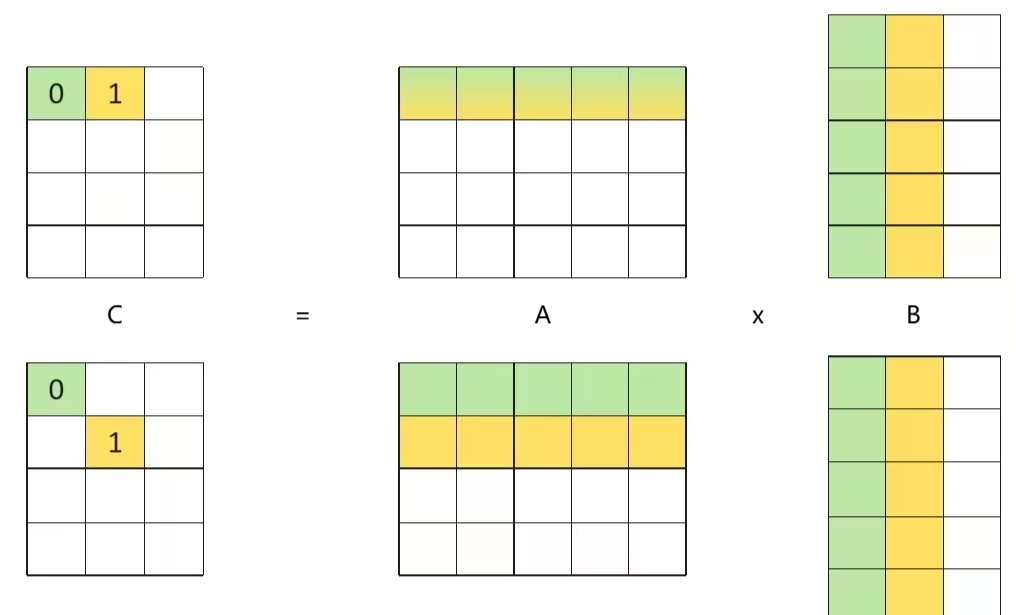
五.性能优化案例:Matmul
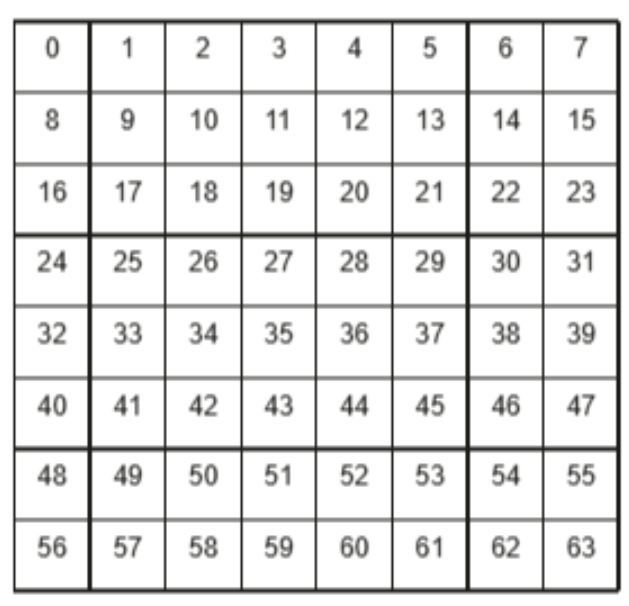
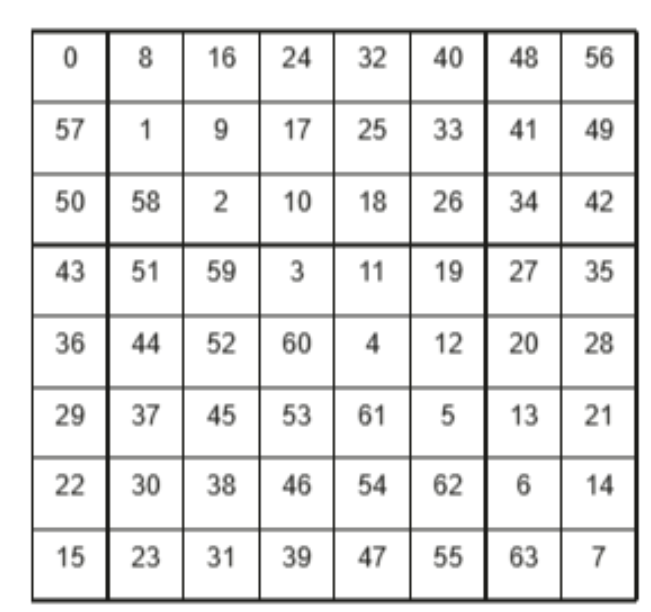
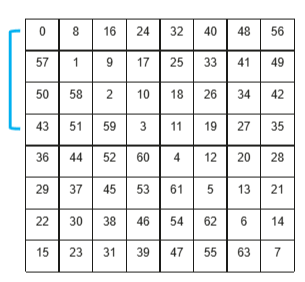
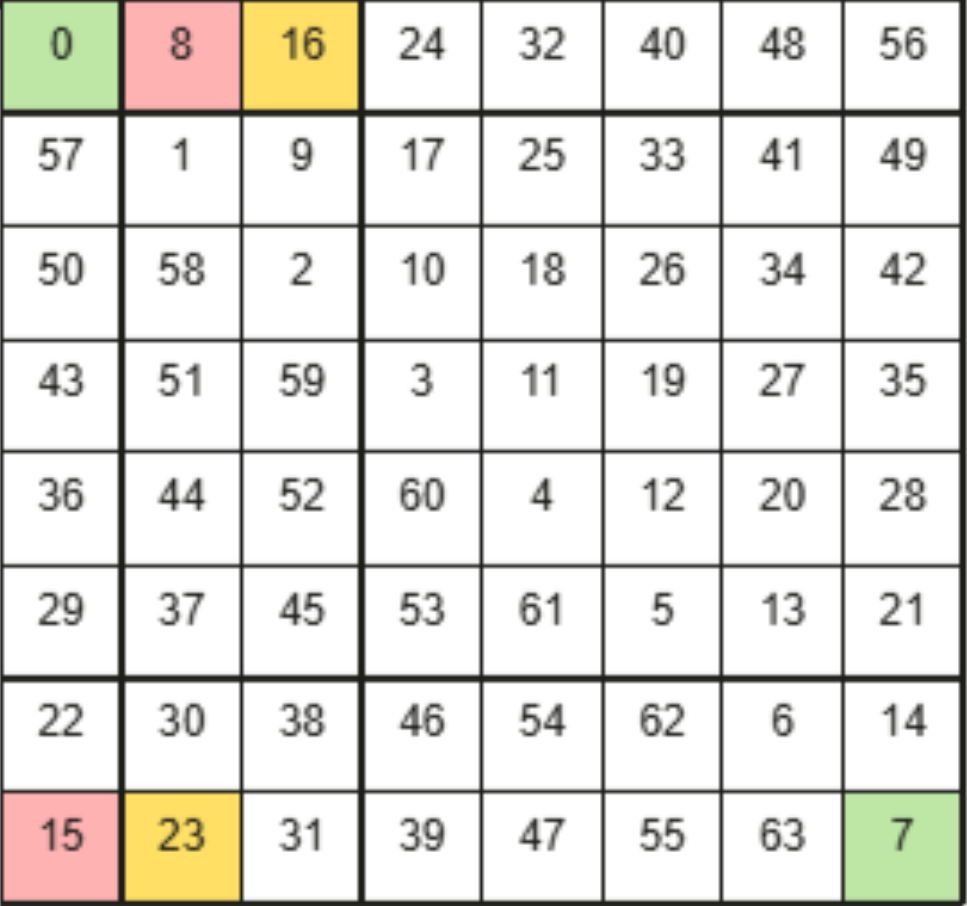
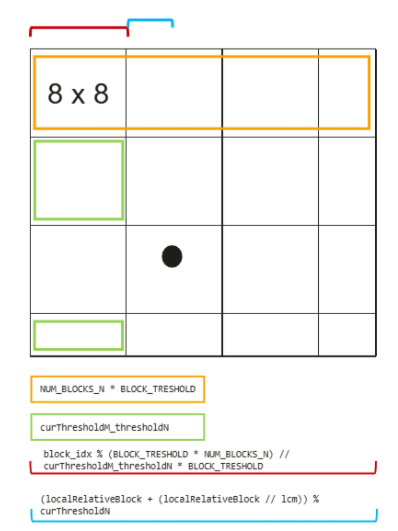
将输出矩阵C均匀分块,每个计算核通过公式coreID + nCore × i轮流处理这些块,实现负载均衡,然后将8×8个小块组合成大块并按行优先执行,但在大块内部采用对角线顺序而非行优先来分配小块,这种设计能减少内存访问冲突、提升缓存命中率。
行优化: 对角线分配:
```python
import torch
import triton
import triton.language as tl
#Triton Kernel
@triton.jit
def matmul_kernel(mat_a, mat_b, mat_c,
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
NUM_BLOCKS: tl.constexpr, NUM_BLOCKS_M: tl.constexpr,
NUM_BLOCKS_N: tl.constexpr, num_cores: tl.constexpr):
pid = tl.program_id(axis=0)
task_m_idx = 0
task_n_idx = 0
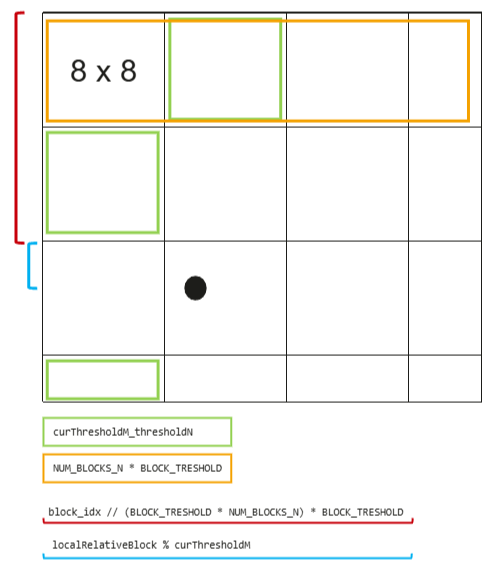
BLOCK_TRESHOLD = 8 # 大块尺寸:8×8
#只在维度足够大时使用复杂分块
if NUM_BLOCKS_M >= BLOCK_TRESHOLD and NUM_BLOCKS_N >= BLOCK_TRESHOLD:
for block_idx in range(pid, NUM_BLOCKS, num_cores): # 负载均衡
# 计算当前大块的M方向尺寸
curThresholdM = (
BLOCK_TRESHOLD
if block_idx < (NUM_BLOCKS_N // BLOCK_TRESHOLD * BLOCK_TRESHOLD) * NUM_BLOCKS_M
else NUM_BLOCKS_M % 8
)
curThresholdM_thresholdM = curThresholdM * BLOCK_TRESHOLD
#计算当前大块的N方向尺寸
curThresholdN = (
BLOCK_TRESHOLD
if block_idx % (NUM_BLOCKS_N * BLOCK_TRESHOLD) < curThresholdM * NUM_BLOCKS_N // curThresholdM_thresholdM * curThresholdM_thresholdM
else NUM_BLOCKS_N % BLOCK_TRESHOLD
)
#计算小块在大块内的相对位置
localRelativeBlock = (
block_idx
% (BLOCK_TRESHOLD * NUM_BLOCKS_N)
% (BLOCK_TRESHOLD * curThresholdM)
)#GM访存512B对其可以最有效发挥带宽效率
mat_a = torch.randn([M, K], dtype=torch.bfloat16, device="npu")
mat_b = torch.randn([K, N], dtype=torch.bfloat16, device="npu")
mat_c = torch.empty(M, N, dtype=mat_a.dtype, device=mat_a.device)
BLOCK_M, BLOCK_N, BLOCK_K = 128, 256, 256
M, K, N = 2048, 7168, 16384
num_cores = get_npu_properties()["num_alcore"]
NUM_BLOCKS_M = triton.cdiv(M, BLOCK_M)
NUM_BLOCKS_N = triton.cdiv(N, BLOCK_N)
NUM_BLOCKS = NUM_BLOCKS_M * NUM_BLOCKS_N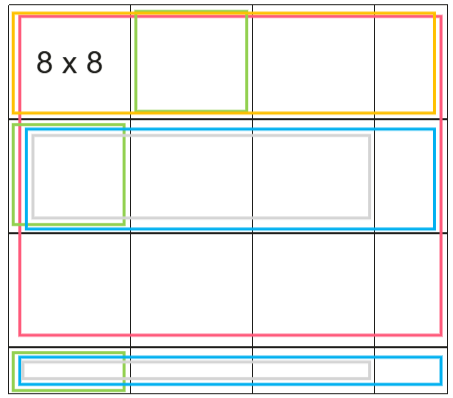

#大block的M方向长度(小block数),≤8
curThresholdM = (
BLOCK_TRESHOLD
if block_idx
< (NUM_BLOCKS_M // BLOCK_TRESHOLD * BLOCK_TRESHOLD) * NUM_BLOCKS_N
else NUM_BLOCKS_M % 8
)
#假设M方向完整,大block里的小block总数
curThresholdM_thresholdN = curThresholdM * BLOCK_TRESHOLD
#大block的N方向长度(小block数),≤8
curThresholdN = (
BLOCK_TRESHOLD
if block_idx % (NUM_BLOCKS_N * BLOCK_TRESHOLD)
< (curThresholdM * NUM_BLOCKS_N)
// curThresholdM_thresholdN
* curThresholdM_thresholdN
else NUM_BLOCKS_N % BLOCK_TRESHOLD
)
#小block在当前大block中的编号
localRelativeBlock = (
block_idx
% (BLOCK_TRESHOLD * NUM_BLOCKS_N)
% (BLOCK_TRESHOLD * curThresholdM)
)
#小block的真实行idx(单位为小block)
task_m_idx = (
localRelativeBlock % curThresholdM
+ block_idx // (BLOCK_TRESHOLD * NUM_BLOCKS_N) * BLOCK_TRESHOLD
)
x, y = (
curThresholdM,
curThresholdN if curThresholdM > curThresholdN else curThresholdM,
)
#最大公约数
while y != 0:
x, y = y, x % y
#最小公倍数
lcm = curThresholdM * curThresholdN // x
#小block的真实列idx (单位为小block)
task_n_idx = (
localRelativeBlock + (localRelativeBlock // lcm)
) % curThresholdN + block_idx % (
BLOCK_TRESHOLD * NUM_BLOCKS_N
) // curThresholdM_thresholdN * BLOCK_TRESHOLD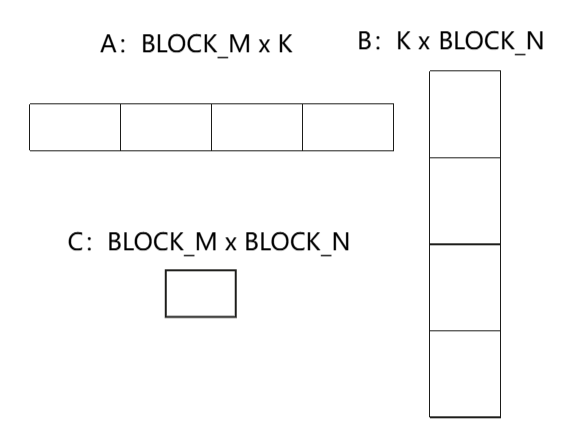
m_start = task_m_idx * BLOCK_M
n_start = task_n_idx * BLOCK_N
mat_c_block = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k_start in range(0, K, BLOCK_K):
# 加载矩阵A的block
mat_a_offset = ((m_start + tl.arange(0, BLOCK_M)) * K)[:, None] + (
k_start + tl.arange(0, BLOCK_K)
)[None, :]
mat_a_mask = ((m_start + tl.arange(0, BLOCK_M)) < M)[:, None] & (
(k_start + tl.arange(0, BLOCK_K)) < K
)[None, :]
mat_a_block = tl.load(mat_a + mat_a_offset, mask=mat_a_mask, other=0.0)
# 加载矩阵B的block
mat_b_offset = ((k_start + tl.arange(0, BLOCK_K)) * N)[:, None] + (
n_start + tl.arange(0, BLOCK_N)
)[None, :]
mat_b_mask = ((k_start + tl.arange(0, BLOCK_K)) < K)[:, None] & (
(n_start + tl.arange(0, BLOCK_N)) < N
)[None, :]
mat_b_block = tl.load(mat_b + mat_b_offset, mask=mat_b_mask, other=0.0)
# 矩阵乘法累加
mat_c_block = tl.dot(mat_a_block, mat_b_block, mat_c_block)# 存储结果矩阵C的block
mat_c_offset = ((m_start + tl.arange(0, BLOCK_M)) * N)[:, None] + (
n_start + tl.arange(0, BLOCK_N)
)[None, :]
mat_c_mask = ((m_start + tl.arange(0, BLOCK_M)) < M)[:, None] & (
(n_start + tl.arange(0, BLOCK_N)) < N
)[None, :]
tl.store(mat_c + mat_c_offset, mat_c_block.to(tl.bfloat16), mask=mat_c_mask)
鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)