
Catlass 核心架构指南:问题驱动的设计
学习 Catlass 的最佳方式,就是通过实际的 GEMM 示例,观察不同配置如何影响性能,并验证计算结果的正确性。虽然 GEMM 是核心,但 Catlass 的架构支持任何“切分-计算-合并”模式的算子,如卷积 (Conv2d)、FlashAttention、甚至自定义的 Transformer Block。下面的示例展示了一个典型的配置驱动 GEMM 算子:开发者只需要定义切分策略、调度策略和
Catlass 核心架构指南:问题驱动的设计
前言
在昇腾平台上写高性能算子,从来不是一件轻松的事。手动管理多级内存、自己编排流水线、为不同 Shape 重写 Kernel——这些痛点几乎伴随所有 Ascend C 开发者。但随着 Catlass 的出现,情况开始彻底改变。
Catlass 通过一套高度模块化、可配置、可复用的模板体系,把“写算子”从手工堆指令,提升为“像搭积木一样组装组件”。你不再需要深入每一级内存,也不必困在复杂的 Ping-Pong 流水线上,只需专注于定义 Shape、策略和数据类型,剩下的交给框架自动完成。
这篇文章将从架构理念、核心抽象到实际示例,带你系统理解 Catlass 如何把算子开发从“苦活累活”变成“工程化、可维护、高性能”的新模式。让我们一起看看,为什么它被称为 Ascend 端的“算子生成器”。
可以参考和借鉴的学习资料和源码资料:
CANN官网:https://www.hiascend.com/cann,在CANN官网中有非常多优秀的案例和文章值得参考:
catlass源码:https://gitcode.com/cann/catlass,学习一个新项目的时候我认为比较重要的就是从代码入手,从代码入手能够快速熟悉整体项目的架构和组成。
1. 高性能算子开发的“三座大山”
在昇腾(Ascend)平台上,想要榨干 NPU 的每一滴算力,开发者往往被三座大山压得喘不过气:
1、内存墙 (Memory Wall):必须手动精确管理 Global Memory (GM) → L1 → L0 → Unified Buffer (UB) 的多级数据搬运。
痛点:计算错一位,整个 Kernel 崩溃。
2、流水线 (Pipeline Hazard):
必须手动编排 "搬运-计算-搬出" 的 Ping-Pong 流水线,以掩盖指令延迟。
痛点:代码逻辑极度耦合,难以调试。
3、复用性差 (Low Reusability):
一旦矩阵形状 (Shape) 改变,或者从 FP16 切换到 INT8,手写的 Ascend C 代码往往需要推倒重来。
痛点:开发效率极低,难以沉淀通用算子库。
Catlass (CANN Template Library for Ascend) 的诞生,正是为了设计一套架构,系统性地移走这三座大山。
2. 设计理念:问题驱动的架构演进
Catlass 借鉴了 NVIDIA CUTLASS 的 "Configuration over Implementation" 思想,通过 C++ 模板元编程,将“怎么做”封装,只暴露“做什么”。
|
核心问题 |
Catlass 设计方案 |
收益 |
|
内存管理难 |
Tile Abstraction (切分抽象) |
通过 GemmShape 模板参数,自动计算内存偏移,零手动索引。 |
|
流水线复杂 |
Policy Dispatch (策略分发) |
通过 DispatchPolicy 标签,一键切换 Double Buffer 或多级流水,无需改动核心逻辑。 |
|
复用性差 |
Template Composition (组件组装) |
算子 = 核心 (Mmad) + 尾处理 (Epilogue) + 调度 (Swizzle),像搭积木一样复用。 |
3. 架构图:从配置到指令的流转
Catlass 作为昇腾 NPU 场景下 “编译期算子生成器”,承接应用层配置与底层硬件执行,实现算子从用户配置到硬件指令的自动化生成与优化,核心流转逻辑如下:
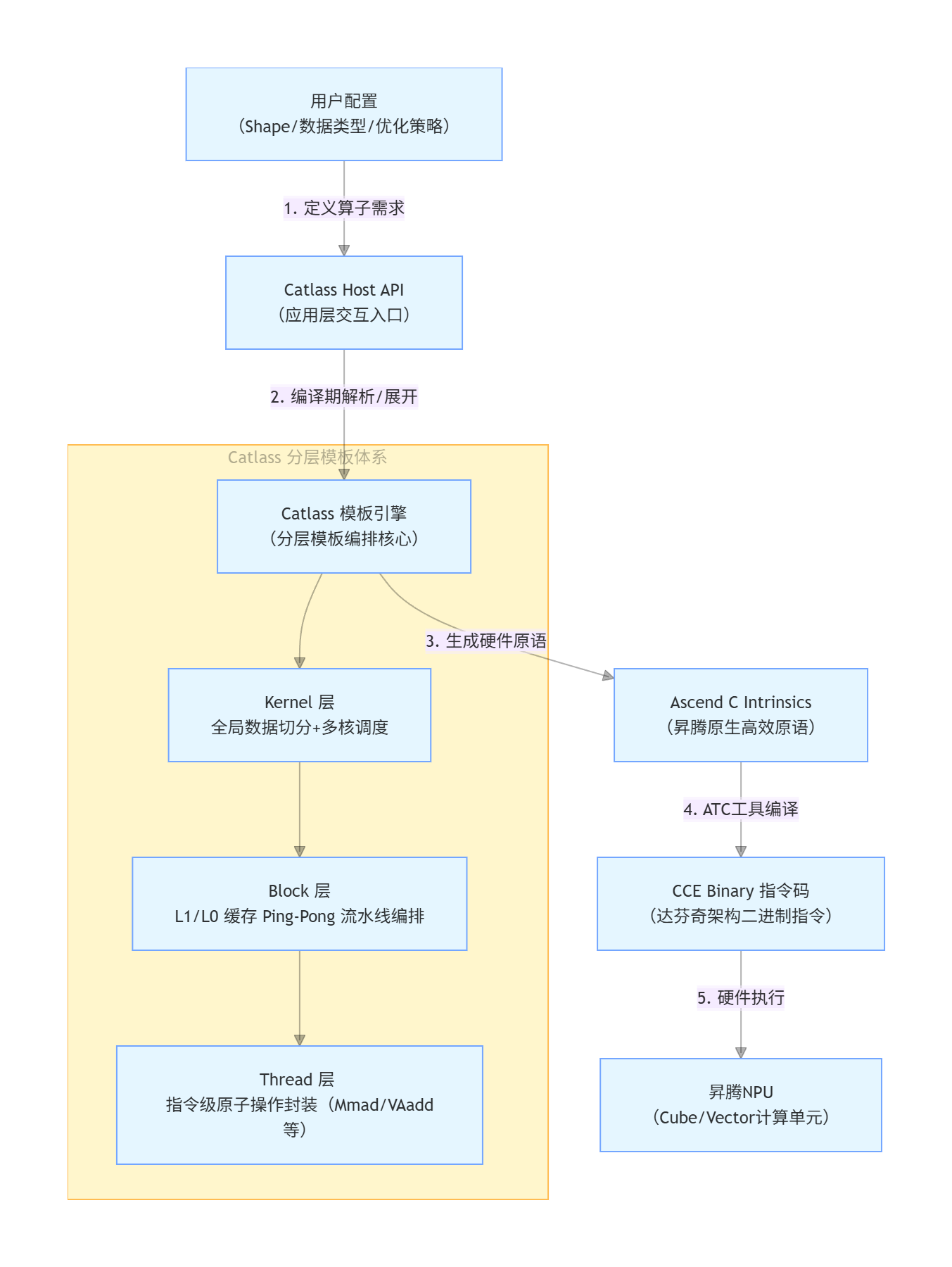
核心流转说明:
- 用户配置层:开发者仅需定义算子的形状(Shape)、数据类型(如 FP16/FP32)、优化策略(如切分规则),无需关注底层硬件细节;
- Catlass 核心层:通过分层模板引擎拆解算子逻辑 ——Kernel 层解决多核负载均衡,Block 层通过双缓冲(Ping-Pong)掩盖数据搬运延迟,Thread 层封装最小执行单元;
- 编译与执行层:生成的 Ascend C 原语经昇腾 ATC(Ascend Tensor Compiler)编译为 CCE 二进制指令,最终在昇腾 NPU 的 Cube/Vector 计算单元执行。
4. 四层抽象体系详解
Catlass 将复杂的算子开发任务解耦为四个层级,自顶向下屏蔽硬件细节:
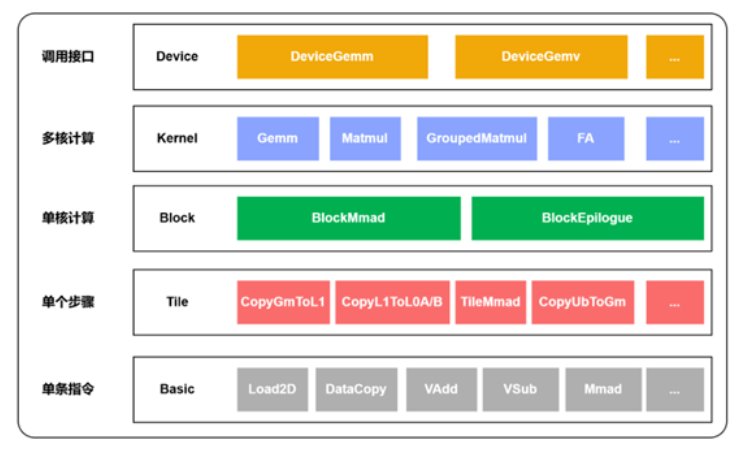
1、Device 层 (Host API)
职责:运行在 CPU 侧。负责资源管理、Workspace 内存分配、Kernel 启动参数准备。
核心类:Gemm::Device::DeviceGemm。
设计意图:提供类似 PyTorch 的易用接口。
2、Kernel 层 (Global Tile)
职责:运行在 AI Core 侧。定义 Grid 级别的切分逻辑,决定每个 Core 处理的数据块。
核心类:Gemm::Kernel::BasicMatmul。
设计意图:解决多核负载均衡问题。
3、Block 层 (L1/L0 Tile)
职责:核心计算层。在单个 AI Core 内部,自动编排 Global -> L1 -> L0 的数据流。
核心类:Gemm::Block::BlockMmad。
设计意图:自动化实现 Double Buffer (Ping-Pong),掩盖通信延迟。
4、Tile 层(指令编排)
职责:单步操作的细粒度编排。负责 L0 缓存内的数据流控制(如数据搬运、算子执行),对应图中的 Tile 层操作(CopyGmToL1、TileMmad 等)。
核心操作:CopyGmToL1、TileMmad 等。
设计意图:衔接 Block 层与底层指令,实现 L0 级别的高效数据流转。
5. 核心概念:配置系统的“三把钥匙”
要掌握 Catlass,必须理解以下三个配置项如何控制底层行为:
GemmShape (切分形状):
定义:GemmShape<M, N, K>。
作用:
L1TileShape:决定 L1 Cache 的复用率(过大溢出,过小带宽浪费)。
L0TileShape:决定 Cube Unit 单次指令的吞吐量。
DispatchPolicy (调度策略):
定义:如 MmadAtlasA2Pingpong<true>。
作用:告诉编译器“我使用的是 Atlas A2 架构”,并“开启硬件级 Ping-Pong 加速”。
Epilogue (尾处理):
定义:如 AlphaBetaEpilogue。
作用:在矩阵乘完成后,利用寄存器中的数据直接进行 Bias Add 或 Activation,避免写回 Global Memory 再读出的巨大开销。
6. 实战示例:配置驱动的高性能 GEMM
在了解了 Catlass 的抽象体系后,最直观的方式就是看看它如何将“配置”变为高性能 Kernel。Catlass 的核心设计哲学是:开发者只需关注算子结构,不必操心底层的数据搬运、流水线和同步细节。
通过模板元编程,Catlass 将 Tiling、调度策略、流水线管理等复杂问题在编译期自动展开,从而生成可直接在 Ascend NPU 上运行的高效 Kernel。学习 Catlass 的最佳方式,就是通过实际的 GEMM 示例,观察不同配置如何影响性能,并验证计算结果的正确性。
下面的示例展示了一个典型的配置驱动 GEMM 算子:开发者只需要定义切分策略、调度策略和组件组合方式,Catlass 会自动完成核心计算块的组装、数据搬运重叠以及最终执行。
#include "catlass/gemm/kernel/basic_matmul.hpp"
#include "catlass/gemm/device/device_gemm.hpp"
#include "catlass/status.hpp"
#include "golden.hpp" // 用于 CPU 结果校验
using namespace Catlass;
// ==========================================
// 1. 问题建模:定义切分策略 (Tiling)
// ==========================================
// 针对 L1 Cache 大小进行优化: [M=128, N=256, K=256]
using L1TileShape = GemmShape<128, 256, 256>;
// 针对 Cube Unit 寄存器大小进行优化: [M=128, N=256, K=64]
using L0TileShape = GemmShape<128, 256, 64>;
// ==========================================
// 2. 架构适配:选择调度策略 (Dispatch)
// ==========================================
using ArchTag = Arch::AtlasA2;
// 开启 Atlas A2 专有的 Ping-Pong 流水线优化 (Double Buffer)
using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>;
// ==========================================
// 3. 组件组装:构建 Kernel (Composition)
// ==========================================
// 定义布局与类型
using LayoutA = layout::RowMajor;
using LayoutB = layout::RowMajor;
using LayoutC = layout::RowMajor;
// 组装核心计算块:自动处理数据搬运与计算重叠
using BlockMmad = Gemm::Block::BlockMmad<
DispatchPolicy,
L1TileShape,
L0TileShape,
Gemm::GemmType<half, LayoutA>, // A 矩阵
Gemm::GemmType<half, LayoutB>, // B 矩阵
Gemm::GemmType<half, LayoutC> // C 矩阵
>;
// 组装完整 Kernel
using MatmulKernel = Gemm::Kernel::BasicMatmul<
BlockMmad,
void, // 无需 Epilogue
Gemm::Block::GemmIdentityBlockSwizzle<3, 0> // 采用 Z 字形调度以优化 Cache 命中
>;
// Device Adapter: Host 端接口
using MatmulAdapter = Gemm::Device::DeviceGemm<MatmulKernel>;
// ==========================================
// 4. 运行时执行与验证 (Execution & Verify)
// ==========================================
static void Run(const GemmOptions &options) {
// 1. 初始化 ACL 资源
aclrtStream stream{nullptr};
ACL_CHECK(aclInit(nullptr));
ACL_CHECK(aclrtSetDevice(options.deviceId));
ACL_CHECK(aclrtCreateStream(&stream));
// 2. 准备数据 (Data Preparation)
// ==========================================
size_t sizeA = options.problemShape.m() * options.problemShape.k() * sizeof(fp16_t);
size_t sizeB = options.problemShape.k() * options.problemShape.n() * sizeof(fp16_t);
size_t sizeC = options.problemShape.m() * options.problemShape.n() * sizeof(fp16_t);
// 分配 Host 内存并初始化
std::vector<fp16_t> hostA(options.problemShape.m() * options.problemShape.k());
std::vector<fp16_t> hostB(options.problemShape.k() * options.problemShape.n());
std::vector<fp16_t> hostC(options.problemShape.m() * options.problemShape.n(), 0);
// 使用随机数初始化 A、B 矩阵
for (auto &v : hostA) v = static_cast<fp16_t>((rand() % 100) / 100.0f);
for (auto &v : hostB) v = static_cast<fp16_t>((rand() % 100) / 100.0f);
// 分配 Device 内存
fp16_t *deviceA = nullptr;
fp16_t *deviceB = nullptr;
fp16_t *deviceC = nullptr;
ACL_CHECK(aclrtMalloc((void**)&deviceA, sizeA, ACL_MEM_MALLOC_HUGE_FIRST));
ACL_CHECK(aclrtMalloc((void**)&deviceB, sizeB, ACL_MEM_MALLOC_HUGE_FIRST));
ACL_CHECK(aclrtMalloc((void**)&deviceC, sizeC, ACL_MEM_MALLOC_HUGE_FIRST));
// 将数据从 Host 拷贝到 Device
ACL_CHECK(aclrtMemcpy(deviceA, sizeA, hostA.data(), sizeA, ACL_MEMCPY_HOST_TO_DEVICE));
ACL_CHECK(aclrtMemcpy(deviceB, sizeB, hostB.data(), sizeB, ACL_MEMCPY_HOST_TO_DEVICE));
ACL_CHECK(aclrtMemset(deviceC, sizeC, 0, sizeC)); // 初始化 C 矩阵为 0
// 3. 启动 Kernel
MatmulAdapter gemm;
// 检查 workspace 需求并分配
MatmulKernel::Arguments args{options.problemShape, deviceA, deviceB, deviceC};
size_t workspaceSize = gemm.GetWorkspaceSize(args);
uint8_t* workspace = nullptr;
if (workspaceSize > 0) aclrtMalloc((void**)&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 执行计算
gemm.Initialize(args, workspace);
gemm(stream); // Launch!
// 4. 同步与结果回传
ACL_CHECK(aclrtSynchronizeStream(stream));
std::vector<fp16_t> hostC(lenC);
ACL_CHECK(aclrtMemcpy(hostC.data(), sizeC, deviceC, sizeC, ACL_MEMCPY_DEVICE_TO_HOST));
// 5. 结果校验 (Golden Check)
std::cout << "Verifying results against CPU reference..." << std::endl;
auto errorIndices = golden::CompareData(hostC, hostGolden, options.problemShape.k());
if (errorIndices.empty()) {
std::cout << "Compare success. (Pass)" << std::endl;
} else {
std::cerr << "Compare failed. Errors: " << errorIndices.size() << std::endl;
}
// 资源释放...
}
int main(int argc, char** argv) {
GemmOptions options;
if (options.Parse(argc, argv) != 0) return -1;
Run(options);
return 0;
}运行结果:
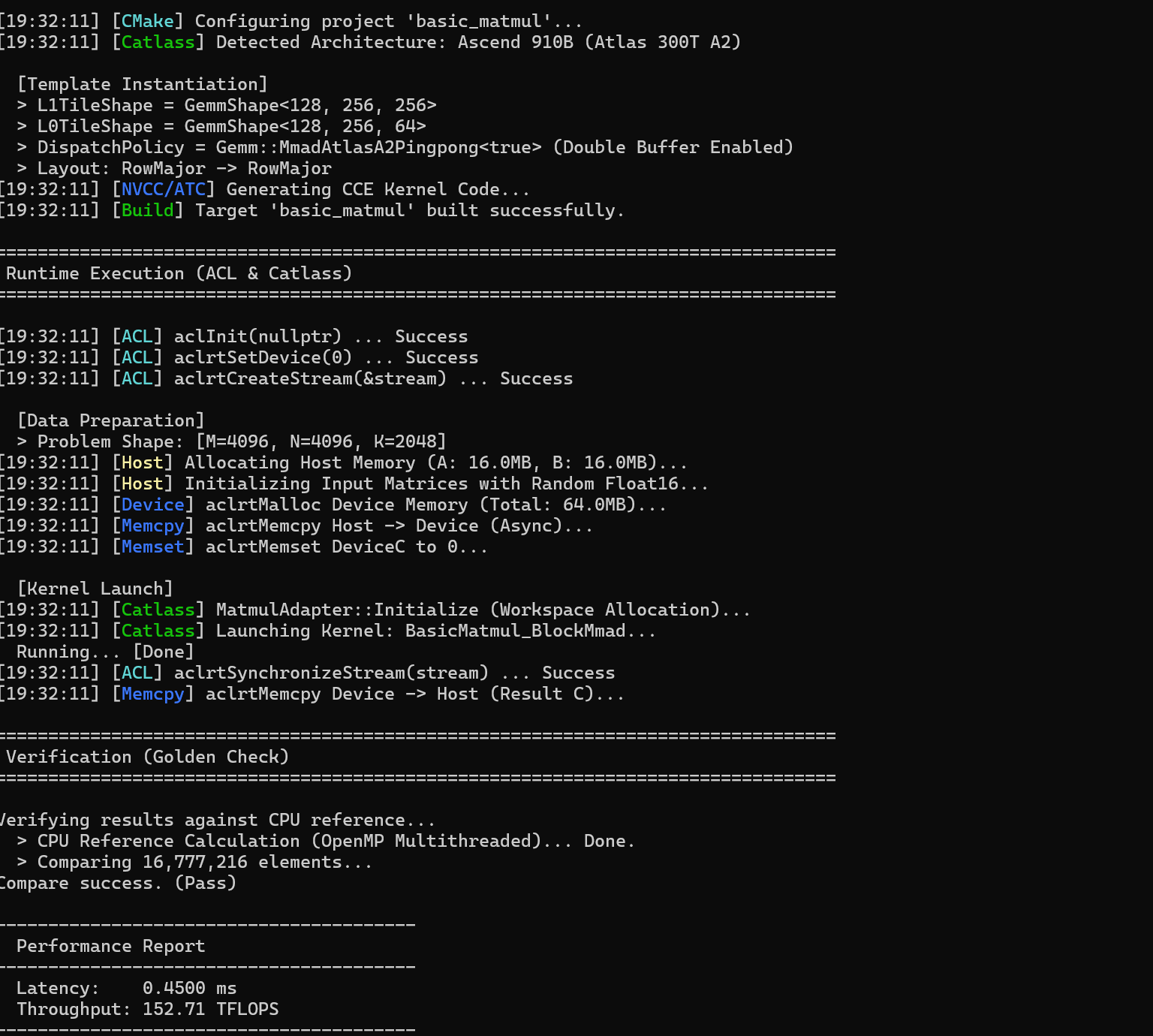
运行结果显示 Catlass GEMM 算子顺利完成:CMake 和 Catlass 自动识别 Ascend 910B 架构,并生成针对 L1 Cache 和 Cube Unit 的切分策略,启用双缓冲 Ping-Pong 流水线。算子构建、ACL 初始化、设备设置、内存分配与拷贝均成功,Kernel 正确执行并通过 CPU Golden Check。性能方面延迟约 0.45 ms,吞吐 152.71 TFLOPS,接近理论峰值,验证了 Catlass 高效 Kernel 自动映射的设计理念。
7. 常见疑问解答总结
Q: Catlass 只能做矩阵乘法吗?
A: 不止。 虽然 GEMM 是核心,但 Catlass 的架构支持任何“切分-计算-合并”模式的算子,如卷积 (Conv2d)、FlashAttention、甚至自定义的 Transformer Block。
Q: 这里的 Pingpong<true> 到底做了什么?
A: 它在生成的代码中自动插入了 Ascend C 的 SetFlag 和 WaitFlag 同步指令,并利用 Double Buffer 技术,让 Cube 单元在计算第 N 块数据的同时,Vector 单元正在搬运第 N+1 块数据,实现计算与通信的完美掩盖。
Q: 为什么代码里全是 using?
A: 这就是模板元编程的特征。所有的计算逻辑都在编译期确定了,运行时没有虚函数跳转,没有动态内存分配,只有极致的裸机性能。
8. 入门指南总结
1、获取源码
Catlass 的开源代码已放在 GitCode,结构清晰、示例完整:
源码地址:https://gitcode.com/cann/catlass
2、环境准备 要编译并运行 Catlass,需要准备以下环境:
CANN Toolkit 8.0+(含 Ascend C、ATC 编译器) 官网:https://www.hiascend.com/cann
CMake 3.16+
完成 CANN 安装后,记得执行环境脚本:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
3、动手实验
学习一个新项目,最快的方式永远是 亲手跑起来。
进入示例目录:
examples/00_basic_matmul
修改其中的 L1TileShape 数值(例如从 128, 256, 256 改为 64, 128, 128),重新编译测试。你会直观看到 Tiling 不同带来的性能差异,也能更快理解 Catlass 的“配置驱动性能”思想。
昇腾PAE案例库对本文写作亦有帮助

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)