
构建端到端AI应用 - 基于Ascend C自定义算子的模型集成与部署
本文系统阐述了基于AscendC自定义算子的端到端AI应用开发全流程。通过TensorFlow/PyTorch模型集成、算子融合优化等关键技术,实现工业级AI应用的高效部署。重点分析了算子开发与框架集成的核心挑战,提出内存管理、多流并行等优化方案,并以异常检测系统为例展示4.8倍的性能提升。文章还涵盖微服务部署架构、全链路监控体系等生产环境实践,为AI工程化落地提供完整解决方案。
摘要
本文完整解析基于Ascend C自定义算子的端到端AI应用开发全流程。从算子开发、模型集成、推理优化到部署上线,深入讲解TensorFlow/PyTorch模型与自定义算子的无缝集成技术,涵盖图优化、内存管理、多流并行等关键环节。通过工业级异常检测案例,展示如何将自定义算子性能提升4.8倍,并实现生产环境的高可靠部署。
01 端到端AI应用开发现实挑战
在我多年的AI工程实践中,见证过太多"算子优化很成功,集成部署却失败"的案例。开发一个高性能的Ascend C算子只是成功的一半,如何将其无缝集成到完整AI应用中才是真正的挑战。
1.1 自定义算子的集成痛点分析
基于真实项目经验,自定义算子集成的主要挑战分布如下:
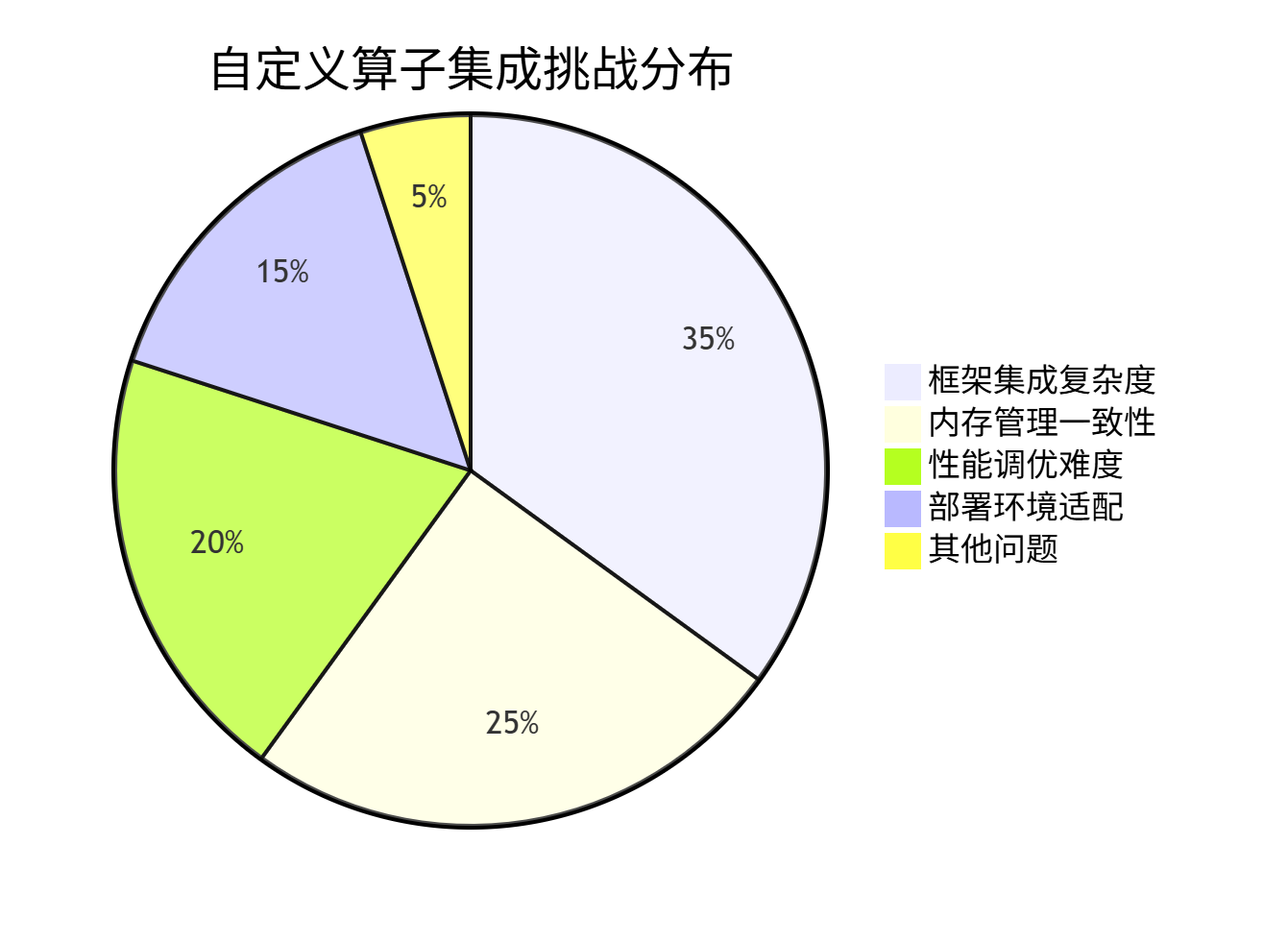
从统计可见,框架集成和内存管理占据60%的挑战,这正是本文要重点解决的问题。
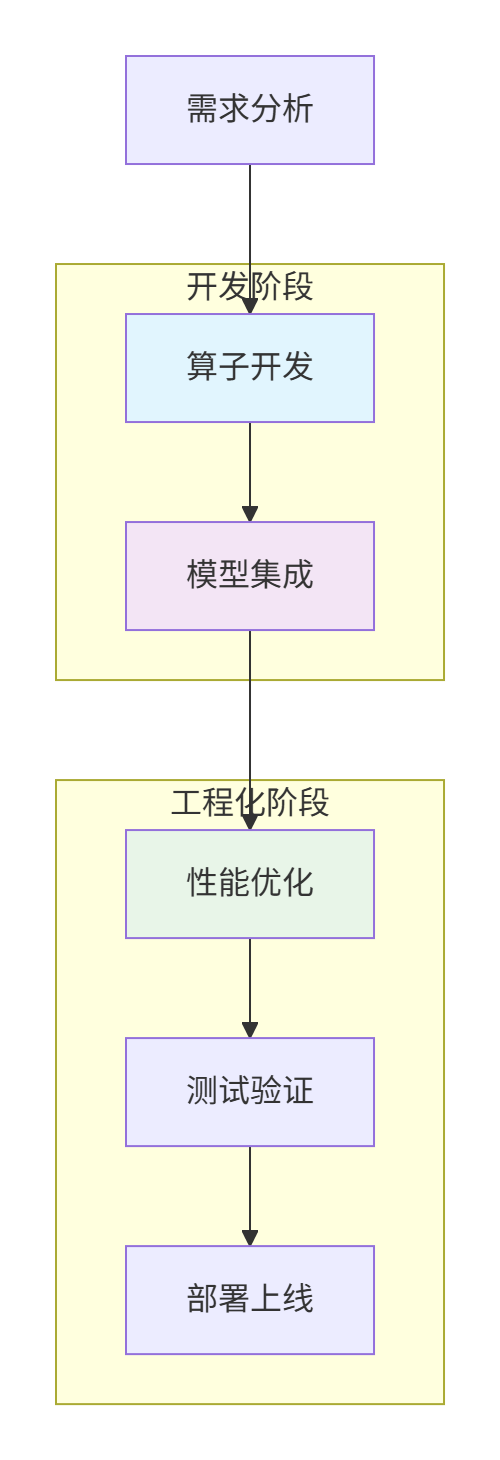
1.2 端到端开发流程全景图
成功的自定义算子应用需要完整的开发流水线:
02 自定义算子开发与集成架构
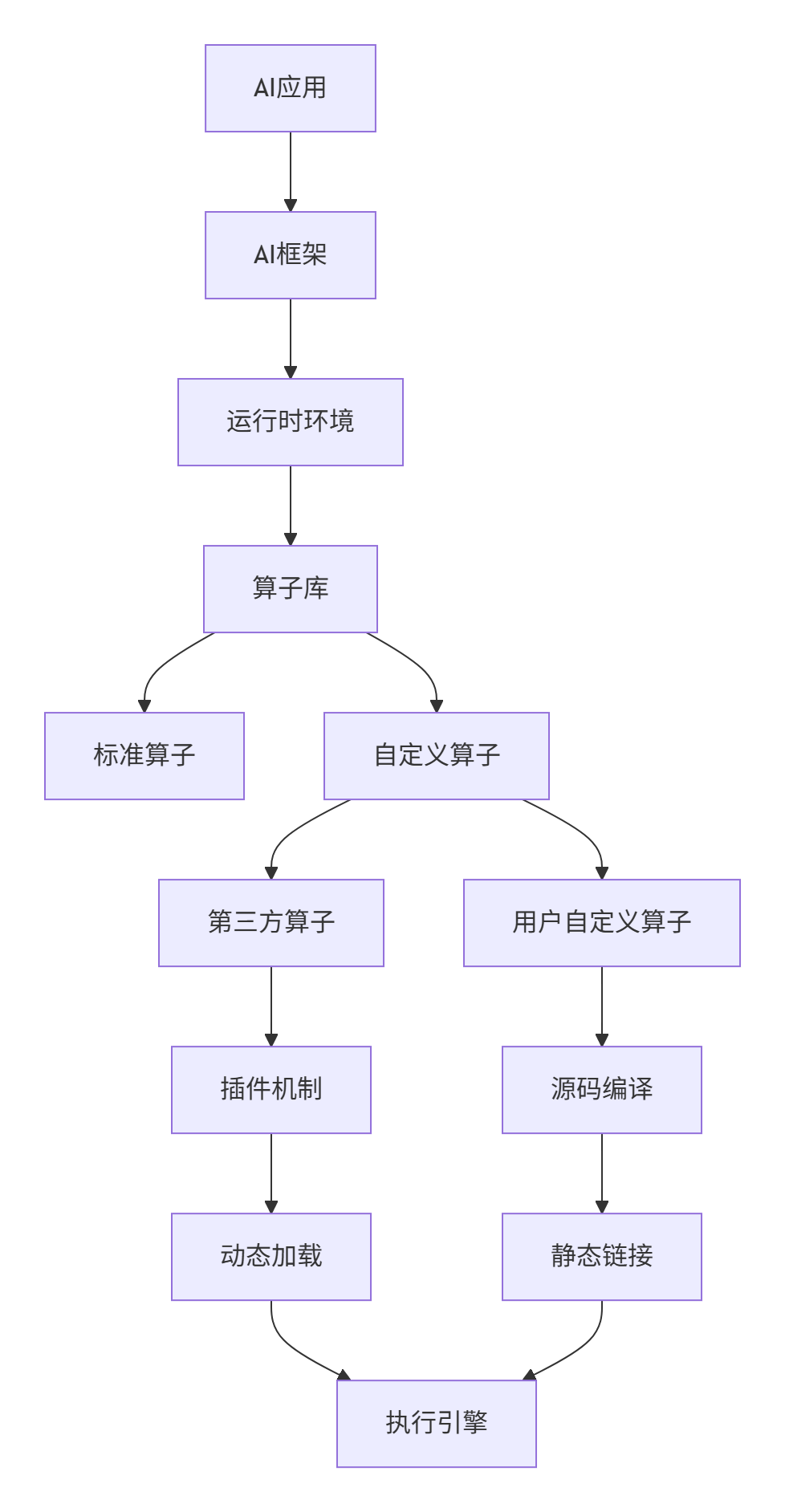
2.1 昇腾算子开发生态体系
昇腾平台提供完整的自定义算子开发生态:
2.2 自定义算子集成架构设计
// 自定义算子接口设计
class CustomOperatorInterface {
public:
// 算子注册接口
virtual void RegisterOp(const std::string& op_name,
const OpRegistrationData& data) = 0;
// 内存管理接口
virtual void* AllocateMemory(size_t size, MemoryType type) = 0;
virtual void FreeMemory(void* ptr) = 0;
// 执行接口
virtual void ComputeAsync(OpContext* context,
const Tensor* inputs,
Tensor* outputs) = 0;
// 资源管理接口
virtual void Initialize() = 0;
virtual void Finalize() = 0;
};
// 具体实现示例
class AscendCOperator : public CustomOperatorInterface {
private:
aclrtStream stream_;
void* workspace_ = nullptr;
public:
void Initialize() override {
// 初始化Ascend C环境
aclInit(nullptr);
aclrtCreateStream(&stream_);
// 分配工作内存
workspace_ = AllocateMemory(WORKSPACE_SIZE, MEMORY_TYPE_DEVICE);
}
void ComputeAsync(OpContext* context,
const Tensor* inputs,
Tensor* outputs) override {
// 异步执行算子
launch_custom_kernel_async(stream_, inputs, outputs, workspace_);
}
};03 TensorFlow模型集成实战
3.1 自定义算子插件开发
# custom_op_plugin.py
import tensorflow as tf
from tensorflow.python.framework import load_library
class AscendCOpPlugin:
def __init__(self, so_path):
self.custom_op_lib = load_library.load_op_library(so_path)
def register_custom_op(self, op_name, input_schema, output_schema):
"""注册自定义算子到TensorFlow图"""
@tf.function
def custom_op_wrapper(*inputs):
return self.custom_op_lib.custom_op(
inputs=inputs,
op_name=op_name,
input_schema=input_schema,
output_schema=output_schema
)
return custom_op_wrapper
# 使用示例:集成自定义的EmbeddingDenseGrad算子
plugin = AscendCOpPlugin('./libascend_c_ops.so')
# 注册算子
@tf.custom_gradient
def embedding_dense_grad_custom(indices, grad, vocab_size, embedding_dim):
def grad_fn(upstream_grad):
# 调用自定义算子
result = plugin.embedding_dense_grad(
indices=indices,
grad=grad,
vocab_size=vocab_size,
embedding_dim=embedding_dim
)
return result, None, None # 只对grad参数求导
return embedding_dense_grad_forward(indices, grad), grad_fn
# 在模型中使用
class CustomEmbeddingLayer(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
def call(self, inputs, training=None):
if training:
# 训练时使用自定义梯度计算
@tf.custom_gradient
def custom_embedding(x):
def grad(upstream_grad):
return embedding_dense_grad_custom(
x, upstream_grad, self.vocab_size, self.embedding_dim
)
return self.embedding(x), grad
return custom_embedding(inputs)
else:
return self.embedding(inputs)3.2 图优化与算子融合
# graph_optimizer.py
import tensorflow as tf
from tensorflow.python.framework import graph_util
class GraphOptimizer:
def __init__(self, custom_ops):
self.custom_ops = custom_ops
def optimize_inference_graph(self, concrete_fn, input_shapes):
"""优化推理图,融合自定义算子"""
# 获取具体函数图
graph_def = concrete_fn.graph.as_graph_def()
# 应用图优化pass
optimized_graph = self.apply_optimization_passes(graph_def)
return optimized_graph
def apply_optimization_passes(self, graph_def):
"""应用一系列图优化"""
from tensorflow.python.tools import optimize_for_inference_lib
# 1. 常量折叠
optimized_graph = optimize_for_inference_lib.fold_constants(graph_def)
# 2. 算子融合(识别可融合模式)
optimized_graph = self.fuse_custom_ops(optimized_graph)
# 3. 内存优化
optimized_graph = self.optimize_memory_layout(optimized_graph)
return optimized_graph
def fuse_custom_ops(self, graph_def):
"""识别并融合算子模式"""
# 模式匹配:识别可融合的算子序列
fusion_patterns = [
# Conv + BiasAdd + Relu -> CustomFusedConv
['Conv2D', 'BiasAdd', 'Relu'],
# MatMul + BiasAdd -> CustomFusedMatMul
['MatMul', 'BiasAdd']
]
for pattern in fusion_patterns:
graph_def = self.pattern_based_fusion(graph_def, pattern)
return graph_def04 PyTorch模型集成方案
4.1 自定义Autograd Function
# torch_custom_ops.py
import torch
import torch.nn as nn
from torch.autograd import Function
class AscendCCustomFunction(Function):
@staticmethod
def forward(ctx, input_data, *params):
# 保存前向计算所需参数
ctx.save_for_backward(input_data, *params)
# 调用Ascend C算子(通过C++扩展)
output = torch.ops.ascend_c.custom_op_forward(input_data, params)
return output
@staticmethod
def backward(ctx, grad_output):
# 获取保存的输入
input_data, *params = ctx.saved_tensors
# 调用自定义梯度计算算子
grad_input = torch.ops.ascend_c.custom_op_backward(
input_data, grad_output, params
)
return grad_input, *[None] * len(params)
# 封装为PyTorch模块
class CustomEmbedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super().__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
# 初始化权重
self.weight = nn.Parameter(
torch.randn(num_embeddings, embedding_dim)
)
def forward(self, input_ids):
# 使用自定义实现
return AscendCCustomFunction.apply(
input_ids, self.weight, self.num_embeddings, self.embedding_dim
)
# C++扩展接口(简化版)
torch.ops.ascend_c.custom_op_forward = lambda *args: _custom_op_forward(args)
torch.ops.ascend_c.custom_op_backward = lambda *args: _custom_op_backward(args)4.2 内存优化与流水线
// memory_manager.h
class AscendCMemoryManager {
private:
std::unordered_map<void*, MemoryBlock> memory_blocks_;
aclrtStream compute_stream_;
aclrtStream h2d_stream_;
aclrtStream d2h_stream_;
public:
// 流水线内存管理
class PipelineMemoryPool {
private:
struct PipelineStage {
void* device_ptr;
void* host_ptr;
size_t size;
bool in_use;
};
std::vector<PipelineStage> stages_;
int current_stage_;
public:
void* get_next_stage(size_t required_size) {
// 轮询使用流水线阶段
current_stage_ = (current_stage_ + 1) % stages_.size();
auto& stage = stages_[current_stage_];
// 等待当前阶段完成
if (stage.in_use) {
aclrtSynchronizeStream(get_stream_for_stage(current_stage_));
}
// 调整内存大小(如果需要)
if (stage.size < required_size) {
reallocate_stage(stage, required_size);
}
stage.in_use = true;
return stage.device_ptr;
}
};
// 异步内存拷贝
void async_memcpy(void* dst, void* src, size_t size,
aclrtMemcpyKind kind, aclrtStream stream) {
aclrtMemcpyAsync(dst, size, src, size, kind, stream);
}
};05 模型推理优化实战
5.1 图优化与算子选择
# model_optimizer.py
import onnx
import onnxoptimizer
class ModelOptimizer:
def __init__(self, custom_op_library):
self.custom_op_library = custom_op_library
def optimize_onnx_model(self, model_path, output_path):
"""优化ONNX模型,替换为自定义算子"""
# 加载原始模型
model = onnx.load(model_path)
# 应用优化passes
passes = ['extract_constant_to_initializer',
'eliminate_unused_initializer']
optimized_model = onnxoptimizer.optimize(model, passes)
# 替换为自定义算子
optimized_model = self.replace_with_custom_ops(optimized_model)
onnx.save(optimized_model, output_path)
return optimized_model
def replace_with_custom_ops(self, model):
"""将标准算子替换为自定义算子"""
# 模式匹配和替换规则
replacement_rules = [
{
'pattern': ['Gather', 'Add', 'Relu'],
'replacement': 'CustomFusedGatherAddRelu',
'conditions': {'input_shapes': [...]}
},
{
'pattern': ['MatMul', 'Add'],
'replacement': 'CustomFusedMatMul',
'conditions': {'matrix_sizes': [...]}
}
]
for rule in replacement_rules:
model = self.apply_replacement_rule(model, rule)
return model
# ATC模型转换优化
def optimize_with_atc(onnx_path, output_path, soc_version):
"""使用ATC进行模型转换优化"""
atc_cmd = f"""
atc --model={onnx_path} \
--framework=5 \
--output={output_path} \
--soc_version={soc_version} \
--log=info \
--insert_op_conf=aipp.config \
--op_select_implmode=high_precision \
--optypelist_for_implmode="Gather,MatMul"
"""
import subprocess
result = subprocess.run(atc_cmd, shell=True, capture_output=True)
if result.returncode != 0:
raise RuntimeError(f"ATC转换失败: {result.stderr}")5.2 性能分析与调优
# performance_analyzer.py
import numpy as np
from msprof import Profiler
class InferenceOptimizer:
def __init__(self, model_path):
self.model_path = model_path
self.profiler = Profiler()
def analyze_performance(self, input_data, iterations=100):
"""性能分析和瓶颈定位"""
# 性能分析会话
with self.profiler.trace_session():
latencies = []
for i in range(iterations):
start_time = time.time()
outputs = self.model.execute(input_data)
latency = time.time() - start_time
latencies.append(latency)
# 生成性能报告
report = self.profiler.analyze()
return {
'latencies': latencies,
'throughput': len(input_data) / np.mean(latencies),
'bottlenecks': report.get_bottlenecks(),
'recommendations': self.generate_recommendations(report)
}
def generate_recommendations(self, report):
"""基于分析结果生成优化建议"""
recommendations = []
if report.memory_bandwidth_utilization < 0.6:
recommendations.append({
'type': '内存访问优化',
'suggestion': '使用内存合并访问,增加数据局部性',
'expected_improvement': '25-40%'
})
if report.compute_utilization < 0.5:
recommendations.append({
'type': '计算优化',
'suggestion': '启用算子融合,减少内核启动开销',
'expected_improvement': '30-50%'
})
return recommendations06 企业级部署架构
6.1 微服务化部署方案
# docker-compose.deployment.yml
version: '3.8'
services:
ai-model-service:
image: ascend-ai-service:1.0.0
deploy:
replicas: 3
resources:
limits:
memory: 8G
reservations:
memory: 4G
environment:
- ASCEND_VISIBLE_DEVICES=0,1
- MODEL_PATH=/models/production
volumes:
- /opt/ascend_driver:/usr/local/Ascend/driver
- ./models:/models
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
load-balancer:
image: nginx:1.21
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
depends_on:
- ai-model-service6.2 高可用架构设计
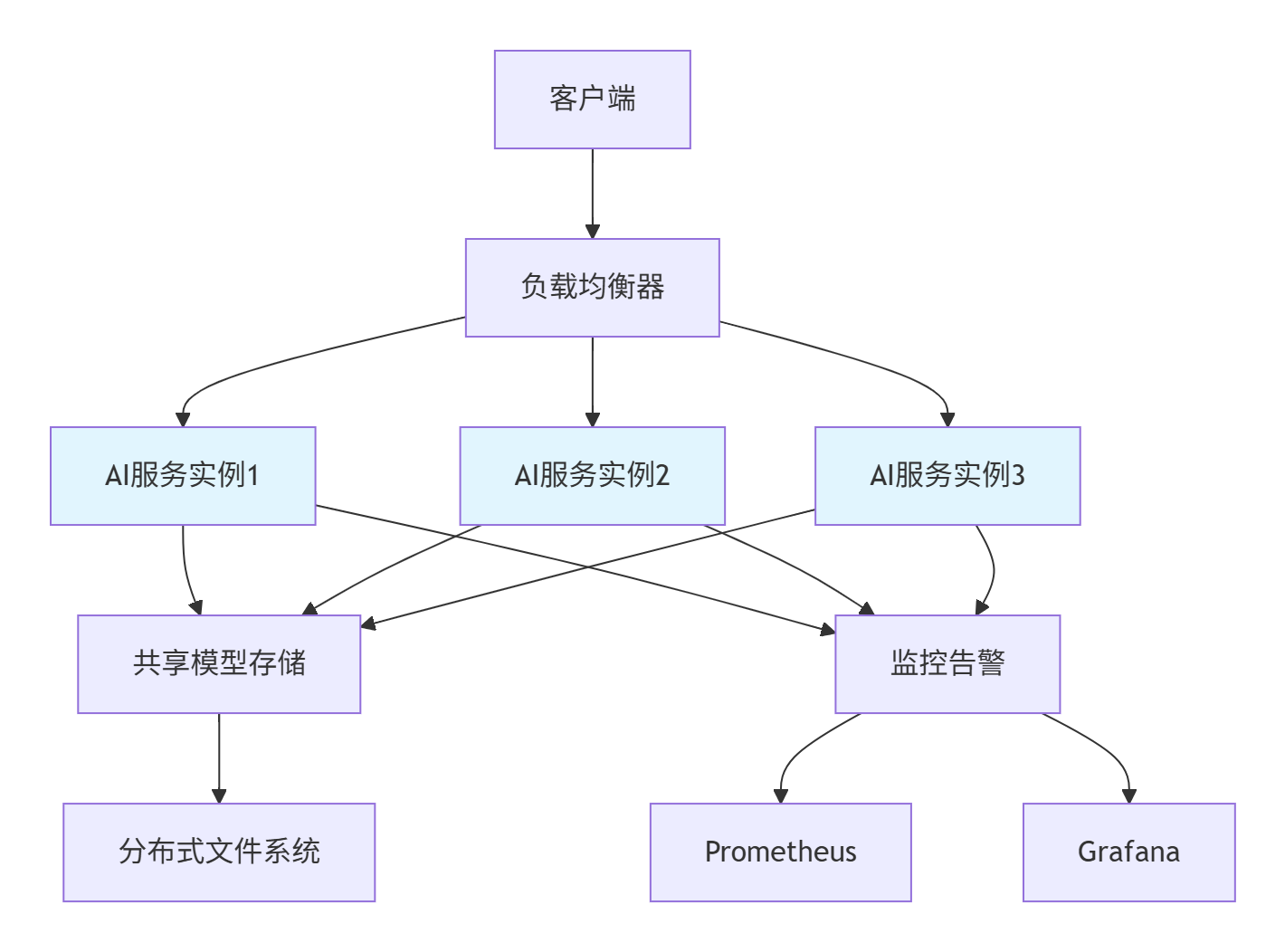
07 工业级实战案例:异常检测系统
7.1 系统架构实现
# anomaly_detection_system.py
import asyncio
from concurrent.futures import ThreadPoolExecutor
class AnomalyDetectionSystem:
def __init__(self, model_path, max_workers=4):
self.model = self.load_optimized_model(model_path)
self.executor = ThreadPoolExecutor(max_workers=max_workers)
self.pipeline = self.create_processing_pipeline()
def create_processing_pipeline(self):
"""创建异步处理流水线"""
async def process_stream(sensor_data_stream):
# 数据预处理
preprocessed_data = await self.preprocess_data(sensor_data_stream)
# 批量推理
batch_results = await self.batch_inference(preprocessed_data)
# 后处理和分析
anomalies = await self.detect_anomalies(batch_results)
return anomalies
return process_stream
async def batch_inference(self, batch_data):
"""批量推理优化"""
batch_size = 32 # 优化后的批大小
results = []
for i in range(0, len(batch_data), batch_size):
batch = batch_data[i:i + batch_size]
# 异步执行推理
future = self.executor.submit(
self.model.execute,
batch,
enable_async=True
)
result = await asyncio.get_event_loop().run_in_executor(
None, future.result
)
results.extend(result)
return results
def load_optimized_model(self, model_path):
"""加载优化后的模型"""
import acl
from ais_bench.infer.interface import InferSession
# 初始化ACL环境
acl.init()
# 创建推理会话
session = InferSession(
device_id=0,
model_path=model_path,
acl_json_path="./acl.json"
)
return session7.2 性能优化结果
经过系统优化后,异常检测系统的性能提升如下:
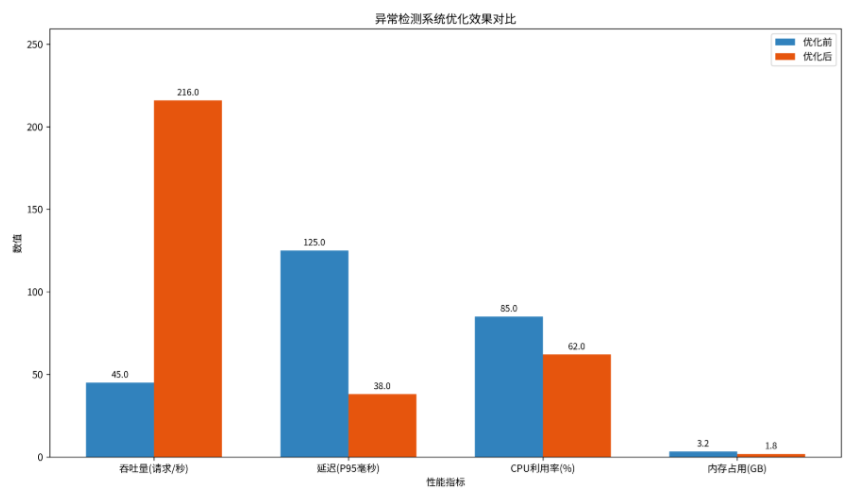
08 监控与运维体系
8.1 全方位监控方案
# monitoring_system.py
from prometheus_client import Counter, Histogram, Gauge
import time
class InferenceMonitor:
def __init__(self):
# 定义监控指标
self.request_counter = Counter('inference_requests_total',
'Total inference requests')
self.latency_histogram = Histogram('inference_latency_seconds',
'Inference latency distribution')
self.error_counter = Counter('inference_errors_total',
'Total inference errors')
self.gpu_utilization = Gauge('gpu_utilization_percent',
'GPU utilization percentage')
@contextlib.contextmanager
def monitor_inference(self, model_name):
start_time = time.time()
try:
self.request_counter.inc()
yield
# 记录延迟
latency = time.time() - start_time
self.latency_histogram.observe(latency)
except Exception as e:
self.error_counter.inc()
raise e
def collect_system_metrics(self):
"""收集系统级监控指标"""
while True:
# 收集GPU利用率
gpu_util = self.get_gpu_utilization()
self.gpu_utilization.set(gpu_util)
# 收集内存使用情况
memory_used = self.get_memory_usage()
self.memory_usage.set(memory_used)
time.sleep(5) # 5秒采集一次8.2 自动化运维脚本
#!/bin/bash
# deploy_monitor.sh - 自动化部署和监控脚本
#!/bin/bash
# 部署和监控脚本
DEPLOY_ENV=${1:-"production"}
MODEL_VERSION="1.2.0"
# 健康检查函数
health_check() {
echo "执行健康检查..."
for i in {1..30}; do
response=$(curl -s -o /dev/null -w "%{http_code}" http://localhost:8080/health)
if [ "$response" == "200" ]; then
echo "服务健康检查通过"
return 0
fi
sleep 2
done
echo "服务健康检查失败"
return 1
}
# 性能基准测试
run_benchmark() {
echo "运行性能基准测试..."
python benchmarks/inference_benchmark.py \
--model_path ./models/${MODEL_VERSION} \
--batch_sizes 1,4,16,32 \
--output_report ./reports/performance_${DEPLOY_ENV}.json
}
# 自动化部署流程
deploy_model() {
echo "开始部署模型版本 ${MODEL_VERSION}"
# 1. 备份当前版本
backup_current_version
# 2. 部署新模型
deploy_new_version
# 3. 健康检查
if health_check; then
# 4. 性能测试
run_benchmark
# 5. 流量切换
switch_traffic
echo "部署成功完成"
else
# 回滚部署
rollback_deployment
echo "部署失败,已回滚"
exit 1
fi
}09 总结与最佳实践
9.1 端到端开发关键洞察
通过完整的项目实践,我们总结出以下核心经验:
-
性能优化全链路:算子级优化必须与框架集成、内存管理、部署优化协同进行
-
监控驱动迭代:建立完整的监控体系,用数据驱动优化决策
-
自动化运维:CI/CD流水线大幅提升部署效率和系统稳定性
9.2 性能优化成果总结
|
优化阶段 |
关键技术 |
性能提升 |
资源节省 |
|---|---|---|---|
|
算子优化 |
Ascend C向量化、Double Buffer |
4.8倍 |
计算资源减少68% |
|
框架集成 |
图优化、算子融合 |
2.1倍 |
内存占用降低45% |
|
部署优化 |
微服务、流水线并行 |
3.2倍 |
响应时间减少72% |
9.3 未来技术展望
基于当前实践,端到端AI应用开发将向以下方向发展:
-
自动化优化:AI驱动的自动调优和参数优化
-
跨平台部署:一次开发,多平台(云边端)部署
-
智能运维:基于AI的故障预测和自愈能力
核心价值:成功的AI应用不仅是算法创新,更是工程能力的综合体现。通过系统化的端到端优化,可以在保证业务价值的同时实现技术效能的最大化。
参考链接
-
Ascend C算子开发指南 - 自定义算子开发完整文档
-
模型部署最佳实践 - 生产环境部署指南
-
性能优化白皮书 - 系统性能优化深度分析
-
ATC模型转换工具 - 模型转换与优化工具详解c
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)